 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRefute-or-Promote: An Adversarial Stage-Gated Multi-Agent Review Methodology for High-Precision LLM-Assisted Defect Discovery
Apr 21, 2026LLM-assisted defect discovery has a precision crisis: plausible-but-wrong reports overwhelm maintainers and degrade credibility for real findings. We present Refute-or-Promote, an inference-time reliability pattern combining Stratified Context Hunting (SCH) for candidate generation, adversarial kill mandates, context asymmetry, and a Cross-Model Critic (CMC). Adversarial agents attempt to disprove candidates at each promotion gate; cold-start reviewers are intended to reduce anchoring cascades; cross-family review can catch correlated blind spots that same-family review misses. Over a 31-day campaign across 7 targets (security libraries, the ISO C++ standard, major compilers), the pipeline killed roughly 79% of 171 candidates before advancing to disclosure (retrospective aggregate); on a consolidated-protocol subset (lcms2, wolfSSL; n=30), the prospective kill rate was 83%. Outcomes: 4 CVEs (3 public, 1 embargoed); LWG 4549 accepted to the C++ working paper; 5 merged C++ editorial PRs; 3 compiler conformance bugs; 8 merged security-related fixes without CVE; an RFC 9000 errata filed under committee review; and 1+ FIPS 140-3 normative compliance issues under coordinated disclosure -- all evaluated by external acceptance, not benchmarks. The most instructive failure: ten dedicated reviewers unanimously endorsed a non-existent Bleichenbacher padding oracle in OpenSSL's CMS module; it was killed only by a single empirical test, motivating the mandatory empirical gate. No vulnerability was discovered autonomously; the contribution is external structure that filters LLM agents' persistent false positives. As a preliminary transfer test beyond defect discovery, a simplified cross-family critique variant also solved five previously unsolved SymPy instances on SWE-bench Verified and one SWE-rebench hard task.
Empirical Analysis of Sim-and-Real Cotraining Of Diffusion Policies For Planar Pushing from Pixels
Mar 28, 2025In imitation learning for robotics, cotraining with demonstration data generated both in simulation and on real hardware has emerged as a powerful recipe to overcome the sim2real gap. This work seeks to elucidate basic principles of this sim-and-real cotraining to help inform simulation design, sim-and-real dataset creation, and policy training. Focusing narrowly on the canonical task of planar pushing from camera inputs enabled us to be thorough in our study. These experiments confirm that cotraining with simulated data \emph{can} dramatically improve performance in real, especially when real data is limited. Performance gains scale with simulated data, but eventually plateau; real-world data increases this performance ceiling. The results also suggest that reducing the domain gap in physics may be more important than visual fidelity for non-prehensile manipulation tasks. Perhaps surprisingly, having some visual domain gap actually helps the cotrained policy -- binary probes reveal that high-performing policies learn to distinguish simulated domains from real. We conclude by investigating this nuance and mechanisms that facilitate positive transfer between sim-and-real. In total, our experiments span over 40 real-world policies (evaluated on 800+ trials) and 200 simulated policies (evaluated on 40,000+ trials).
Stronger Generalization Guarantees for Robot Learning by Combining Generative Models and Real-World Data
Nov 16, 2021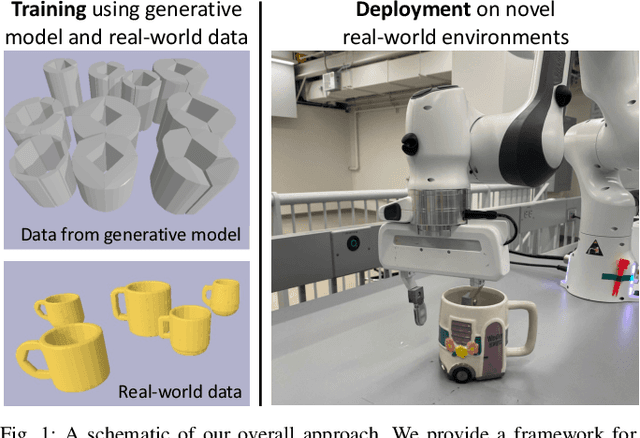
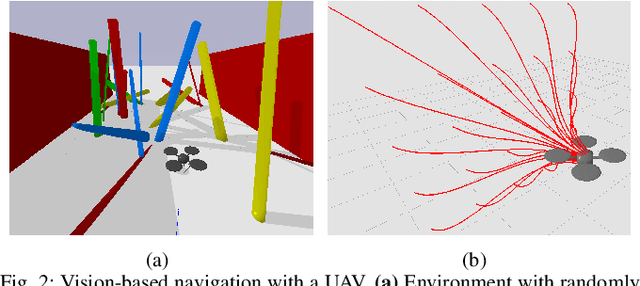
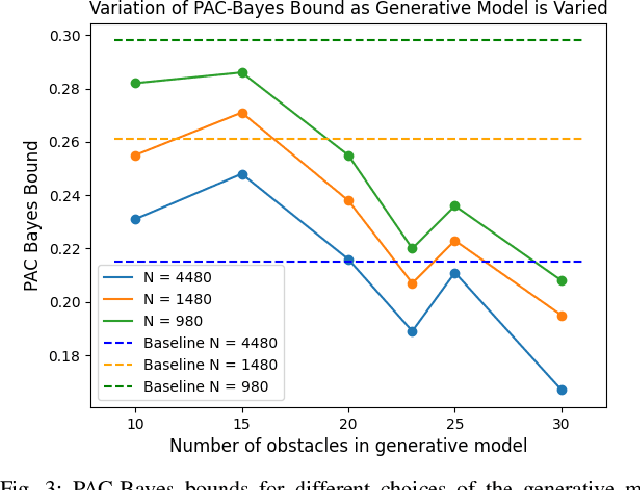

We are motivated by the problem of learning policies for robotic systems with rich sensory inputs (e.g., vision) in a manner that allows us to guarantee generalization to environments unseen during training. We provide a framework for providing such generalization guarantees by leveraging a finite dataset of real-world environments in combination with a (potentially inaccurate) generative model of environments. The key idea behind our approach is to utilize the generative model in order to implicitly specify a prior over policies. This prior is updated using the real-world dataset of environments by minimizing an upper bound on the expected cost across novel environments derived via Probably Approximately Correct (PAC)-Bayes generalization theory. We demonstrate our approach on two simulated systems with nonlinear/hybrid dynamics and rich sensing modalities: (i) quadrotor navigation with an onboard vision sensor, and (ii) grasping objects using a depth sensor. Comparisons with prior work demonstrate the ability of our approach to obtain stronger generalization guarantees by utilizing generative models. We also present hardware experiments for validating our bounds for the grasping task.