 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffuseVAE: Efficient, Controllable and High-Fidelity Generation from Low-Dimensional Latents
Jan 02, 2022
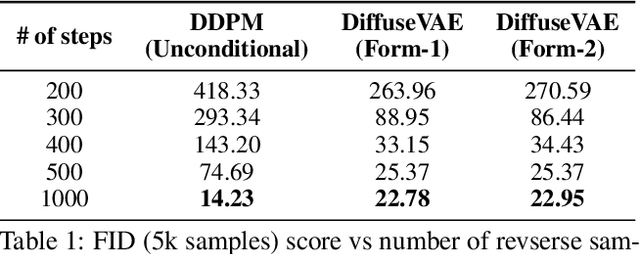
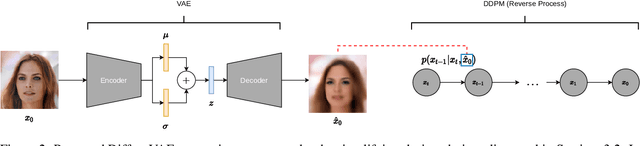
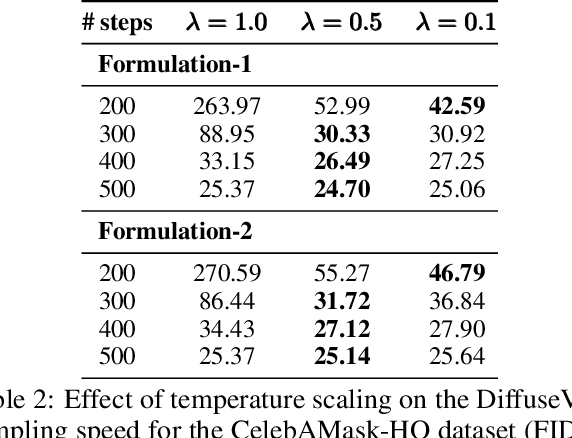
Diffusion Probabilistic models have been shown to generate state-of-the-art results on several competitive image synthesis benchmarks but lack a low-dimensional, interpretable latent space, and are slow at generation. On the other hand, Variational Autoencoders (VAEs) typically have access to a low-dimensional latent space but exhibit poor sample quality. Despite recent advances, VAEs usually require high-dimensional hierarchies of the latent codes to generate high-quality samples. We present DiffuseVAE, a novel generative framework that integrates VAE within a diffusion model framework, and leverage this to design a novel conditional parameterization for diffusion models. We show that the resulting model can improve upon the unconditional diffusion model in terms of sampling efficiency while also equipping diffusion models with the low-dimensional VAE inferred latent code. Furthermore, we show that the proposed model can generate high-resolution samples and exhibits synthesis quality comparable to state-of-the-art models on standard benchmarks. Lastly, we show that the proposed method can be used for controllable image synthesis and also exhibits out-of-the-box capabilities for downstream tasks like image super-resolution and denoising. For reproducibility, our source code is publicly available at \url{https://github.com/kpandey008/DiffuseVAE}.
Solving Inverse Problems with NerfGANs
Dec 16, 2021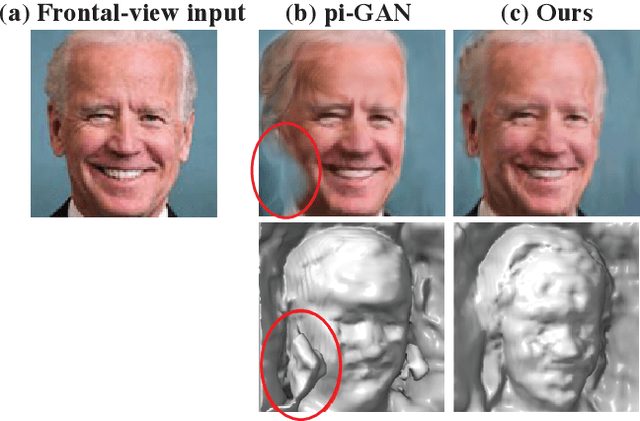
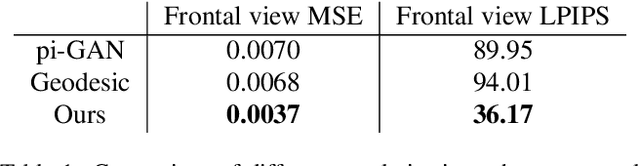

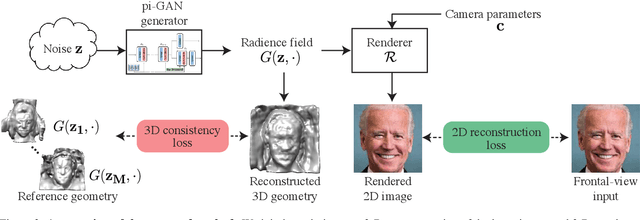
We introduce a novel framework for solving inverse problems using NeRF-style generative models. We are interested in the problem of 3-D scene reconstruction given a single 2-D image and known camera parameters. We show that naively optimizing the latent space leads to artifacts and poor novel view rendering. We attribute this problem to volume obstructions that are clear in the 3-D geometry and become visible in the renderings of novel views. We propose a novel radiance field regularization method to obtain better 3-D surfaces and improved novel views given single view observations. Our method naturally extends to general inverse problems including inpainting where one observes only partially a single view. We experimentally evaluate our method, achieving visual improvements and performance boosts over the baselines in a wide range of tasks. Our method achieves $30-40\%$ MSE reduction and $15-25\%$ reduction in LPIPS loss compared to the previous state of the art.
When Creators Meet the Metaverse: A Survey on Computational Arts
Nov 26, 2021

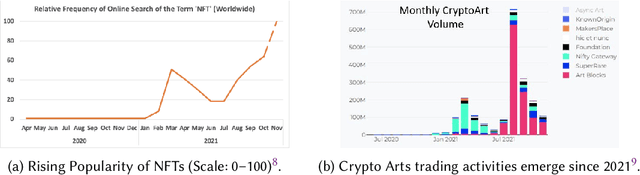

The metaverse, enormous virtual-physical cyberspace, has brought unprecedented opportunities for artists to blend every corner of our physical surroundings with digital creativity. This article conducts a comprehensive survey on computational arts, in which seven critical topics are relevant to the metaverse, describing novel artworks in blended virtual-physical realities. The topics first cover the building elements for the metaverse, e.g., virtual scenes and characters, auditory, textual elements. Next, several remarkable types of novel creations in the expanded horizons of metaverse cyberspace have been reflected, such as immersive arts, robotic arts, and other user-centric approaches fuelling contemporary creative outputs. Finally, we propose several research agendas: democratising computational arts, digital privacy, and safety for metaverse artists, ownership recognition for digital artworks, technological challenges, and so on. The survey also serves as introductory material for artists and metaverse technologists to begin creations in the realm of surrealistic cyberspace.
Constrained Instance and Class Reweighting for Robust Learning under Label Noise
Nov 09, 2021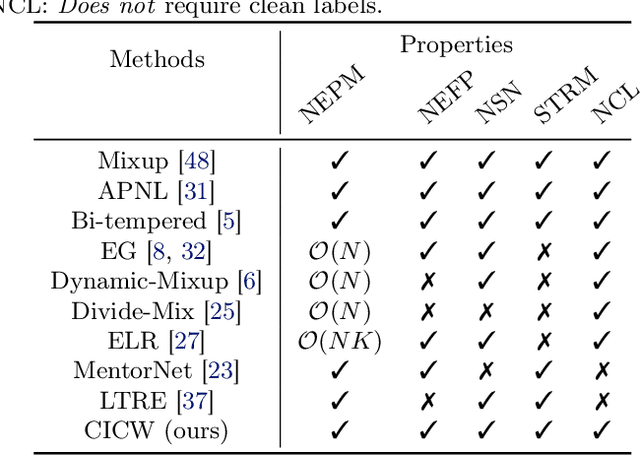
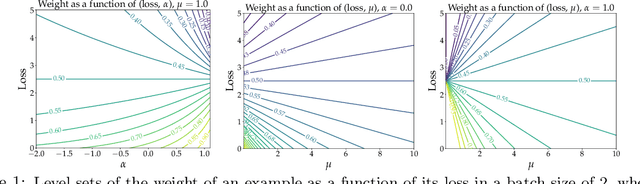
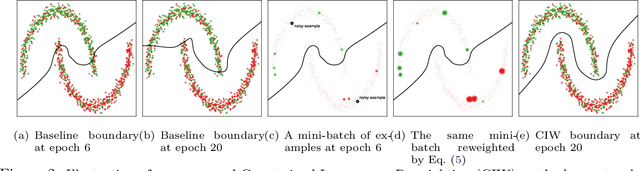
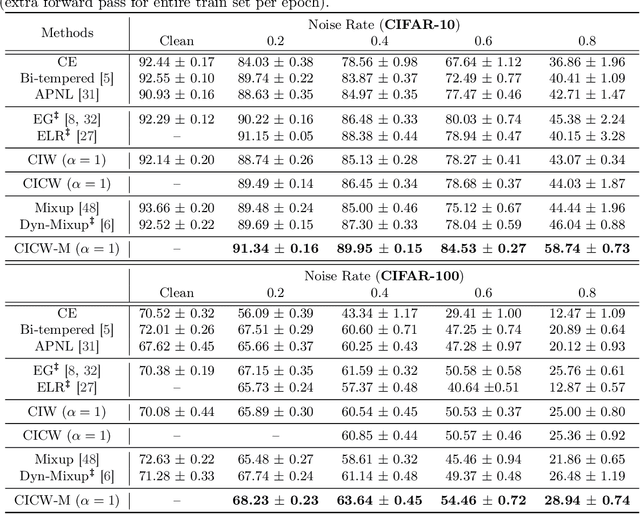
Deep neural networks have shown impressive performance in supervised learning, enabled by their ability to fit well to the provided training data. However, their performance is largely dependent on the quality of the training data and often degrades in the presence of noise. We propose a principled approach for tackling label noise with the aim of assigning importance weights to individual instances and class labels. Our method works by formulating a class of constrained optimization problems that yield simple closed form updates for these importance weights. The proposed optimization problems are solved per mini-batch which obviates the need of storing and updating the weights over the full dataset. Our optimization framework also provides a theoretical perspective on existing label smoothing heuristics for addressing label noise (such as label bootstrapping). We evaluate our method on several benchmark datasets and observe considerable performance gains in the presence of label noise.
Exploring System Performance of Continual Learning for Mobile and Embedded Sensing Applications
Oct 25, 2021
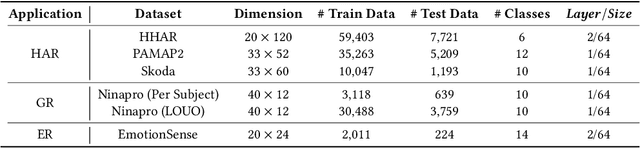
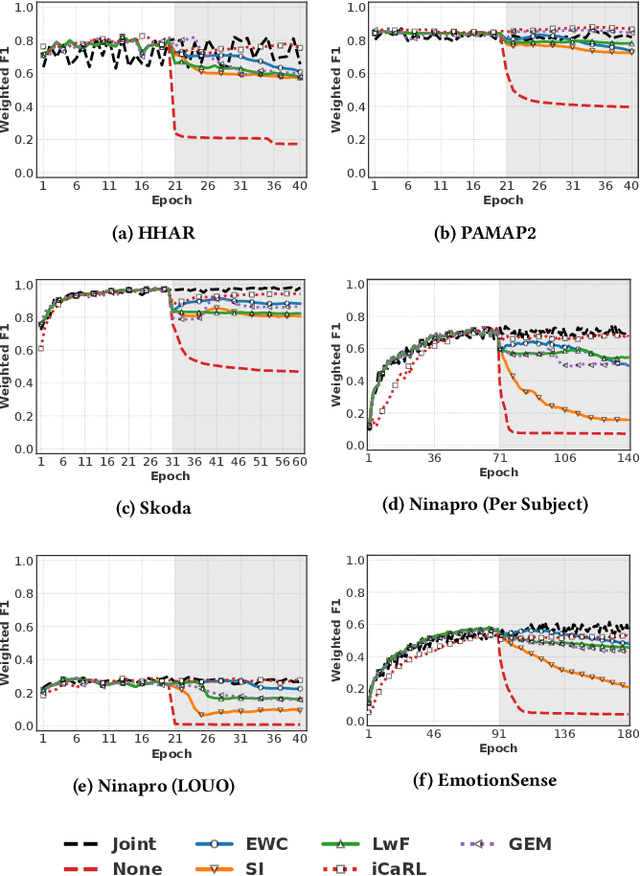
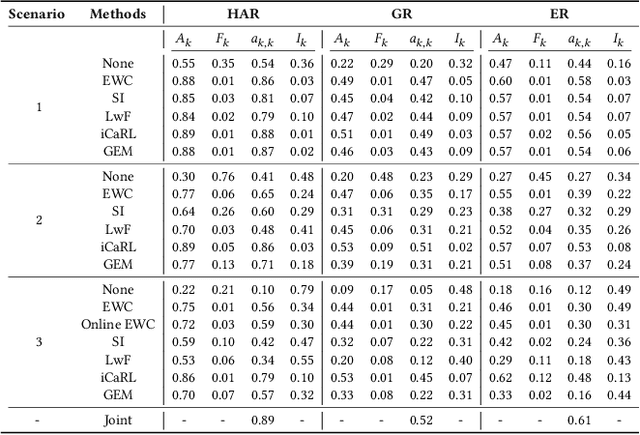
Continual learning approaches help deep neural network models adapt and learn incrementally by trying to solve catastrophic forgetting. However, whether these existing approaches, applied traditionally to image-based tasks, work with the same efficacy to the sequential time series data generated by mobile or embedded sensing systems remains an unanswered question. To address this void, we conduct the first comprehensive empirical study that quantifies the performance of three predominant continual learning schemes (i.e., regularization, replay, and replay with examples) on six datasets from three mobile and embedded sensing applications in a range of scenarios having different learning complexities. More specifically, we implement an end-to-end continual learning framework on edge devices. Then we investigate the generalizability, trade-offs between performance, storage, computational costs, and memory footprint of different continual learning methods. Our findings suggest that replay with exemplars-based schemes such as iCaRL has the best performance trade-offs, even in complex scenarios, at the expense of some storage space (few MBs) for training examples (1% to 5%). We also demonstrate for the first time that it is feasible and practical to run continual learning on-device with a limited memory budget. In particular, the latency on two types of mobile and embedded devices suggests that both incremental learning time (few seconds - 4 minutes) and training time (1 - 75 minutes) across datasets are acceptable, as training could happen on the device when the embedded device is charging thereby ensuring complete data privacy. Finally, we present some guidelines for practitioners who want to apply a continual learning paradigm for mobile sensing tasks.
Implicit Rate-Constrained Optimization of Non-decomposable Objectives
Jul 29, 2021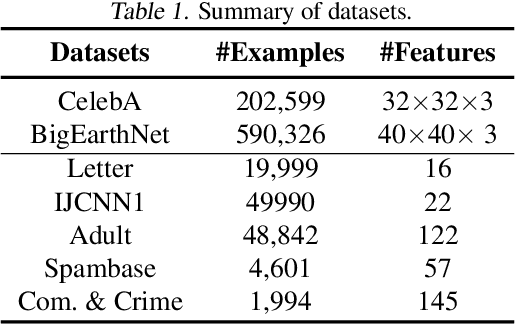


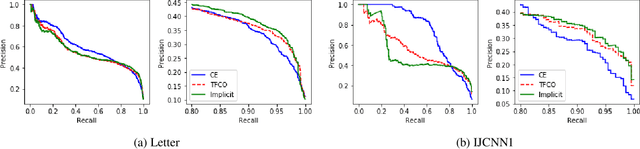
We consider a popular family of constrained optimization problems arising in machine learning that involve optimizing a non-decomposable evaluation metric with a certain thresholded form, while constraining another metric of interest. Examples of such problems include optimizing the false negative rate at a fixed false positive rate, optimizing precision at a fixed recall, optimizing the area under the precision-recall or ROC curves, etc. Our key idea is to formulate a rate-constrained optimization that expresses the threshold parameter as a function of the model parameters via the Implicit Function theorem. We show how the resulting optimization problem can be solved using standard gradient based methods. Experiments on benchmark datasets demonstrate the effectiveness of our proposed method over existing state-of-the art approaches for these problems. The code for the proposed method is available at https://github.com/google-research/google-research/tree/master/implicit_constrained_optimization .
Wavelet Design in a Learning Framework
Jul 23, 2021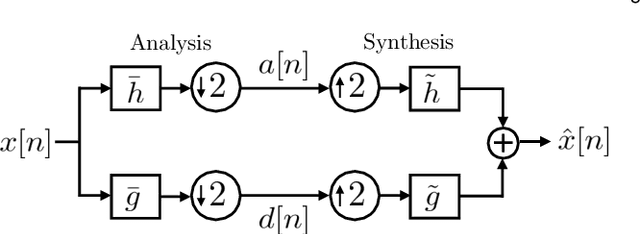
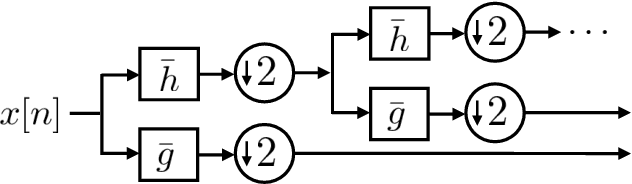
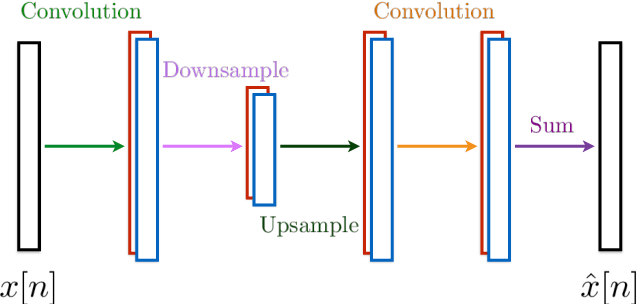
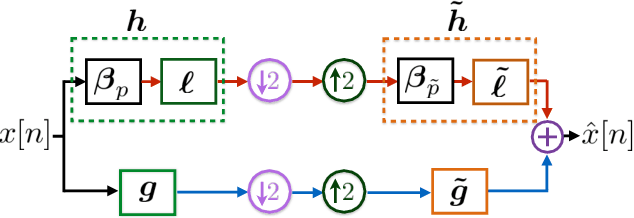
Wavelets have proven to be highly successful in several signal and image processing applications. Wavelet design has been an active field of research for over two decades, with the problem often being approached from an analytical perspective. In this paper, we introduce a learning based approach to wavelet design. We draw a parallel between convolutional autoencoders and wavelet multiresolution approximation, and show how the learning angle provides a coherent computational framework for addressing the design problem. We aim at designing data-independent wavelets by training filterbank autoencoders, which precludes the need for customized datasets. In fact, we use high-dimensional Gaussian vectors for training filterbank autoencoders, and show that a near-zero training loss implies that the learnt filters satisfy the perfect reconstruction property with very high probability. Properties of a wavelet such as orthogonality, compact support, smoothness, symmetry, and vanishing moments can be incorporated by designing the autoencoder architecture appropriately and with a suitable regularization term added to the mean-squared error cost used in the learning process. Our approach not only recovers the well known Daubechies family of orthogonal wavelets and the Cohen-Daubechies-Feauveau family of symmetric biorthogonal wavelets, but also learns wavelets outside these families.
Retrieve in Style: Unsupervised Facial Feature Transfer and Retrieval
Jul 17, 2021
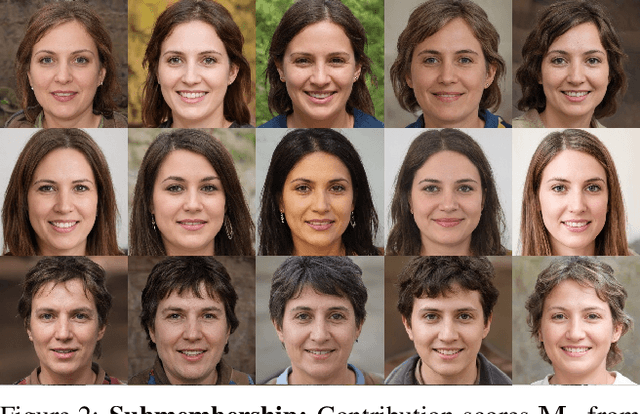
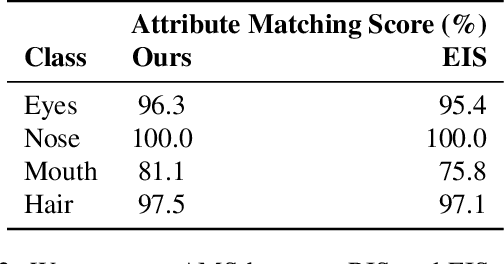

We present Retrieve in Style (RIS), an unsupervised framework for fine-grained facial feature transfer and retrieval on real images. Recent work shows that it is possible to learn a catalog that allows local semantic transfers of facial features on generated images by capitalizing on the disentanglement property of the StyleGAN latent space. RIS improves existing art on: 1) feature disentanglement and allows for challenging transfers (i.e., hair and pose) that were not shown possible in SoTA methods. 2) eliminating the need for per-image hyperparameter tuning, and for computing a catalog over a large batch of images. 3) enabling face retrieval using the proposed facial features (e.g., eyes), and to our best knowledge, is the first work to retrieve face images at the fine-grained level. 4) robustness and natural application to real images. Our qualitative and quantitative analyses show RIS achieves both high-fidelity feature transfers and accurate fine-grained retrievals on real images. We discuss the responsible application of RIS.
Risk score learning for COVID-19 contact tracing apps
Apr 17, 2021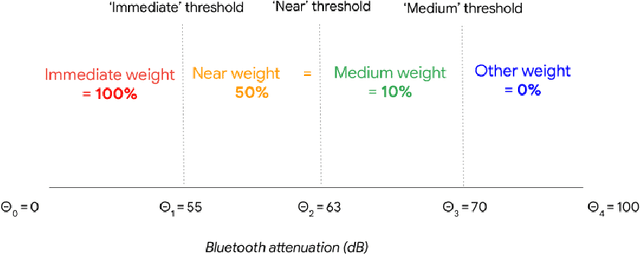
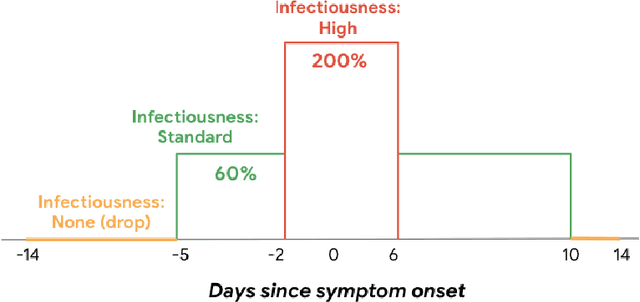
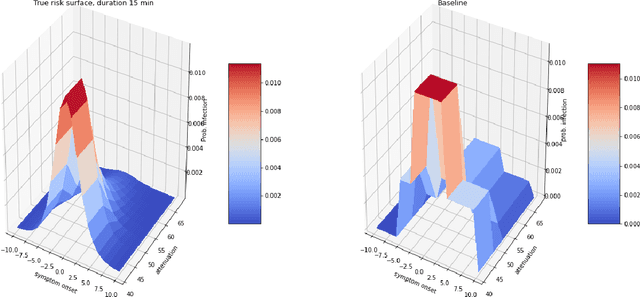
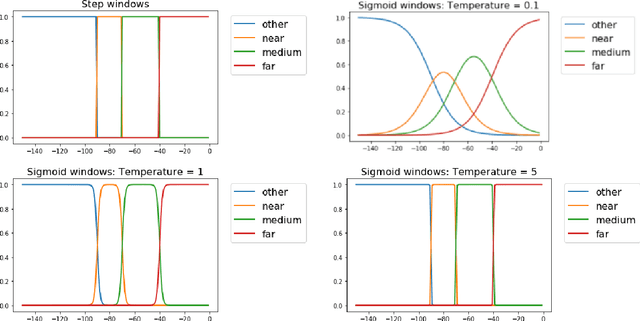
Digital contact tracing apps for COVID-19, such as the one developed by Google and Apple, need to estimate the risk that a user was infected during a particular exposure, in order to decide whether to notify the user to take precautions, such as entering into quarantine, or requesting a test. Such risk score models contain numerous parameters that must be set by the public health authority. Although expert guidance for how to set these parameters has been provided (e.g. https://github.com/lfph/gaen-risk-scoring/blob/main/risk-scoring.md), it is natural to ask if we could do better using a data-driven approach. This can be particularly useful when the risk factors of the disease change, e.g., due to the evolution of new variants, or the adoption of vaccines. In this paper, we show that machine learning methods can be used to automatically optimize the parameters of the risk score model, provided we have access to exposure and outcome data. Although this data is already being collected in an aggregated, privacy-preserving way by several health authorities, in this paper we limit ourselves to simulated data, so that we can systematically study the different factors that affect the feasibility of the approach. In particular, we show that the parameters become harder to estimate when there is more missing data (e.g., due to infections which were not recorded by the app). Nevertheless, the learning approach outperforms a strong manually designed baseline.
Score-Based Generative Modeling through Stochastic Differential Equations
Nov 26, 2020
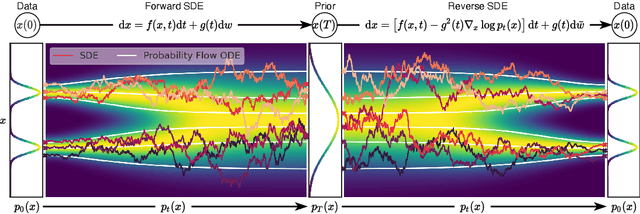

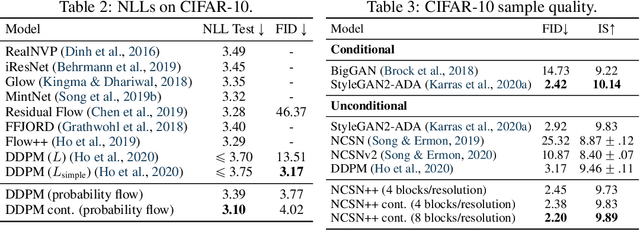
Creating noise from data is easy; creating data from noise is generative modeling. We present a stochastic differential equation (SDE) that smoothly transforms a complex data distribution to a known prior distribution by slowly injecting noise, and a corresponding reverse-time SDE that transforms the prior distribution back into the data distribution by slowly removing the noise. Crucially, the reverse-time SDE depends only on the time-dependent gradient field (a.k.a., score) of the perturbed data distribution. By leveraging advances in score-based generative modeling, we can accurately estimate these scores with neural networks, and use numerical SDE solvers to generate samples. We show that this framework encapsulates previous approaches in diffusion probabilistic modeling and score-based generative modeling, and allows for new sampling procedures. In particular, we introduce a predictor-corrector framework to correct errors in the evolution of the discretized reverse-time SDE. We also derive an equivalent neural ODE that samples from the same distribution as the SDE, which enables exact likelihood computation, and improved sampling efficiency. In addition, our framework enables conditional generation with an unconditional model, as we demonstrate with experiments on class-conditional generation, image inpainting, and colorization. Combined with multiple architectural improvements, we achieve record-breaking performance for unconditional image generation on CIFAR-10 with an Inception score of 9.89 and FID of 2.20, a competitive likelihood of 3.10 bits/dim, and demonstrate high fidelity generation of $1024 \times 1024$ images for the first time from a score-based generative model.