 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredictive Price-Performance Optimization for Serverless Query Processing
Dec 16, 2021
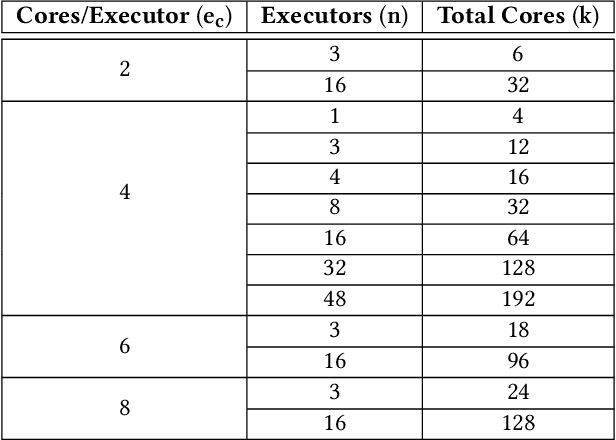
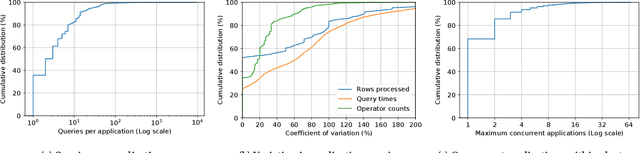
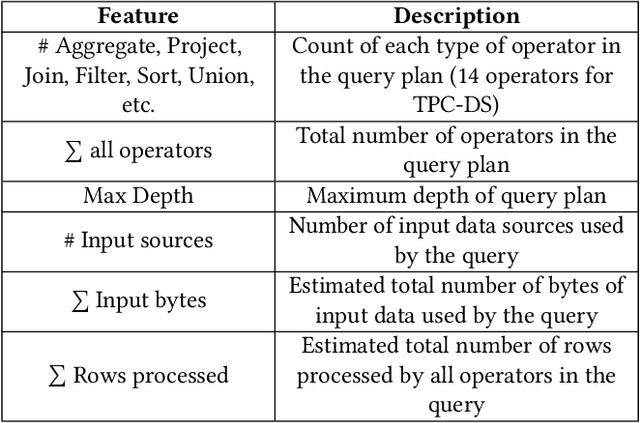
We present an efficient, parametric modeling framework for predictive resource allocations, focusing on the amount of computational resources, that can optimize for a range of price-performance objectives for data analytics in serverless query processing settings. We discuss and evaluate in depth how our system, AutoExecutor, can use this framework to automatically select near-optimal executor and core counts for Spark SQL queries running on Azure Synapse. Our techniques improve upon Spark's in-built, reactive, dynamic executor allocation capabilities by substantially reducing the total executors allocated and executor occupancy while running queries, thereby freeing up executors that can potentially be used by other concurrent queries or in reducing the overall cluster provisioning needs. In contrast with post-execution analysis tools such as Sparklens, we predict resource allocations for queries before executing them and can also account for changes in input data sizes for predicting the desired allocations.
Phoebe: A Learning-based Checkpoint Optimizer
Oct 05, 2021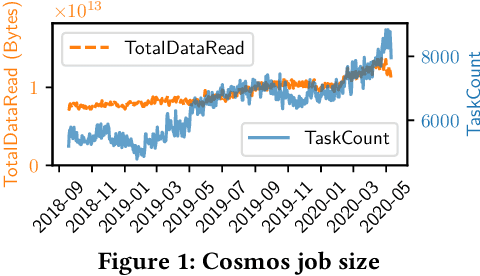
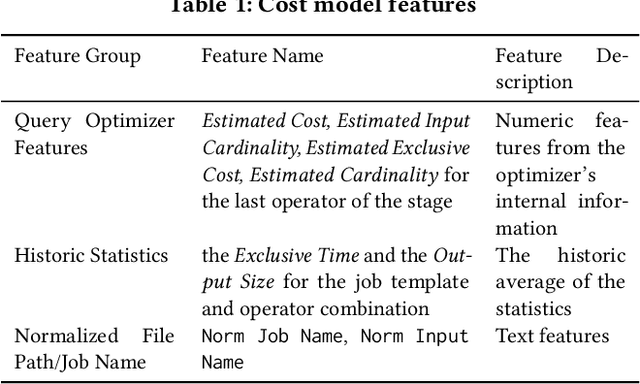

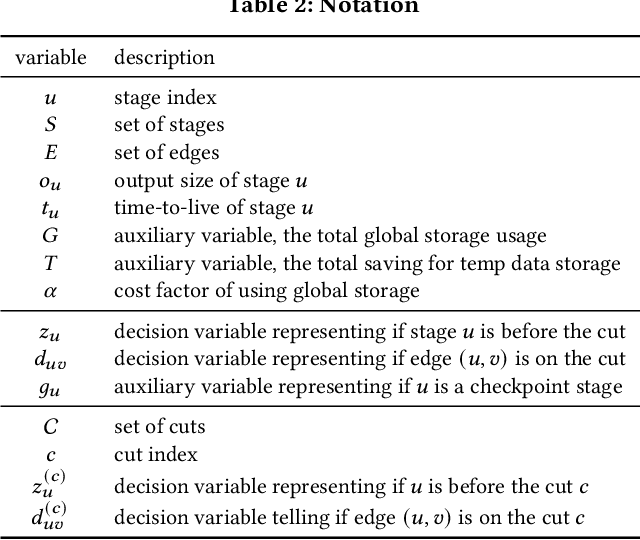
Easy-to-use programming interfaces paired with cloud-scale processing engines have enabled big data system users to author arbitrarily complex analytical jobs over massive volumes of data. However, as the complexity and scale of analytical jobs increase, they encounter a number of unforeseen problems, hotspots with large intermediate data on temporary storage, longer job recovery time after failures, and worse query optimizer estimates being examples of issues that we are facing at Microsoft. To address these issues, we propose Phoebe, an efficient learning-based checkpoint optimizer. Given a set of constraints and an objective function at compile-time, Phoebe is able to determine the decomposition of job plans, and the optimal set of checkpoints to preserve their outputs to durable global storage. Phoebe consists of three machine learning predictors and one optimization module. For each stage of a job, Phoebe makes accurate predictions for: (1) the execution time, (2) the output size, and (3) the start/end time taking into account the inter-stage dependencies. Using these predictions, we formulate checkpoint optimization as an integer programming problem and propose a scalable heuristic algorithm that meets the latency requirement of the production environment. We demonstrate the effectiveness of Phoebe in production workloads, and show that we can free the temporary storage on hotspots by more than 70% and restart failed jobs 68% faster on average with minimum performance impact. Phoebe also illustrates that adding multiple sets of checkpoints is not cost-efficient, which dramatically reduces the complexity of the optimization.
On Empirical Risk Minimization with Dependent and Heavy-Tailed Data
Sep 10, 2021In this work, we establish risk bounds for the Empirical Risk Minimization (ERM) with both dependent and heavy-tailed data-generating processes. We do so by extending the seminal works of Mendelson [Men15, Men18] on the analysis of ERM with heavy-tailed but independent and identically distributed observations, to the strictly stationary exponentially $\beta$-mixing case. Our analysis is based on explicitly controlling the multiplier process arising from the interaction between the noise and the function evaluations on inputs. It allows for the interaction to be even polynomially heavy-tailed, which covers a significantly large class of heavy-tailed models beyond what is analyzed in the learning theory literature. We illustrate our results by deriving rates of convergence for the high-dimensional linear regression problem with dependent and heavy-tailed data.
Escaping Saddle-Points Faster under Interpolation-like Conditions
Sep 28, 2020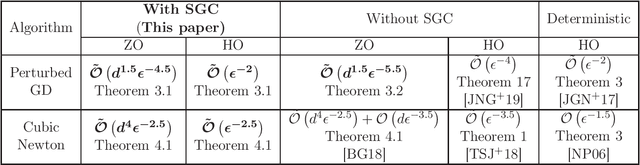
In this paper, we show that under over-parametrization several standard stochastic optimization algorithms escape saddle-points and converge to local-minimizers much faster. One of the fundamental aspects of over-parametrized models is that they are capable of interpolating the training data. We show that, under interpolation-like assumptions satisfied by the stochastic gradients in an over-parametrization setting, the first-order oracle complexity of Perturbed Stochastic Gradient Descent (PSGD) algorithm to reach an $\epsilon$-local-minimizer, matches the corresponding deterministic rate of $\tilde{\mathcal{O}}(1/\epsilon^{2})$. We next analyze Stochastic Cubic-Regularized Newton (SCRN) algorithm under interpolation-like conditions, and show that the oracle complexity to reach an $\epsilon$-local-minimizer under interpolation-like conditions, is $\tilde{\mathcal{O}}(1/\epsilon^{2.5})$. While this obtained complexity is better than the corresponding complexity of either PSGD, or SCRN without interpolation-like assumptions, it does not match the rate of $\tilde{\mathcal{O}}(1/\epsilon^{1.5})$ corresponding to deterministic Cubic-Regularized Newton method. It seems further Hessian-based interpolation-like assumptions are necessary to bridge this gap. We also discuss the corresponding improved complexities in the zeroth-order settings.
Intelligent O-RAN for Beyond 5G and 6G Wireless Networks
May 17, 2020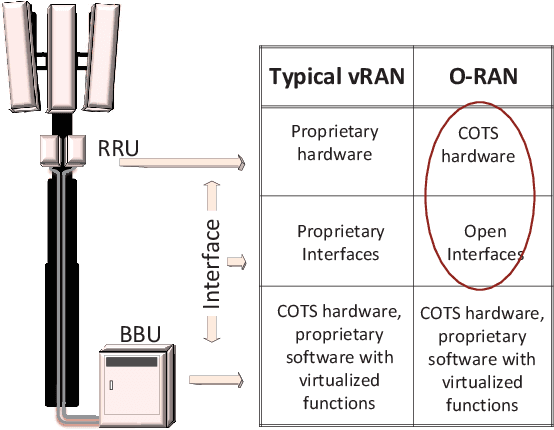
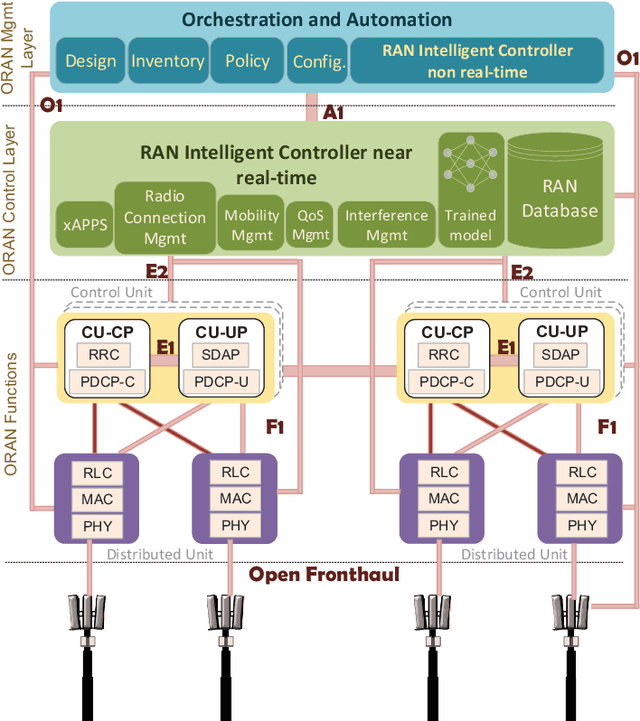
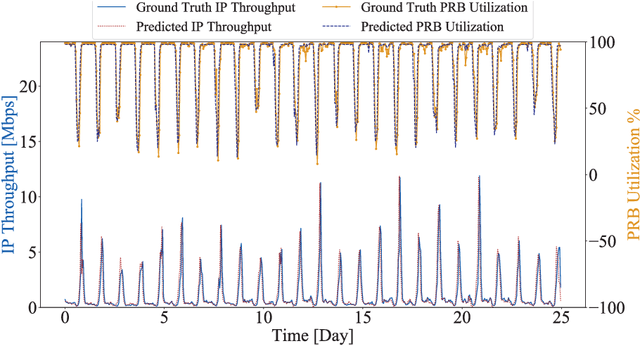
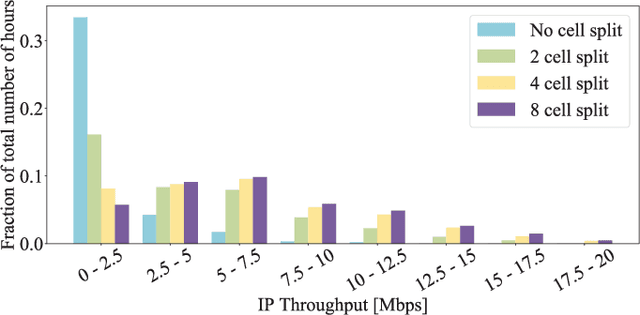
Building on the principles of openness and intelligence, there has been a concerted global effort from the operators towards enhancing the radio access network (RAN) architecture. The objective is to build an operator-defined RAN architecture (and associated interfaces) on open hardware that provides intelligent radio control for beyond fifth generation (5G) as well as future sixth generation (6G) wireless networks. Specifically, the open-radio access network (O-RAN) alliance has been formed by merging xRAN forum and C-RAN alliance to formally define the requirements that would help achieve this objective. Owing to the importance of O-RAN in the current wireless landscape, this article provides an introduction to the concepts, principles, and requirements of the Open RAN as specified by the O-RAN alliance. In order to illustrate the role of intelligence in O-RAN, we propose an intelligent radio resource management scheme to handle traffic congestion and demonstrate its efficacy on a real-world dataset obtained from a large operator. A high-level architecture of this deployment scenario that is compliant with the O-RAN requirements is also discussed. The article concludes with key technical challenges and open problems for future research and development.
Online and Bandit Algorithms for Nonstationary Stochastic Saddle-Point Optimization
Dec 03, 2019Saddle-point optimization problems are an important class of optimization problems with applications to game theory, multi-agent reinforcement learning and machine learning. A majority of the rich literature available for saddle-point optimization has focused on the offline setting. In this paper, we study nonstationary versions of stochastic, smooth, strongly-convex and strongly-concave saddle-point optimization problem, in both online (or first-order) and multi-point bandit (or zeroth-order) settings. We first propose natural notions of regret for such nonstationary saddle-point optimization problems. We then analyze extragradient and Frank-Wolfe algorithms, for the unconstrained and constrained settings respectively, for the above class of nonstationary saddle-point optimization problems. We establish sub-linear regret bounds on the proposed notions of regret in both the online and bandit setting.
Suspicion-Free Adversarial Attacks on Clustering Algorithms
Nov 16, 2019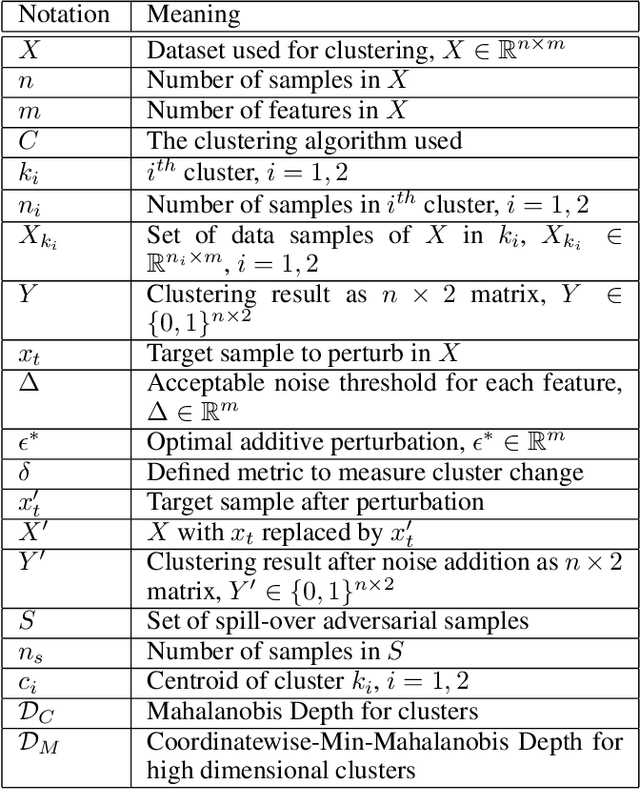

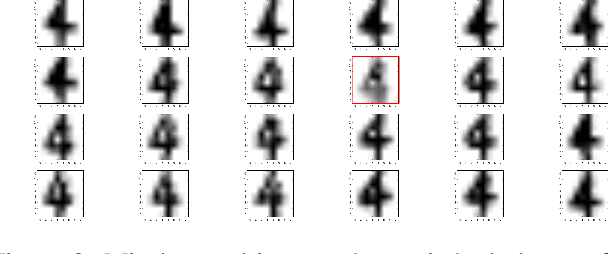

Clustering algorithms are used in a large number of applications and play an important role in modern machine learning-- yet, adversarial attacks on clustering algorithms seem to be broadly overlooked unlike supervised learning. In this paper, we seek to bridge this gap by proposing a black-box adversarial attack for clustering models for linearly separable clusters. Our attack works by perturbing a single sample close to the decision boundary, which leads to the misclustering of multiple unperturbed samples, named spill-over adversarial samples. We theoretically show the existence of such adversarial samples for the K-Means clustering. Our attack is especially strong as (1) we ensure the perturbed sample is not an outlier, hence not detectable, and (2) the exact metric used for clustering is not known to the attacker. We theoretically justify that the attack can indeed be successful without the knowledge of the true metric. We conclude by providing empirical results on a number of datasets, and clustering algorithms. To the best of our knowledge, this is the first work that generates spill-over adversarial samples without the knowledge of the true metric ensuring that the perturbed sample is not an outlier, and theoretically proves the above.
Multi-Point Bandit Algorithms for Nonstationary Online Nonconvex Optimization
Sep 11, 2019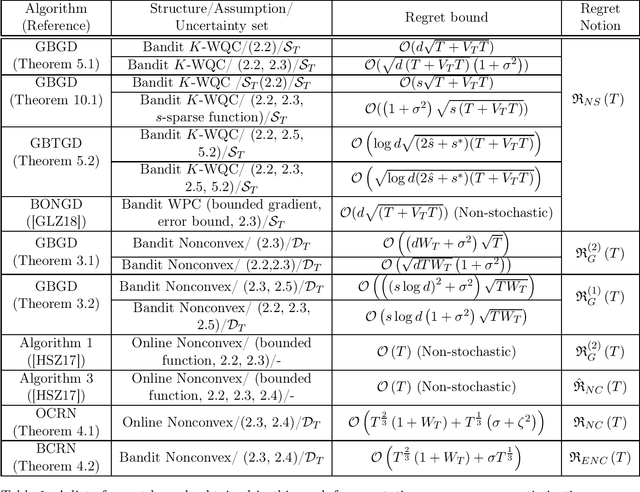
Bandit algorithms have been predominantly analyzed in the convex setting with function-value based stationary regret as the performance measure. In this paper, motivated by online reinforcement learning problems, we propose and analyze bandit algorithms for both general and structured nonconvex problems with nonstationary (or dynamic) regret as the performance measure, in both stochastic and non-stochastic settings. First, for general nonconvex functions, we consider nonstationary versions of first-order and second-order stationary solutions as a regret measure, motivated by similar performance measures for offline nonconvex optimization. In the case of second-order stationary solution based regret, we propose and analyze online and bandit versions of the cubic regularized Newton's method. The bandit version is based on estimating the Hessian matrices in the bandit setting, based on second-order Gaussian Stein's identity. Our nonstationary regret bounds in terms of second-order stationary solutions have interesting consequences for avoiding saddle points in the bandit setting. Next, for weakly quasi convex functions and monotone weakly submodular functions we consider nonstationary regret measures in terms of function-values; such structured classes of nonconvex functions enable one to consider regret measure defined in terms of function values, similar to convex functions. For this case of function-value, and first-order stationary solution based regret measures, we provide regret bounds in both the low- and high-dimensional settings, for some scenarios.
Cloudy with high chance of DBMS: A 10-year prediction for Enterprise-Grade ML
Aug 30, 2019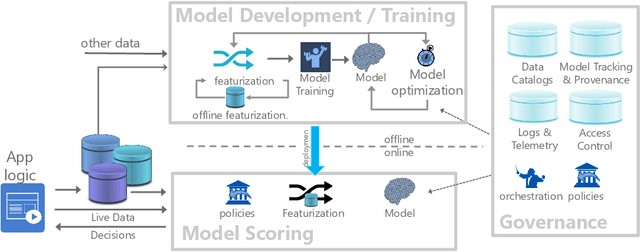
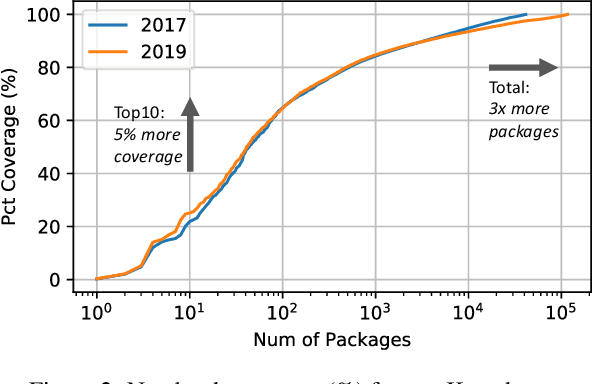
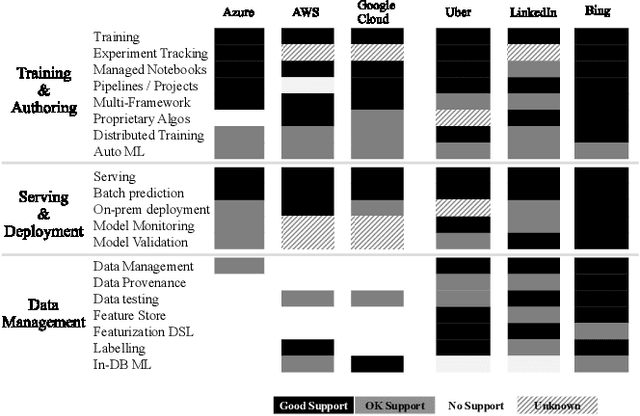
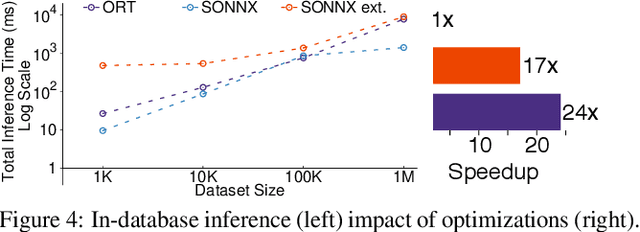
Machine learning (ML) has proven itself in high-value web applications such as search ranking and is emerging as a powerful tool in a much broader range of enterprise scenarios including voice recognition and conversational understanding for customer support, autotuning for videoconferencing, inteligent feedback loops in largescale sysops, manufacturing and autonomous vehicle management, complex financial predictions, just to name a few. Meanwhile, as the value of data is increasingly recognized and monetized, concerns about securing valuable data and risks to individual privacy have been growing. Consequently, rigorous data management has emerged as a key requirement in enterprise settings. How will these trends (ML growing popularity, and stricter data governance) intersect? What are the unmet requirements for applying ML in enterprise settings? What are the technical challenges for the DB community to solve? In this paper, we present our vision of how ML and database systems are likely to come together, and early steps we take towards making this vision a reality.
Strong Black-box Adversarial Attacks on Unsupervised Machine Learning Models
Jan 28, 2019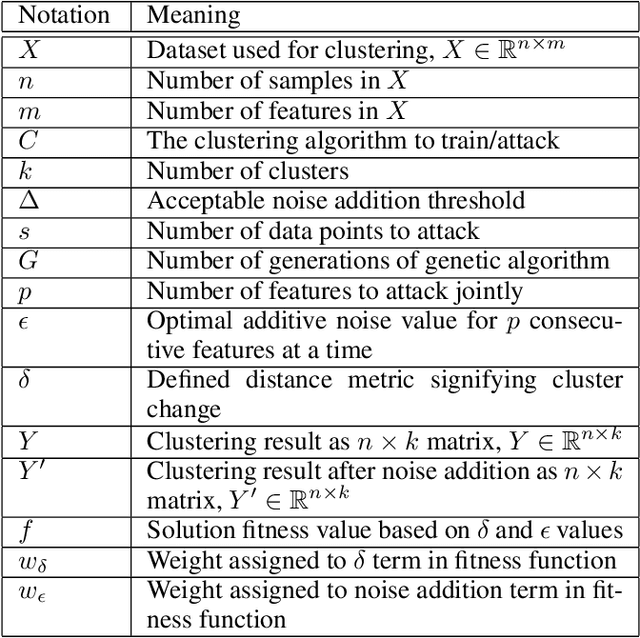
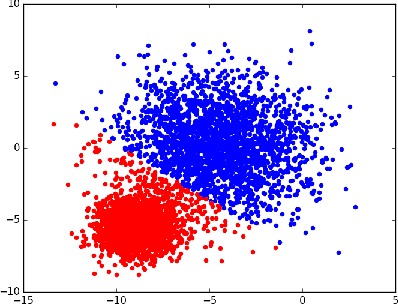
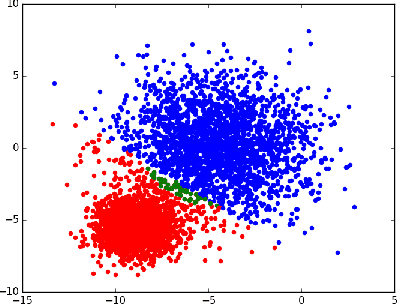

Machine Learning (ML) and Deep Learning (DL) models have achieved state-of-the-art performance on multiple learning tasks, from vision to natural language modelling. With the growing adoption of ML and DL to many areas of computer science, recent research has also started focusing on the security properties of these models. There has been a lot of work undertaken to understand if (deep) neural network architectures are resilient to black-box adversarial attacks which craft perturbed input samples that fool the classifier without knowing the architecture used. Recent work has also focused on the transferability of adversarial attacks and found that adversarial attacks are generally easily transferable between models, datasets, and techniques. However, such attacks and their analysis have not been covered from the perspective of unsupervised machine learning algorithms. In this paper, we seek to bridge this gap through multiple contributions. We first provide a strong (iterative) black-box adversarial attack that can craft adversarial samples which will be incorrectly clustered irrespective of the choice of clustering algorithm. We choose 4 prominent clustering algorithms, and a real-world dataset to show the working of the proposed adversarial algorithm. Using these clustering algorithms we also carry out a simple study of cross-technique adversarial attack transferability.