 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Monosemanticity: Extracting Interpretable Features from Claude 3 Sonnet
May 28, 2026We demonstrate that sparse autoencoders can extract interpretable features from Claude 3 Sonnet, a production-scale language model, addressing the open question of whether dictionary learning methods scale beyond small transformers. We trained sparse autoencoders with up to 34 million features on the model's middle layer residual stream, using scaling laws to guide hyperparameter selection. The resulting features are multilingual and multimodal (generalizing to images despite text-only training), respond to both concrete instances and abstract discussions of concepts, and can be used to steer model behavior in ways consistent with their interpretations. We find features corresponding to famous entities and locations, as well as more abstract concepts like sarcasm or errors in code. We also identify features relevant to ways in which language models might cause harm--including features representing deception, power-seeking, sycophancy, and bias--and show that these causally influence model outputs when manipulated. Additionally, we conduct analyses of feature interpretability, geometry, and computational function. However, significant limitations remain: our suite of features is incomplete, and we lack rigorous methods for evaluating whether our features faithfully capture model computations.
Inherently Interpretable Sparse Word Embeddings through Sparse Coding
Apr 08, 2020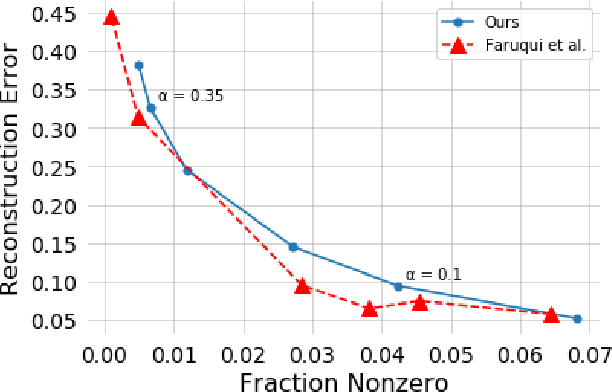
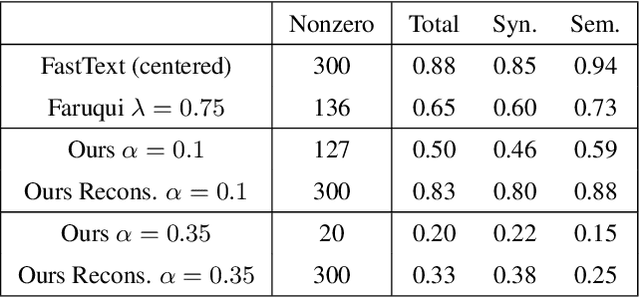
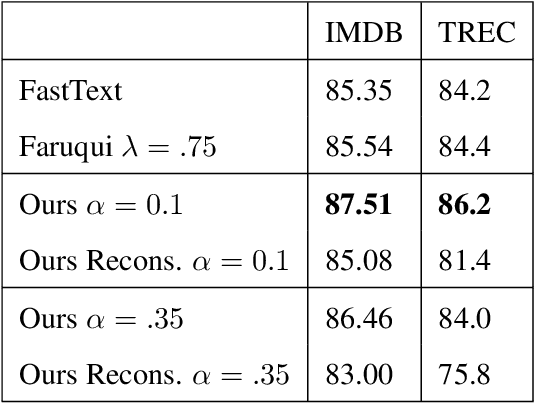

Word embeddings are a powerful natural language processing technique, but they are extremely difficult to interpret. In order to create more interpretable word embeddings, we transform pretrained dense word embeddings into sparse embeddings. These new embeddings are inherently interpretable: each of their dimensions are created from and represent a natural language word or specific syntactic concept. We construct these embeddings through sparse coding, where each vector in the basis set is itself a word embedding. We show that models trained using these sparse embeddings can achieve good performance and are extremely interpretable.
Exploring Sentence Vector Spaces through Automatic Summarization
Oct 16, 2018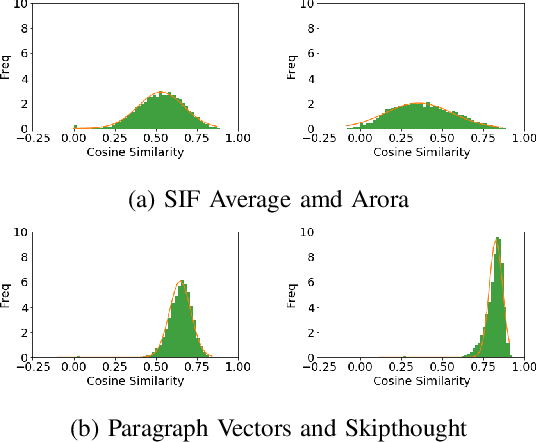
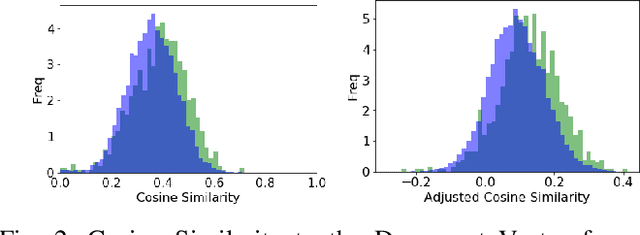
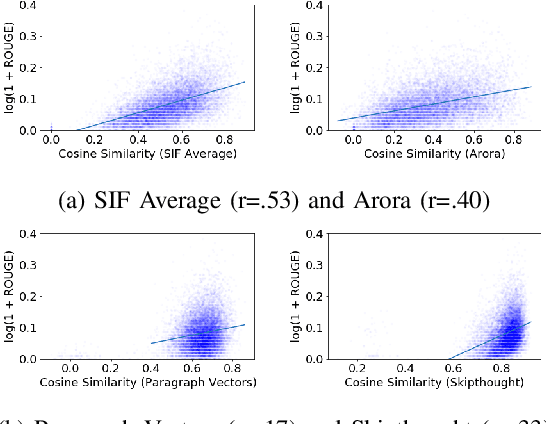
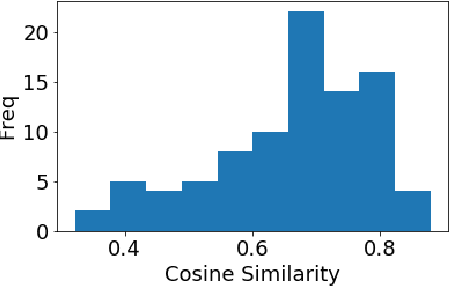
Given vector representations for individual words, it is necessary to compute vector representations of sentences for many applications in a compositional manner, often using artificial neural networks. Relatively little work has explored the internal structure and properties of such sentence vectors. In this paper, we explore the properties of sentence vectors in the context of automatic summarization. In particular, we show that cosine similarity between sentence vectors and document vectors is strongly correlated with sentence importance and that vector semantics can identify and correct gaps between the sentences chosen so far and the document. In addition, we identify specific dimensions which are linked to effective summaries. To our knowledge, this is the first time specific dimensions of sentence embeddings have been connected to sentence properties. We also compare the features of different methods of sentence embeddings. Many of these insights have applications in uses of sentence embeddings far beyond summarization.