 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI Agents for Conversational Patient Triage: Preliminary Simulation-Based Evaluation with Real-World EHR Data
Jun 04, 2025



Background: We present a Patient Simulator that leverages real world patient encounters which cover a broad range of conditions and symptoms to provide synthetic test subjects for development and testing of healthcare agentic models. The simulator provides a realistic approach to patient presentation and multi-turn conversation with a symptom-checking agent. Objectives: (1) To construct and instantiate a Patient Simulator to train and test an AI health agent, based on patient vignettes derived from real EHR data. (2) To test the validity and alignment of the simulated encounters provided by the Patient Simulator to expert human clinical providers. (3) To illustrate the evaluation framework of such an LLM system on the generated realistic, data-driven simulations -- yielding a preliminary assessment of our proposed system. Methods: We first constructed realistic clinical scenarios by deriving patient vignettes from real-world EHR encounters. These vignettes cover a variety of presenting symptoms and underlying conditions. We then evaluate the performance of the Patient Simulator as a simulacrum of a real patient encounter across over 500 different patient vignettes. We leveraged a separate AI agent to provide multi-turn questions to obtain a history of present illness. The resulting multiturn conversations were evaluated by two expert clinicians. Results: Clinicians scored the Patient Simulator as consistent with the patient vignettes in those same 97.7% of cases. The extracted case summary based on the conversation history was 99% relevant. Conclusions: We developed a methodology to incorporate vignettes derived from real healthcare patient data to build a simulation of patient responses to symptom checking agents. The performance and alignment of this Patient Simulator could be used to train and test a multi-turn conversational AI agent at scale.
Generative Large Language Models are autonomous practitioners of evidence-based medicine
Jan 05, 2024



Background: Evidence-based medicine (EBM) is fundamental to modern clinical practice, requiring clinicians to continually update their knowledge and apply the best clinical evidence in patient care. The practice of EBM faces challenges due to rapid advancements in medical research, leading to information overload for clinicians. The integration of artificial intelligence (AI), specifically Generative Large Language Models (LLMs), offers a promising solution towards managing this complexity. Methods: This study involved the curation of real-world clinical cases across various specialties, converting them into .json files for analysis. LLMs, including proprietary models like ChatGPT 3.5 and 4, Gemini Pro, and open-source models like LLaMA v2 and Mixtral-8x7B, were employed. These models were equipped with tools to retrieve information from case files and make clinical decisions similar to how clinicians must operate in the real world. Model performance was evaluated based on correctness of final answer, judicious use of tools, conformity to guidelines, and resistance to hallucinations. Results: GPT-4 was most capable of autonomous operation in a clinical setting, being generally more effective in ordering relevant investigations and conforming to clinical guidelines. Limitations were observed in terms of model ability to handle complex guidelines and diagnostic nuances. Retrieval Augmented Generation made recommendations more tailored to patients and healthcare systems. Conclusions: LLMs can be made to function as autonomous practitioners of evidence-based medicine. Their ability to utilize tooling can be harnessed to interact with the infrastructure of a real-world healthcare system and perform the tasks of patient management in a guideline directed manner. Prompt engineering may help to further enhance this potential and transform healthcare for the clinician and the patient.
Contrastive Learning Improves Critical Event Prediction in COVID-19 Patients
Jan 11, 2021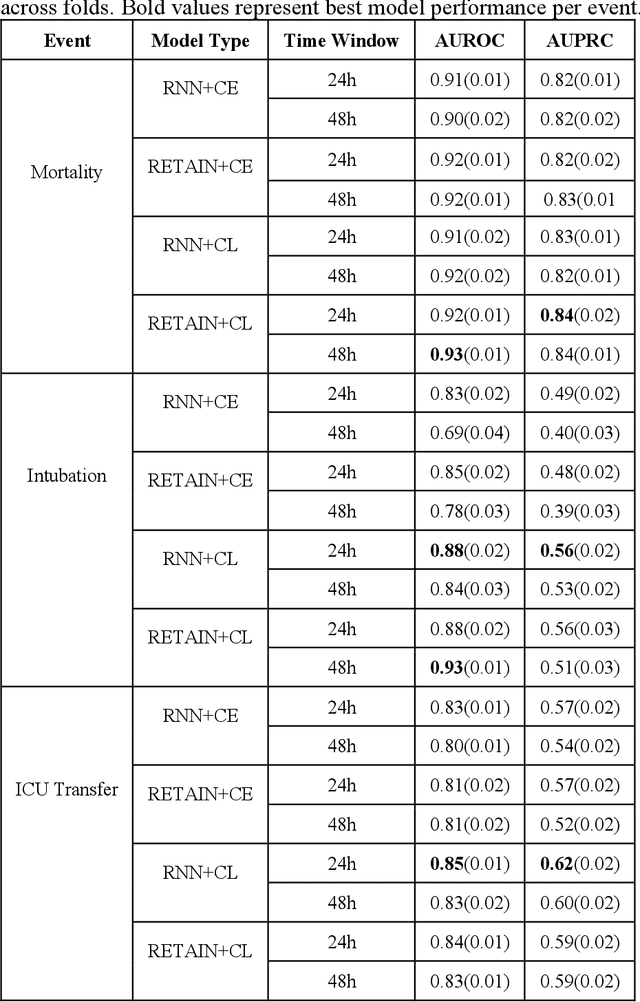
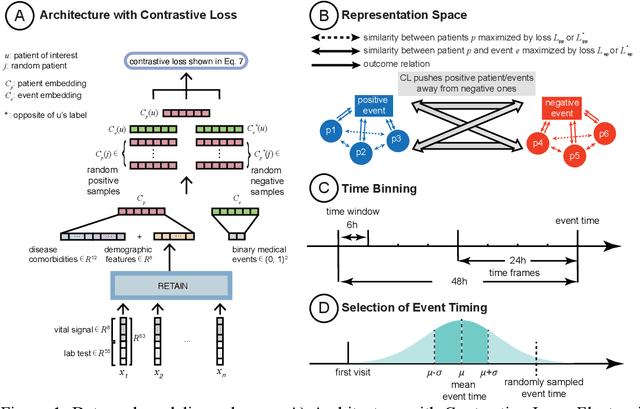
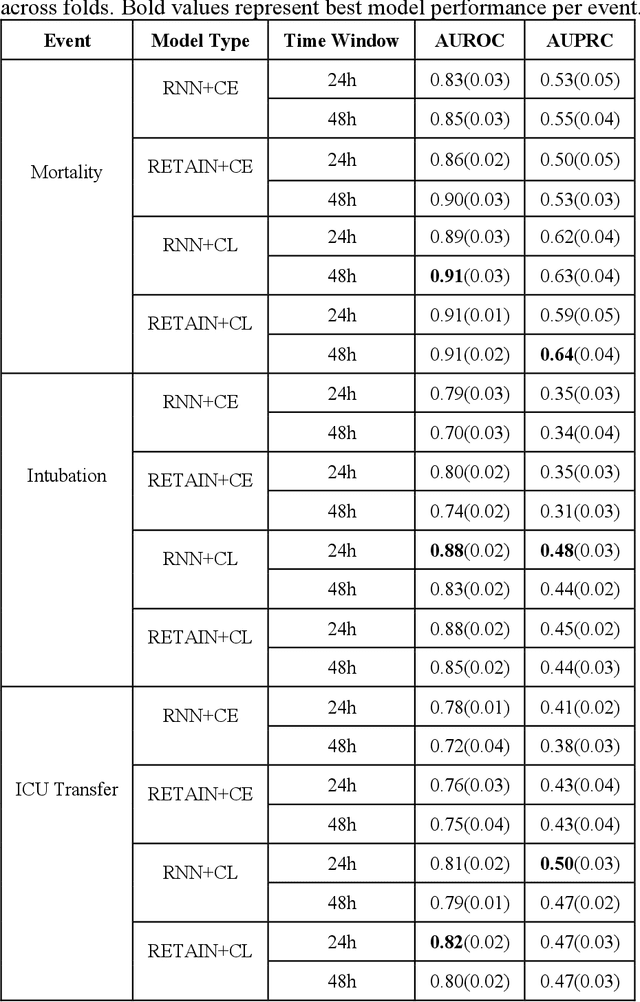
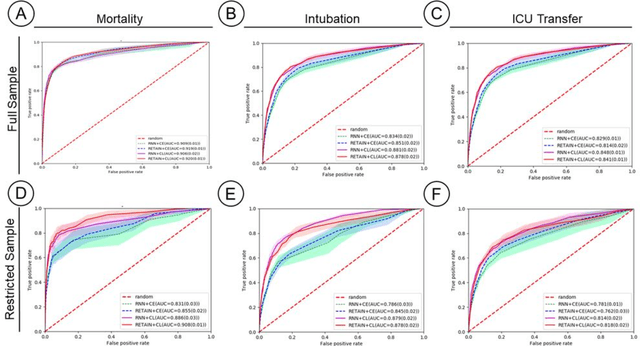
Machine Learning (ML) models typically require large-scale, balanced training data to be robust, generalizable, and effective in the context of healthcare. This has been a major issue for developing ML models for the coronavirus-disease 2019 (COVID-19) pandemic where data is highly imbalanced, particularly within electronic health records (EHR) research. Conventional approaches in ML use cross-entropy loss (CEL) that often suffers from poor margin classification. For the first time, we show that contrastive loss (CL) improves the performance of CEL especially for imbalanced EHR data and the related COVID-19 analyses. This study has been approved by the Institutional Review Board at the Icahn School of Medicine at Mount Sinai. We use EHR data from five hospitals within the Mount Sinai Health System (MSHS) to predict mortality, intubation, and intensive care unit (ICU) transfer in hospitalized COVID-19 patients over 24 and 48 hour time windows. We train two sequential architectures (RNN and RETAIN) using two loss functions (CEL and CL). Models are tested on full sample data set which contain all available data and restricted data set to emulate higher class imbalance.CL models consistently outperform CEL models with the restricted data set on these tasks with differences ranging from 0.04 to 0.15 for AUPRC and 0.05 to 0.1 for AUROC. For the restricted sample, only the CL model maintains proper clustering and is able to identify important features, such as pulse oximetry. CL outperforms CEL in instances of severe class imbalance, on three EHR outcomes with respect to three performance metrics: predictive power, clustering, and feature importance. We believe that the developed CL framework can be expanded and used for EHR ML work in general.