 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGandalf the Red: Adaptive Security for LLMs
Jan 14, 2025Current evaluations of defenses against prompt attacks in large language model (LLM) applications often overlook two critical factors: the dynamic nature of adversarial behavior and the usability penalties imposed on legitimate users by restrictive defenses. We propose D-SEC (Dynamic Security Utility Threat Model), which explicitly separates attackers from legitimate users, models multi-step interactions, and rigorously expresses the security-utility in an optimizable form. We further address the shortcomings in existing evaluations by introducing Gandalf, a crowd-sourced, gamified red-teaming platform designed to generate realistic, adaptive attack datasets. Using Gandalf, we collect and release a dataset of 279k prompt attacks. Complemented by benign user data, our analysis reveals the interplay between security and utility, showing that defenses integrated in the LLM (e.g., system prompts) can degrade usability even without blocking requests. We demonstrate that restricted application domains, defense-in-depth, and adaptive defenses are effective strategies for building secure and useful LLM applications. Code is available at \href{https://github.com/lakeraai/dsec-gandalf}{\texttt{https://github.com/lakeraai/dsec-gandalf}}.
Recommendations on test datasets for evaluating AI solutions in pathology
Apr 21, 2022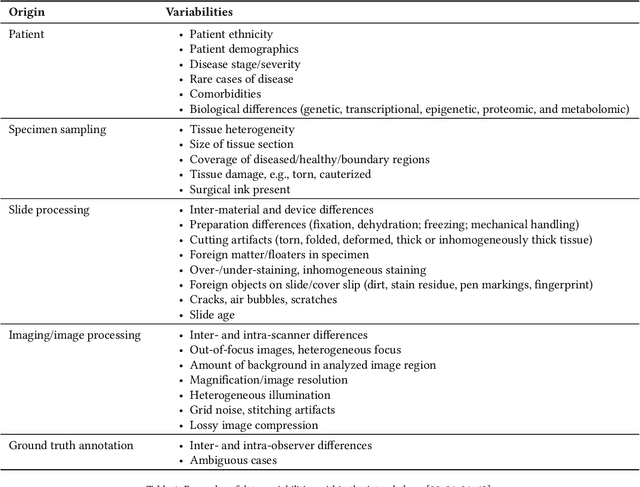
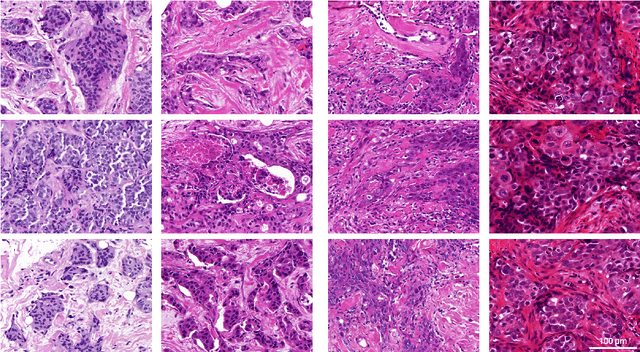

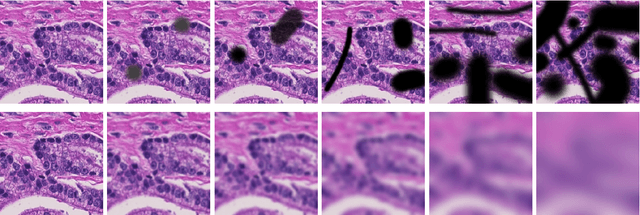
Artificial intelligence (AI) solutions that automatically extract information from digital histology images have shown great promise for improving pathological diagnosis. Prior to routine use, it is important to evaluate their predictive performance and obtain regulatory approval. This assessment requires appropriate test datasets. However, compiling such datasets is challenging and specific recommendations are missing. A committee of various stakeholders, including commercial AI developers, pathologists, and researchers, discussed key aspects and conducted extensive literature reviews on test datasets in pathology. Here, we summarize the results and derive general recommendations for the collection of test datasets. We address several questions: Which and how many images are needed? How to deal with low-prevalence subsets? How can potential bias be detected? How should datasets be reported? What are the regulatory requirements in different countries? The recommendations are intended to help AI developers demonstrate the utility of their products and to help regulatory agencies and end users verify reported performance measures. Further research is needed to formulate criteria for sufficiently representative test datasets so that AI solutions can operate with less user intervention and better support diagnostic workflows in the future.