 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeControlling biases and diversity in diverse image-to-image translation
Jul 23, 2019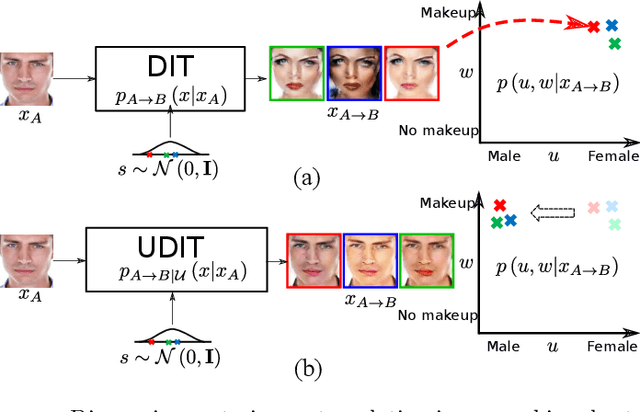



The task of unpaired image-to-image translation is highly challenging due to the lack of explicit cross-domain pairs of instances. We consider here diverse image translation (DIT), an even more challenging setting in which an image can have multiple plausible translations. This is normally achieved by explicitly disentangling content and style in the latent representation and sampling different styles codes while maintaining the image content. Despite the success of current DIT models, they are prone to suffer from bias. In this paper, we study the problem of bias in image-to-image translation. Biased datasets may add undesired changes (e.g. change gender or race in face images) to the output translations as a consequence of the particular underlying visual distribution in the target domain. In order to alleviate the effects of this problem we propose the use of semantic constraints that enforce the preservation of desired image properties. Our proposed model is a step towards unbiased diverse image-to-image translation (UDIT), and results in less unwanted changes in the translated images while still performing the wanted transformation. Experiments on several heavily biased datasets show the effectiveness of the proposed techniques in different domains such as faces, objects, and scenes.
Image-to-image translation for cross-domain disentanglement
Nov 04, 2018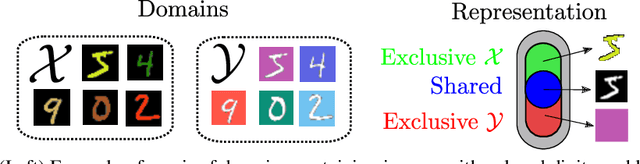
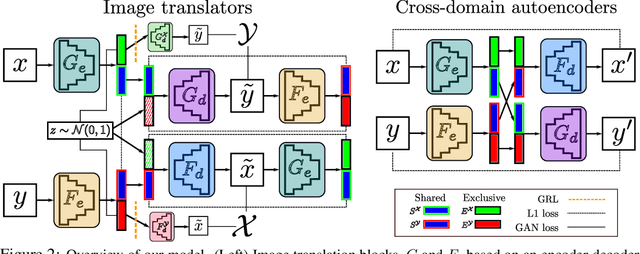
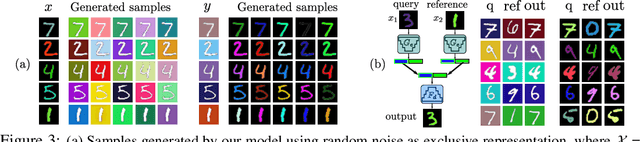

Deep image translation methods have recently shown excellent results, outputting high-quality images covering multiple modes of the data distribution. There has also been increased interest in disentangling the internal representations learned by deep methods to further improve their performance and achieve a finer control. In this paper, we bridge these two objectives and introduce the concept of cross-domain disentanglement. We aim to separate the internal representation into three parts. The shared part contains information for both domains. The exclusive parts, on the other hand, contain only factors of variation that are particular to each domain. We achieve this through bidirectional image translation based on Generative Adversarial Networks and cross-domain autoencoders, a novel network component. Our model offers multiple advantages. We can output diverse samples covering multiple modes of the distributions of both domains, perform domain-specific image transfer and interpolation, and cross-domain retrieval without the need of labeled data, only paired images. We compare our model to the state-of-the-art in multi-modal image translation and achieve better results for translation on challenging datasets as well as for cross-domain retrieval on realistic datasets.
Transferring GANs: generating images from limited data
Oct 02, 2018
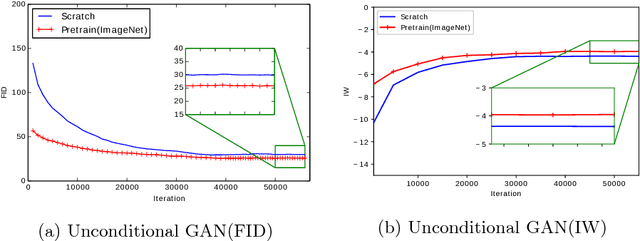

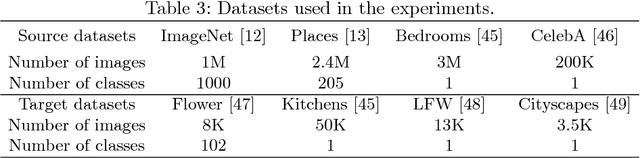
Transferring the knowledge of pretrained networks to new domains by means of finetuning is a widely used practice for applications based on discriminative models. To the best of our knowledge this practice has not been studied within the context of generative deep networks. Therefore, we study domain adaptation applied to image generation with generative adversarial networks. We evaluate several aspects of domain adaptation, including the impact of target domain size, the relative distance between source and target domain, and the initialization of conditional GANs. Our results show that using knowledge from pretrained networks can shorten the convergence time and can significantly improve the quality of the generated images, especially when the target data is limited. We show that these conclusions can also be drawn for conditional GANs even when the pretrained model was trained without conditioning. Our results also suggest that density may be more important than diversity and a dataset with one or few densely sampled classes may be a better source model than more diverse datasets such as ImageNet or Places.
Synthetic data generation for end-to-end thermal infrared tracking
Sep 26, 2018

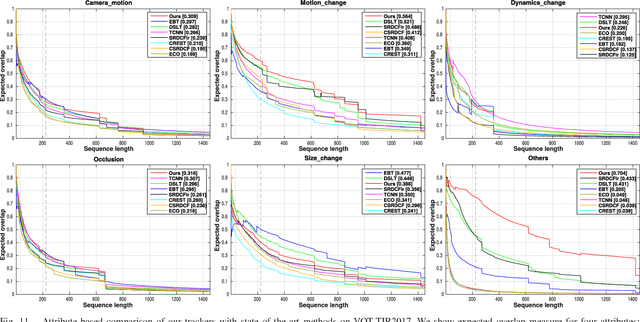
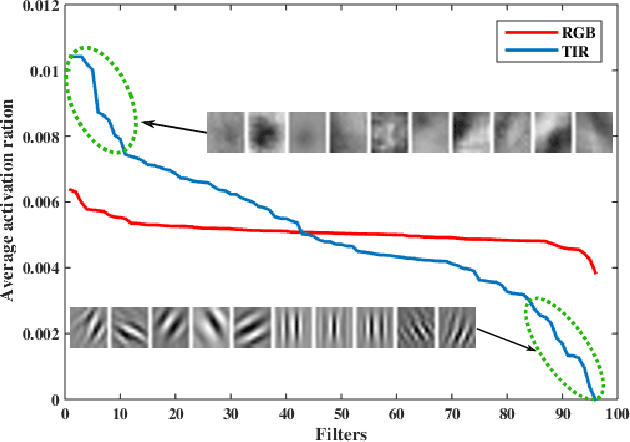
The usage of both off-the-shelf and end-to-end trained deep networks have significantly improved performance of visual tracking on RGB videos. However, the lack of large labeled datasets hampers the usage of convolutional neural networks for tracking in thermal infrared (TIR) images. Therefore, most state of the art methods on tracking for TIR data are still based on handcrafted features. To address this problem, we propose to use image-to-image translation models. These models allow us to translate the abundantly available labeled RGB data to synthetic TIR data. We explore both the usage of paired and unpaired image translation models for this purpose. These methods provide us with a large labeled dataset of synthetic TIR sequences, on which we can train end-to-end optimal features for tracking. To the best of our knowledge we are the first to train end-to-end features for TIR tracking. We perform extensive experiments on VOT-TIR2017 dataset. We show that a network trained on a large dataset of synthetic TIR data obtains better performance than one trained on the available real TIR data. Combining both data sources leads to further improvement. In addition, when we combine the network with motion features we outperform the state of the art with a relative gain of over 10%, clearly showing the efficiency of using synthetic data to train end-to-end TIR trackers.
Objects as context for detecting their semantic parts
Mar 27, 2018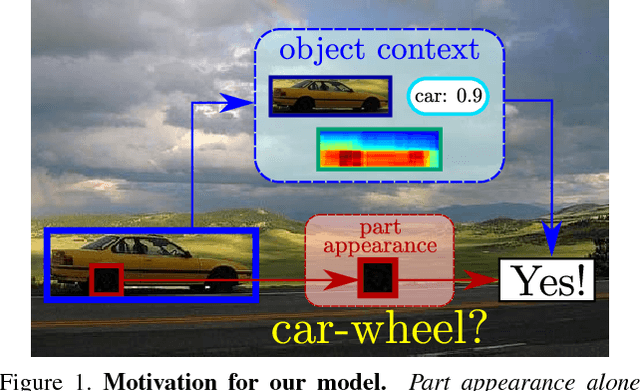
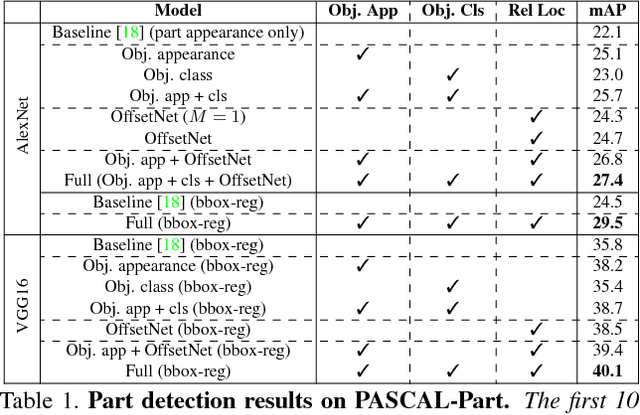
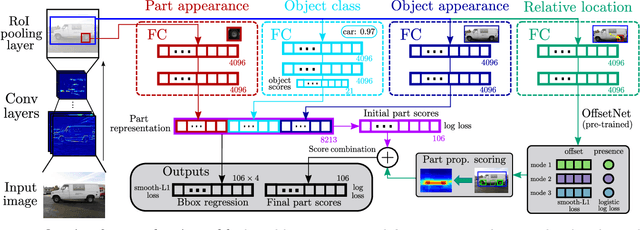
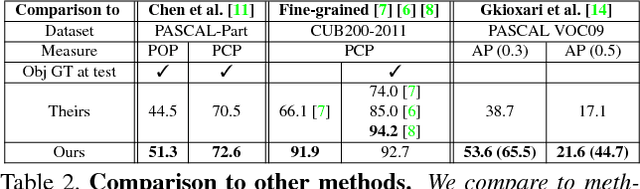
We present a semantic part detection approach that effectively leverages object information.We use the object appearance and its class as indicators of what parts to expect. We also model the expected relative location of parts inside the objects based on their appearance. We achieve this with a new network module, called OffsetNet, that efficiently predicts a variable number of part locations within a given object. Our model incorporates all these cues to detect parts in the context of their objects. This leads to considerably higher performance for the challenging task of part detection compared to using part appearance alone (+5 mAP on the PASCAL-Part dataset). We also compare to other part detection methods on both PASCAL-Part and CUB200-2011 datasets.
Do semantic parts emerge in Convolutional Neural Networks?
Sep 20, 2017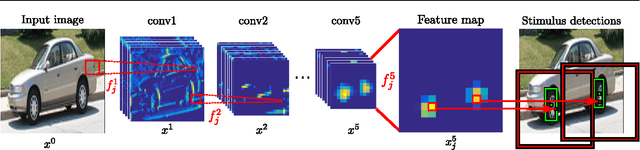
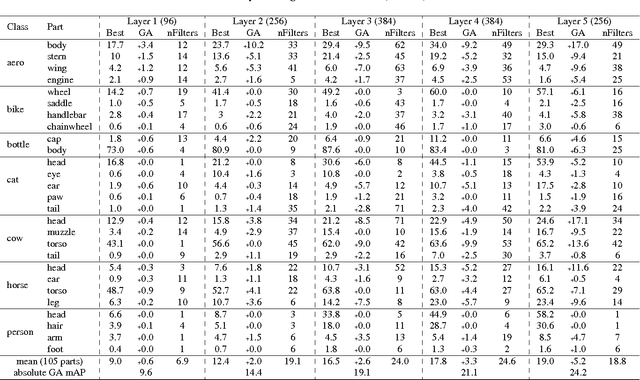

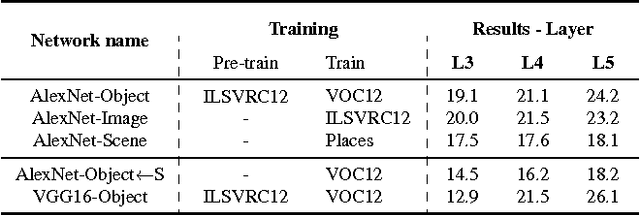
Semantic object parts can be useful for several visual recognition tasks. Lately, these tasks have been addressed using Convolutional Neural Networks (CNN), achieving outstanding results. In this work we study whether CNNs learn semantic parts in their internal representation. We investigate the responses of convolutional filters and try to associate their stimuli with semantic parts. We perform two extensive quantitative analyses. First, we use ground-truth part bounding-boxes from the PASCAL-Part dataset to determine how many of those semantic parts emerge in the CNN. We explore this emergence for different layers, network depths, and supervision levels. Second, we collect human judgements in order to study what fraction of all filters systematically fire on any semantic part, even if not annotated in PASCAL-Part. Moreover, we explore several connections between discriminative power and semantics. We find out which are the most discriminative filters for object recognition, and analyze whether they respond to semantic parts or to other image patches. We also investigate the other direction: we determine which semantic parts are the most discriminative and whether they correspond to those parts emerging in the network. This enables to gain an even deeper understanding of the role of semantic parts in the network.
An active search strategy for efficient object class detection
Apr 14, 2015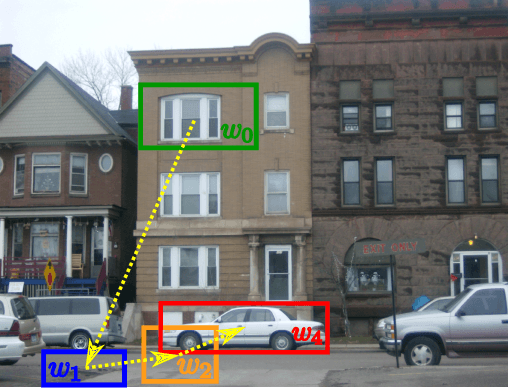
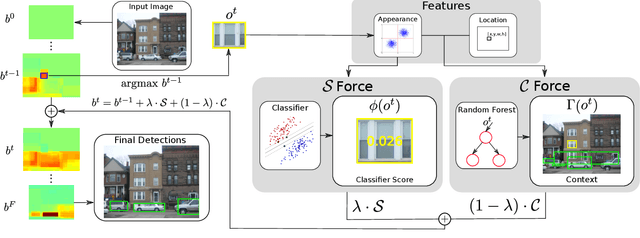
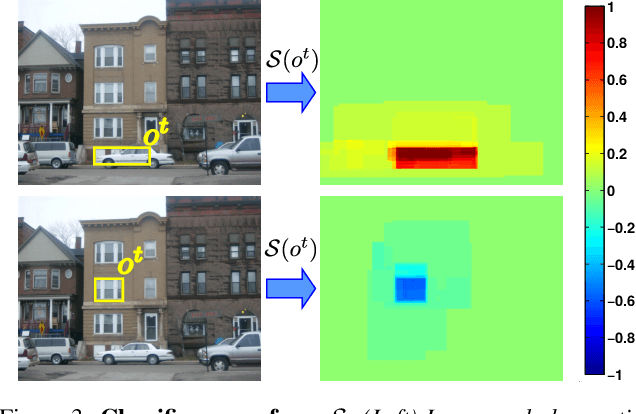
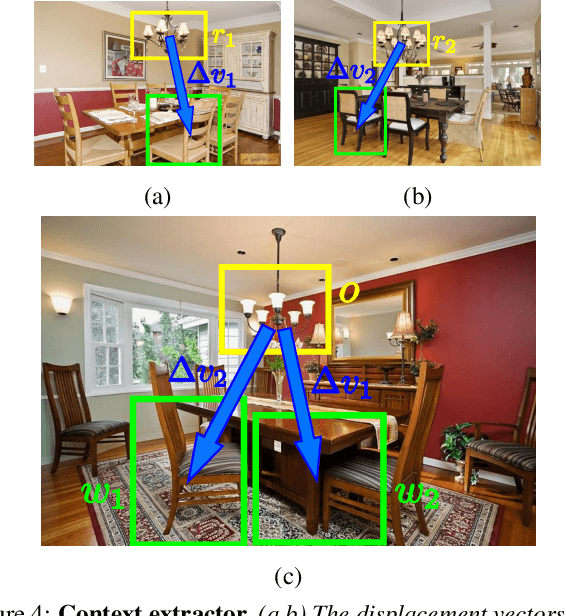
Object class detectors typically apply a window classifier to all the windows in a large set, either in a sliding window manner or using object proposals. In this paper, we develop an active search strategy that sequentially chooses the next window to evaluate based on all the information gathered before. This results in a substantial reduction in the number of classifier evaluations and in a more elegant approach in general. Our search strategy is guided by two forces. First, we exploit context as the statistical relation between the appearance of a window and its location relative to the object, as observed in the training set. This enables to jump across distant regions in the image (e.g. observing a sky region suggests that cars might be far below) and is done efficiently in a Random Forest framework. Second, we exploit the score of the classifier to attract the search to promising areas surrounding a highly scored window, and to keep away from areas near low scored ones. Our search strategy can be applied on top of any classifier as it treats it as a black-box. In experiments with R-CNN on the challenging SUN2012 dataset, our method matches the detection accuracy of evaluating all windows independently, while evaluating 9x fewer windows.