 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWay Off-Policy Batch Deep Reinforcement Learning of Implicit Human Preferences in Dialog
Jul 08, 2019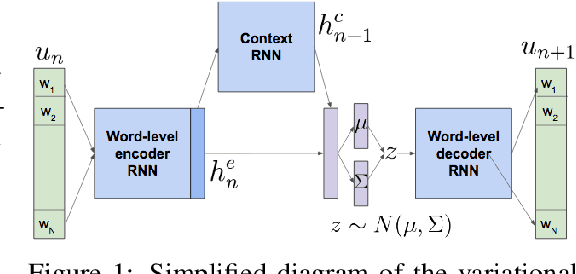
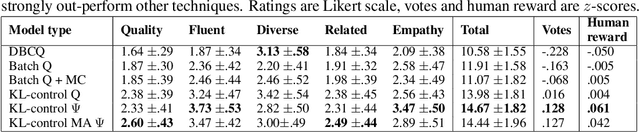

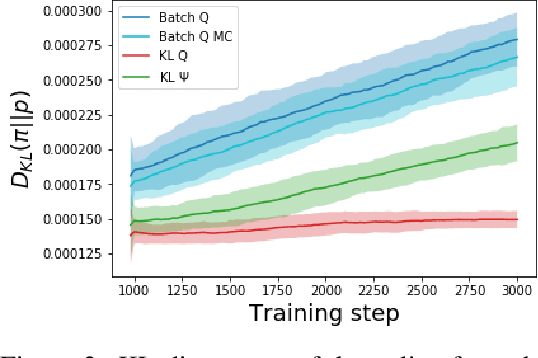
Most deep reinforcement learning (RL) systems are not able to learn effectively from off-policy data, especially if they cannot explore online in the environment. These are critical shortcomings for applying RL to real-world problems where collecting data is expensive, and models must be tested offline before being deployed to interact with the environment -- e.g. systems that learn from human interaction. Thus, we develop a novel class of off-policy batch RL algorithms, which are able to effectively learn offline, without exploring, from a fixed batch of human interaction data. We leverage models pre-trained on data as a strong prior, and use KL-control to penalize divergence from this prior during RL training. We also use dropout-based uncertainty estimates to lower bound the target Q-values as a more efficient alternative to Double Q-Learning. The algorithms are tested on the problem of open-domain dialog generation -- a challenging reinforcement learning problem with a 20,000-dimensional action space. Using our Way Off-Policy algorithm, we can extract multiple different reward functions post-hoc from collected human interaction data, and learn effectively from all of these. We test the real-world generalization of these systems by deploying them live to converse with humans in an open-domain setting, and demonstrate that our algorithm achieves significant improvements over prior methods in off-policy batch RL.
Approximating Interactive Human Evaluation with Self-Play for Open-Domain Dialog Systems
Jun 21, 2019
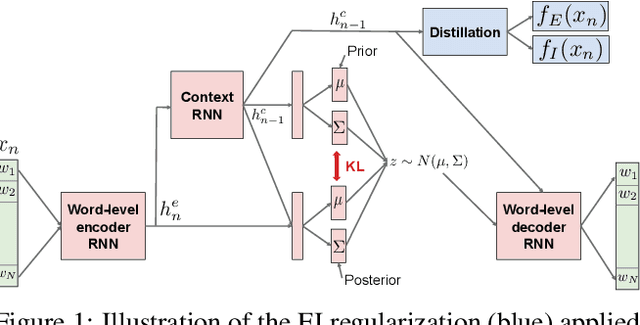
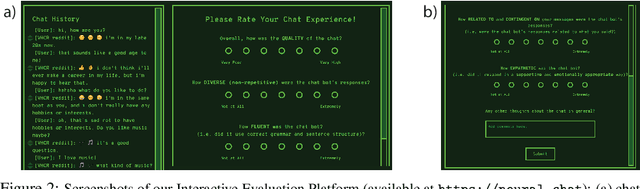
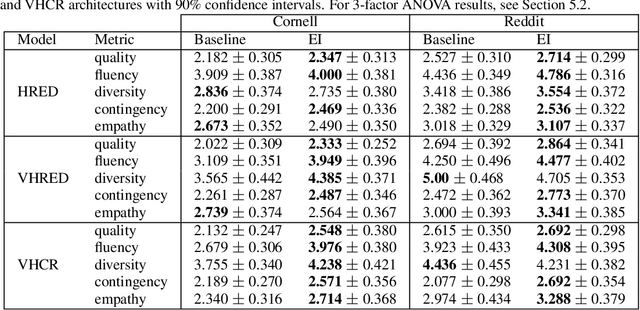
Building an open-domain conversational agent is a challenging problem. Current evaluation methods, mostly post-hoc judgments of single-turn evaluation, do not capture conversation quality in a realistic interactive context. In this paper, we investigate interactive human evaluation and provide evidence for its necessity; we then introduce a novel, model-agnostic, and dataset-agnostic method to approximate it. In particular, we propose a self-play scenario where the dialog system talks to itself and we calculate a combination of proxies such as sentiment and semantic coherence on the conversation trajectory. We show that this metric is capable of capturing the human-rated quality of a dialog model better than any automated metric known to-date, achieving a significant Pearson correlation (r>.7, p<.05). To investigate the strengths of this novel metric and interactive evaluation in comparison to state-of-the-art metrics and one-turn evaluation, we perform extended experiments with a set of models, including several that make novel improvements to recent hierarchical dialog generation architectures through sentiment and semantic knowledge distillation on the utterance level. Finally, we open-source the interactive evaluation platform we built and the dataset we collected to allow researchers to efficiently deploy and evaluate generative dialog models.
Places: An Image Database for Deep Scene Understanding
Oct 06, 2016
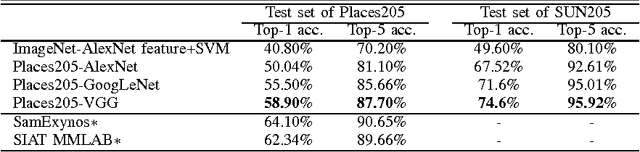

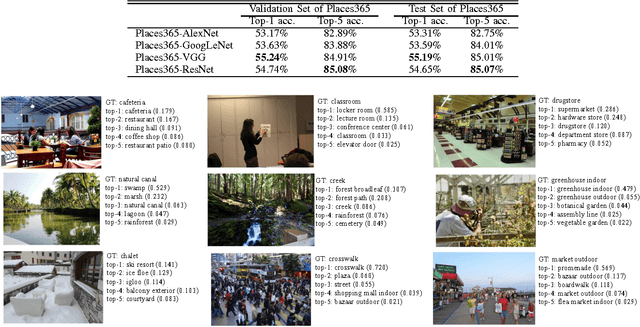
The rise of multi-million-item dataset initiatives has enabled data-hungry machine learning algorithms to reach near-human semantic classification at tasks such as object and scene recognition. Here we describe the Places Database, a repository of 10 million scene photographs, labeled with scene semantic categories and attributes, comprising a quasi-exhaustive list of the types of environments encountered in the world. Using state of the art Convolutional Neural Networks, we provide impressive baseline performances at scene classification. With its high-coverage and high-diversity of exemplars, the Places Database offers an ecosystem to guide future progress on currently intractable visual recognition problems.
Learning Deep Features for Discriminative Localization
Dec 14, 2015



In this work, we revisit the global average pooling layer proposed in [13], and shed light on how it explicitly enables the convolutional neural network to have remarkable localization ability despite being trained on image-level labels. While this technique was previously proposed as a means for regularizing training, we find that it actually builds a generic localizable deep representation that can be applied to a variety of tasks. Despite the apparent simplicity of global average pooling, we are able to achieve 37.1% top-5 error for object localization on ILSVRC 2014, which is remarkably close to the 34.2% top-5 error achieved by a fully supervised CNN approach. We demonstrate that our network is able to localize the discriminative image regions on a variety of tasks despite not being trained for them
Speeding Up Neural Networks for Large Scale Classification using WTA Hashing
Apr 28, 2015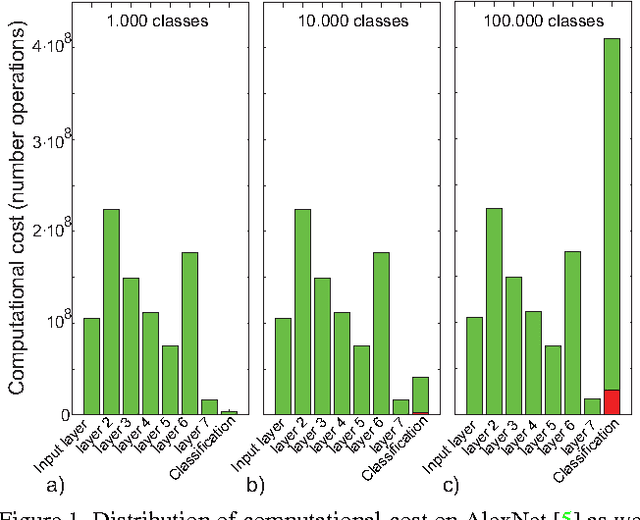
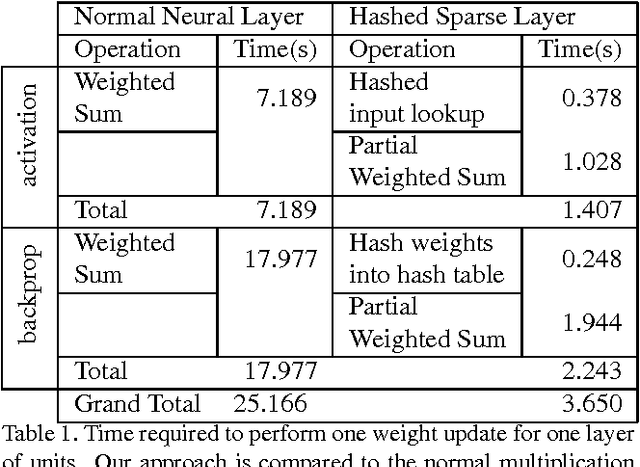
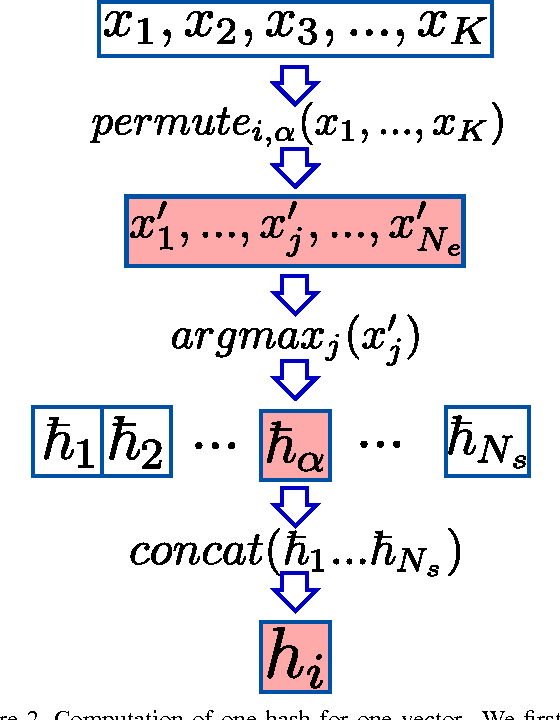
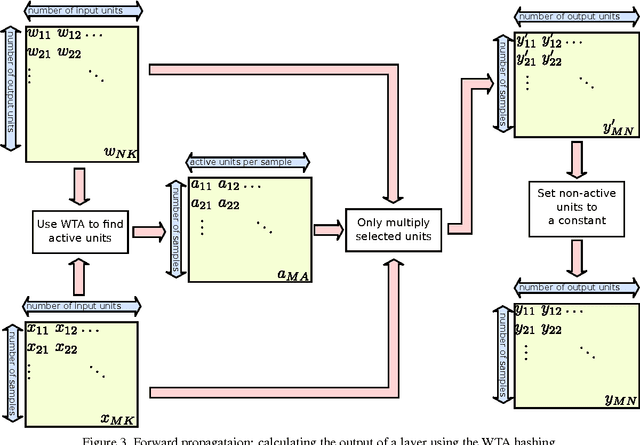
In this paper we propose to use the Winner Takes All hashing technique to speed up forward propagation and backward propagation in fully connected layers in convolutional neural networks. The proposed technique reduces significantly the computational complexity, which in turn, allows us to train layers with a large number of kernels with out the associated time penalty. As a consequence we are able to train convolutional neural network on a very large number of output classes with only a small increase in the computational cost. To show the effectiveness of the technique we train a new output layer on a pretrained network using both the regular multiplicative approach and our proposed hashing methodology. Our results showed no drop in performance and demonstrate, with our implementation, a 7 fold speed up during the training.
Object Detectors Emerge in Deep Scene CNNs
Apr 15, 2015


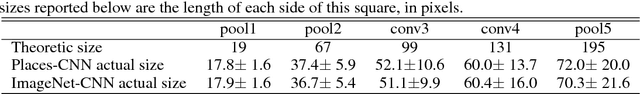
With the success of new computational architectures for visual processing, such as convolutional neural networks (CNN) and access to image databases with millions of labeled examples (e.g., ImageNet, Places), the state of the art in computer vision is advancing rapidly. One important factor for continued progress is to understand the representations that are learned by the inner layers of these deep architectures. Here we show that object detectors emerge from training CNNs to perform scene classification. As scenes are composed of objects, the CNN for scene classification automatically discovers meaningful objects detectors, representative of the learned scene categories. With object detectors emerging as a result of learning to recognize scenes, our work demonstrates that the same network can perform both scene recognition and object localization in a single forward-pass, without ever having been explicitly taught the notion of objects.
Are all training examples equally valuable?
Nov 25, 2013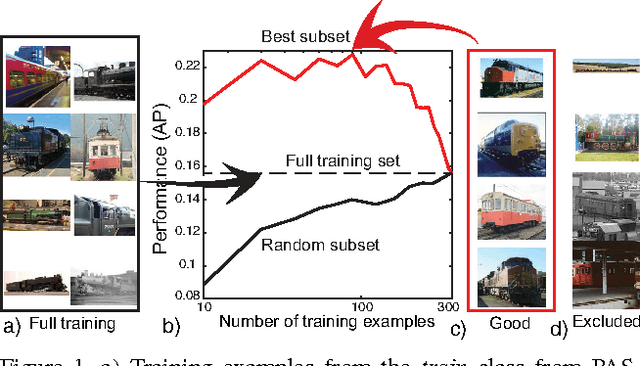

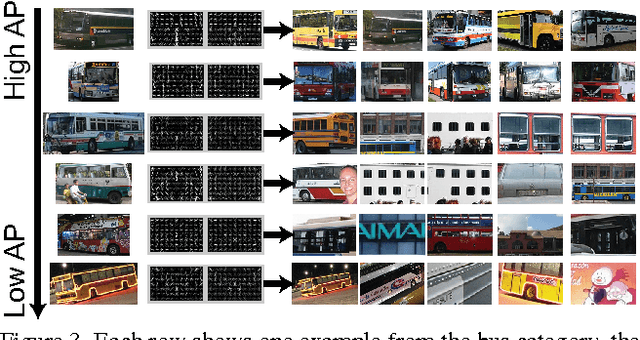
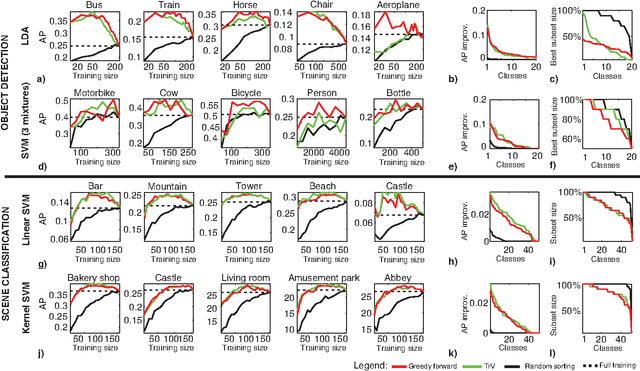
When learning a new concept, not all training examples may prove equally useful for training: some may have higher or lower training value than others. The goal of this paper is to bring to the attention of the vision community the following considerations: (1) some examples are better than others for training detectors or classifiers, and (2) in the presence of better examples, some examples may negatively impact performance and removing them may be beneficial. In this paper, we propose an approach for measuring the training value of an example, and use it for ranking and greedily sorting examples. We test our methods on different vision tasks, models, datasets and classifiers. Our experiments show that the performance of current state-of-the-art detectors and classifiers can be improved when training on a subset, rather than the whole training set.