 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMinimal Rolling Shutter Absolute Pose with Unknown Focal Length and Radial Distortion
Apr 29, 2020
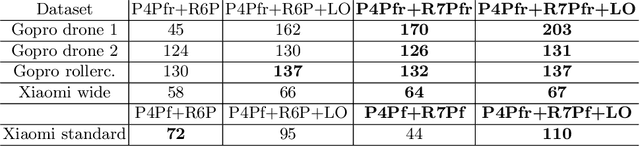
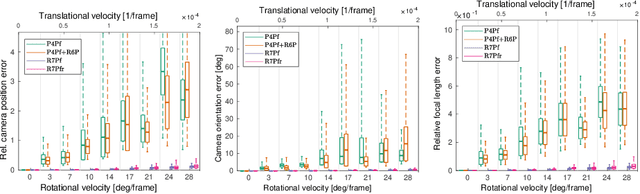

The internal geometry of most modern consumer cameras is not adequately described by the perspective projection. Almost all cameras exhibit some radial lens distortion and are equipped with an electronic rolling shutter that induces distortions when the camera moves during the image capture. When focal length has not been calibrated offline, the parameters that describe the radial and rolling shutter distortions are usually unknown. While for global shutter cameras, minimal solvers for the absolute camera pose and unknown focal length and radial distortion are available, solvers for the rolling shutter were missing. We present the first minimal solutions for the absolute pose of a rolling shutter camera with unknown rolling shutter parameters, focal length, and radial distortion. Our new minimal solvers combine iterative schemes designed for calibrated rolling shutter cameras with fast generalized eigenvalue and Groebner basis solvers. In a series of experiments, with both synthetic and real data, we show that our new solvers provide accurate estimates of the camera pose, rolling shutter parameters, focal length, and radial distortion parameters.
TetraTSDF: 3D human reconstruction from a single image with a tetrahedral outer shell
Apr 22, 2020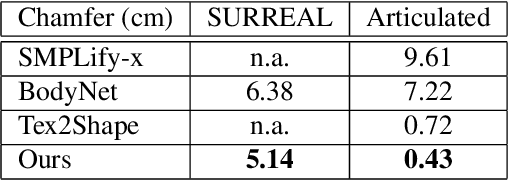
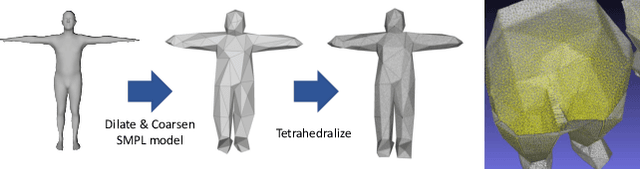

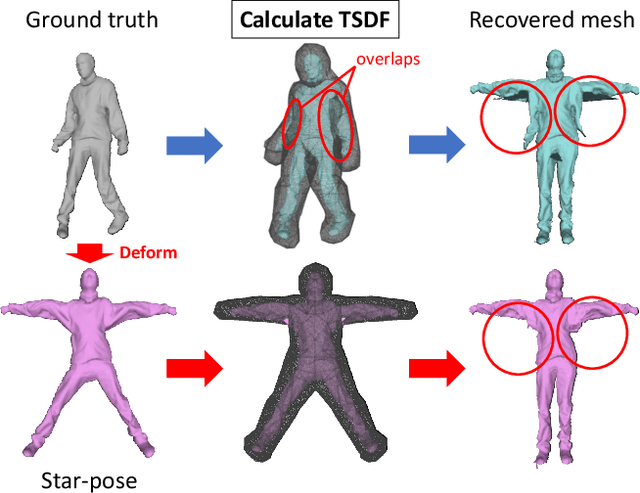
Recovering the 3D shape of a person from its 2D appearance is ill-posed due to ambiguities. Nevertheless, with the help of convolutional neural networks (CNN) and prior knowledge on the 3D human body, it is possible to overcome such ambiguities to recover detailed 3D shapes of human bodies from single images. Current solutions, however, fail to reconstruct all the details of a person wearing loose clothes. This is because of either (a) huge memory requirement that cannot be maintained even on modern GPUs or (b) the compact 3D representation that cannot encode all the details. In this paper, we propose the tetrahedral outer shell volumetric truncated signed distance function (TetraTSDF) model for the human body, and its corresponding part connection network (PCN) for 3D human body shape regression. Our proposed model is compact, dense, accurate, and yet well suited for CNN-based regression task. Our proposed PCN allows us to learn the distribution of the TSDF in the tetrahedral volume from a single image in an end-to-end manner. Results show that our proposed method allows to reconstruct detailed shapes of humans wearing loose clothes from single RGB images.
Two-Stream FCNs to Balance Content and Style for Style Transfer
Nov 19, 2019
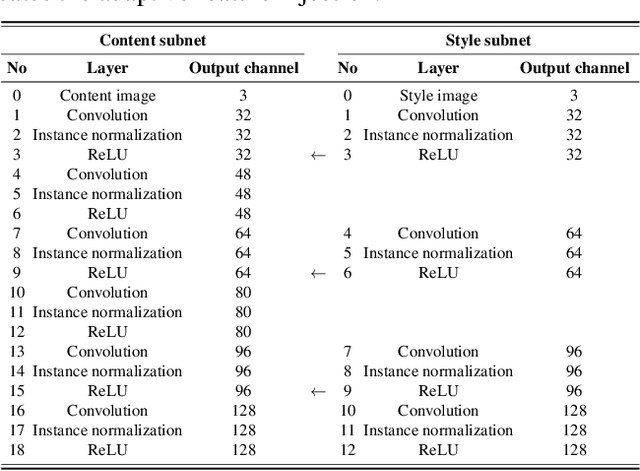

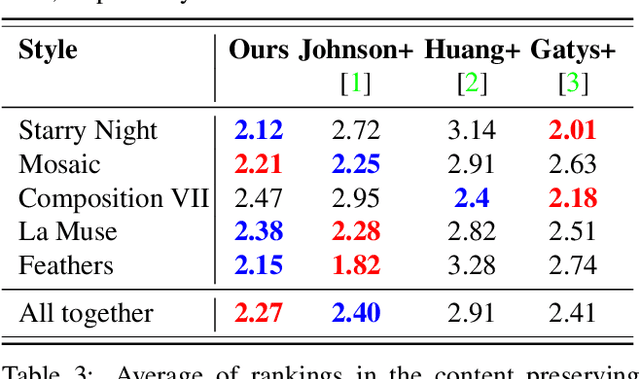
Style transfer is to render given image contents in given styles, and it has an important role in both computer vision fundamental research and industrial applications. Following the success of deep learning based approaches, this problem has been re-launched very recently, but still remains a difficult task because of trade-off between preserving contents and faithful rendering of styles. In this paper, we propose an end-to-end two-stream Fully Convolutional Networks (FCNs) aiming at balancing the contributions of the content and the style in rendered images. Our proposed network consists of the encoder and decoder parts. The encoder part utilizes a FCN for content and a FCN for style where the two FCNs have feature injections and are independently trained to preserve the semantic content and to learn the faithful style representation in each. The semantic content feature and the style representation feature are then concatenated adaptively and fed into the decoder to generate style-transferred (stylized) images. In order to train our proposed network, we employ a loss network, the pre-trained VGG-16, to compute content loss and style loss, both of which are efficiently used for the feature injection as well as the feature concatenation. Our intensive experiments show that our proposed model generates more balanced stylized images in content and style than state-of-the-art methods. Moreover, our proposed network achieves efficiency in speed.
Visual-Relation Conscious Image Generation from Structured-Text
Aug 05, 2019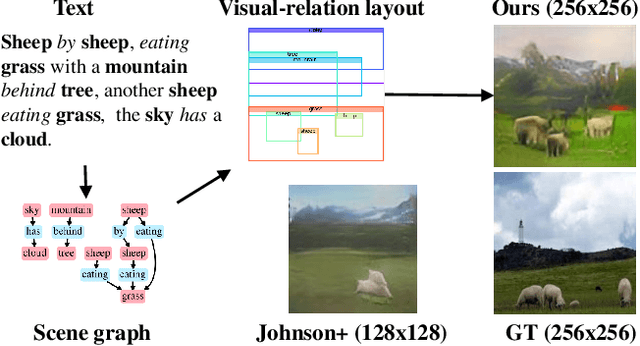
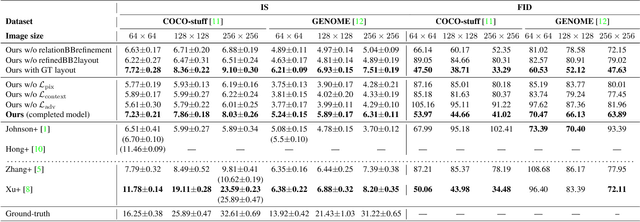
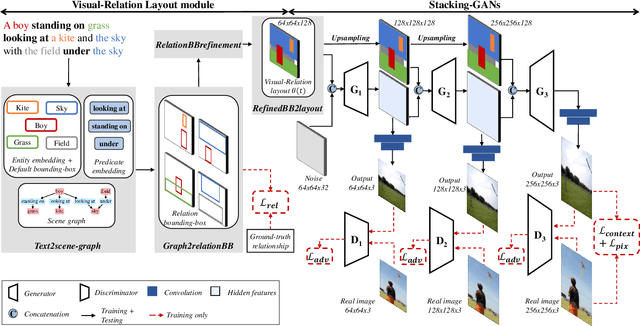
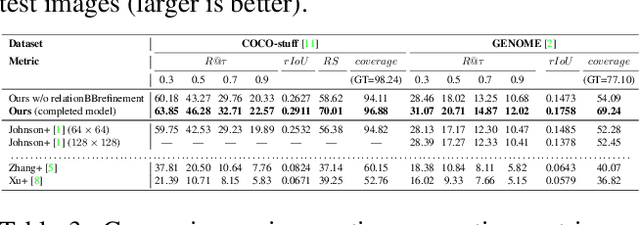
Generating realistic images from text descriptions is a challenging problem and has many applications such as image editing or computer-aided design. In spite of recent progress on this text-to-image generation based on GANs, generating realistic images from complex descriptions with many entities in a general scene is not yet achieved in the literature. In the presence of multiple entities, the relationships between entities become important because they condition the location of each entity. We propose a GAN-based end-to-end network that learns the visual-relation layout between entities from given texts and conditions the layout in generating images. Our proposed network consists of the visual-relation layout module and the stacking-GANs. The visual-relation layout module predicts bounding-boxes for all the entities given in an input text so that each of them uniquely corresponds to each entity while keeping its involved relationships. The visual-relation layout is obtained by aggregating all the bounding-boxes, reflecting the scene structure given in text. The stacking-GANs is the stack of three GANs conditioned on the output of previous GAN and the visual-relation layout, consistently capturing the scene structure. Our network realistically renders entities' details in high resolution while keeping the scene structure. Experimental results on two public datasets show outperformances of our method against state-of-the-art methods.
Linear solution to the minimal absolute pose rolling shutter problem
Dec 30, 2018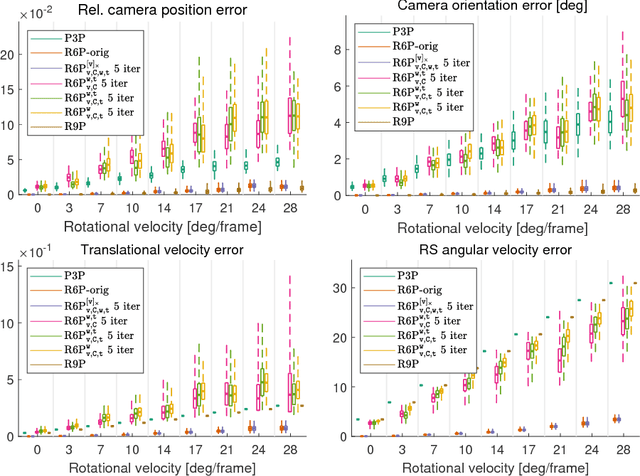

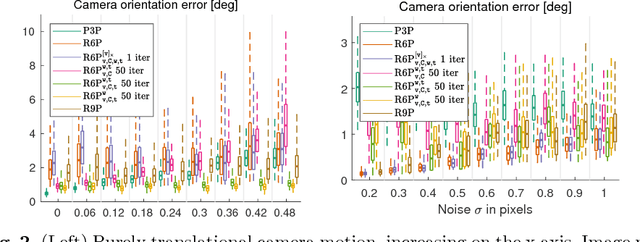
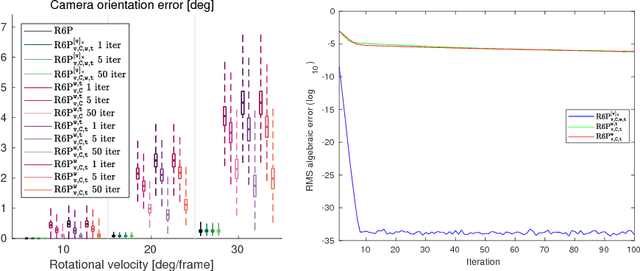
This paper presents new efficient solutions to the rolling shutter camera absolute pose problem. Unlike the state-of-the-art polynomial solvers, we approach the problem using simple and fast linear solvers in an iterative scheme. We present several solutions based on fixing different sets of variables and investigate the performance of them thoroughly. We design a new alternation strategy that estimates all parameters in each iteration linearly by fixing just the non-linear terms. Our best 6-point solver, based on the new alternation technique, shows an identical or even better performance than the state-of-the-art R6P solver and is two orders of magnitude faster. In addition, a linear non-iterative solver is presented that requires a non-minimal number of 9 correspondences but provides even better results than the state-of-the-art R6P. Moreover, all proposed linear solvers provide a single solution while the state-of-the-art R6P provides up to 20 solutions which have to be pruned by expensive verification.
Video Semantic Salient Instance Segmentation: Benchmark Dataset and Baseline
Aug 09, 2018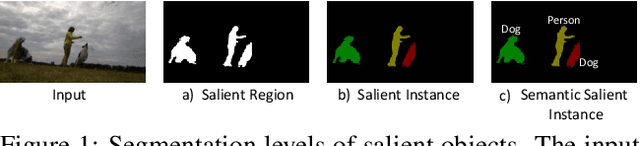
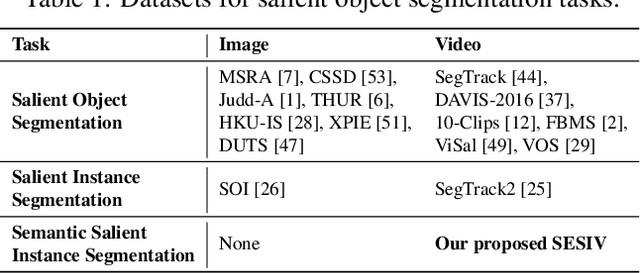

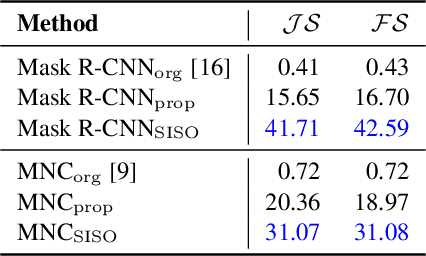
This paper pushes the envelope on salient regions in a video to decompose them into semantically meaningful components, semantic salient instances. To address this video semantic salient instance segmentation, we construct a new dataset, Semantic Salient Instance Video (SESIV) dataset. Our SESIV dataset consists of 84 high-quality video sequences with pixel-wisely per-frame ground-truth labels annotated for different segmentation tasks. We also provide a baseline for this problem, called Fork-Join Strategy (FJS). FJS is a two-stream network leveraging advantages of two different segmentation tasks, i.e., semantic instance segmentation and salient object segmentation. In FJS, we introduce a sequential fusion that combines the outputs of the two streams to have non-overlapping instances one by one. We also introduce a recurrent instance propagation to refine the shapes and semantic meanings of instances, and an identity tracking to maintain both the identity and the semantic meaning of an instance over the entire video. Experimental results demonstrated the effectiveness of our proposed FJS.
Video Salient Object Detection Using Spatiotemporal Deep Features
Jun 18, 2018
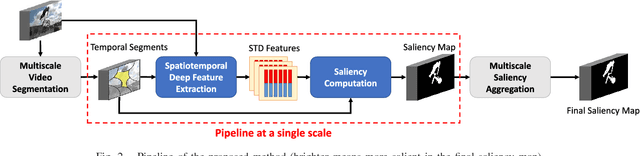
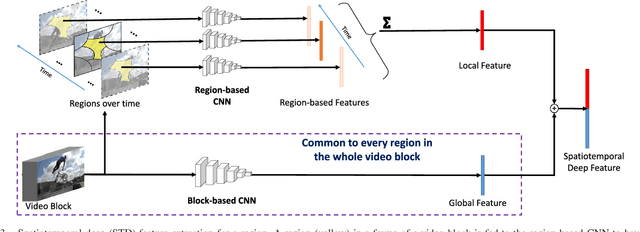
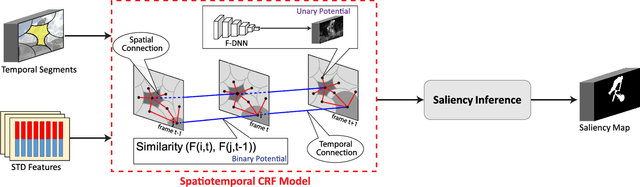
This paper presents a method for detecting salient objects in videos where temporal information in addition to spatial information is fully taken into account. Following recent reports on the advantage of deep features over conventional hand-crafted features, we propose a new set of SpatioTemporal Deep (STD) features that utilize local and global contexts over frames. We also propose new SpatioTemporal Conditional Random Field (STCRF) to compute saliency from STD features. STCRF is our extension of CRF to the temporal domain and describes the relationships among neighboring regions both in a frame and over frames. STCRF leads to temporally consistent saliency maps over frames, contributing to the accurate detection of salient objects' boundaries and noise reduction during detection. Our proposed method first segments an input video into multiple scales and then computes a saliency map at each scale level using STD features with STCRF. The final saliency map is computed by fusing saliency maps at different scale levels. Our experiments, using publicly available benchmark datasets, confirm that the proposed method significantly outperforms state-of-the-art methods. We also applied our saliency computation to the video object segmentation task, showing that our method outperforms existing video object segmentation methods.
Region-Based Multiscale Spatiotemporal Saliency for Video
Aug 04, 2017


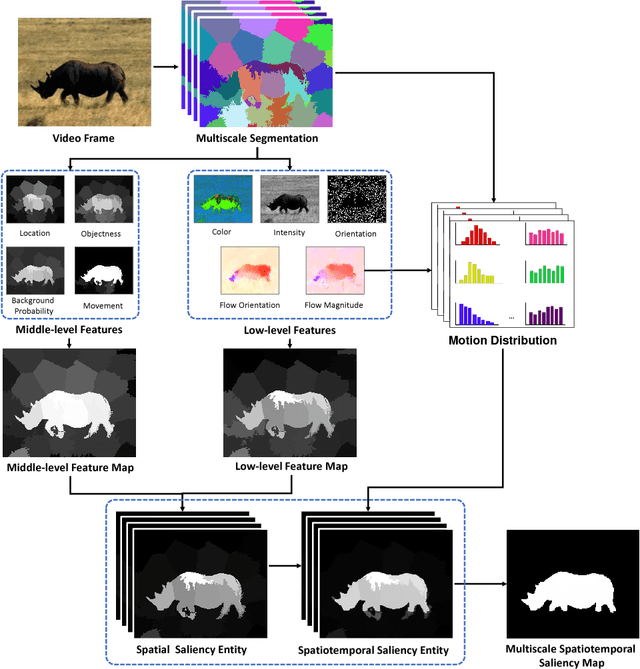
Detecting salient objects from a video requires exploiting both spatial and temporal knowledge included in the video. We propose a novel region-based multiscale spatiotemporal saliency detection method for videos, where static features and dynamic features computed from the low and middle levels are combined together. Our method utilizes such combined features spatially over each frame and, at the same time, temporally across frames using consistency between consecutive frames. Saliency cues in our method are analyzed through a multiscale segmentation model, and fused across scale levels, yielding to exploring regions efficiently. An adaptive temporal window using motion information is also developed to combine saliency values of consecutive frames in order to keep temporal consistency across frames. Performance evaluation on several popular benchmark datasets validates that our method outperforms existing state-of-the-arts.