 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWord Interdependence Exposes How LSTMs Compose Representations
Apr 27, 2020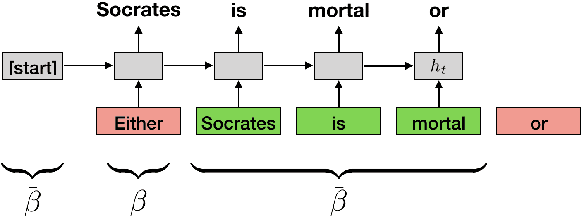
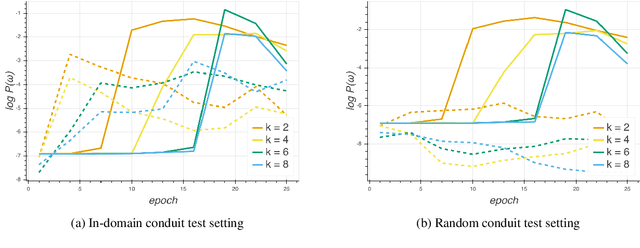
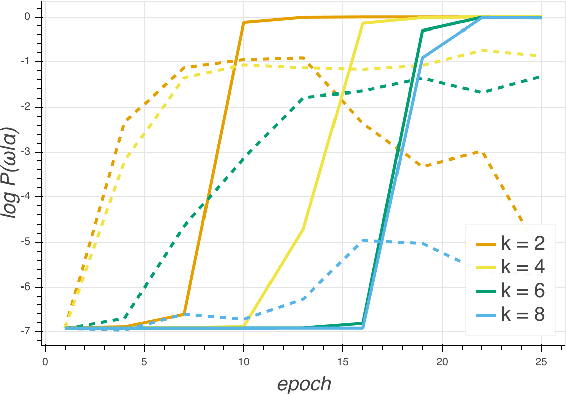
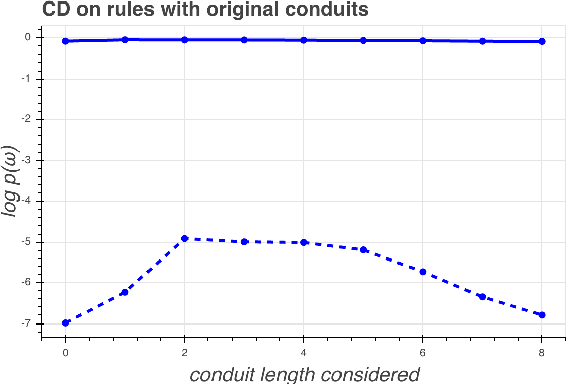
Recent work in NLP shows that LSTM language models capture compositional structure in language data. For a closer look at how these representations are composed hierarchically, we present a novel measure of interdependence between word meanings in an LSTM, based on their interactions at the internal gates. To explore how compositional representations arise over training, we conduct simple experiments on synthetic data, which illustrate our measure by showing how high interdependence can hurt generalization. These synthetic experiments also illustrate a specific hypothesis about how hierarchical structures are discovered over the course of training: that parent constituents rely on effective representations of their children, rather than on learning long-range relations independently. We further support this measure with experiments on English language data, where interdependence is higher for more closely syntactically linked word pairs.
How to Evaluate Word Representations of Informal Domain?
Nov 13, 2019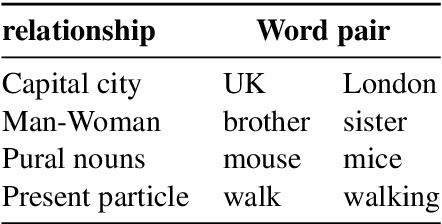
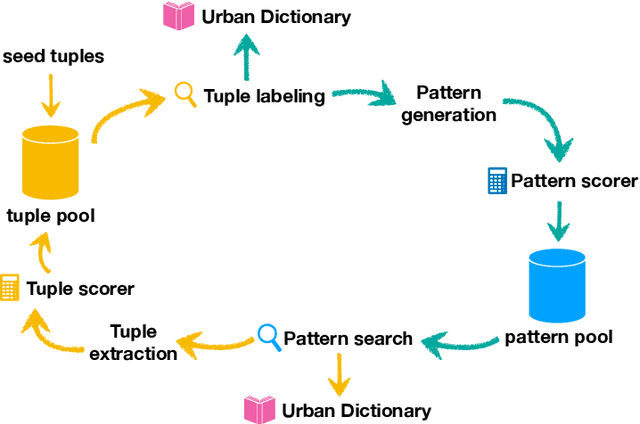


Diverse word representations have surged in most state-of-the-art natural language processing (NLP) applications. Nevertheless, how to efficiently evaluate such word embeddings in the informal domain such as Twitter or forums, remains an ongoing challenge due to the lack of sufficient evaluation dataset. We derived a large list of variant spelling pairs from UrbanDictionary with the automatic approaches of weakly-supervised pattern-based bootstrapping and self-training linear-chain conditional random field (CRF). With these extracted relation pairs we promote the odds of eliding the text normalization procedure of traditional NLP pipelines and directly adopting representations of non-standard words in the informal domain. Our code is available.
Semantic Graph Parsing with Recurrent Neural Network DAG Grammars
Oct 20, 2019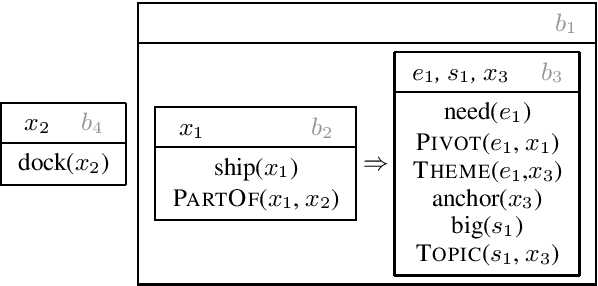
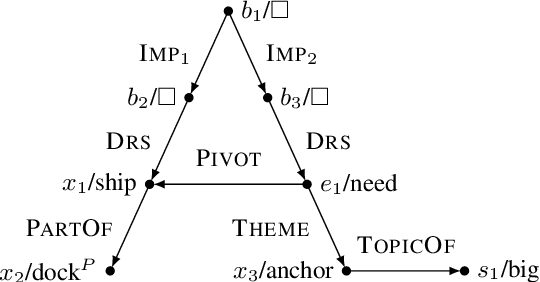

Semantic parses are directed acyclic graphs (DAGs), so semantic parsing should be modeled as graph prediction. But predicting graphs presents difficult technical challenges, so it is simpler and more common to predict the linearized graphs found in semantic parsing datasets using well-understood sequence models. The cost of this simplicity is that the predicted strings may not be well-formed graphs. We present recurrent neural network DAG grammars, a graph-aware sequence model that ensures only well-formed graphs while sidestepping many difficulties in graph prediction. We test our model on the Parallel Meaning Bank---a multilingual semantic graphbank. Our approach yields competitive results in English and establishes the first results for German, Italian and Dutch.
A systematic comparison of methods for low-resource dependency parsing on genuinely low-resource languages
Sep 06, 2019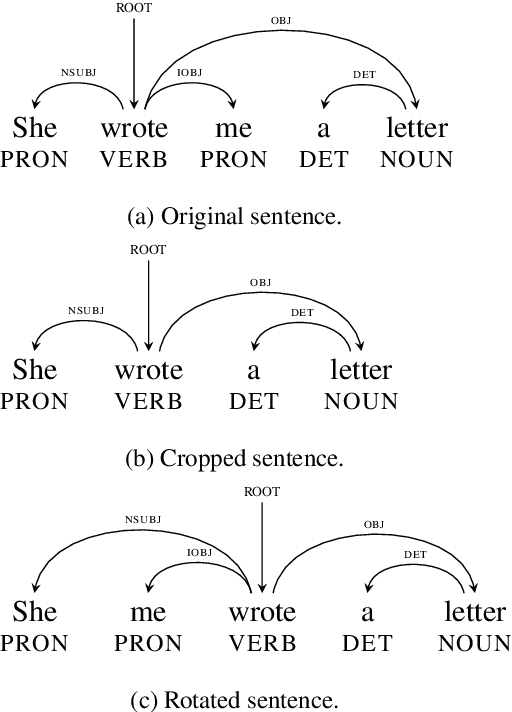
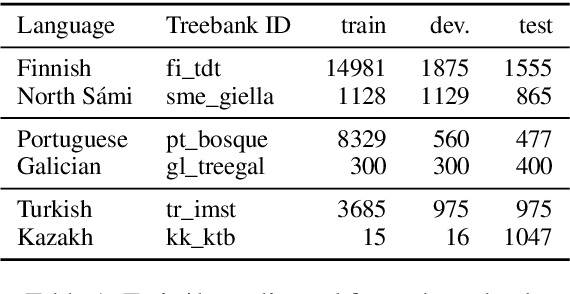
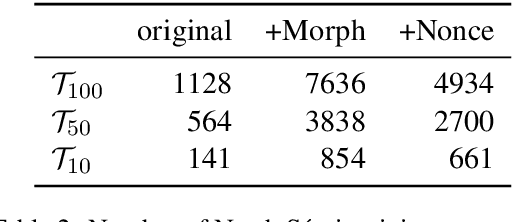
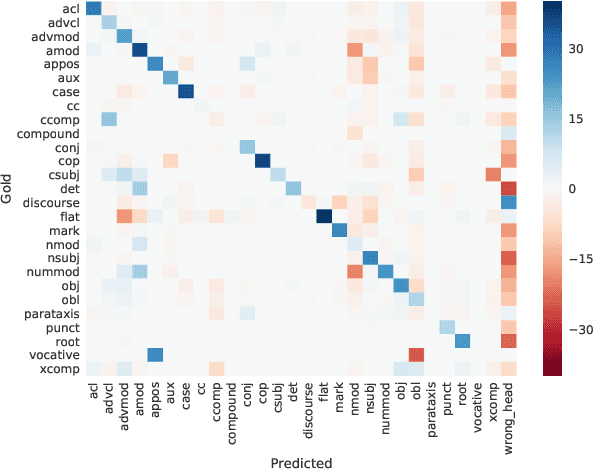
Parsers are available for only a handful of the world's languages, since they require lots of training data. How far can we get with just a small amount of training data? We systematically compare a set of simple strategies for improving low-resource parsers: data augmentation, which has not been tested before; cross-lingual training; and transliteration. Experimenting on three typologically diverse low-resource languages---North S\'ami, Galician, and Kazah---We find that (1) when only the low-resource treebank is available, data augmentation is very helpful; (2) when a related high-resource treebank is available, cross-lingual training is helpful and complements data augmentation; and (3) when the high-resource treebank uses a different writing system, transliteration into a shared orthographic spaces is also very helpful.
Classifying topics in speech when all you have is crummy translations
Aug 29, 2019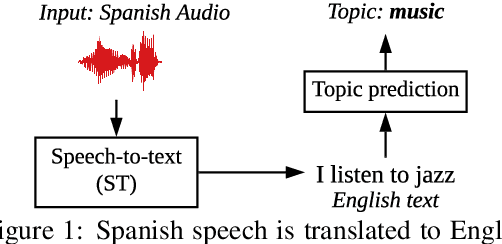

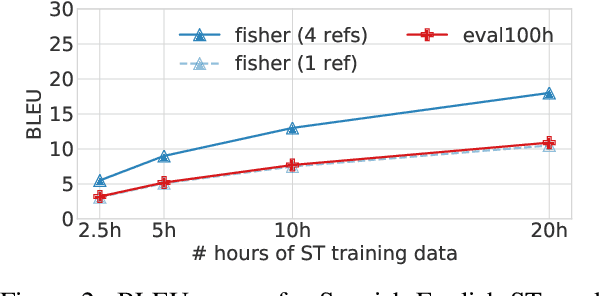

Given a large amount of unannotated speech in a language with few resources, can we classify the speech utterances by topic? We show that this is possible if text translations are available for just a small amount of speech (less than 20 hours), using a recent model for direct speech-to-text translation. While the translations are poor, they are still good enough to correctly classify 1-minute speech segments over 70% of the time - a 20% improvement over a majority-class baseline. Such a system might be useful for humanitarian applications like crisis response, where incoming speech must be quickly assessed for further action.
Sparsity Emerges Naturally in Neural Language Models
Jul 22, 2019
Concerns about interpretability, computational resources, and principled inductive priors have motivated efforts to engineer sparse neural models for NLP tasks. If sparsity is important for NLP, might well-trained neural models naturally become roughly sparse? Using the Taxi-Euclidean norm to measure sparsity, we find that frequent input words are associated with concentrated or sparse activations, while frequent target words are associated with dispersed activations but concentrated gradients. We find that gradients associated with function words are more concentrated than the gradients of content words, even controlling for word frequency.
Understanding Learning Dynamics Of Language Models with SVCCA
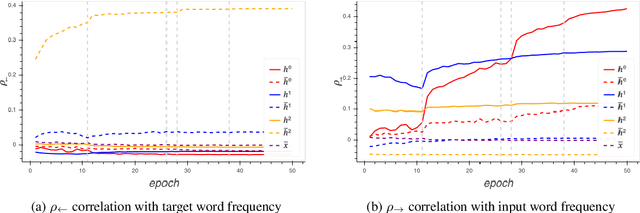
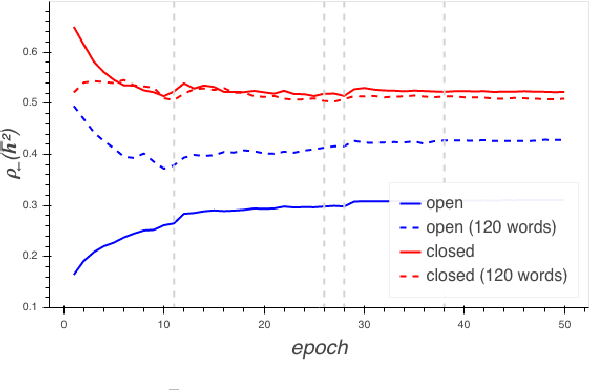
Nov 01, 2018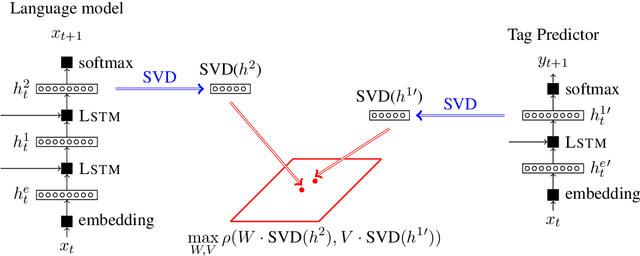

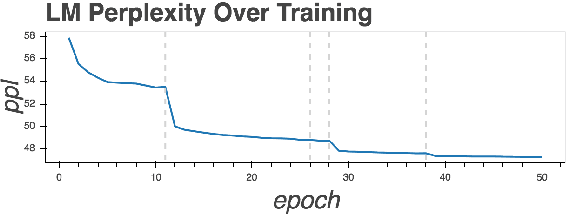

Recent work has demonstrated that neural language models encode linguistic structure implicitly in a number of ways. However, existing research has not shed light on the process by which this structure is acquired during training. We use SVCCA as a tool for understanding how a language model is implicitly predicting a variety of word cluster tags. We present experiments suggesting that a single recurrent layer of a language model learns linguistic structure in phases. We find, for example, that a language model naturally stabilizes its representation of part of speech earlier than it learns semantic and topic information.
The problem with probabilistic DAG automata for semantic graphs
Oct 29, 2018
Semantic representations in the form of directed acyclic graphs (DAGs) have been introduced in recent years, and to model them, we need probabilistic models of DAGs. One model that has attracted some attention is the DAG automaton, but it has not been studied as a probabilistic model. We show that some DAG automata cannot be made into useful probabilistic models by the nearly universal strategy of assigning weights to transitions. The problem affects single-rooted, multi-rooted, and unbounded-degree variants of DAG automata, and appears to be pervasive. It does not affect planar variants, but these are problematic for other reasons.
Pre-training on high-resource speech recognition improves low-resource speech-to-text translation
Sep 05, 2018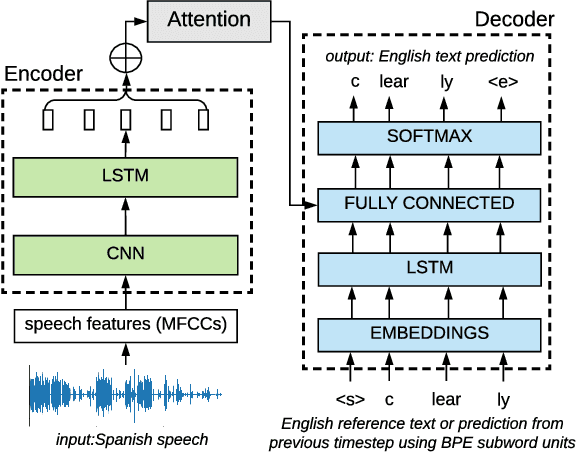

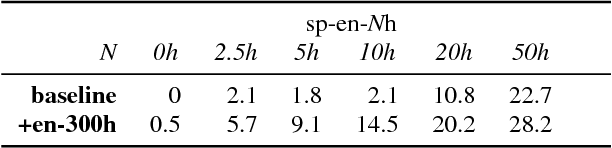
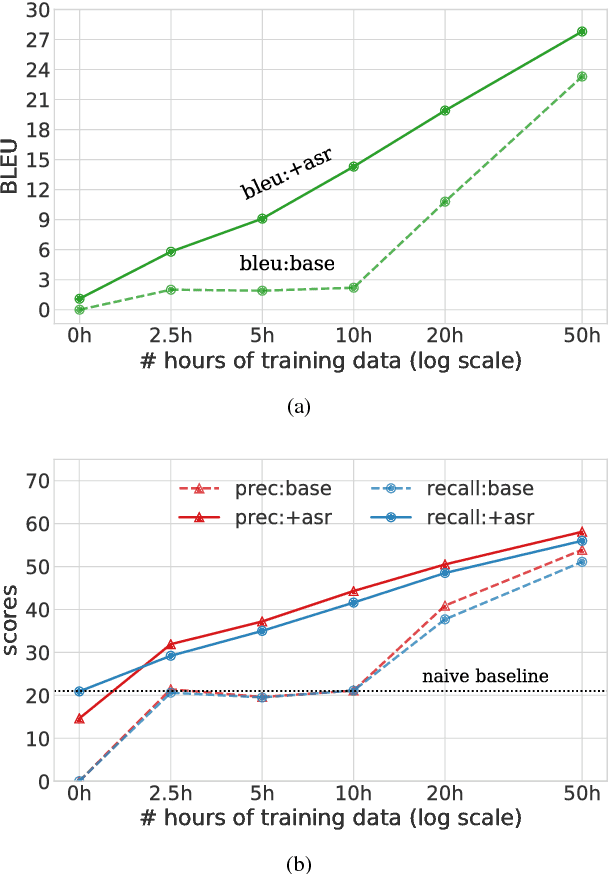
We present a simple approach to improve direct speech-to-text translation (ST) when the source language is low-resource: we pre-train the model on a high-resource automatic speech recognition (ASR) task, and then fine-tune its parameters for ST. We demonstrate that our approach is effective by pre-training on 300 hours of English ASR data to improve Spanish-English ST from 10.8 to 20.2 BLEU when only 20 hours of Spanish-English ST training data is available. Through an ablation study, we find that the pre-trained encoder (acoustic model) accounts for most of the improvement, which is surprising since the shared language in these tasks is the target language (text), and not the source language (audio). Applying this insight, we show that pre-training on ASR helps ST even when the ASR language differs from both source and target ST languages: pre-training on French ASR also improves Spanish-English ST. Finally, we show that the approach improves a true low-resource task: pre-training on a combination of English ASR and French ASR improves Mboshi-French ST, where only 4 hours of data are available, from 3.5 to 7.1 BLEU.
Indicatements that character language models learn English morpho-syntactic units and regularities
Aug 31, 2018
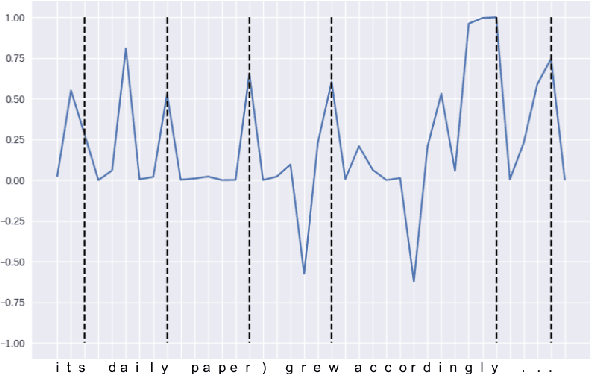
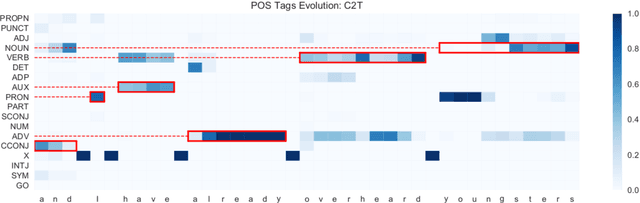
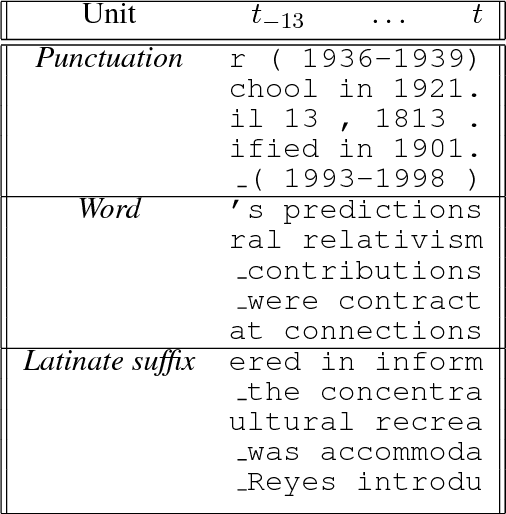
Character language models have access to surface morphological patterns, but it is not clear whether or how they learn abstract morphological regularities. We instrument a character language model with several probes, finding that it can develop a specific unit to identify word boundaries and, by extension, morpheme boundaries, which allows it to capture linguistic properties and regularities of these units. Our language model proves surprisingly good at identifying the selectional restrictions of English derivational morphemes, a task that requires both morphological and syntactic awareness. Thus we conclude that, when morphemes overlap extensively with the words of a language, a character language model can perform morphological abstraction.