 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Language-EXtended Indoor SLAM (LEXIS): A Versatile System for Real-time Visual Scene Understanding
Sep 26, 2023
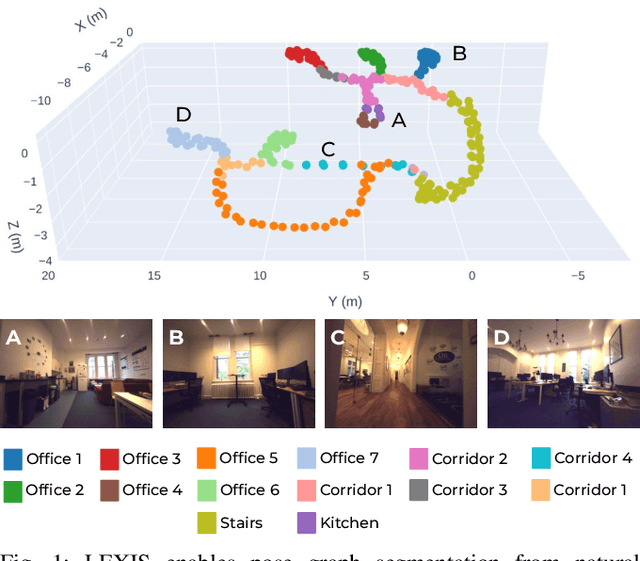
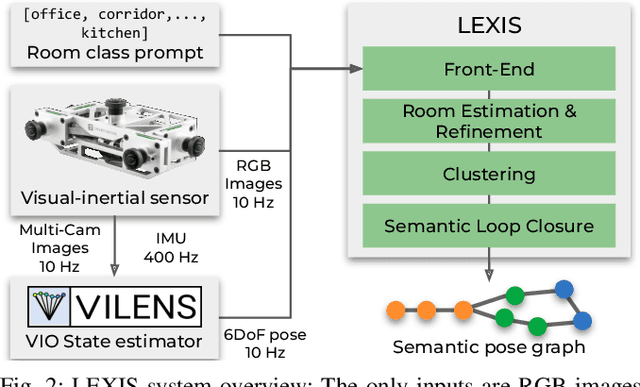
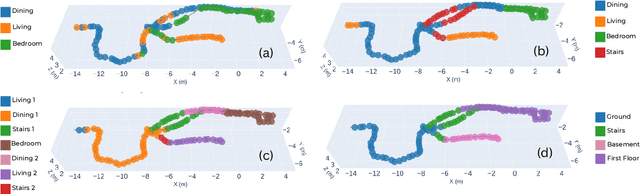
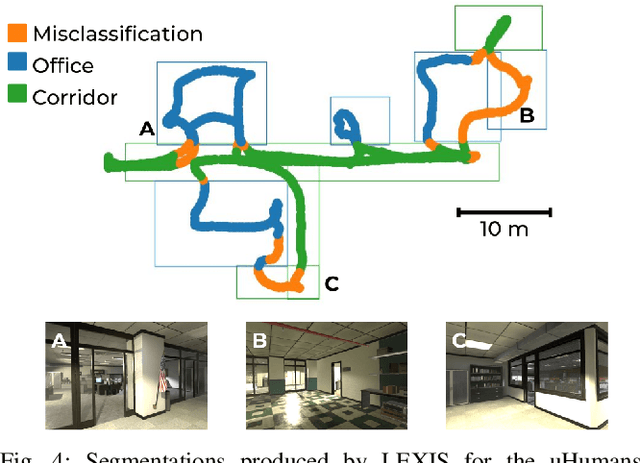
Versatile and adaptive semantic understanding would enable autonomous systems to comprehend and interact with their surroundings. Existing fixed-class models limit the adaptability of indoor mobile and assistive autonomous systems. In this work, we introduce LEXIS, a real-time indoor Simultaneous Localization and Mapping (SLAM) system that harnesses the open-vocabulary nature of Large Language Models (LLMs) to create a unified approach to scene understanding and place recognition. The approach first builds a topological SLAM graph of the environment (using visual-inertial odometry) and embeds Contrastive Language-Image Pretraining (CLIP) features in the graph nodes. We use this representation for flexible room classification and segmentation, serving as a basis for room-centric place recognition. This allows loop closure searches to be directed towards semantically relevant places. Our proposed system is evaluated using both public, simulated data and real-world data, covering office and home environments. It successfully categorizes rooms with varying layouts and dimensions and outperforms the state-of-the-art (SOTA). For place recognition and trajectory estimation tasks we achieve equivalent performance to the SOTA, all also utilizing the same pre-trained model. Lastly, we demonstrate the system's potential for planning.
FlexTrain: A Dynamic Training Framework for Heterogeneous Devices Environments
Oct 31, 2023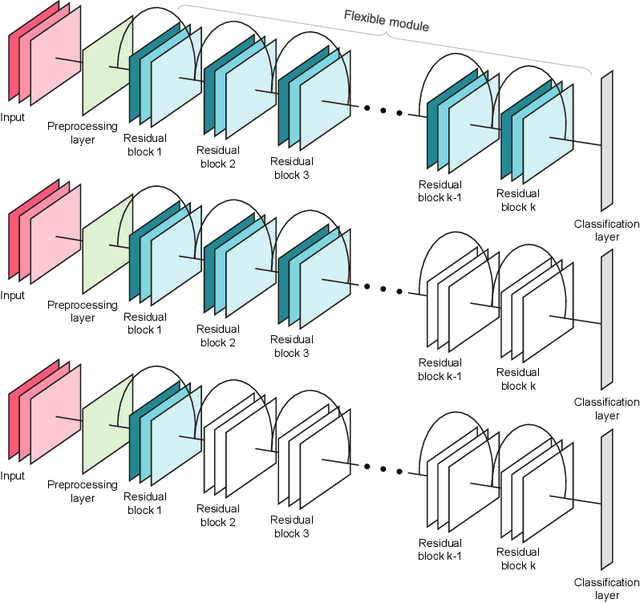
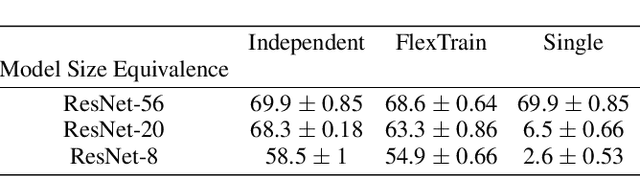
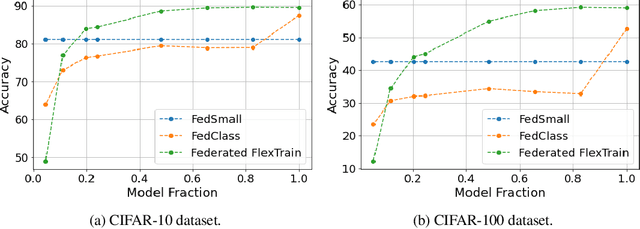

As deep learning models become increasingly large, they pose significant challenges in heterogeneous devices environments. The size of deep learning models makes it difficult to deploy them on low-power or resource-constrained devices, leading to long inference times and high energy consumption. To address these challenges, we propose FlexTrain, a framework that accommodates the diverse storage and computational resources available on different devices during the training phase. FlexTrain enables efficient deployment of deep learning models, while respecting device constraints, minimizing communication costs, and ensuring seamless integration with diverse devices. We demonstrate the effectiveness of FlexTrain on the CIFAR-100 dataset, where a single global model trained with FlexTrain can be easily deployed on heterogeneous devices, saving training time and energy consumption. We also extend FlexTrain to the federated learning setting, showing that our approach outperforms standard federated learning benchmarks on both CIFAR-10 and CIFAR-100 datasets.
Plagiarism and AI Assistance Misuse in Web Programming: Unfair Benefits and Characteristics
Oct 31, 2023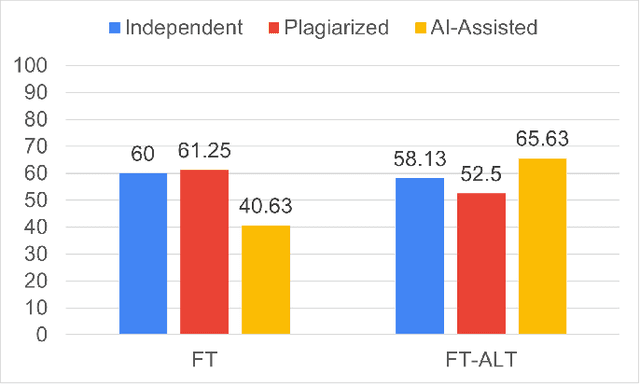
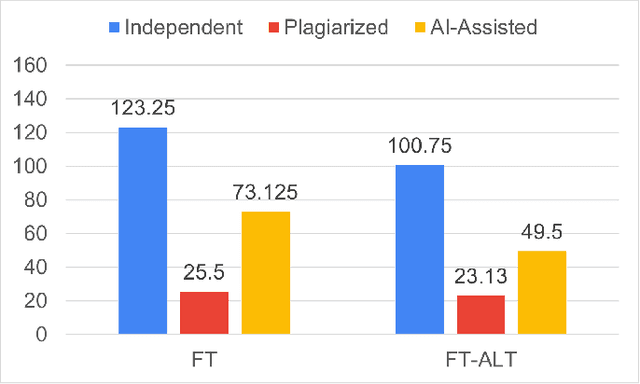
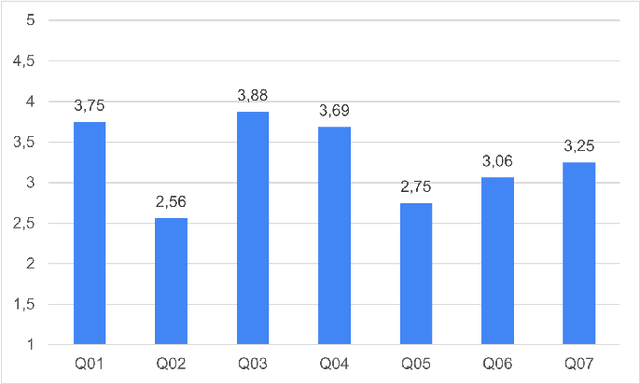
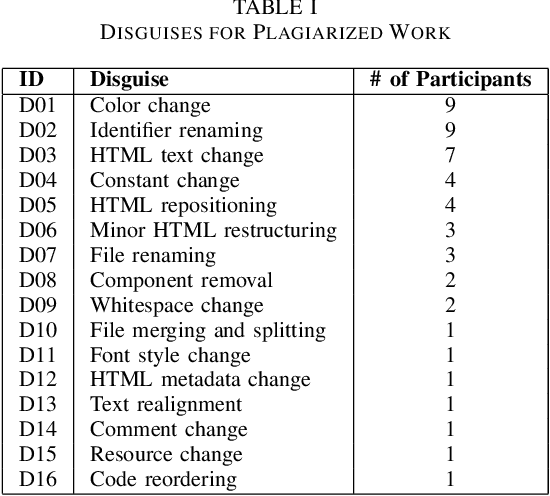
In programming education, plagiarism and misuse of artificial intelligence (AI) assistance are emerging issues. However, not many relevant studies are focused on web programming. We plan to develop automated tools to help instructors identify both misconducts. To fully understand the issues, we conducted a controlled experiment to observe the unfair benefits and the characteristics. We compared student performance in completing web programming tasks independently, with a submission to plagiarize, and with the help of AI assistance (ChatGPT). Our study shows that students who are involved in such misconducts get comparable test marks with less completion time. Plagiarized submissions are similar to the independent ones except in trivial aspects such as color and identifier names. AI-assisted submissions are more complex, making them less readable. Students believe AI assistance could be useful given proper acknowledgment of the use, although they are not convinced with readability and correctness of the solutions.
Hierarchical Time Series Forecasting with Bayesian Modeling
Aug 28, 2023
We encounter time series data in many domains such as finance, physics, business, and weather. One of the main tasks of time series analysis, one that helps to take informed decisions under uncertainty, is forecasting. Time series are often hierarchically structured, e.g., a company sales might be broken down into different regions, and each region into different stores. In some cases the number of series in the hierarchy is too big to fit in a single model to produce forecasts in relevant time, and a decentralized approach is beneficial. One way to do this is to train independent forecasting models for each series and for some summary statistics series implied by the hierarchy (e.g. the sum of all series) and to pass those models to a reconciliation algorithm to improve those forecasts by sharing information between the series. In this work we focus on the reconciliation step, and propose a method to do so from a Bayesian perspective - Bayesian forecast reconciliation. We also define the common case of linear Gaussian reconciliation, where the forecasts are Gaussian and the hierarchy has linear structure, and show that we can compute reconciliation in closed form. We evaluate these methods on synthetic and real data sets, and compare them to other work in this field.
From Text to Structure: Using Large Language Models to Support the Development of Legal Expert Systems
Nov 01, 2023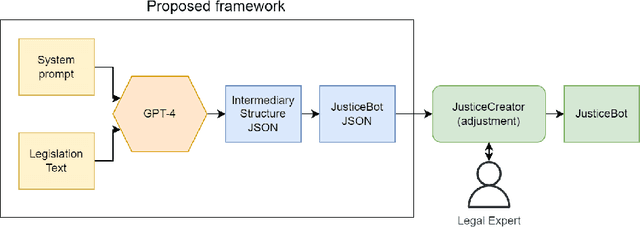


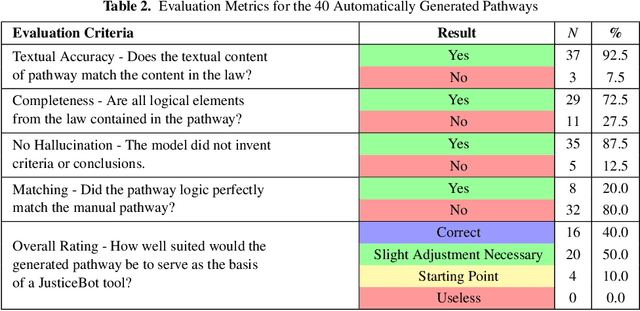
Encoding legislative text in a formal representation is an important prerequisite to different tasks in the field of AI & Law. For example, rule-based expert systems focused on legislation can support laypeople in understanding how legislation applies to them and provide them with helpful context and information. However, the process of analyzing legislation and other sources to encode it in the desired formal representation can be time-consuming and represents a bottleneck in the development of such systems. Here, we investigate to what degree large language models (LLMs), such as GPT-4, are able to automatically extract structured representations from legislation. We use LLMs to create pathways from legislation, according to the JusticeBot methodology for legal decision support systems, evaluate the pathways and compare them to manually created pathways. The results are promising, with 60% of generated pathways being rated as equivalent or better than manually created ones in a blind comparison. The approach suggests a promising path to leverage the capabilities of LLMs to ease the costly development of systems based on symbolic approaches that are transparent and explainable.
An Embedded Diachronic Sense Change Model with a Case Study from Ancient Greek
Nov 01, 2023
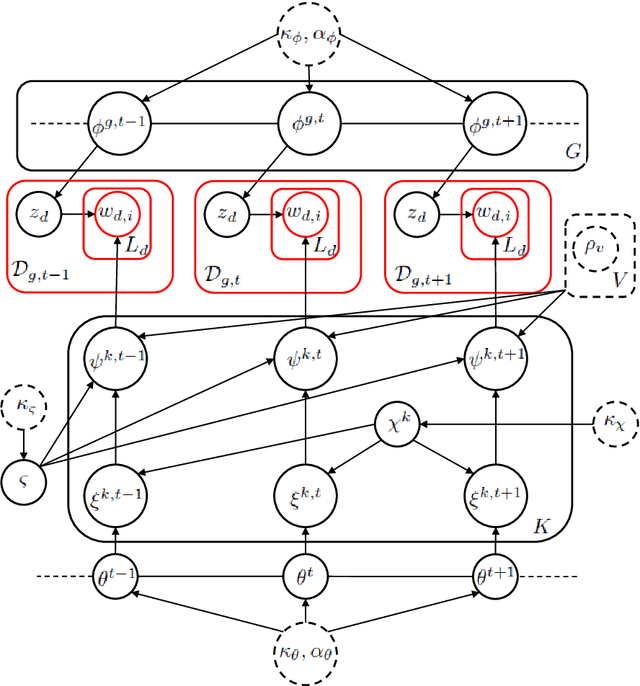
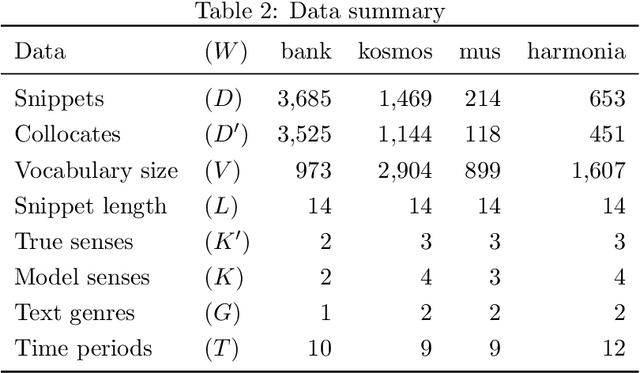
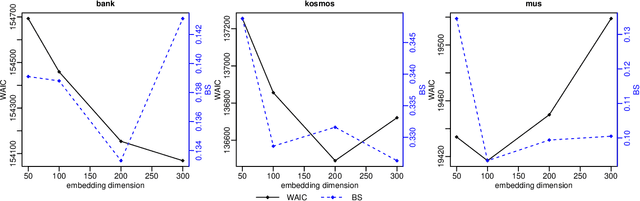
Word meanings change over time, and word senses evolve, emerge or die out in the process. For ancient languages, where the corpora are often small, sparse and noisy, modelling such changes accurately proves challenging, and quantifying uncertainty in sense-change estimates consequently becomes important. GASC and DiSC are existing generative models that have been used to analyse sense change for target words from an ancient Greek text corpus, using unsupervised learning without the help of any pre-training. These models represent the senses of a given target word such as "kosmos" (meaning decoration, order or world) as distributions over context words, and sense prevalence as a distribution over senses. The models are fitted using MCMC methods to measure temporal changes in these representations. In this paper, we introduce EDiSC, an embedded version of DiSC, which combines word embeddings with DiSC to provide superior model performance. We show empirically that EDiSC offers improved predictive accuracy, ground-truth recovery and uncertainty quantification, as well as better sampling efficiency and scalability properties with MCMC methods. We also discuss the challenges of fitting these models.
Magmaw: Modality-Agnostic Adversarial Attacks on Machine Learning-Based Wireless Communication Systems
Nov 01, 2023Machine Learning (ML) has been instrumental in enabling joint transceiver optimization by merging all physical layer blocks of the end-to-end wireless communication systems. Although there have been a number of adversarial attacks on ML-based wireless systems, the existing methods do not provide a comprehensive view including multi-modality of the source data, common physical layer components, and wireless domain constraints. This paper proposes Magmaw, the first black-box attack methodology capable of generating universal adversarial perturbations for any multimodal signal transmitted over a wireless channel. We further introduce new objectives for adversarial attacks on ML-based downstream applications. The resilience of the attack to the existing widely used defense methods of adversarial training and perturbation signal subtraction is experimentally verified. For proof-of-concept evaluation, we build a real-time wireless attack platform using a software-defined radio system. Experimental results demonstrate that Magmaw causes significant performance degradation even in the presence of the defense mechanisms. Surprisingly, Magmaw is also effective against encrypted communication channels and conventional communications.
Real-time Motion Generation and Data Augmentation for Grasping Moving Objects with Dynamic Speed and Position Changes
Sep 22, 2023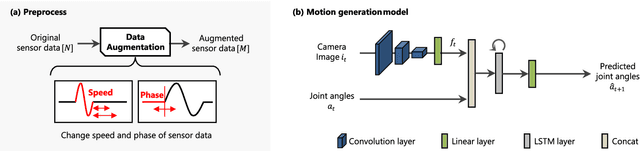
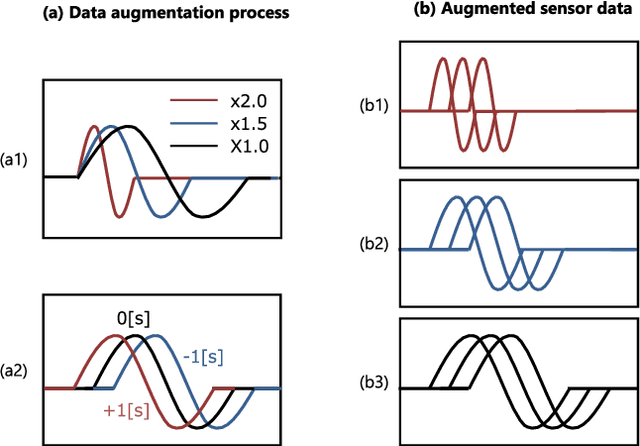
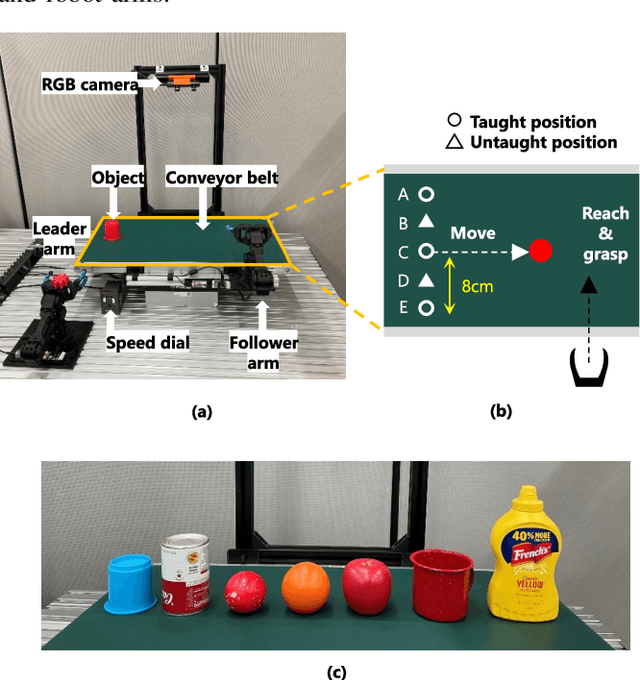

While deep learning enables real robots to perform complex tasks had been difficult to implement in the past, the challenge is the enormous amount of trial-and-error and motion teaching in a real environment. The manipulation of moving objects, due to their dynamic properties, requires learning a wide range of factors such as the object's position, movement speed, and grasping timing. We propose a data augmentation method for enabling a robot to grasp moving objects with different speeds and grasping timings at low cost. Specifically, the robot is taught to grasp an object moving at low speed using teleoperation, and multiple data with different speeds and grasping timings are generated by down-sampling and padding the robot sensor data in the time-series direction. By learning multiple sensor data in a time series, the robot can generate motions while adjusting the grasping timing for unlearned movement speeds and sudden speed changes. We have shown using a real robot that this data augmentation method facilitates learning the relationship between object position and velocity and enables the robot to perform robust grasping motions for unlearned positions and objects with dynamically changing positions and velocities.
A Real-time Faint Space Debris Detector With Learning-based LCM
Sep 15, 2023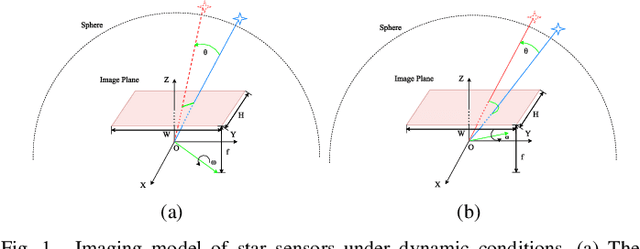

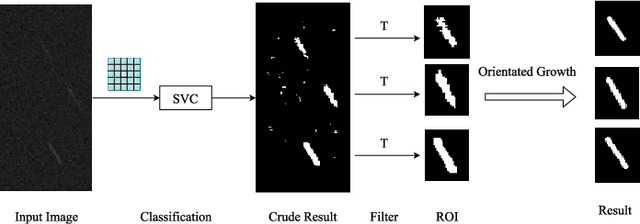
With the development of aerospace technology, the increasing population of space debris has posed a great threat to the safety of spacecraft. However, the low intensity of reflected light and high angular velocity of space debris impede the extraction. Besides, due to the limitations of the ground observation methods, small space debris can hardly be detected, making it necessary to enhance the spacecraft's capacity for space situational awareness (SSA). Considering that traditional methods have some defects in low-SNR target detection, such as low effectiveness and large time consumption, this paper proposes a method for low-SNR streak extraction based on local contrast and maximum likelihood estimation (MLE), which can detect space objects with SNR 2.0 efficiently. In the proposed algorithm, local contrast will be applied for crude classifications, which will return connected components as preliminary results, and then MLE will be performed to reconstruct the connected components of targets via orientated growth, further improving the precision. The algorithm has been verified with both simulated streaks and real star tracker images, and the average centroid error of the proposed algorithm is close to the state-of-the-art method like ODCC. At the same time, the algorithm in this paper has significant advantages in efficiency compared with ODCC. In conclusion, the algorithm in this paper is of high speed and precision, which guarantees its promising applications in the extraction of high dynamic targets.
Design Of Rubble Analyzer Probe Using ML For Earthquake
Oct 24, 2023

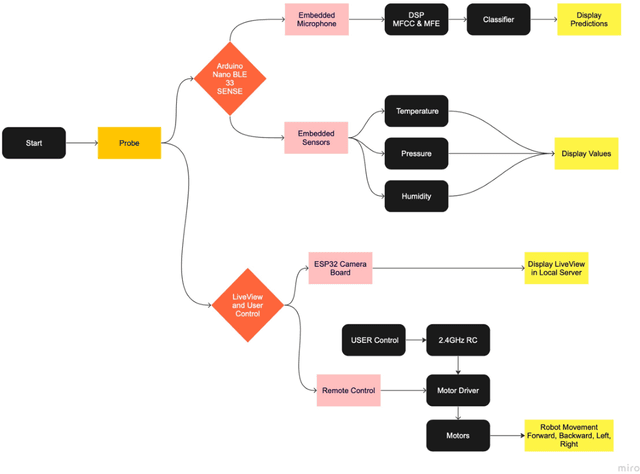
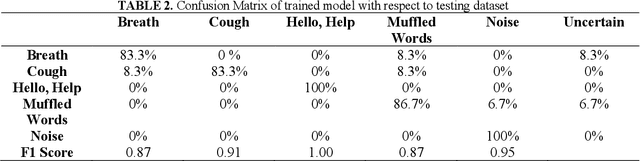
The earthquake rubble analyzer uses machine learning to detect human presence via ambient sounds, achieving 97.45% accuracy. It also provides real-time environmental data, aiding in assessing survival prospects for trapped individuals, crucial for post-earthquake rescue efforts