 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeValet: A Standardized Testbed of Traditional Imperfect-Information Card Games
Mar 03, 2026AI algorithms for imperfect-information games are typically compared using performance metrics on individual games, making it difficult to assess robustness across game choices. Card games are a natural domain for imperfect information due to hidden hands and stochastic draws. To facilitate comparative research on imperfect-information game-playing algorithms and game systems, we introduce Valet, a diverse and comprehensive testbed of 21 traditional imperfect-information card games. These games span multiple genres, cultures, player counts, deck structures, mechanics, winning conditions, and methods of hiding and revealing information. To standardize implementations across systems, we encode the rules of each game in RECYCLE, a card game description language. We empirically characterize each game's branching factor and duration using random simulations, reporting baseline score distributions for a Monte Carlo Tree Search player against random opponents to demonstrate the suitability of Valet as a benchmarking suite.
Generalized Rapid Action Value Estimation in Memory-Constrained Environments
Feb 26, 2026Generalized Rapid Action Value Estimation (GRAVE) has been shown to be a strong variant within the Monte-Carlo Tree Search (MCTS) family of algorithms for General Game Playing (GGP). However, its reliance on storing additional win/visit statistics at each node makes its use impractical in memory-constrained environments, thereby limiting its applicability in practice. In this paper, we introduce the GRAVE2, GRAVER and GRAVER2 algorithms, which extend GRAVE through two-level search, node recycling, and a combination of both techniques, respectively. We show that these enhancements enable a drastic reduction in the number of stored nodes while matching the playing strength of GRAVE.
GAVEL: Generating Games Via Evolution and Language Models
Jul 12, 2024



Automatically generating novel and interesting games is a complex task. Challenges include representing game rules in a computationally workable form, searching through the large space of potential games under most such representations, and accurately evaluating the originality and quality of previously unseen games. Prior work in automated game generation has largely focused on relatively restricted rule representations and relied on domain-specific heuristics. In this work, we explore the generation of novel games in the comparatively expansive Ludii game description language, which encodes the rules of over 1000 board games in a variety of styles and modes of play. We draw inspiration from recent advances in large language models and evolutionary computation in order to train a model that intelligently mutates and recombines games and mechanics expressed as code. We demonstrate both quantitatively and qualitatively that our approach is capable of generating new and interesting games, including in regions of the potential rules space not covered by existing games in the Ludii dataset. A sample of the generated games are available to play online through the Ludii portal.
Measuring Board Game Distance
Jan 10, 2023This paper presents a general approach for measuring distances between board games within the Ludii general game system. These distances are calculated using a previously published set of general board game concepts, each of which represents a common game idea or shared property. Our results compare and contrast two different measures of distance, highlighting the subjective nature of such metrics and discussing the different ways that they can be interpreted.
The Ludii Game Description Language is Universal
May 03, 2022



There are several different game description languages (GDLs), each intended to allow wide ranges of arbitrary games (i.e., general games) to be described in a single higher-level language than general-purpose programming languages. Games described in such formats can subsequently be presented as challenges for automated general game playing agents, which are expected to be capable of playing any arbitrary game described in such a language without prior knowledge about the games to be played. The language used by the Ludii general game system was previously shown to be capable of representing equivalent games for any arbitrary, finite, deterministic, fully observable extensive-form game. In this paper, we prove its universality by extending this to include finite non-deterministic and imperfect-information games.
Spatial State-Action Features for General Games
Jan 17, 2022In many board games and other abstract games, patterns have been used as features that can guide automated game-playing agents. Such patterns or features often represent particular configurations of pieces, empty positions, etc., which may be relevant for a game's strategies. Their use has been particularly prevalent in the game of Go, but also many other games used as benchmarks for AI research. Simple, linear policies of such features are unlikely to produce state-of-the-art playing strength like the deep neural networks that have been more commonly used in recent years do. However, they typically require significantly fewer resources to train, which is paramount for large-scale studies of hundreds to thousands of distinct games. In this paper, we formulate a design and efficient implementation of spatial state-action features for general games. These are patterns that can be trained to incentivise or disincentivise actions based on whether or not they match variables of the state in a local area around action variables. We provide extensive details on several design and implementation choices, with a primary focus on achieving a high degree of generality to support a wide variety of different games using different board geometries or other graphs. Secondly, we propose an efficient approach for evaluating active features for any given set of features. In this approach, we take inspiration from heuristics used in problems such as SAT to optimise the order in which parts of patterns are matched and prune unnecessary evaluations. An empirical evaluation on 33 distinct games in the Ludii general game system demonstrates the efficiency of this approach in comparison to a naive baseline, as well as a baseline based on prefix trees.
General Board Geometry
Nov 22, 2021
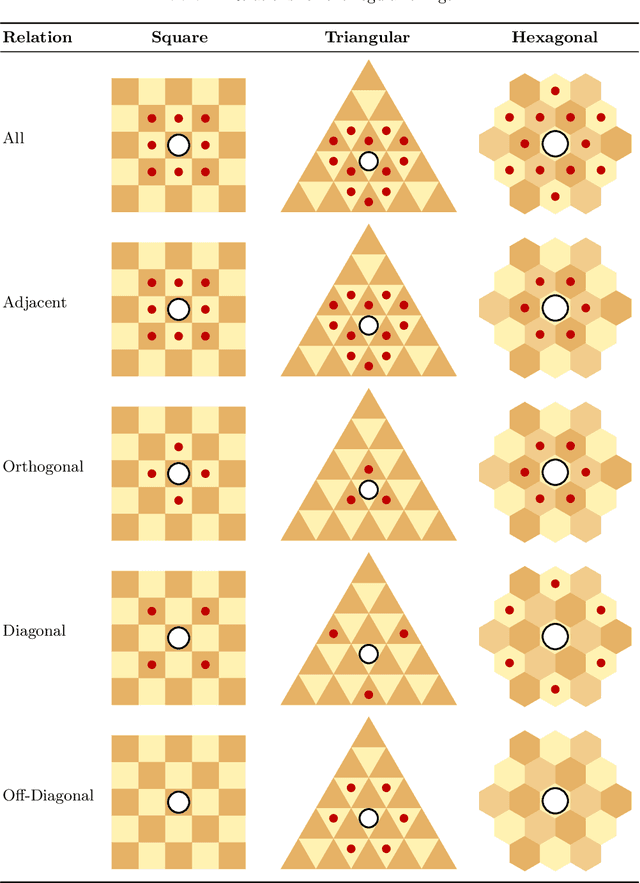
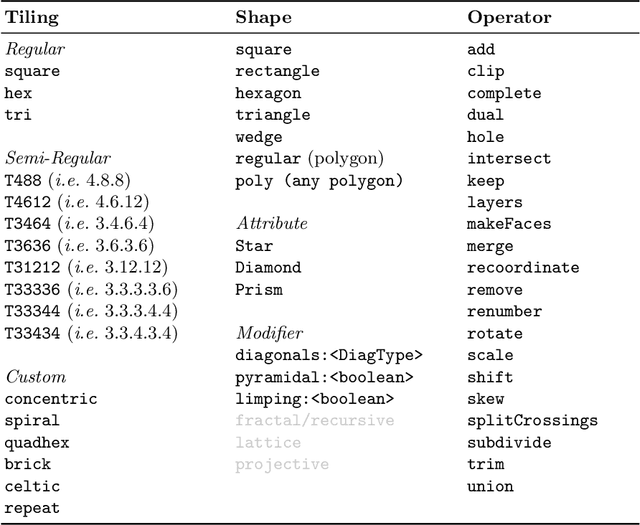
Game boards are described in the Ludii general game system by their underlying graphs, based on tiling, shape and graph operators, with the automatic detection of important properties such as topological relationships between graph elements, directions and radial step sequences. This approach allows most conceivable game boards to be described simply and succinctly.
Optimised Playout Implementations for the Ludii General Game System
Nov 04, 2021
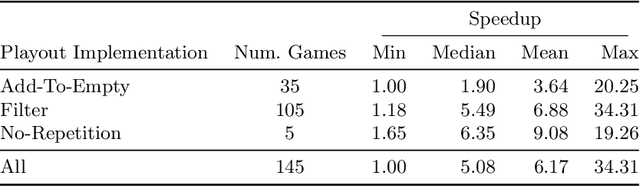
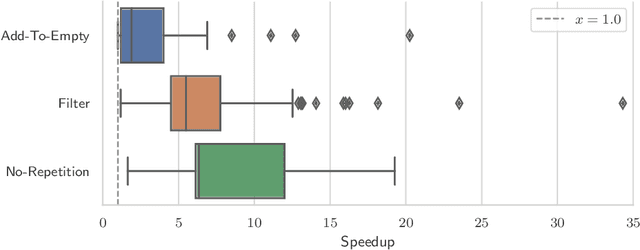
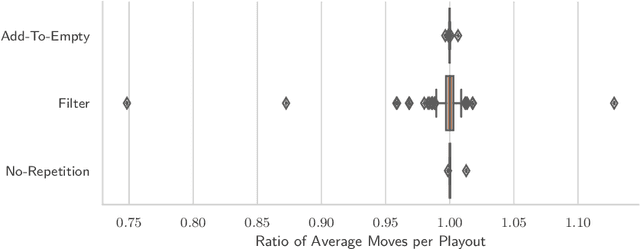
This paper describes three different optimised implementations of playouts, as commonly used by game-playing algorithms such as Monte-Carlo Tree Search. Each of the optimised implementations is applicable only to specific sets of games, based on their rules. The Ludii general game system can automatically infer, based on a game's description in its general game description language, whether any optimised implementations are applicable. An empirical evaluation demonstrates major speedups over a standard implementation, with a median result of running playouts 5.08 times as fast, over 145 different games in Ludii for which one of the optimised implementations is applicable.
General Board Game Concepts
Jul 02, 2021
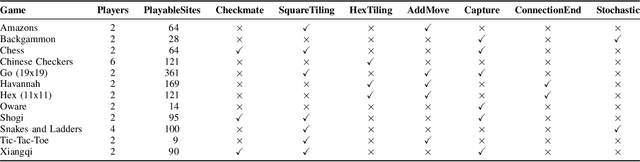
Many games often share common ideas or aspects between them, such as their rules, controls, or playing area. However, in the context of General Game Playing (GGP) for board games, this area remains under-explored. We propose to formalise the notion of "game concept", inspired by terms generally used by game players and designers. Through the Ludii General Game System, we describe concepts for several levels of abstraction, such as the game itself, the moves played, or the states reached. This new GGP feature associated with the ludeme representation of games opens many new lines of research. The creation of a hyper-agent selector, the transfer of AI learning between games, or explaining AI techniques using game terms, can all be facilitated by the use of game concepts. Other applications which can benefit from game concepts are also discussed, such as the generation of plausible reconstructed rules for incomplete ancient games, or the implementation of a board game recommender system.
Manipulating the Distributions of Experience used for Self-Play Learning in Expert Iteration
May 30, 2020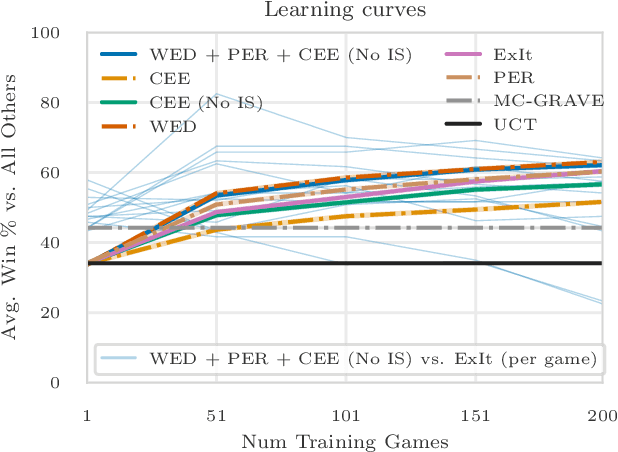
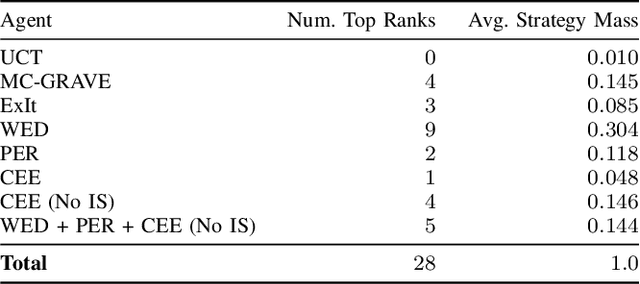
Expert Iteration (ExIt) is an effective framework for learning game-playing policies from self-play. ExIt involves training a policy to mimic the search behaviour of a tree search algorithm - such as Monte-Carlo tree search - and using the trained policy to guide it. The policy and the tree search can then iteratively improve each other, through experience gathered in self-play between instances of the guided tree search algorithm. This paper outlines three different approaches for manipulating the distribution of data collected from self-play, and the procedure that samples batches for learning updates from the collected data. Firstly, samples in batches are weighted based on the durations of the episodes in which they were originally experienced. Secondly, Prioritized Experience Replay is applied within the ExIt framework, to prioritise sampling experience from which we expect to obtain valuable training signals. Thirdly, a trained exploratory policy is used to diversify the trajectories experienced in self-play. This paper summarises the effects of these manipulations on training performance evaluated in fourteen different board games. We find major improvements in early training performance in some games, and minor improvements averaged over fourteen games.