 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeObject localization in ImageNet by looking out of the window
Aug 04, 2015
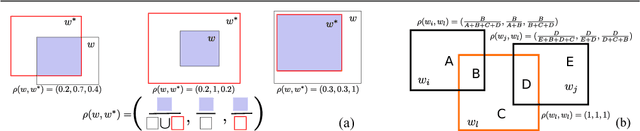
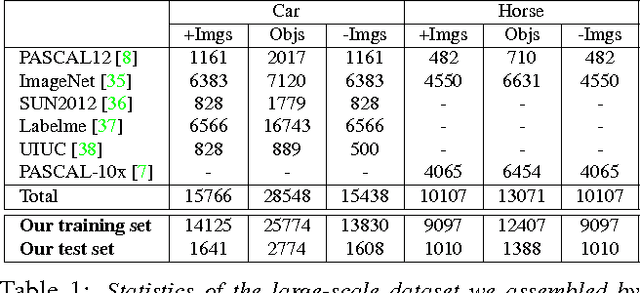
We propose a method for annotating the location of objects in ImageNet. Traditionally, this is cast as an image window classification problem, where each window is considered independently and scored based on its appearance alone. Instead, we propose a method which scores each candidate window in the context of all other windows in the image, taking into account their similarity in appearance space as well as their spatial relations in the image plane. We devise a fast and exact procedure to optimize our scoring function over all candidate windows in an image, and we learn its parameters using structured output regression. We demonstrate on 92000 images from ImageNet that this significantly improves localization over recent techniques that score windows in isolation.
Joint calibration of Ensemble of Exemplar SVMs
Apr 24, 2015

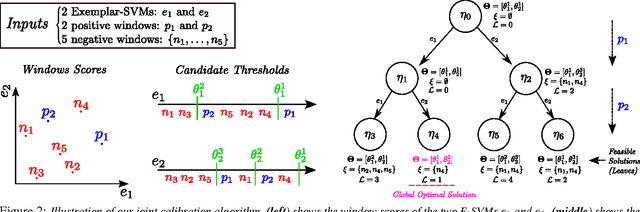

We present a method for calibrating the Ensemble of Exemplar SVMs model. Unlike the standard approach, which calibrates each SVM independently, our method optimizes their joint performance as an ensemble. We formulate joint calibration as a constrained optimization problem and devise an efficient optimization algorithm to find its global optimum. The algorithm dynamically discards parts of the solution space that cannot contain the optimum early on, making the optimization computationally feasible. We experiment with EE-SVM trained on state-of-the-art CNN descriptors. Results on the ILSVRC 2014 and PASCAL VOC 2007 datasets show that (i) our joint calibration procedure outperforms independent calibration on the task of classifying windows as belonging to an object class or not; and (ii) this improved window classifier leads to better performance on the object detection task.
An active search strategy for efficient object class detection
Apr 14, 2015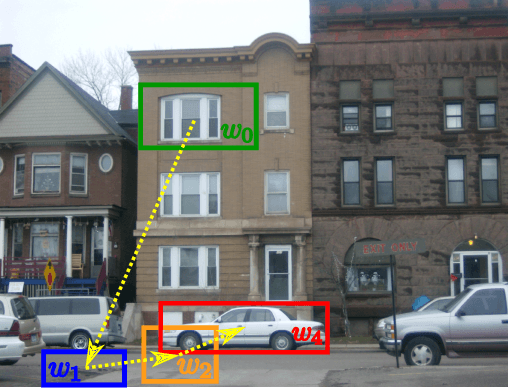
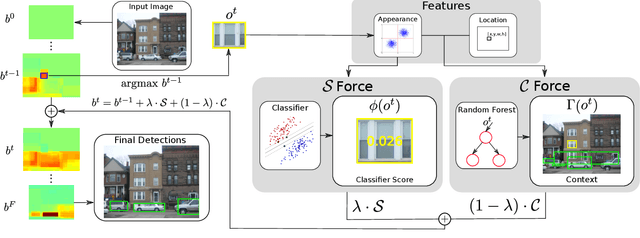
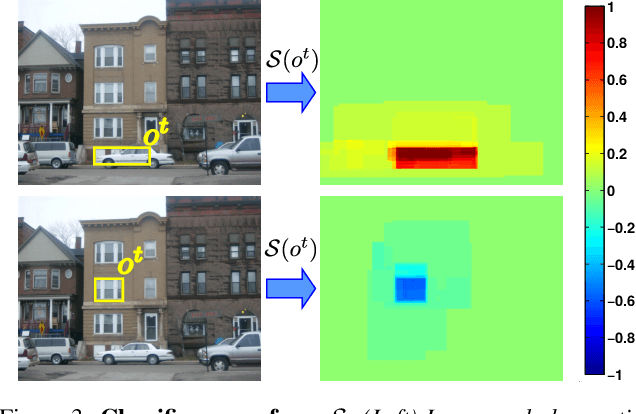
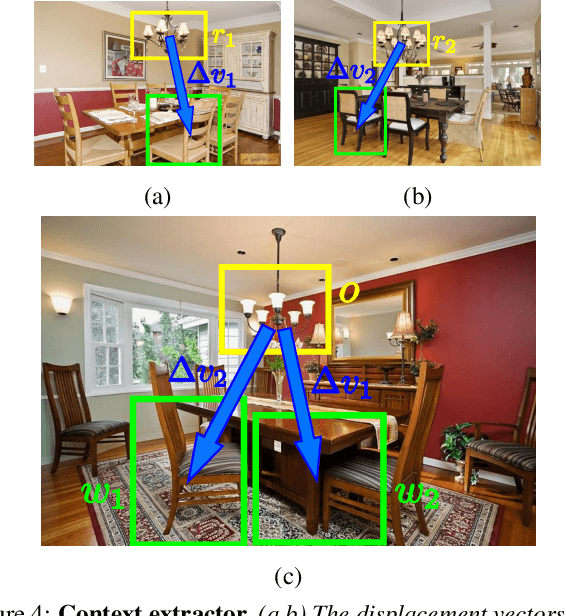
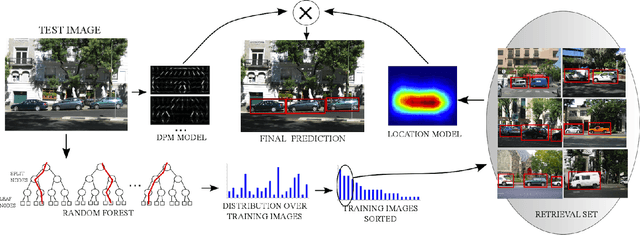
Object class detectors typically apply a window classifier to all the windows in a large set, either in a sliding window manner or using object proposals. In this paper, we develop an active search strategy that sequentially chooses the next window to evaluate based on all the information gathered before. This results in a substantial reduction in the number of classifier evaluations and in a more elegant approach in general. Our search strategy is guided by two forces. First, we exploit context as the statistical relation between the appearance of a window and its location relative to the object, as observed in the training set. This enables to jump across distant regions in the image (e.g. observing a sky region suggests that cars might be far below) and is done efficiently in a Random Forest framework. Second, we exploit the score of the classifier to attract the search to promising areas surrounding a highly scored window, and to keep away from areas near low scored ones. Our search strategy can be applied on top of any classifier as it treats it as a black-box. In experiments with R-CNN on the challenging SUN2012 dataset, our method matches the detection accuracy of evaluating all windows independently, while evaluating 9x fewer windows.
Context Forest for efficient object detection with large mixture models
Mar 03, 2015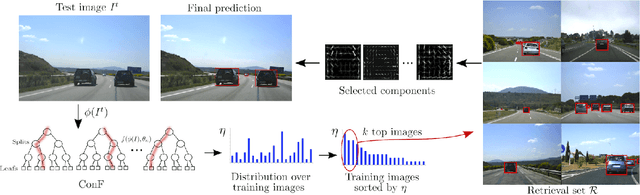

We present Context Forest (ConF), a technique for predicting properties of the objects in an image based on its global appearance. Compared to standard nearest-neighbour techniques, ConF is more accurate, fast and memory efficient. We train ConF to predict which aspects of an object class are likely to appear in a given image (e.g. which viewpoint). This enables to speed-up multi-component object detectors, by automatically selecting the most relevant components to run on that image. This is particularly useful for detectors trained from large datasets, which typically need many components to fully absorb the data and reach their peak performance. ConF provides a speed-up of 2x for the DPM detector [1] and of 10x for the EE-SVM detector [2]. To show ConF's generality, we also train it to predict at which locations objects are likely to appear in an image. Incorporating this information in the detector score improves mAP performance by about 2% by removing false positive detections in unlikely locations.
Associative embeddings for large-scale knowledge transfer with self-assessment
Jul 30, 2014
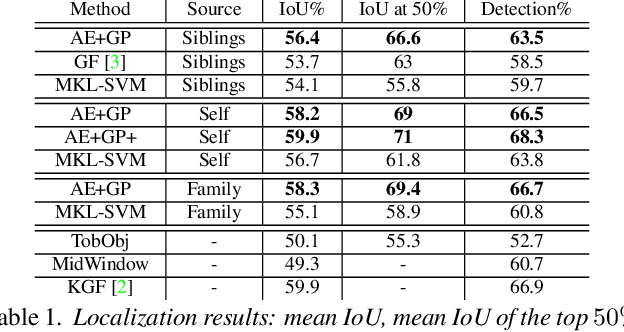
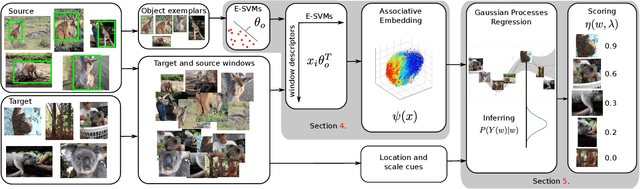
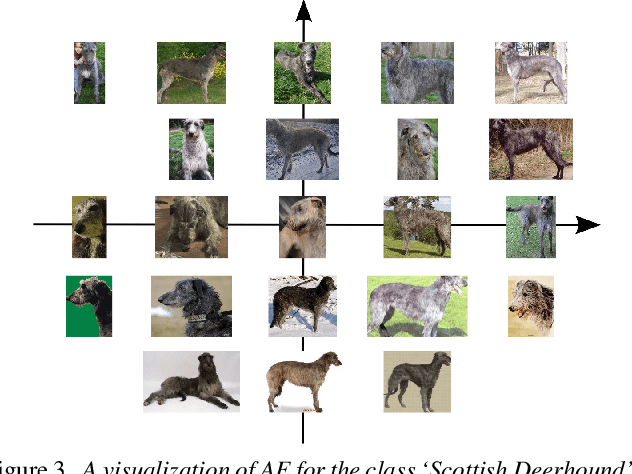
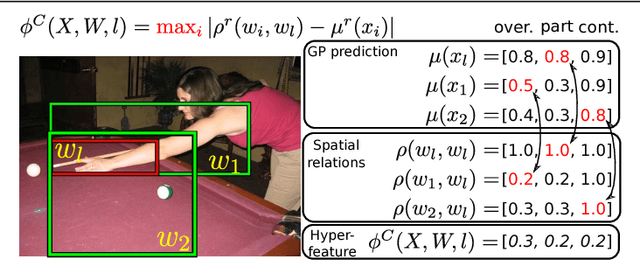
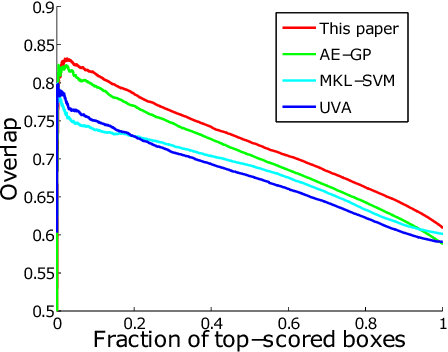
We propose a method for knowledge transfer between semantically related classes in ImageNet. By transferring knowledge from the images that have bounding-box annotations to the others, our method is capable of automatically populating ImageNet with many more bounding-boxes and even pixel-level segmentations. The underlying assumption that objects from semantically related classes look alike is formalized in our novel Associative Embedding (AE) representation. AE recovers the latent low-dimensional space of appearance variations among image windows. The dimensions of AE space tend to correspond to aspects of window appearance (e.g. side view, close up, background). We model the overlap of a window with an object using Gaussian Processes (GP) regression, which spreads annotation smoothly through AE space. The probabilistic nature of GP allows our method to perform self-assessment, i.e. assigning a quality estimate to its own output. It enables trading off the amount of returned annotations for their quality. A large scale experiment on 219 classes and 0.5 million images demonstrates that our method outperforms state-of-the-art methods and baselines for both object localization and segmentation. Using self-assessment we can automatically return bounding-box annotations for 30% of all images with high localization accuracy (i.e.~73% average overlap with ground-truth).