 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRed-Teaming Vision-Language-Action Models via Quality Diversity Prompt Generation for Robust Robot Policies
Mar 12, 2026Vision-Language-Action (VLA) models have significant potential to enable general-purpose robotic systems for a range of vision-language tasks. However, the performance of VLA-based robots is highly sensitive to the precise wording of language instructions, and it remains difficult to predict when such robots will fail. To improve the robustness of VLAs to different wordings, we present Q-DIG (Quality Diversity for Diverse Instruction Generation), which performs red-teaming by scalably identifying diverse natural language task descriptions that induce failures while remaining task-relevant. Q-DIG integrates Quality Diversity (QD) techniques with Vision-Language Models (VLMs) to generate a broad spectrum of adversarial instructions that expose meaningful vulnerabilities in VLA behavior. Our results across multiple simulation benchmarks show that Q-DIG finds more diverse and meaningful failure modes compared to baseline methods, and that fine-tuning VLAs on the generated instructions improves task success rates. Furthermore, results from a user study highlight that Q-DIG generates prompts judged to be more natural and human-like than those from baselines. Finally, real-world evaluations of Q-DIG prompts show results consistent with simulation, and fine-tuning VLAs on the generated prompts further success rates on unseen instructions. Together, these findings suggest that Q-DIG is a promising approach for identifying vulnerabilities and improving the robustness of VLA-based robots. Our anonymous project website is at qdigvla.github.io.
Algorithmic Prompt Generation for Diverse Human-like Teaming and Communication with Large Language Models
Apr 04, 2025



Understanding how humans collaborate and communicate in teams is essential for improving human-agent teaming and AI-assisted decision-making. However, relying solely on data from large-scale user studies is impractical due to logistical, ethical, and practical constraints, necessitating synthetic models of multiple diverse human behaviors. Recently, agents powered by Large Language Models (LLMs) have been shown to emulate human-like behavior in social settings. But, obtaining a large set of diverse behaviors requires manual effort in the form of designing prompts. On the other hand, Quality Diversity (QD) optimization has been shown to be capable of generating diverse Reinforcement Learning (RL) agent behavior. In this work, we combine QD optimization with LLM-powered agents to iteratively search for prompts that generate diverse team behavior in a long-horizon, multi-step collaborative environment. We first show, through a human-subjects experiment (n=54 participants), that humans exhibit diverse coordination and communication behavior in this domain. We then show that our approach can effectively replicate trends from human teaming data and also capture behaviors that are not easily observed without collecting large amounts of data. Our findings highlight the combination of QD and LLM-powered agents as an effective tool for studying teaming and communication strategies in multi-agent collaboration.
One-shot Policy Elicitation via Semantic Reward Manipulation
Jan 06, 2021
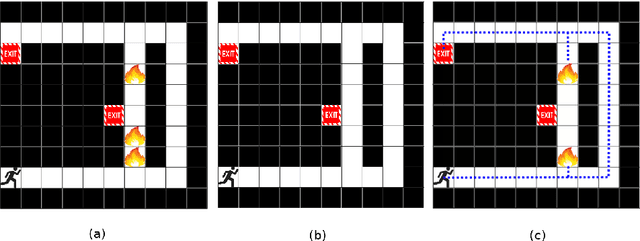
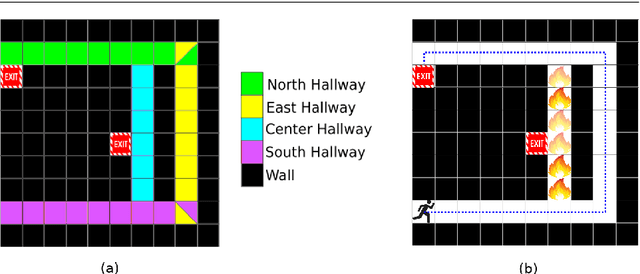

Synchronizing expectations and knowledge about the state of the world is an essential capability for effective collaboration. For robots to effectively collaborate with humans and other autonomous agents, it is critical that they be able to generate intelligible explanations to reconcile differences between their understanding of the world and that of their collaborators. In this work we present Single-shot Policy Explanation for Augmenting Rewards (SPEAR), a novel sequential optimization algorithm that uses semantic explanations derived from combinations of planning predicates to augment agents' reward functions, driving their policies to exhibit more optimal behavior. We provide an experimental validation of our algorithm's policy manipulation capabilities in two practically grounded applications and conclude with a performance analysis of SPEAR on domains of increasingly complex state space and predicate counts. We demonstrate that our method makes substantial improvements over the state-of-the-art in terms of runtime and addressable problem size, enabling an agent to leverage its own expertise to communicate actionable information to improve another's performance.
Automated Failure-Mode Clustering and Labeling for Informed Car-To-Driver Handover in Autonomous Vehicles
May 09, 2020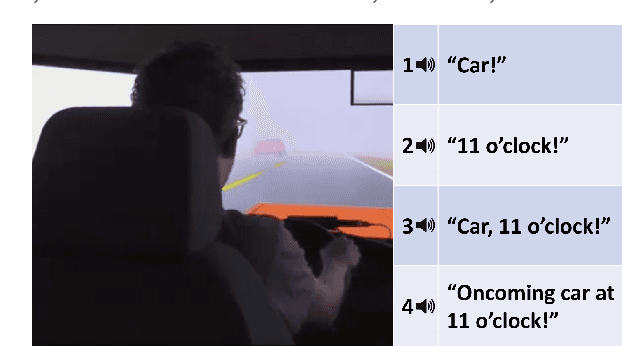
The car-to-driver handover is a critically important component of safe autonomous vehicle operation when the vehicle is unable to safely proceed on its own. Current implementations of this handover in automobiles take the form of a generic alarm indicating an imminent transfer of control back to the human driver. However, certain levels of vehicle autonomy may allow the driver to engage in other, non-driving related tasks prior to a handover, leading to substantial difficulty in quickly regaining situational awareness. This delay in re-orientation could potentially lead to life-threatening failures unless mitigating steps are taken. Explainable AI has been shown to improve fluency and teamwork in human-robot collaboration scenarios. Therefore, we hypothesize that by utilizing autonomous explanation, these car-to-driver handovers can be performed more safely and reliably. The rationale is, by providing the driver with additional situational knowledge, they will more rapidly focus on the relevant parts of the driving environment. Towards this end, we propose an algorithmic failure-mode identification and explanation approach to enable informed handovers from vehicle to driver. Furthermore, we propose a set of human-subjects driving-simulator studies to determine the appropriate form of explanation during handovers, as well as validate our framework.