 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFUNQUE: Fusion of Unified Quality Evaluators
Feb 23, 2022
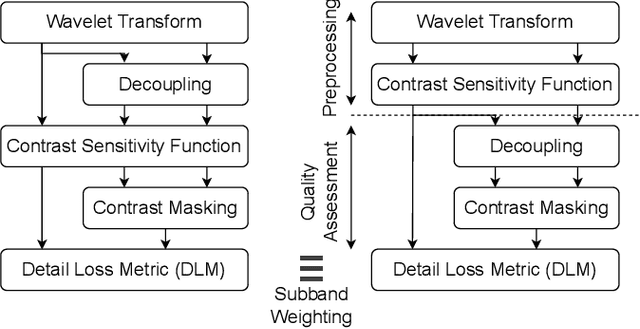
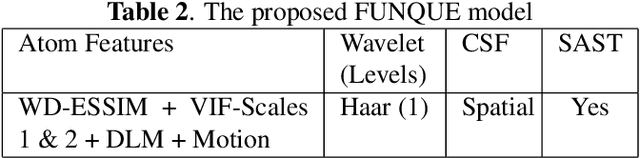
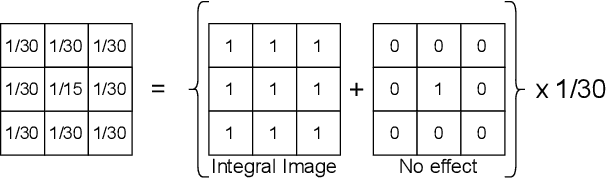
Fusion-based quality assessment has emerged as a powerful method for developing high-performance quality models from quality models that individually achieve lower performances. A prominent example of such an algorithm is VMAF, which has been widely adopted as an industry standard for video quality prediction along with SSIM. In addition to advancing the state-of-the-art, it is imperative to alleviate the computational burden presented by the use of a heterogeneous set of quality models. In this paper, we unify "atom" quality models by computing them on a common transform domain that accounts for the Human Visual System, and we propose FUNQUE, a quality model that fuses unified quality evaluators. We demonstrate that in comparison to the state-of-the-art, FUNQUE offers significant improvements in both correlation against subjective scores and efficiency, due to computation sharing.
FAVER: Blind Quality Prediction of Variable Frame Rate Videos
Jan 05, 2022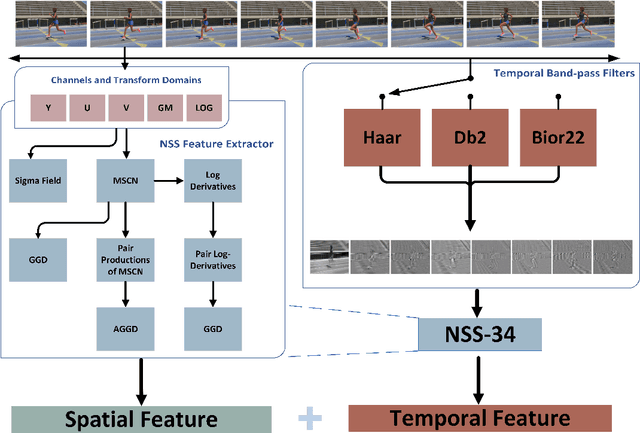
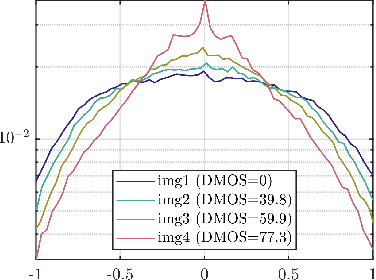
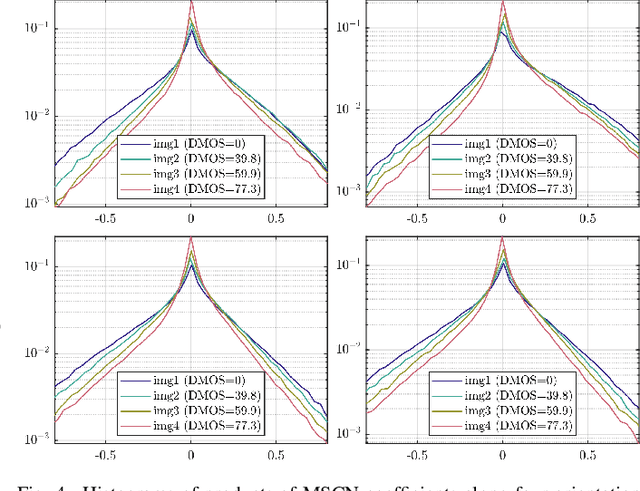
Video quality assessment (VQA) remains an important and challenging problem that affects many applications at the widest scales. Recent advances in mobile devices and cloud computing techniques have made it possible to capture, process, and share high resolution, high frame rate (HFR) videos across the Internet nearly instantaneously. Being able to monitor and control the quality of these streamed videos can enable the delivery of more enjoyable content and perceptually optimized rate control. Accordingly, there is a pressing need to develop VQA models that can be deployed at enormous scales. While some recent effects have been applied to full-reference (FR) analysis of variable frame rate and HFR video quality, the development of no-reference (NR) VQA algorithms targeting frame rate variations has been little studied. Here, we propose a first-of-a-kind blind VQA model for evaluating HFR videos, which we dub the Framerate-Aware Video Evaluator w/o Reference (FAVER). FAVER uses extended models of spatial natural scene statistics that encompass space-time wavelet-decomposed video signals, to conduct efficient frame rate sensitive quality prediction. Our extensive experiments on several HFR video quality datasets show that FAVER outperforms other blind VQA algorithms at a reasonable computational cost. To facilitate reproducible research and public evaluation, an implementation of FAVER is being made freely available online: \url{https://github.com/uniqzheng/HFR-BVQA}.
Image Quality Assessment using Contrastive Learning
Oct 25, 2021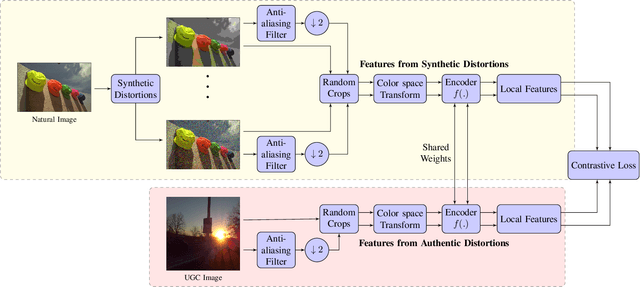
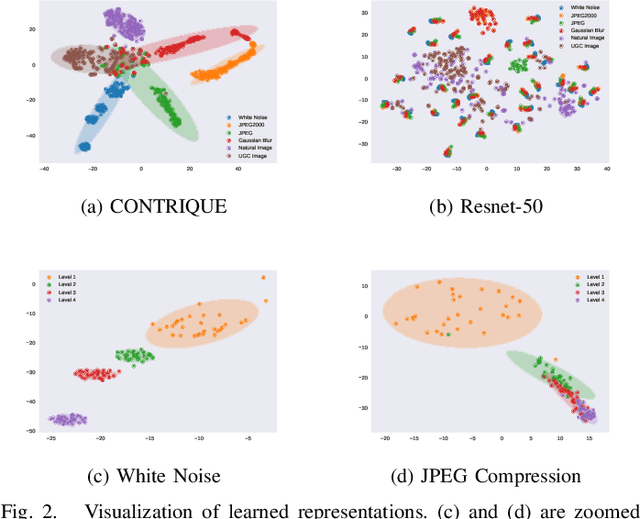
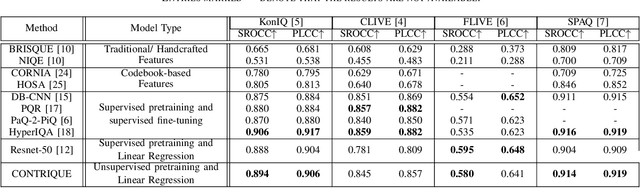
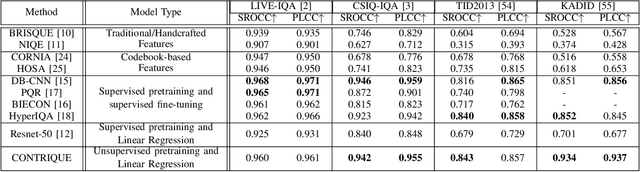
We consider the problem of obtaining image quality representations in a self-supervised manner. We use prediction of distortion type and degree as an auxiliary task to learn features from an unlabeled image dataset containing a mixture of synthetic and realistic distortions. We then train a deep Convolutional Neural Network (CNN) using a contrastive pairwise objective to solve the auxiliary problem. We refer to the proposed training framework and resulting deep IQA model as the CONTRastive Image QUality Evaluator (CONTRIQUE). During evaluation, the CNN weights are frozen and a linear regressor maps the learned representations to quality scores in a No-Reference (NR) setting. We show through extensive experiments that CONTRIQUE achieves competitive performance when compared to state-of-the-art NR image quality models, even without any additional fine-tuning of the CNN backbone. The learned representations are highly robust and generalize well across images afflicted by either synthetic or authentic distortions. Our results suggest that powerful quality representations with perceptual relevance can be obtained without requiring large labeled subjective image quality datasets. The implementations used in this paper are available at \url{https://github.com/pavancm/CONTRIQUE}.
Self-Supervised Learning of Perceptually Optimized Block Motion Estimates for Video Compression
Oct 11, 2021
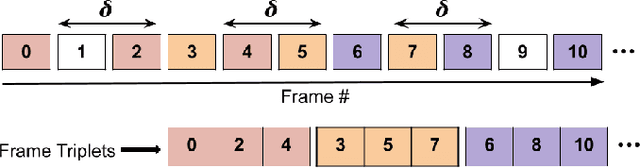
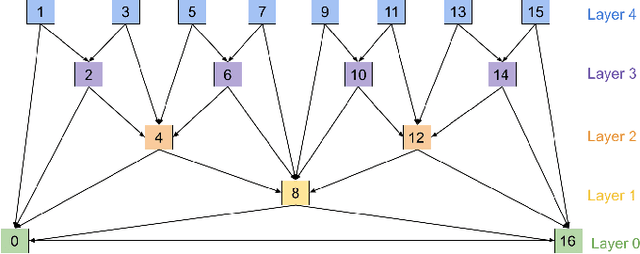
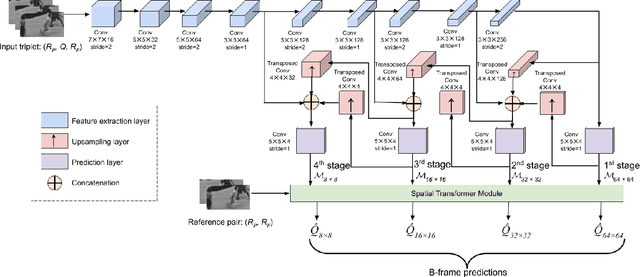
Block based motion estimation is integral to inter prediction processes performed in hybrid video codecs. Prevalent block matching based methods that are used to compute block motion vectors (MVs) rely on computationally intensive search procedures. They also suffer from the aperture problem, which can worsen as the block size is reduced. Moreover, the block matching criteria used in typical codecs do not account for the resulting levels of perceptual quality of the motion compensated pictures that are created upon decoding. Towards achieving the elusive goal of perceptually optimized motion estimation, we propose a search-free block motion estimation framework using a multi-stage convolutional neural network, which is able to conduct motion estimation on multiple block sizes simultaneously, using a triplet of frames as input. This composite block translation network (CBT-Net) is trained in a self-supervised manner on a large database that we created from publicly available uncompressed video content. We deploy the multi-scale structural similarity (MS-SSIM) loss function to optimize the perceptual quality of the motion compensated predicted frames. Our experimental results highlight the computational efficiency of our proposed model relative to conventional block matching based motion estimation algorithms, for comparable prediction errors. Further, when used to perform inter prediction in AV1, the MV predictions of the perceptually optimized model result in average Bjontegaard-delta rate (BD-rate) improvements of -1.70% and -1.52% with respect to the MS-SSIM and Video Multi-Method Assessment Fusion (VMAF) quality metrics, respectively as compared to the block matching based motion estimation system employed in the SVT-AV1 encoder.
High Frame Rate Video Quality Assessment using VMAF and Entropic Differences
Sep 27, 2021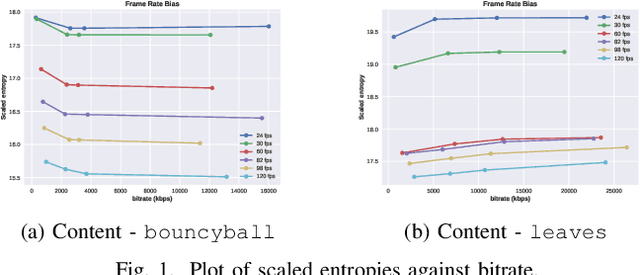
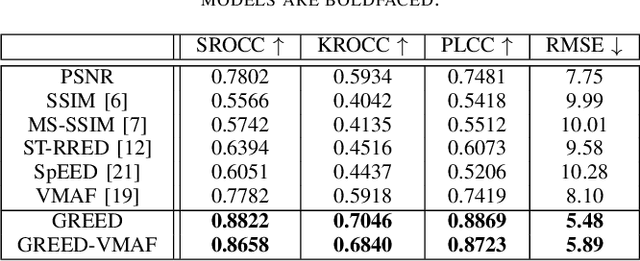

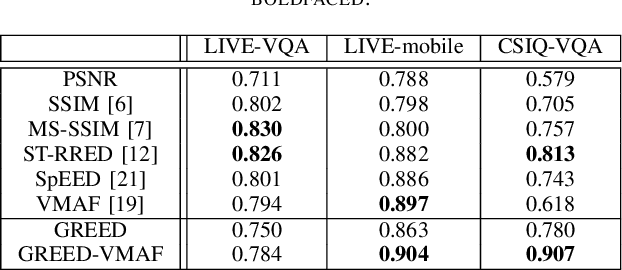
The popularity of streaming videos with live, high-action content has led to an increased interest in High Frame Rate (HFR) videos. In this work we address the problem of frame rate dependent Video Quality Assessment (VQA) when the videos to be compared have different frame rate and compression factor. The current VQA models such as VMAF have superior correlation with perceptual judgments when videos to be compared have same frame rates and contain conventional distortions such as compression, scaling etc. However this framework requires additional pre-processing step when videos with different frame rates need to be compared, which can potentially limit its overall performance. Recently, Generalized Entropic Difference (GREED) VQA model was proposed to account for artifacts that arise due to changes in frame rate, and showed superior performance on the LIVE-YT-HFR database which contains frame rate dependent artifacts such as judder, strobing etc. In this paper we propose a simple extension, where the features from VMAF and GREED are fused in order to exploit the advantages of both models. We show through various experiments that the proposed fusion framework results in more efficient features for predicting frame rate dependent video quality. We also evaluate the fused feature set on standard non-HFR VQA databases and obtain superior performance than both GREED and VMAF, indicating the combined feature set captures complimentary perceptual quality information.
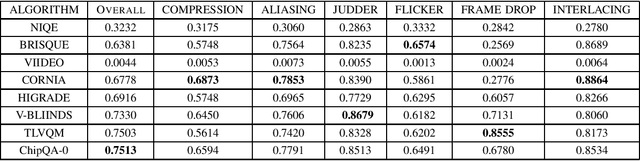
ChipQA: No-Reference Video Quality Prediction via Space-Time Chips
Sep 17, 2021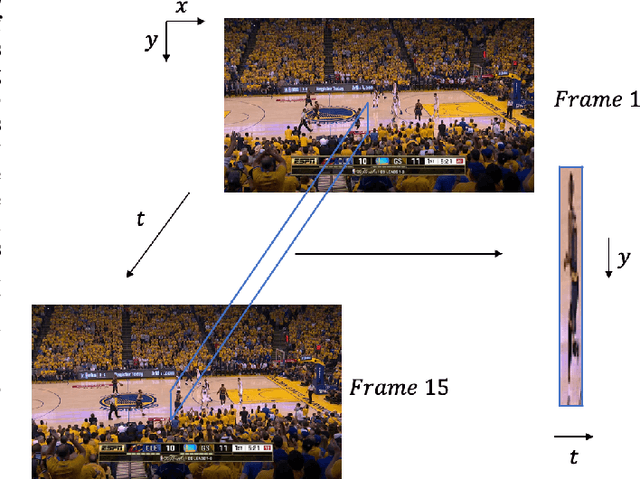
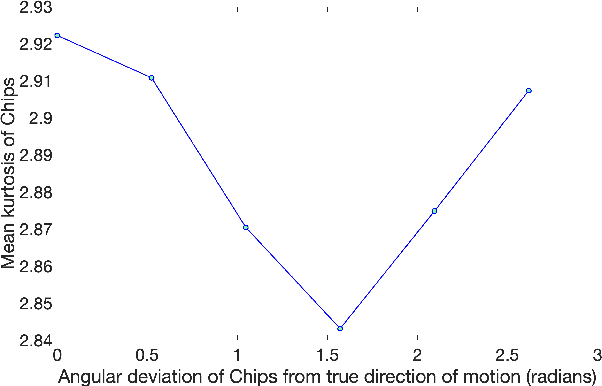
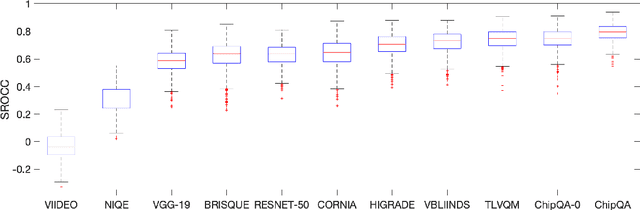
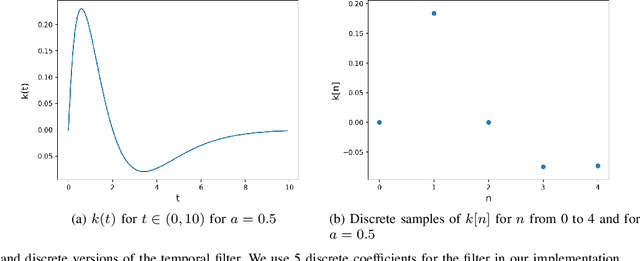
We propose a new model for no-reference video quality assessment (VQA). Our approach uses a new idea of highly-localized space-time (ST) slices called Space-Time Chips (ST Chips). ST Chips are localized cuts of video data along directions that \textit{implicitly} capture motion. We use perceptually-motivated bandpass and normalization models to first process the video data, and then select oriented ST Chips based on how closely they fit parametric models of natural video statistics. We show that the parameters that describe these statistics can be used to reliably predict the quality of videos, without the need for a reference video. The proposed method implicitly models ST video naturalness, and deviations from naturalness. We train and test our model on several large VQA databases, and show that our model achieves state-of-the-art performance at reduced cost, without requiring motion computation.
Assessment of Subjective and Objective Quality of Live Streaming Sports Videos
Jun 15, 2021
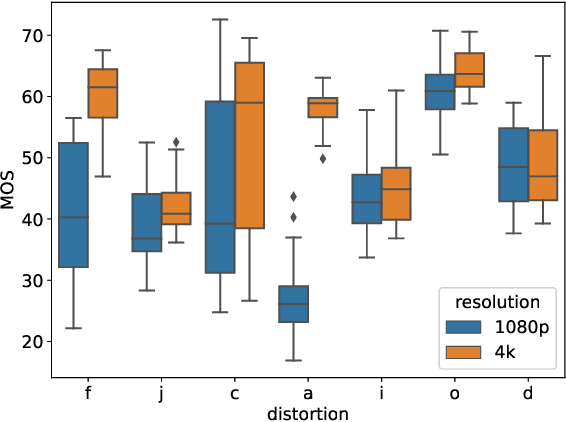
Video live streaming is gaining prevalence among video streaming services, especially for the delivery of popular sporting events. Many objective Video Quality Assessment (VQA) models have been developed to predict the perceptual quality of videos. Appropriate databases that exemplify the distortions encountered in live streaming videos are important to designing and learning objective VQA models. Towards making progress in this direction, we built a video quality database specifically designed for live streaming VQA research. The new video database is called the Laboratory for Image and Video Engineering (LIVE) Live stream Database. The LIVE Livestream Database includes 315 videos of 45 contents impaired by 6 types of distortions. We also performed a subjective quality study using the new database, whereby more than 12,000 human opinions were gathered from 40 subjects. We demonstrate the usefulness of the new resource by performing a holistic evaluation of the performance of current state-of-the-art (SOTA) VQA models. The LIVE Livestream database is being made publicly available for these purposes at https://live.ece.utexas.edu/research/LIVE_APV_Study/apv_index.html.
Convolutional Block Design for Learned Fractional Downsampling
May 20, 2021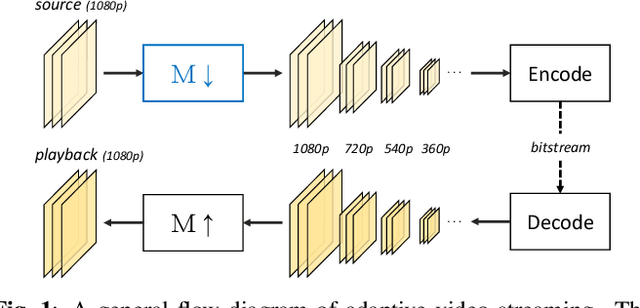
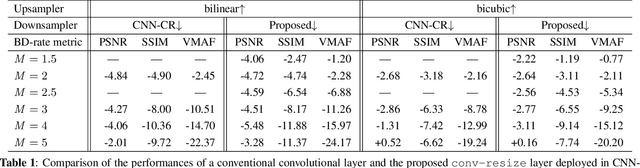
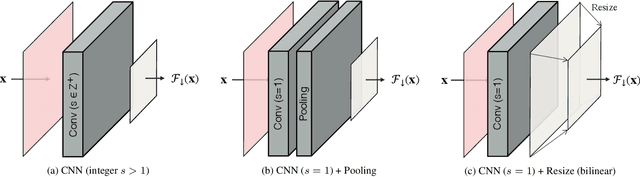
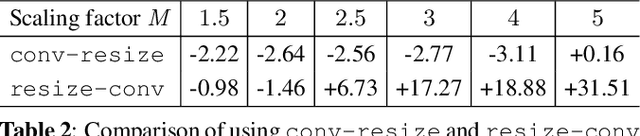
The layers of convolutional neural networks (CNNs) can be used to alter the resolution of their inputs, but the scaling factors are limited to integer values. However, in many image and video processing applications, the ability to resize by a fractional factor would be advantageous. One example is conversion between resolutions standardized for video compression, such as from 1080p to 720p. To solve this problem, we propose an alternative building block, formulated as a conventional convolutional layer followed by a differentiable resizer. More concretely, the convolutional layer preserves the resolution of the input, while the resizing operation is fully handled by the resizer. In this way, any CNN architecture can be adapted for non-integer resizing. As an application, we replace the resizing convolutional layer of a modern deep downsampling model by the proposed building block, and apply it to an adaptive bitrate video streaming scenario. Our experimental results show that an improvement in coding efficiency over the conventional Lanczos algorithm is attained, in terms of PSNR, SSIM, and VMAF on test videos.
Space-Time Video Regularity and Visual Fidelity: Compression, Resolution and Frame Rate Adaptation
Mar 31, 2021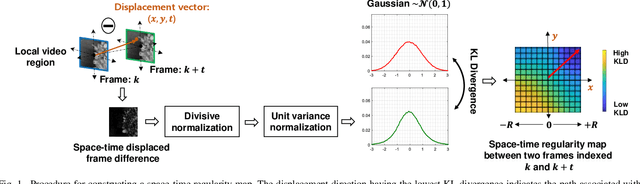
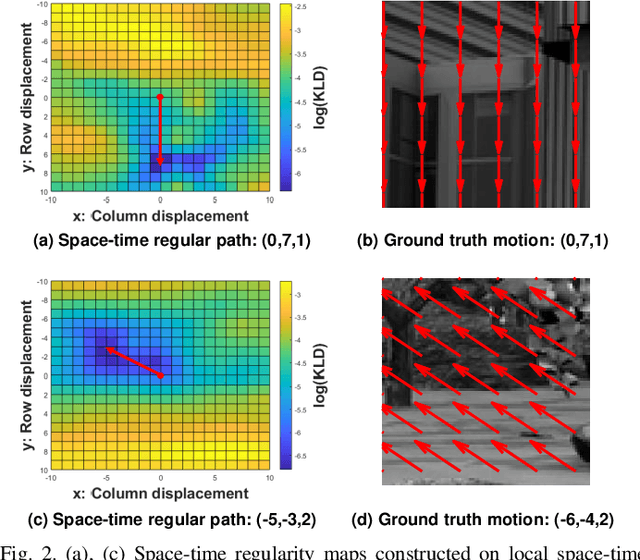
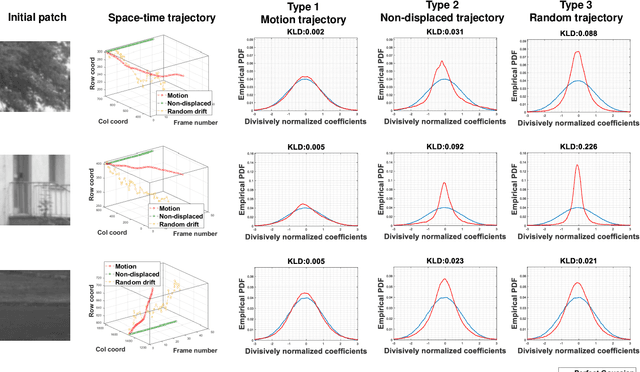
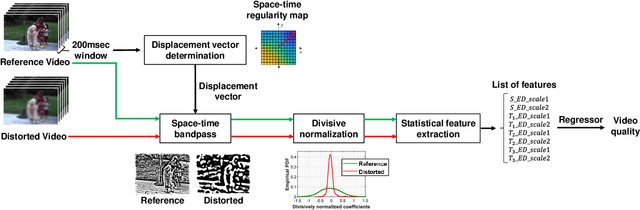
In order to be able to deliver today's voluminous amount of video contents through limited bandwidth channels in a perceptually optimal way, it is important to consider perceptual trade-offs of compression and space-time downsampling protocols. In this direction, we have studied and developed new models of natural video statistics (NVS), which are useful because high-quality videos contain statistical regularities that are disturbed by distortions. Specifically, we model the statistics of divisively normalized difference between neighboring frames that are relatively displaced. In an extensive empirical study, we found that those paths of space-time displaced frame differences that provide maximal regularity against our NVS model generally align best with motion trajectories. Motivated by this, we build a new video quality prediction engine that extracts NVS features from displaced frame differences, and combines them in a learned regressor that can accurately predict perceptual quality. As a stringent test of the new model, we apply it to the difficult problem of predicting the quality of videos subjected not only to compression, but also to downsampling in space and/or time. We show that the new quality model achieves state-of-the-art (SOTA) prediction performance compared on the new ETRI-LIVE Space-Time Subsampled Video Quality (STSVQ) database, which is dedicated to this problem. Downsampling protocols are of high interest to the streaming video industry, given rapid increases in frame resolutions and frame rates.
A Hitchhiker's Guide to Structural Similarity
Jan 30, 2021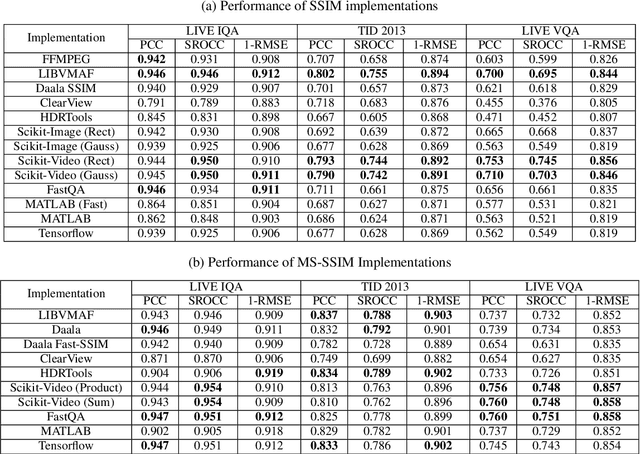
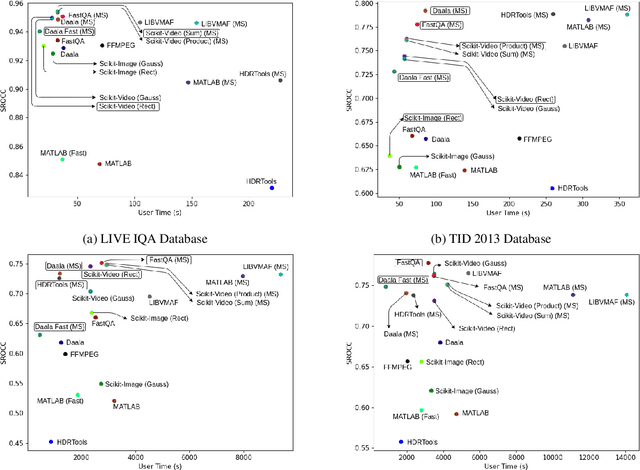
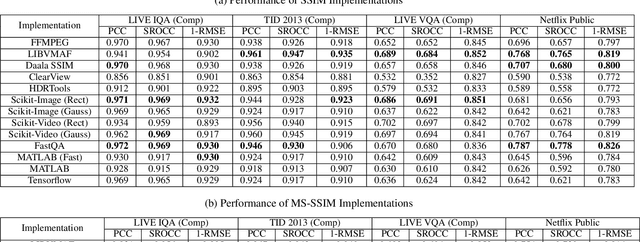
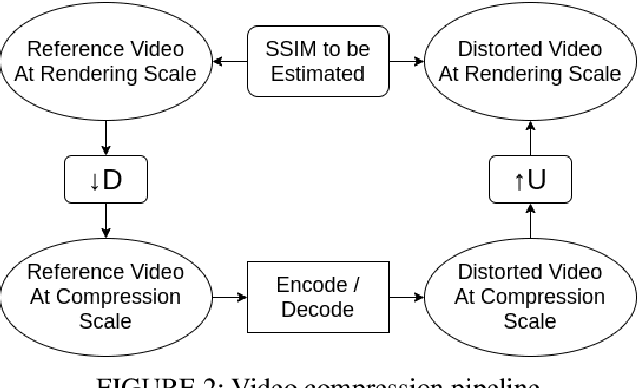
The Structural Similarity (SSIM) Index is a very widely used image/video quality model that continues to play an important role in the perceptual evaluation of compression algorithms, encoding recipes and numerous other image/video processing algorithms. Several public implementations of the SSIM and Multiscale-SSIM (MS-SSIM) algorithms have been developed, which differ in efficiency and performance. This "bendable ruler" makes the process of quality assessment of encoding algorithms unreliable. To address this situation, we studied and compared the functions and performances of popular and widely used implementations of SSIM, and we also considered a variety of design choices. Based on our studies and experiments, we have arrived at a collection of recommendations on how to use SSIM most effectively, including ways to reduce its computational burden.