 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetection of Suicidal Risk on Social Media: A Hybrid Model
May 26, 2025Suicidal thoughts and behaviors are increasingly recognized as a critical societal concern, highlighting the urgent need for effective tools to enable early detection of suicidal risk. In this work, we develop robust machine learning models that leverage Reddit posts to automatically classify them into four distinct levels of suicide risk severity. We frame this as a multi-class classification task and propose a RoBERTa-TF-IDF-PCA Hybrid model, integrating the deep contextual embeddings from Robustly Optimized BERT Approach (RoBERTa), a state-of-the-art deep learning transformer model, with the statistical term-weighting of TF-IDF, further compressed with PCA, to boost the accuracy and reliability of suicide risk assessment. To address data imbalance and overfitting, we explore various data resampling techniques and data augmentation strategies to enhance model generalization. Additionally, we compare our model's performance against that of using RoBERTa only, the BERT model and other traditional machine learning classifiers. Experimental results demonstrate that the hybrid model can achieve improved performance, giving a best weighted $F_{1}$ score of 0.7512.
One-shot Policy Elicitation via Semantic Reward Manipulation
Jan 06, 2021
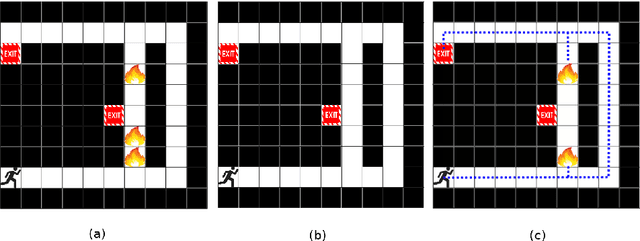
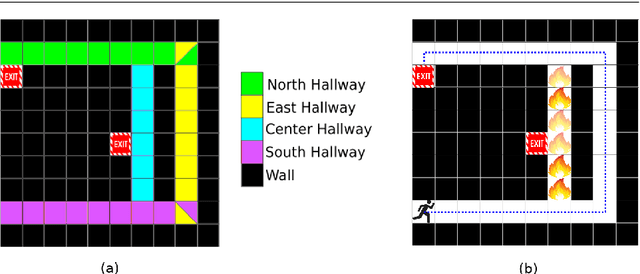

Synchronizing expectations and knowledge about the state of the world is an essential capability for effective collaboration. For robots to effectively collaborate with humans and other autonomous agents, it is critical that they be able to generate intelligible explanations to reconcile differences between their understanding of the world and that of their collaborators. In this work we present Single-shot Policy Explanation for Augmenting Rewards (SPEAR), a novel sequential optimization algorithm that uses semantic explanations derived from combinations of planning predicates to augment agents' reward functions, driving their policies to exhibit more optimal behavior. We provide an experimental validation of our algorithm's policy manipulation capabilities in two practically grounded applications and conclude with a performance analysis of SPEAR on domains of increasingly complex state space and predicate counts. We demonstrate that our method makes substantial improvements over the state-of-the-art in terms of runtime and addressable problem size, enabling an agent to leverage its own expertise to communicate actionable information to improve another's performance.