 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual Foresight for Robotic Stow: A Diffusion-Based World Model from Sparse Snapshots
Feb 12, 2026Automated warehouses execute millions of stow operations, where robots place objects into storage bins. For these systems it is valuable to anticipate how a bin will look from the current observations and the planned stow behavior before real execution. We propose FOREST, a stow-intent-conditioned world model that represents bin states as item-aligned instance masks and uses a latent diffusion transformer to predict the post-stow configuration from the observed context. Our evaluation shows that FOREST substantially improves the geometric agreement between predicted and true post-stow layouts compared with heuristic baselines. We further evaluate the predicted post-stow layouts in two downstream tasks, in which replacing the real post-stow masks with FOREST predictions causes only modest performance loss in load-quality assessment and multi-stow reasoning, indicating that our model can provide useful foresight signals for warehouse planning.
Stow: Robotic Packing of Items into Fabric Pods
May 07, 2025



This paper presents a compliant manipulation system capable of placing items onto densely packed shelves. The wide diversity of items and strict business requirements for high producing rates and low defect generation have prohibited warehouse robotics from performing this task. Our innovations in hardware, perception, decision-making, motion planning, and control have enabled this system to perform over 500,000 stows in a large e-commerce fulfillment center. The system achieves human levels of packing density and speed while prioritizing work on overhead shelves to enhance the safety of humans working alongside the robots.
Improving Visual Feature Extraction in Glacial Environments
Aug 27, 2019

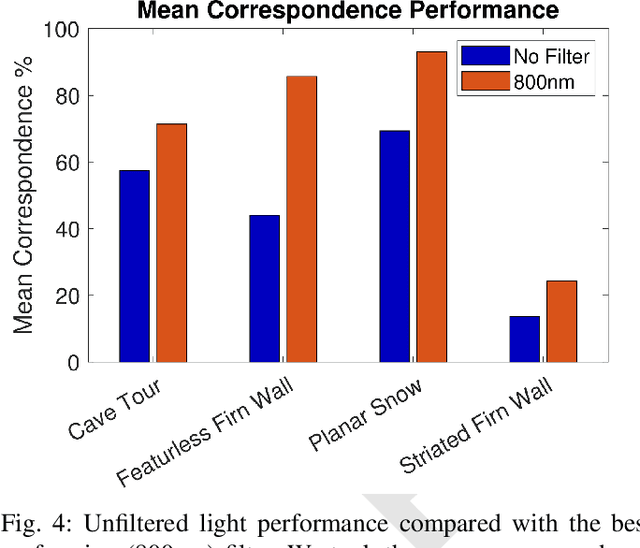
Glacial science could benefit tremendously from autonomous robots, but previous glacial robots have had perception issues in these colorless and featureless environments, specifically with visual feature extraction. Glaciologists use near-infrared imagery to reveal the underlying heterogeneous spatial structure of snow and ice, and we theorize that this hidden near-infrared structure could produce more and higher quality features than available in visible light. We took a custom camera rig to Igloo Cave at Mt. St. Helens to test our theory. The camera rig contains two identical machine vision cameras, one which was outfitted with multiple filters to see only near-infrared light. We extracted features from short video clips taken inside Igloo Cave at Mt. St. Helens, using three popular feature extractors (FAST, SIFT, and SURF). We quantified the number of features and their quality for visual navigation using feature correspondence and the epipolar constraint. Our results indicate that near-infrared imagery produces more features that tend to be of higher quality than that of visible light imagery.