 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Compressed Model of Residual CNDS
Jun 15, 2017

Convolutional neural networks have achieved a great success in the recent years. Although, the way to maximize the performance of the convolutional neural networks still in the beginning. Furthermore, the optimization of the size and the time that need to train the convolutional neural networks is very far away from reaching the researcher's ambition. In this paper, we proposed a new convolutional neural network that combined several techniques to boost the optimization of the convolutional neural network in the aspects of speed and size. As we used our previous model Residual-CNDS (ResCNDS), which solved the problems of slower convergence, overfitting, and degradation, and compressed it. The outcome model called Residual-Squeeze-CNDS (ResSquCNDS), which we demonstrated on our sold technique to add residual learning and our model of compressing the convolutional neural networks. Our model of compressing adapted from the SQUEEZENET model, but our model is more generalizable, which can be applied almost to any neural network model, and fully integrated into the residual learning, which addresses the problem of the degradation very successfully. Our proposed model trained on very large-scale MIT Places365-Standard scene datasets, which backing our hypothesis that the new compressed model inherited the best of the previous ResCNDS8 model, and almost get the same accuracy in the validation Top-1 and Top-5 with 87.64% smaller in size and 13.33% faster in the training time.
Residual Squeeze VGG16
May 05, 2017
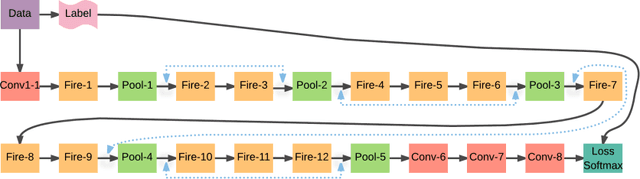

Deep learning has given way to a new era of machine learning, apart from computer vision. Convolutional neural networks have been implemented in image classification, segmentation and object detection. Despite recent advancements, we are still in the very early stages and have yet to settle on best practices for network architecture in terms of deep design, small in size and a short training time. In this work, we propose a very deep neural network comprised of 16 Convolutional layers compressed with the Fire Module adapted from the SQUEEZENET model. We also call for the addition of residual connections to help suppress degradation. This model can be implemented on almost every neural network model with fully incorporated residual learning. This proposed model Residual-Squeeze-VGG16 (ResSquVGG16) trained on the large-scale MIT Places365-Standard scene dataset. In our tests, the model performed with accuracy similar to the pre-trained VGG16 model in Top-1 and Top-5 validation accuracy while also enjoying a 23.86% reduction in training time and an 88.4% reduction in size. In our tests, this model was trained from scratch.
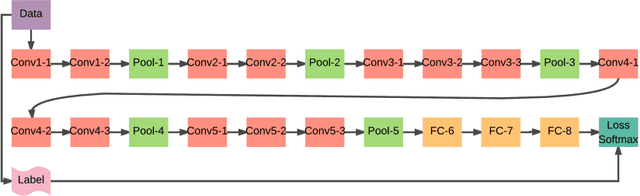
Residual CNDS
Aug 07, 2016



Convolutional Neural networks nowadays are of tremendous importance for any image classification system. One of the most investigated methods to increase the accuracy of CNN is by increasing the depth of CNN. Increasing the depth by stacking more layers also increases the difficulty of training besides making it computationally expensive. Some research found that adding auxiliary forks after intermediate layers increases the accuracy. Specifying which intermediate layer shoud have the fork just addressed recently. Where a simple rule were used to detect the position of intermediate layers that needs the auxiliary supervision fork. This technique known as convolutional neural networks with deep supervision (CNDS). This technique enhanced the accuracy of classification over the straight forward CNN used on the MIT places dataset and ImageNet. In the other side, Residual Learning is another technique emerged recently to ease the training of very deep CNN. Residual Learning framwork changed the learning of layers from unreferenced functions to learning residual function with regard to the layer's input. Residual Learning achieved state of arts results on ImageNet 2015 and COCO competitions. In this paper, we study the effect of adding residual connections to CNDS network. Our experiments results show increasing of accuracy over using CNDS only.