 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Censor by Noisy Sampling
Mar 23, 2022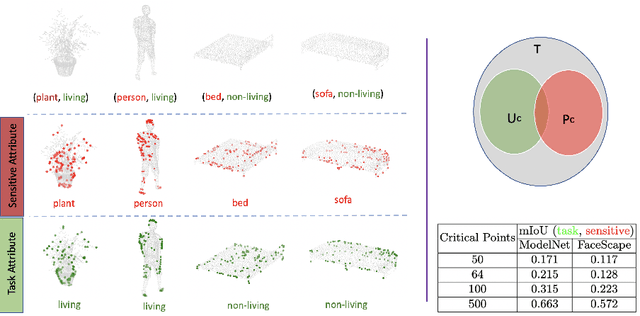
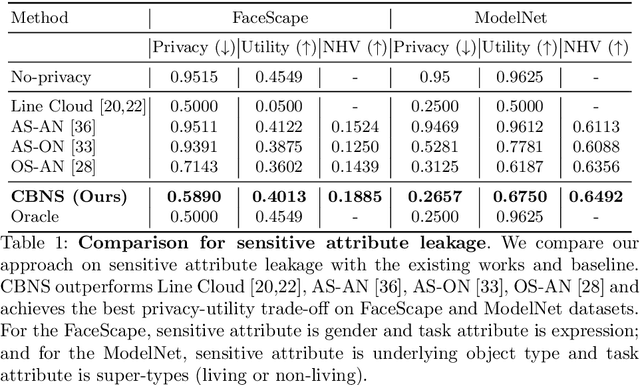

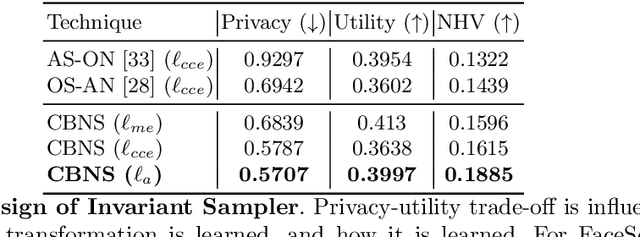
Point clouds are an increasingly ubiquitous input modality and the raw signal can be efficiently processed with recent progress in deep learning. This signal may, often inadvertently, capture sensitive information that can leak semantic and geometric properties of the scene which the data owner does not want to share. The goal of this work is to protect sensitive information when learning from point clouds; by censoring the sensitive information before the point cloud is released for downstream tasks. Specifically, we focus on preserving utility for perception tasks while mitigating attribute leakage attacks. The key motivating insight is to leverage the localized saliency of perception tasks on point clouds to provide good privacy-utility trade-offs. We realize this through a mechanism called Censoring by Noisy Sampling (CBNS), which is composed of two modules: i) Invariant Sampler: a differentiable point-cloud sampler which learns to remove points invariant to utility and ii) Noisy Distorter: which learns to distort sampled points to decouple the sensitive information from utility, and mitigate privacy leakage. We validate the effectiveness of CBNS through extensive comparisons with state-of-the-art baselines and sensitivity analyses of key design choices. Results show that CBNS achieves superior privacy-utility trade-offs on multiple datasets.
Decouple-and-Sample: Protecting sensitive information in task agnostic data release
Mar 17, 2022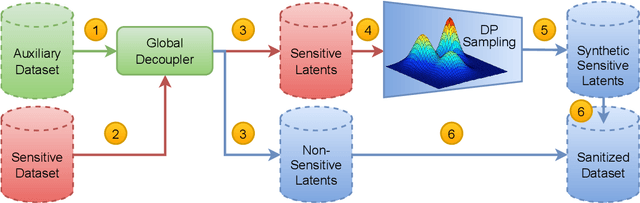
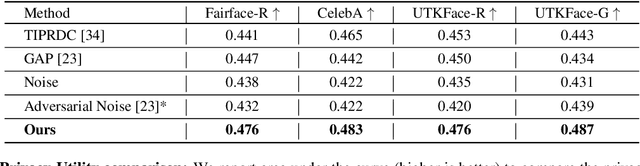
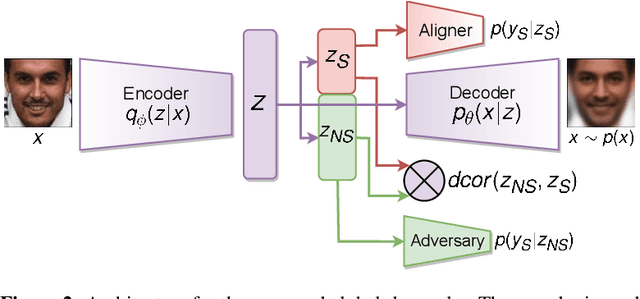
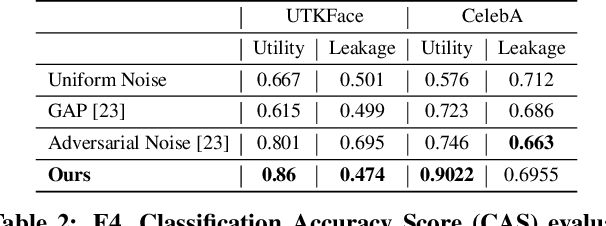
We propose sanitizer, a framework for secure and task-agnostic data release. While releasing datasets continues to make a big impact in various applications of computer vision, its impact is mostly realized when data sharing is not inhibited by privacy concerns. We alleviate these concerns by sanitizing datasets in a two-stage process. First, we introduce a global decoupling stage for decomposing raw data into sensitive and non-sensitive latent representations. Secondly, we design a local sampling stage to synthetically generate sensitive information with differential privacy and merge it with non-sensitive latent features to create a useful representation while preserving the privacy. This newly formed latent information is a task-agnostic representation of the original dataset with anonymized sensitive information. While most algorithms sanitize data in a task-dependent manner, a few task-agnostic sanitization techniques sanitize data by censoring sensitive information. In this work, we show that a better privacy-utility trade-off is achieved if sensitive information can be synthesized privately. We validate the effectiveness of the sanitizer by outperforming state-of-the-art baselines on the existing benchmark tasks and demonstrating tasks that are not possible using existing techniques.
Singularity: Planet-Scale, Preemptive and Elastic Scheduling of AI Workloads
Feb 21, 2022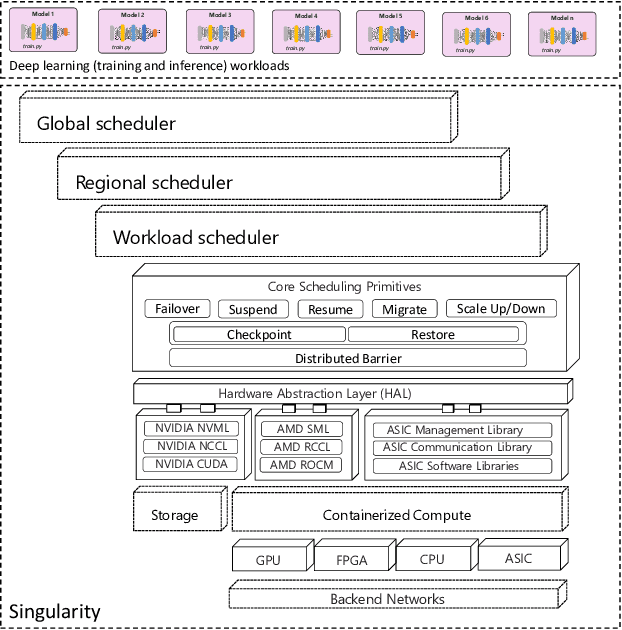
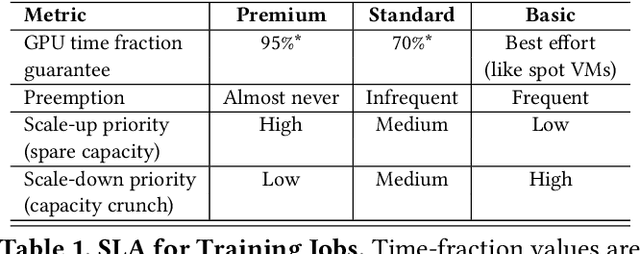
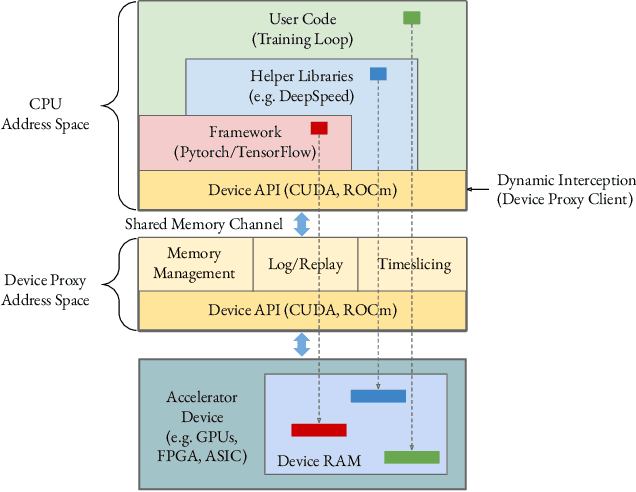
Lowering costs by driving high utilization across deep learning workloads is a crucial lever for cloud providers. We present Singularity, Microsoft's globally distributed scheduling service for highly-efficient and reliable execution of deep learning training and inference workloads. At the heart of Singularity is a novel, workload-aware scheduler that can transparently preempt and elastically scale deep learning workloads to drive high utilization without impacting their correctness or performance, across a global fleet of AI accelerators (e.g., GPUs, FPGAs). All jobs in Singularity are preemptable, migratable, and dynamically resizable (elastic) by default: a live job can be dynamically and transparently (a) preempted and migrated to a different set of nodes, cluster, data center or a region and resumed exactly from the point where the execution was preempted, and (b) resized (i.e., elastically scaled-up/down) on a varying set of accelerators of a given type. Our mechanisms are transparent in that they do not require the user to make any changes to their code or require using any custom libraries that may limit flexibility. Additionally, our approach significantly improves the reliability of deep learning workloads. We show that the resulting efficiency and reliability gains with Singularity are achieved with negligible impact on the steady-state performance. Finally, our design approach is agnostic of DNN architectures and handles a variety of parallelism strategies (e.g., data/pipeline/model parallelism).
AdaSplit: Adaptive Trade-offs for Resource-constrained Distributed Deep Learning
Dec 02, 2021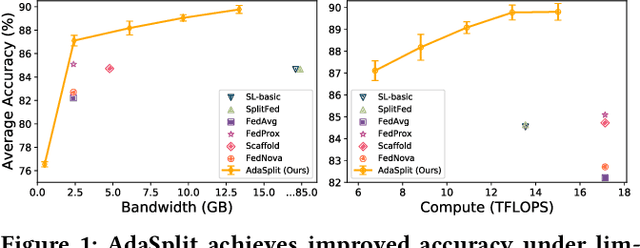
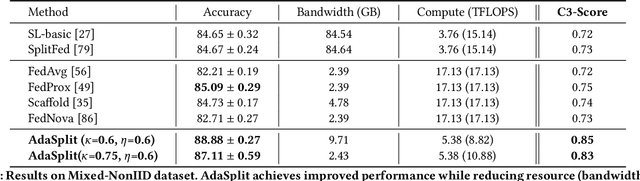
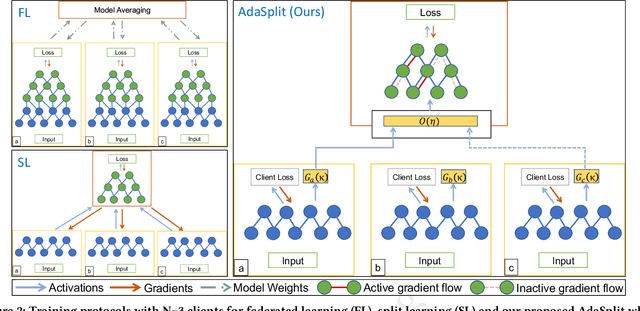
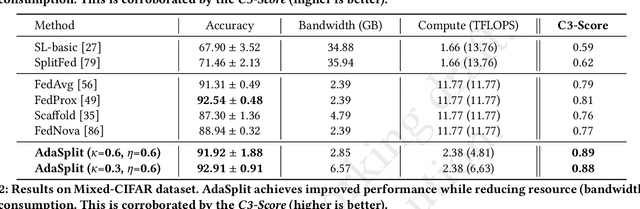
Distributed deep learning frameworks like federated learning (FL) and its variants are enabling personalized experiences across a wide range of web clients and mobile/IoT devices. However, FL-based frameworks are constrained by computational resources at clients due to the exploding growth of model parameters (eg. billion parameter model). Split learning (SL), a recent framework, reduces client compute load by splitting the model training between client and server. This flexibility is extremely useful for low-compute setups but is often achieved at cost of increase in bandwidth consumption and may result in sub-optimal convergence, especially when client data is heterogeneous. In this work, we introduce AdaSplit which enables efficiently scaling SL to low resource scenarios by reducing bandwidth consumption and improving performance across heterogeneous clients. To capture and benchmark this multi-dimensional nature of distributed deep learning, we also introduce C3-Score, a metric to evaluate performance under resource budgets. We validate the effectiveness of AdaSplit under limited resources through extensive experimental comparison with strong federated and split learning baselines. We also present a sensitivity analysis of key design choices in AdaSplit which validates the ability of AdaSplit to provide adaptive trade-offs across variable resource budgets.
MedPerf: Open Benchmarking Platform for Medical Artificial Intelligence using Federated Evaluation
Oct 08, 2021
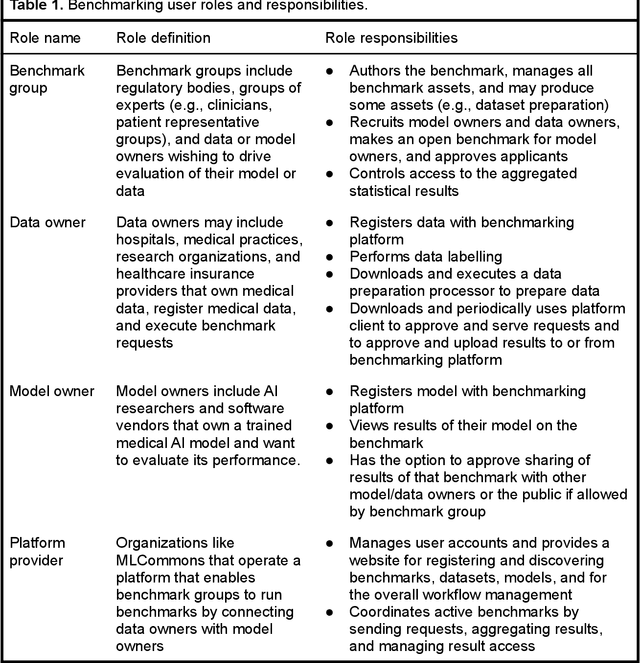
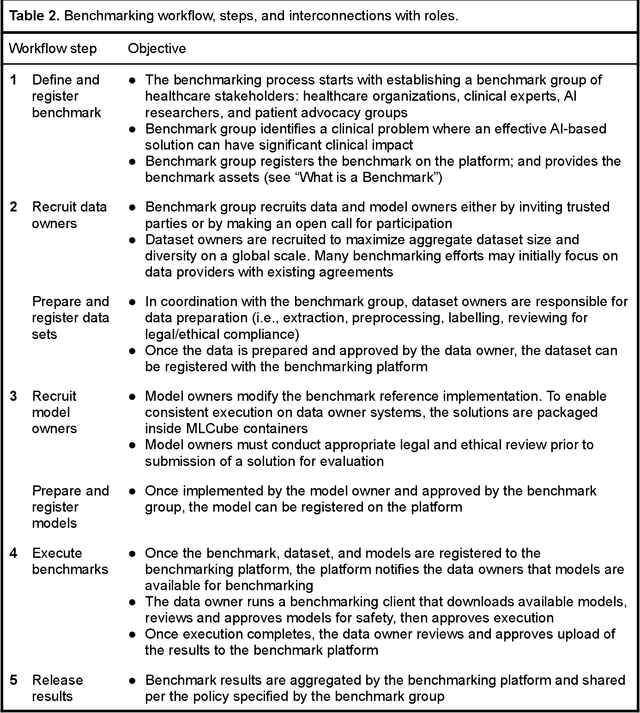
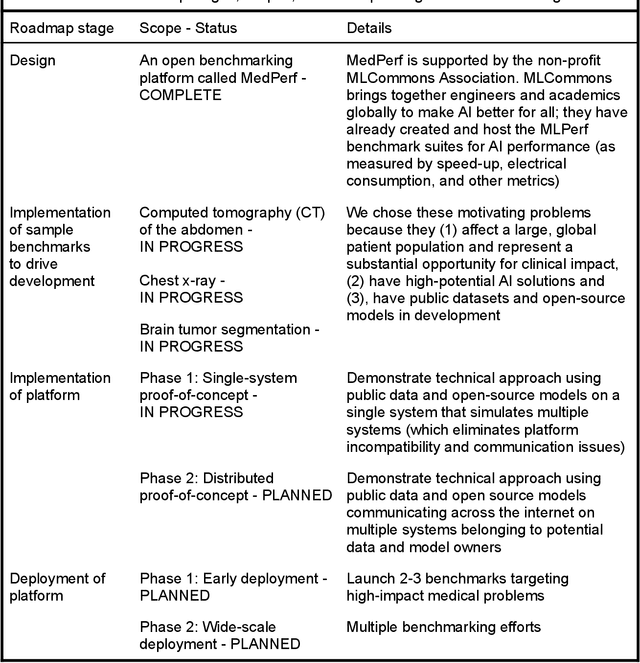
Medical AI has tremendous potential to advance healthcare by supporting the evidence-based practice of medicine, personalizing patient treatment, reducing costs, and improving provider and patient experience. We argue that unlocking this potential requires a systematic way to measure the performance of medical AI models on large-scale heterogeneous data. To meet this need, we are building MedPerf, an open framework for benchmarking machine learning in the medical domain. MedPerf will enable federated evaluation in which models are securely distributed to different facilities for evaluation, thereby empowering healthcare organizations to assess and verify the performance of AI models in an efficient and human-supervised process, while prioritizing privacy. We describe the current challenges healthcare and AI communities face, the need for an open platform, the design philosophy of MedPerf, its current implementation status, and our roadmap. We call for researchers and organizations to join us in creating the MedPerf open benchmarking platform.
An In-Memory Analog Computing Co-Processor for Energy-Efficient CNN Inference on Mobile Devices
May 24, 2021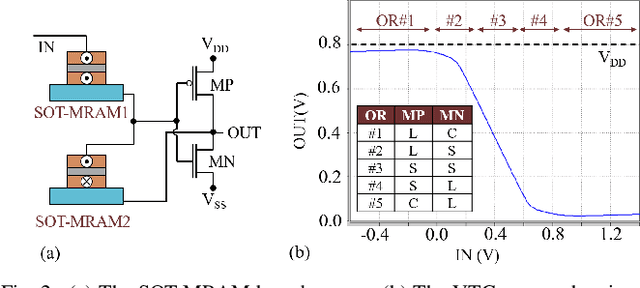
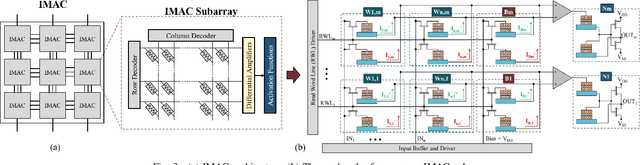
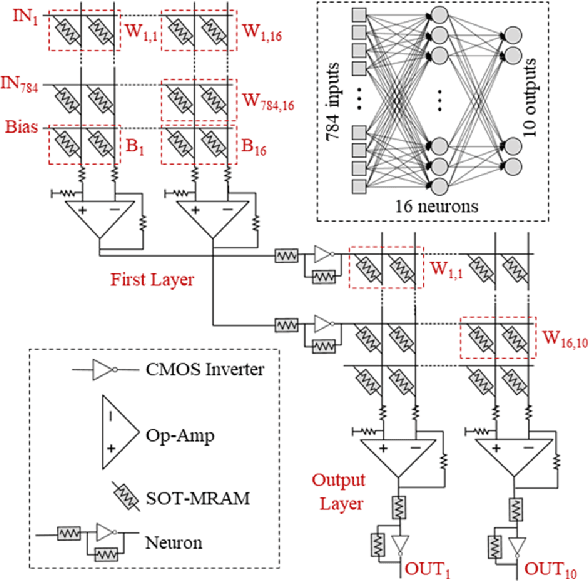
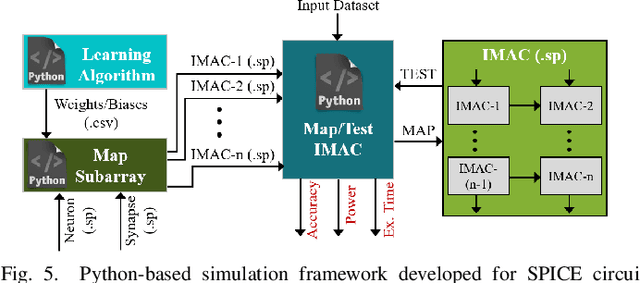
In this paper, we develop an in-memory analog computing (IMAC) architecture realizing both synaptic behavior and activation functions within non-volatile memory arrays. Spin-orbit torque magnetoresistive random-access memory (SOT-MRAM) devices are leveraged to realize sigmoidal neurons as well as binarized synapses. First, it is shown the proposed IMAC architecture can be utilized to realize a multilayer perceptron (MLP) classifier achieving orders of magnitude performance improvement compared to previous mixed-signal and digital implementations. Next, a heterogeneous mixed-signal and mixed-precision CPU-IMAC architecture is proposed for convolutional neural networks (CNNs) inference on mobile processors, in which IMAC is designed as a co-processor to realize fully-connected (FC) layers whereas convolution layers are executed in CPU. Architecture-level analytical models are developed to evaluate the performance and energy consumption of the CPU-IMAC architecture. Simulation results exhibit 6.5% and 10% energy savings for CPU-IMAC based realizations of LeNet and VGG CNN models, for MNIST and CIFAR-10 pattern recognition tasks, respectively.
Automatic calibration of time of flight based non-line-of-sight reconstruction
May 21, 2021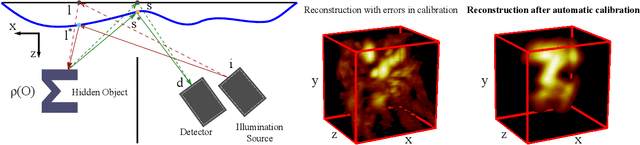

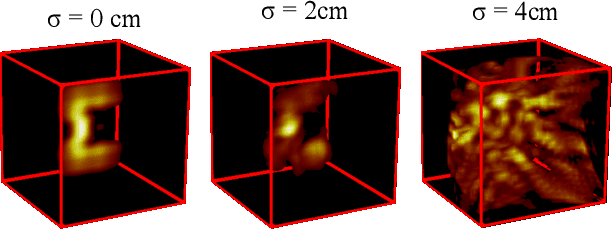

Time of flight based Non-line-of-sight (NLOS) imaging approaches require precise calibration of illumination and detector positions on the visible scene to produce reasonable results. If this calibration error is sufficiently high, reconstruction can fail entirely without any indication to the user. In this work, we highlight the necessity of building autocalibration into NLOS reconstruction in order to handle mis-calibration. We propose a forward model of NLOS measurements that is differentiable with respect to both, the hidden scene albedo, and virtual illumination and detector positions. With only a mean squared error loss and no regularization, our model enables joint reconstruction and recovery of calibration parameters by minimizing the measurement residual using gradient descent. We demonstrate our method is able to produce robust reconstructions using simulated and real data where the calibration error applied causes other state of the art algorithms to fail.
Can Self Reported Symptoms Predict Daily COVID-19 Cases?
May 18, 2021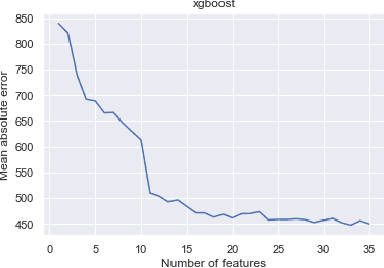
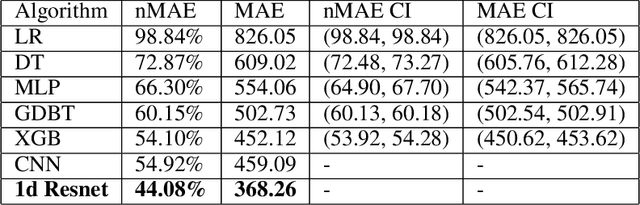
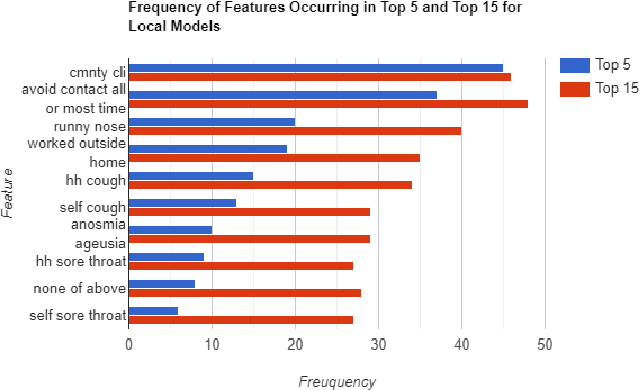

The COVID-19 pandemic has impacted lives and economies across the globe, leading to many deaths. While vaccination is an important intervention, its roll-out is slow and unequal across the globe. Therefore, extensive testing still remains one of the key methods to monitor and contain the virus. Testing on a large scale is expensive and arduous. Hence, we need alternate methods to estimate the number of cases. Online surveys have been shown to be an effective method for data collection amidst the pandemic. In this work, we develop machine learning models to estimate the prevalence of COVID-19 using self-reported symptoms. Our best model predicts the daily cases with a mean absolute error (MAE) of 226.30 (normalized MAE of 27.09%) per state, which demonstrates the possibility of predicting the actual number of confirmed cases by utilizing self-reported symptoms. The models are developed at two levels of data granularity - local models, which are trained at the state level, and a single global model which is trained on the combined data aggregated across all states. Our results indicate a lower error on the local models as opposed to the global model. In addition, we also show that the most important symptoms (features) vary considerably from state to state. This work demonstrates that the models developed on crowd-sourced data, curated via online platforms, can complement the existing epidemiological surveillance infrastructure in a cost-effective manner.
COVID-19 Outbreak Prediction and Analysis using Self Reported Symptoms
Dec 21, 2020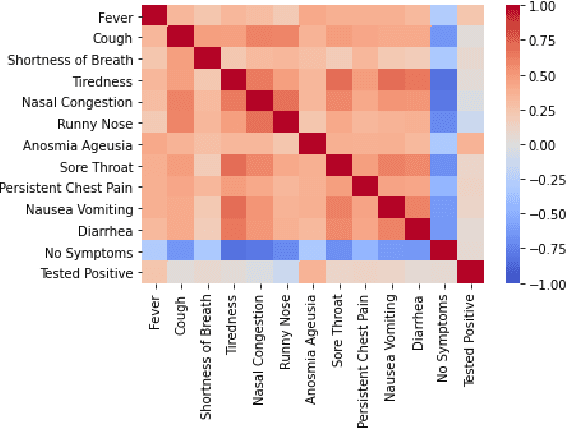
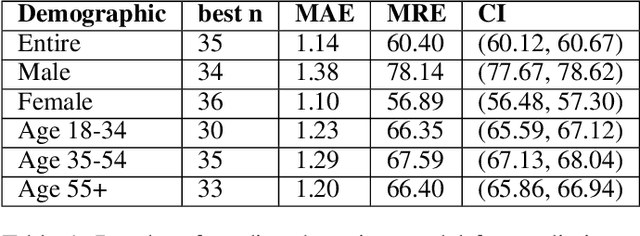
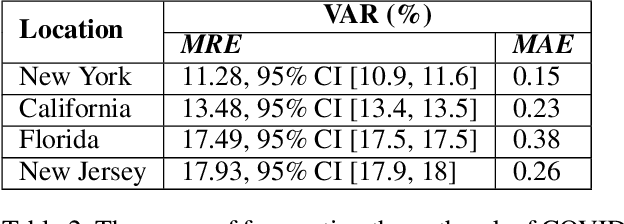
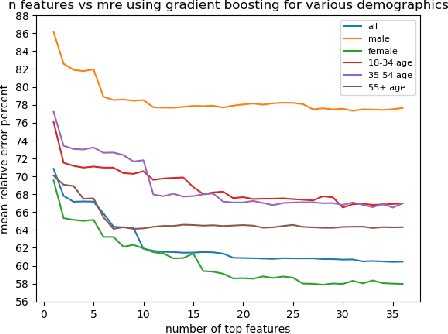
The COVID-19 pandemic has challenged scientists and policy-makers internationally to develop novel approaches to public health policy. Furthermore, it has also been observed that the prevalence and spread of COVID-19 vary across different spatial, temporal, and demographics. Despite ramping up testing, we still are not at the required level in most parts of the globe. Therefore, we utilize self-reported symptoms survey data to understand trends in the spread of COVID-19. The aim of this study is to segment populations that are highly susceptible. In order to understand such populations, we perform exploratory data analysis, outbreak prediction, and time-series forecasting using public health and policy datasets. From our studies, we try to predict the likely % of the population that tested positive for COVID-19 based on self-reported symptoms. Our findings reaffirm the predictive value of symptoms, such as anosmia and ageusia. And we forecast that % of the population having COVID-19-like illness (CLI) and those tested positive as 0.15% and 1.14% absolute error respectively. These findings could help aid faster development of the public health policy, particularly in areas with low levels of testing and having a greater reliance on self-reported symptoms. Our analysis sheds light on identifying clinical attributes of interest across different demographics. We also provide insights into the effects of various policy enactments on COVID-19 prevalence.
DISCO: Dynamic and Invariant Sensitive Channel Obfuscation for deep neural networks
Dec 20, 2020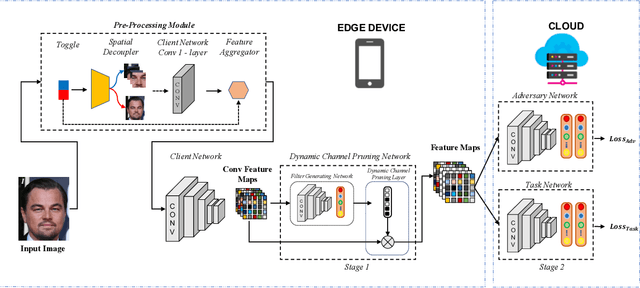
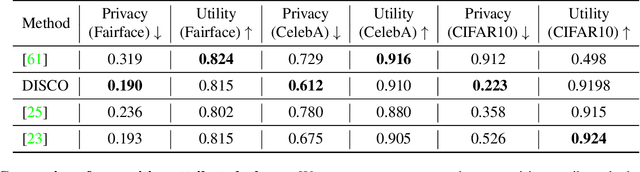

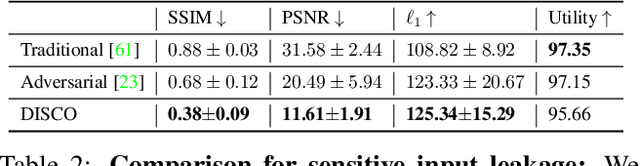
Recent deep learning models have shown remarkable performance in image classification. While these deep learning systems are getting closer to practical deployment, the common assumption made about data is that it does not carry any sensitive information. This assumption may not hold for many practical cases, especially in the domain where an individual's personal information is involved, like healthcare and facial recognition systems. We posit that selectively removing features in this latent space can protect the sensitive information and provide a better privacy-utility trade-off. Consequently, we propose DISCO which learns a dynamic and data driven pruning filter to selectively obfuscate sensitive information in the feature space. We propose diverse attack schemes for sensitive inputs \& attributes and demonstrate the effectiveness of DISCO against state-of-the-art methods through quantitative and qualitative evaluation. Finally, we also release an evaluation benchmark dataset of 1 million sensitive representations to encourage rigorous exploration of novel attack schemes.