 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI Agents for Conversational Patient Triage: Preliminary Simulation-Based Evaluation with Real-World EHR Data
Jun 04, 2025



Background: We present a Patient Simulator that leverages real world patient encounters which cover a broad range of conditions and symptoms to provide synthetic test subjects for development and testing of healthcare agentic models. The simulator provides a realistic approach to patient presentation and multi-turn conversation with a symptom-checking agent. Objectives: (1) To construct and instantiate a Patient Simulator to train and test an AI health agent, based on patient vignettes derived from real EHR data. (2) To test the validity and alignment of the simulated encounters provided by the Patient Simulator to expert human clinical providers. (3) To illustrate the evaluation framework of such an LLM system on the generated realistic, data-driven simulations -- yielding a preliminary assessment of our proposed system. Methods: We first constructed realistic clinical scenarios by deriving patient vignettes from real-world EHR encounters. These vignettes cover a variety of presenting symptoms and underlying conditions. We then evaluate the performance of the Patient Simulator as a simulacrum of a real patient encounter across over 500 different patient vignettes. We leveraged a separate AI agent to provide multi-turn questions to obtain a history of present illness. The resulting multiturn conversations were evaluated by two expert clinicians. Results: Clinicians scored the Patient Simulator as consistent with the patient vignettes in those same 97.7% of cases. The extracted case summary based on the conversation history was 99% relevant. Conclusions: We developed a methodology to incorporate vignettes derived from real healthcare patient data to build a simulation of patient responses to symptom checking agents. The performance and alignment of this Patient Simulator could be used to train and test a multi-turn conversational AI agent at scale.
Identifying Risk of Opioid Use Disorder for Patients Taking Opioid Medications with Deep Learning
Oct 09, 2020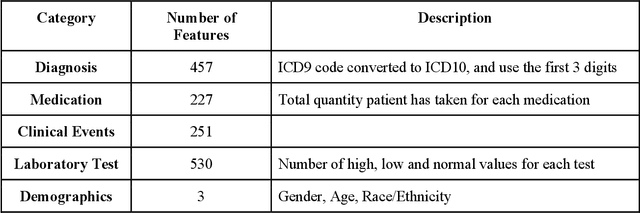
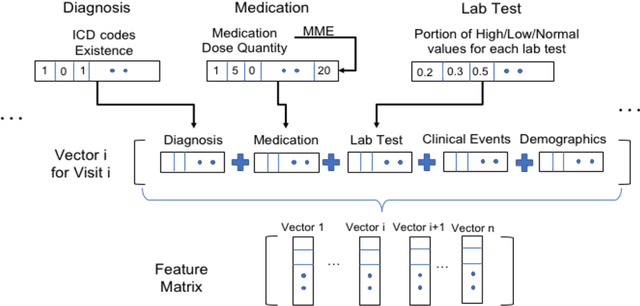
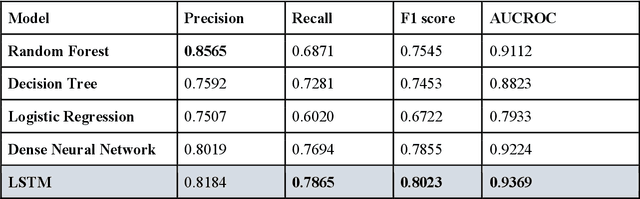
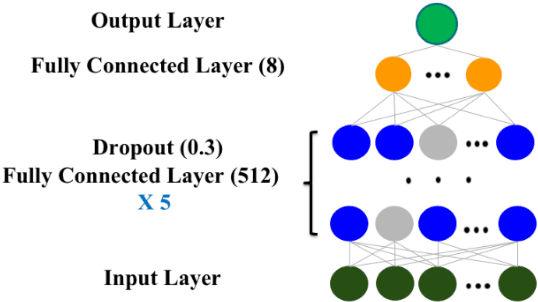
The United States is experiencing an opioid epidemic, and there were more than 10 million opioid misusers aged 12 or older each year. Identifying patients at high risk of Opioid Use Disorder (OUD) can help to make early clinical interventions to reduce the risk of OUD. Our goal is to predict OUD patients among opioid prescription users through analyzing electronic health records with machine learning and deep learning methods. This will help us to better understand the diagnoses of OUD, providing new insights on opioid epidemic. Electronic health records of patients who have been prescribed with medications containing active opioid ingredients were extracted from Cerner Health Facts database between January 1, 2008 and December 31, 2017. Long Short-Term Memory (LSTM) models were applied to predict opioid use disorder risk in the future based on recent five encounters, and compared to Logistic Regression, Random Forest, Decision Tree and Dense Neural Network. Prediction performance was assessed using F-1 score, precision, recall, and AUROC. Our temporal deep learning model provided promising prediction results which outperformed other methods, with a F1 score of 0.8023 and AUCROC of 0.9369. The model can identify OUD related medications and vital signs as important features for the prediction. LSTM based temporal deep learning model is effective on predicting opioid use disorder using a patient past history of electronic health records, with minimal domain knowledge. It has potential to improve clinical decision support for early intervention and prevention to combat the opioid epidemic.
Disease phenotyping using deep learning: A diabetes case study
Nov 28, 2018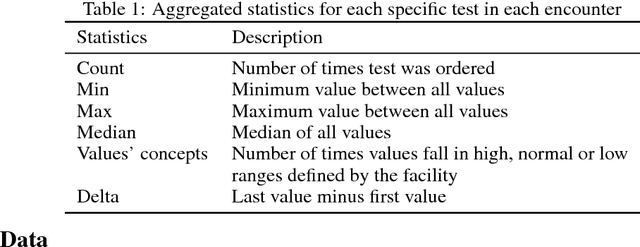
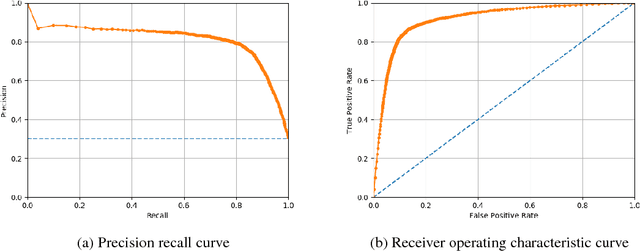
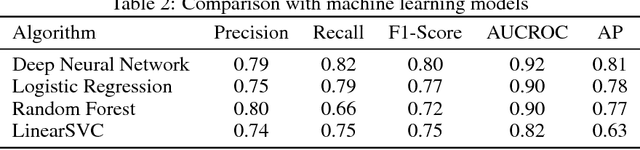
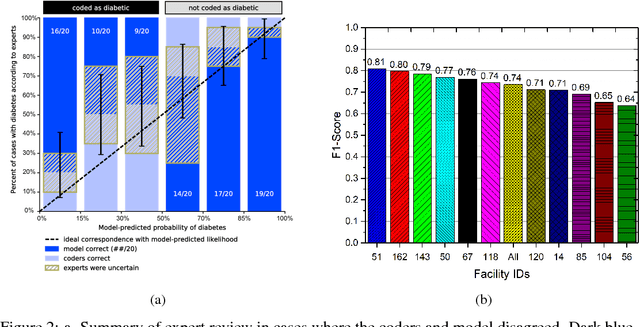
Characterization of a patient clinical phenotype is central to biomedical informatics. ICD codes, assigned to inpatient encounters by coders, is important for population health and cohort discovery when clinical information is limited. While ICD codes are assigned to patients by professionals trained and certified in coding there is substantial variability in coding. We present a methodology that uses deep learning methods to model coder decision making and that predicts ICD codes. Our approach predicts codes based on demographics, lab results, and medications, as well as codes from previous encounters. We are able to predict existing codes with high accuracy for all three of the test cases we investigated: diabetes, acute renal failure, and chronic kidney disease. We employed a panel of clinicians, in a blinded manner, to assess ground truth and compared the predictions of coders, model and clinicians. When disparities between the model prediction and coder assigned codes were reviewed, our model outperformed coder assigned ICD codes.