 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMatrix Decomposition on Graphs: A Functional View
Feb 05, 2021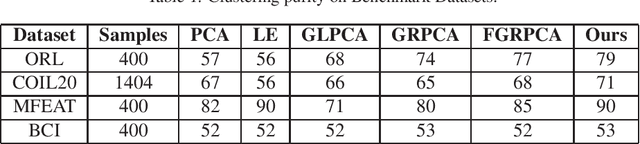
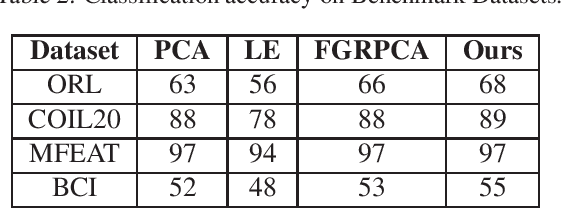

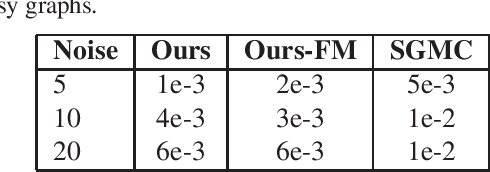
We propose a functional view of matrix decomposition problems on graphs such as geometric matrix completion and graph regularized dimensionality reduction. Our unifying framework is based on the key idea that using a reduced basis to represent functions on the product space is sufficient to recover a low rank matrix approximation even from a sparse signal. We validate our framework on several real and synthetic benchmarks (for both problems) where it either outperforms state of the art or achieves competitive results at a fraction of the computational effort of prior work.
Learning Visual Representations for Transfer Learning by Suppressing Texture
Nov 04, 2020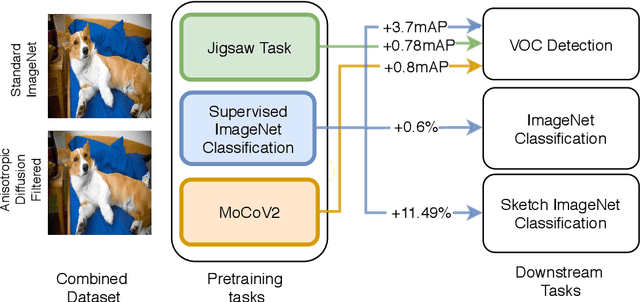
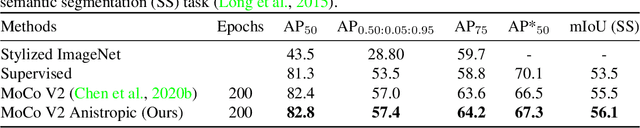

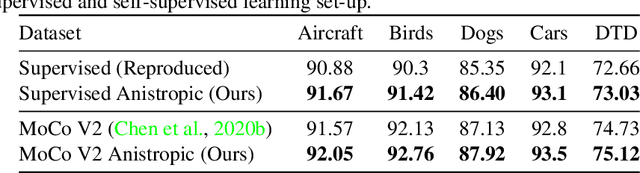
Recent literature has shown that features obtained from supervised training of CNNs may over-emphasize texture rather than encoding high-level information. In self-supervised learning in particular, texture as a low-level cue may provide shortcuts that prevent the network from learning higher level representations. To address these problems we propose to use classic methods based on anisotropic diffusion to augment training using images with suppressed texture. This simple method helps retain important edge information and suppress texture at the same time. We empirically show that our method achieves state-of-the-art results on object detection and image classification with eight diverse datasets in either supervised or self-supervised learning tasks such as MoCoV2 and Jigsaw. Our method is particularly effective for transfer learning tasks and we observed improved performance on five standard transfer learning datasets. The large improvements (up to 11.49\%) on the Sketch-ImageNet dataset, DTD dataset and additional visual analyses with saliency maps suggest that our approach helps in learning better representations that better transfer.
Geometric Matrix Completion: A Functional View
Sep 29, 2020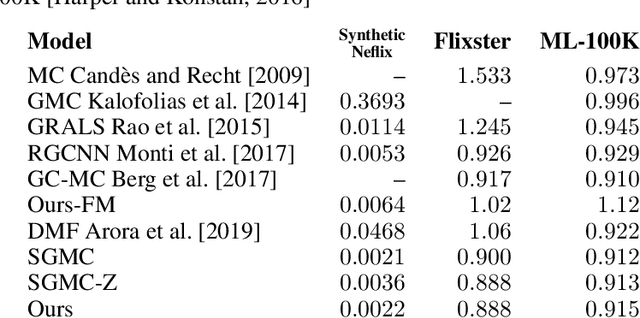
We propose a totally functional view of geometric matrix completion problem. Differently from existing work, we propose a novel regularization inspired from the functional map literature that is more interpretable and theoretically sound. On synthetic tasks with strong underlying geometric structure, our framework outperforms state of the art by a huge margin (two order of magnitude) demonstrating the potential of our approach. On real datasets, we achieve state-of-the-art results at a fraction of the computational effort of previous methods. Our code is publicly available at https://github.com/Not-IITian/functional-matrix-completion
Weakly Supervised Deep Functional Map for Shape Matching
Sep 28, 2020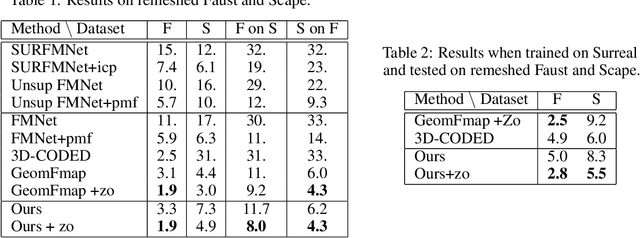

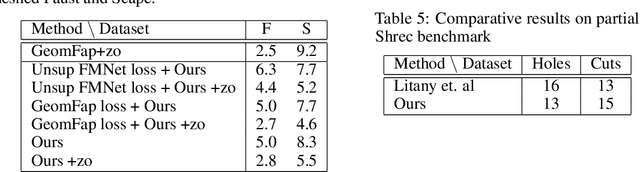
A variety of deep functional maps have been proposed recently, from fully supervised to totally unsupervised, with a range of loss functions as well as different regularization terms. However, it is still not clear what are minimum ingredients of a deep functional map pipeline and whether such ingredients unify or generalize all recent work on deep functional maps. We show empirically minimum components for obtaining state of the art results with different loss functions, supervised as well as unsupervised. Furthermore, we propose a novel framework designed for both full-to-full as well as partial to full shape matching that achieves state of the art results on several benchmark datasets outperforming even the fully supervised methods by a significant margin. Our code is publicly available at https://github.com/Not-IITian/Weakly-supervised-Functional-map
ASAP-NMS: Accelerating Non-Maximum Suppression Using Spatially Aware Priors
Aug 21, 2020

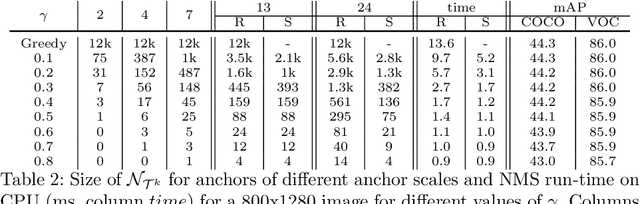

The widely adopted sequential variant of Non Maximum Suppression (or Greedy-NMS) is a crucial module for object-detection pipelines. Unfortunately, for the region proposal stage of two/multi-stage detectors, NMS is turning out to be a latency bottleneck due to its sequential nature. In this article, we carefully profile Greedy-NMS iterations to find that a major chunk of computation is wasted in comparing proposals that are already far-away and have a small chance of suppressing each other. We address this issue by comparing only those proposals that are generated from nearby anchors. The translation-invariant property of the anchor lattice affords generation of a lookup table, which provides an efficient access to nearby proposals, during NMS. This leads to an Accelerated NMS algorithm which leverages Spatially Aware Priors, or ASAP-NMS, and improves the latency of the NMS step from 13.6ms to 1.2 ms on a CPU without sacrificing the accuracy of a state-of-the-art two-stage detector on COCO and VOC datasets. Importantly, ASAP-NMS is agnostic to image resolution and can be used as a simple drop-in module during inference. Using ASAP-NMS at run-time only, we obtain an mAP of 44.2\%@25Hz on the COCO dataset with a V100 GPU.
Price Optimization in Fashion E-commerce
Jul 10, 2020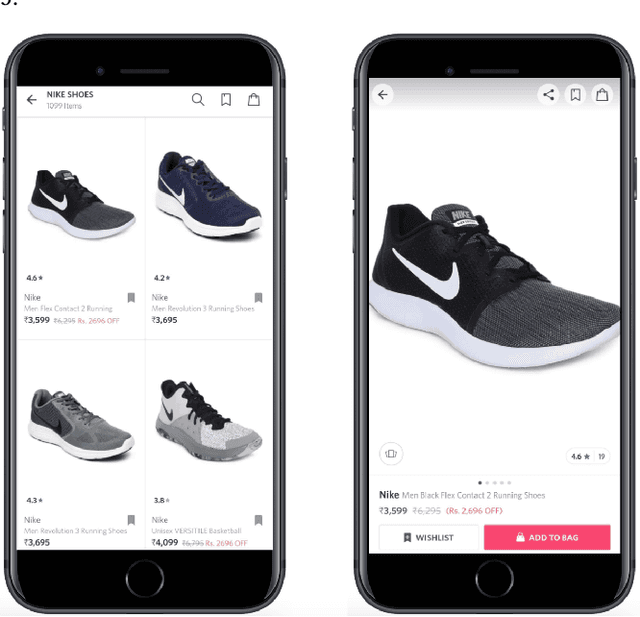
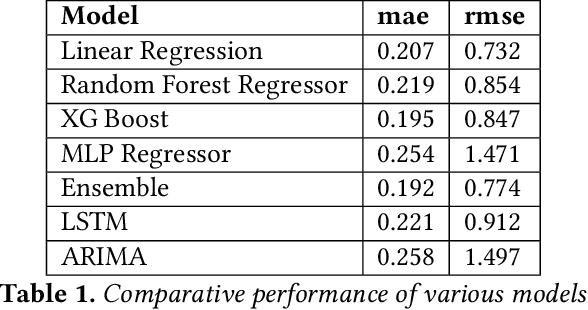
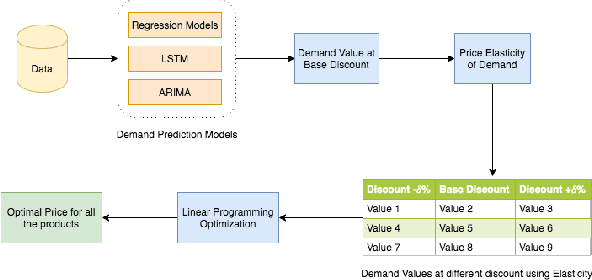
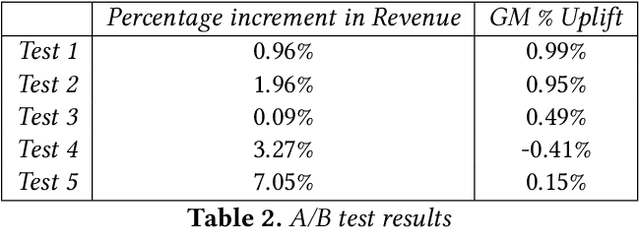
With the rapid growth in the fashion e-commerce industry, it is becoming extremely challenging for the E-tailers to set an optimal price point for all the products on the platform. By establishing an optimal price point, they can maximize overall revenue and profit for the platform. In this paper, we propose a novel machine learning and optimization technique to find the optimal price point at an individual product level. It comprises three major components. Firstly, we use a demand prediction model to predict the next day demand for each product at a certain discount percentage. Next step, we use the concept of price elasticity of demand to get the multiple demand values by varying the discount percentage. Thus we obtain multiple price demand pairs for each product and we have to choose one of them for the live platform. Typically fashion e-commerce has millions of products, so there can be many permutations. Each permutation will assign a unique price point for all the products, which will sum up to a unique revenue number. To choose the best permutation which gives maximum revenue, a linear programming optimization technique is used. We have deployed the above methods in the live production environment and conducted several AB tests. According to the AB test result, our model is improving the revenue by 1 percent and gross margin by 0.81 percent.
OpenEDS2020: Open Eyes Dataset
May 08, 2020

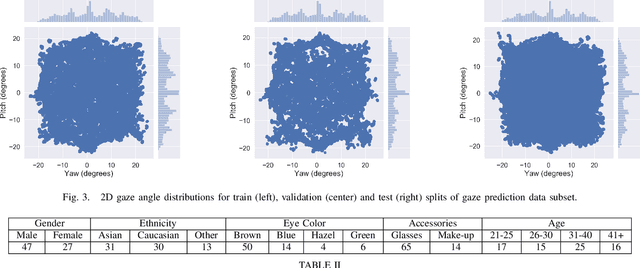
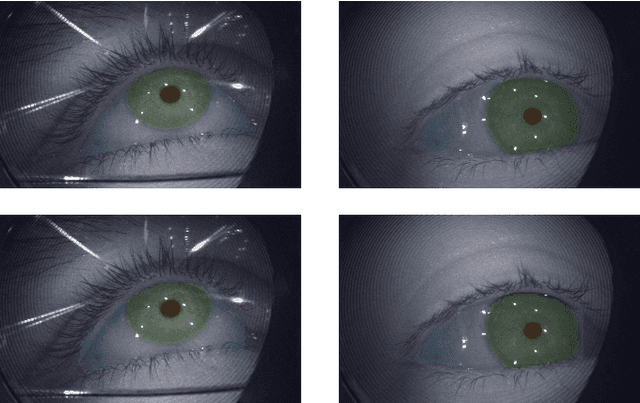
We present the second edition of OpenEDS dataset, OpenEDS2020, a novel dataset of eye-image sequences captured at a frame rate of 100 Hz under controlled illumination, using a virtual-reality head-mounted display mounted with two synchronized eye-facing cameras. The dataset, which is anonymized to remove any personally identifiable information on participants, consists of 80 participants of varied appearance performing several gaze-elicited tasks, and is divided in two subsets: 1) Gaze Prediction Dataset, with up to 66,560 sequences containing 550,400 eye-images and respective gaze vectors, created to foster research in spatio-temporal gaze estimation and prediction approaches; and 2) Eye Segmentation Dataset, consisting of 200 sequences sampled at 5 Hz, with up to 29,500 images, of which 5% contain a semantic segmentation label, devised to encourage the use of temporal information to propagate labels to contiguous frames. Baseline experiments have been evaluated on OpenEDS2020, one for each task, with average angular error of 5.37 degrees when performing gaze prediction on 1 to 5 frames into the future, and a mean intersection over union score of 84.1% for semantic segmentation. As its predecessor, OpenEDS dataset, we anticipate that this new dataset will continue creating opportunities to researchers in eye tracking, machine learning and computer vision communities, to advance the state of the art for virtual reality applications. The dataset is available for download upon request at http://research.fb.com/programs/openeds-2020-challenge/.
Towards Automatic Generation of Questions from Long Answers
Apr 15, 2020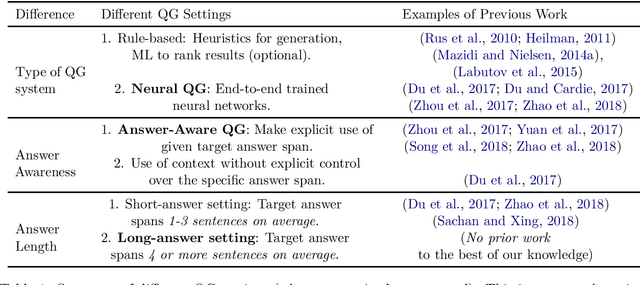

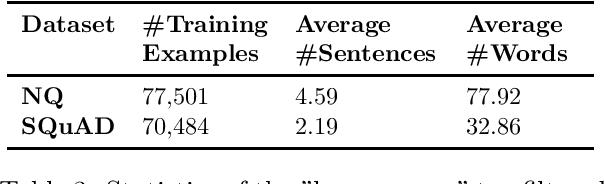
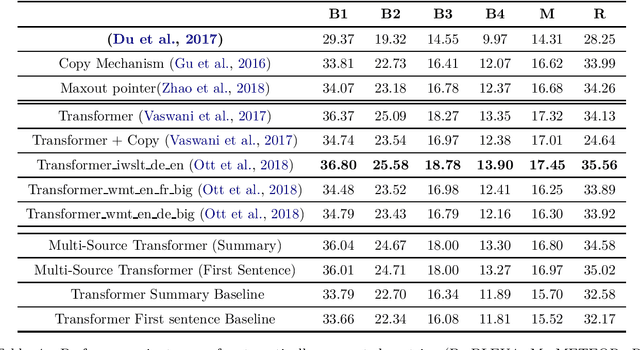
Automatic question generation (AQG) has broad applicability in domains such as tutoring systems, conversational agents, healthcare literacy, and information retrieval. Existing efforts at AQG have been limited to short answer lengths of up to two or three sentences. However, several real-world applications require question generation from answers that span several sentences. Therefore, we propose a novel evaluation benchmark to assess the performance of existing AQG systems for long-text answers. We leverage the large-scale open-source Google Natural Questions dataset to create the aforementioned long-answer AQG benchmark. We empirically demonstrate that the performance of existing AQG methods significantly degrades as the length of the answer increases. Transformer-based methods outperform other existing AQG methods on long answers in terms of automatic as well as human evaluation. However, we still observe degradation in the performance of our best performing models with increasing sentence length, suggesting that long answer QA is a challenging benchmark task for future research.
Deep Geometric Functional Maps: Robust Feature Learning for Shape Correspondence
Mar 31, 2020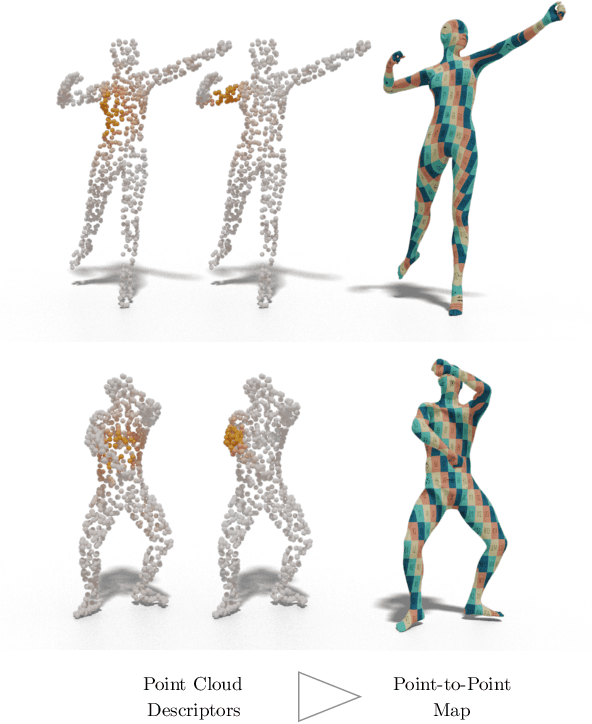
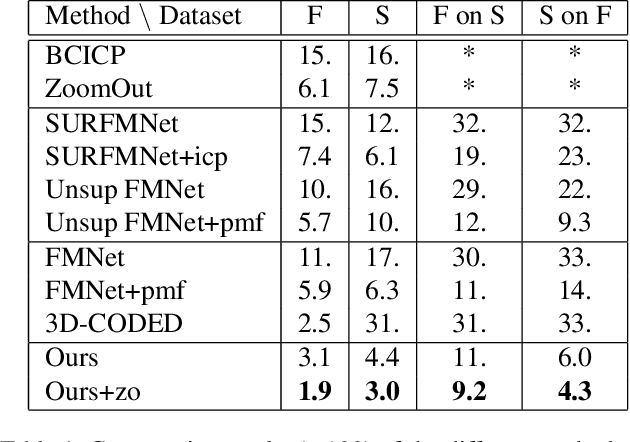
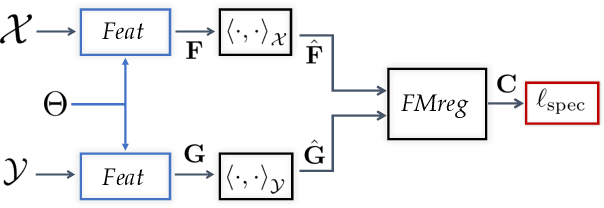

We present a novel learning-based approach for computing correspondences between non-rigid 3D shapes. Unlike previous methods that either require extensive training data or operate on handcrafted input descriptors and thus generalize poorly across diverse datasets, our approach is both accurate and robust to changes in shape structure. Key to our method is a feature-extraction network that learns directly from raw shape geometry, combined with a novel regularized map extraction layer and loss, based on the functional map representation. We demonstrate through extensive experiments in challenging shape matching scenarios that our method can learn from less training data than existing supervised approaches and generalizes significantly better than current descriptor-based learning methods. Our source code is available at: https://github.com/LIX-shape-analysis/GeomFmaps.
Listwise Learning to Rank with Deep Q-Networks
Feb 13, 2020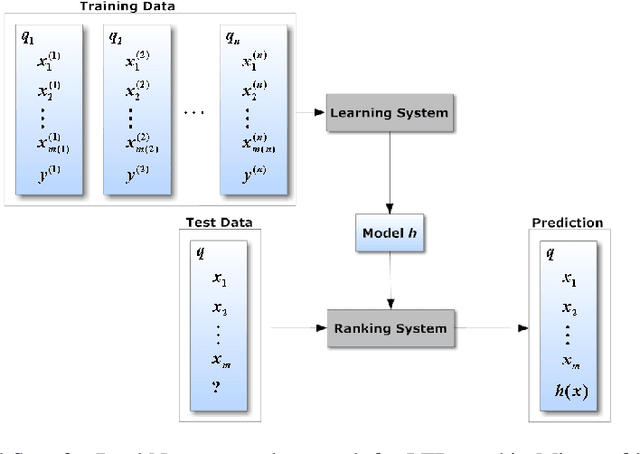
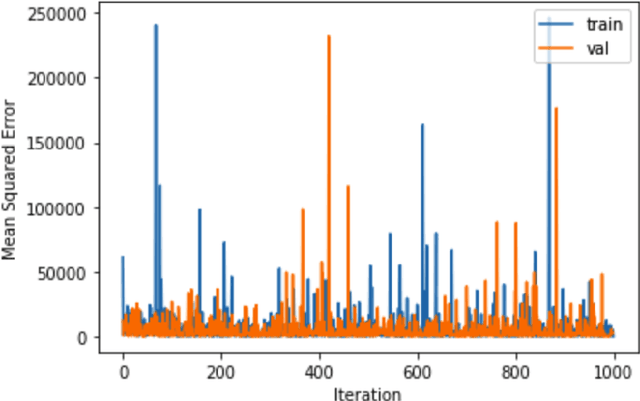
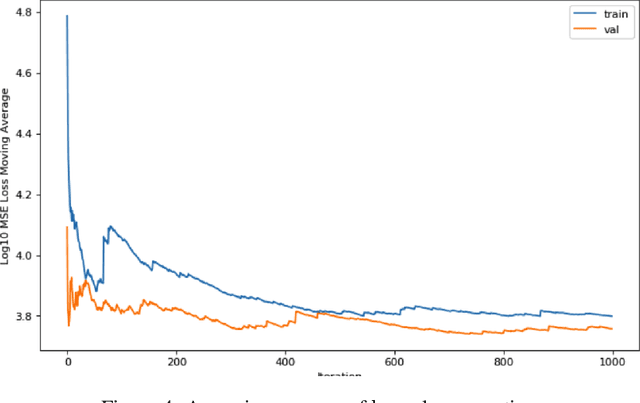
Learning to Rank is the problem involved with ranking a sequence of documents based on their relevance to a given query. Deep Q-Learning has been shown to be a useful method for training an agent in sequential decision making. In this paper, we show that DeepQRank, our deep q-learning to rank agent, demonstrates performance that can be considered state-of-the-art. Though less computationally efficient than a supervised learning approach such as linear regression, our agent has fewer limitations in terms of which format of data it can use for training and evaluation. We run our algorithm against Microsoft's LETOR listwise dataset and achieve an NDCG@1 (ranking accuracy in the range [0,1]) of 0.5075, narrowly beating out the leading supervised learning model, SVMRank (0.4958).