 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Novel View Synthesis with View-Dependent Effects from a Single Image
Dec 13, 2023
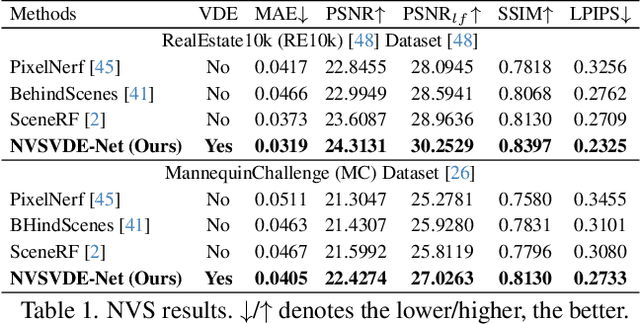
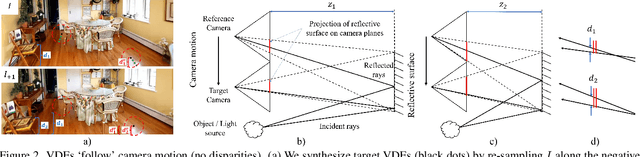
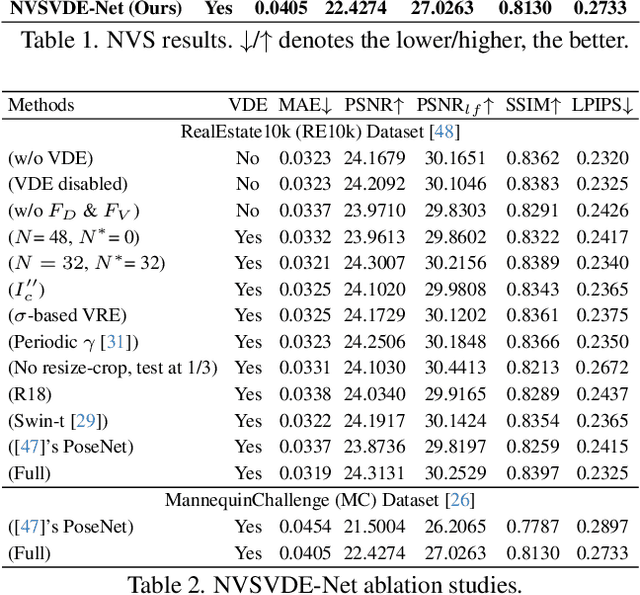
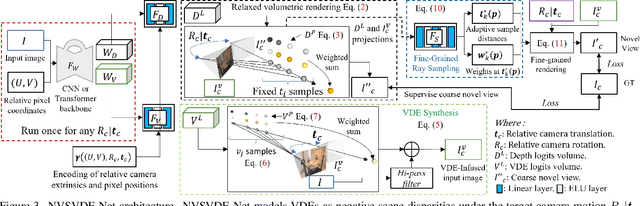
In this paper, we firstly consider view-dependent effects into single image-based novel view synthesis (NVS) problems. For this, we propose to exploit the camera motion priors in NVS to model view-dependent appearance or effects (VDE) as the negative disparity in the scene. By recognizing specularities "follow" the camera motion, we infuse VDEs into the input images by aggregating input pixel colors along the negative depth region of the epipolar lines. Also, we propose a `relaxed volumetric rendering' approximation that allows computing the densities in a single pass, improving efficiency for NVS from single images. Our method can learn single-image NVS from image sequences only, which is a completely self-supervised learning method, for the first time requiring neither depth nor camera pose annotations. We present extensive experiment results and show that our proposed method can learn NVS with VDEs, outperforming the SOTA single-view NVS methods on the RealEstate10k and MannequinChallenge datasets.
Secure Deep Reinforcement Learning for Dynamic Resource Allocation in Wireless MEC Networks
Dec 13, 2023This paper proposes a blockchain-secured deep reinforcement learning (BC-DRL) optimization framework for {data management and} resource allocation in decentralized {wireless mobile edge computing (MEC)} networks. In our framework, {we design a low-latency reputation-based proof-of-stake (RPoS) consensus protocol to select highly reliable blockchain-enabled BSs to securely store MEC user requests and prevent data tampering attacks.} {We formulate the MEC resource allocation optimization as a constrained Markov decision process that balances minimum processing latency and denial-of-service (DoS) probability}. {We use the MEC aggregated features as the DRL input to significantly reduce the high-dimensionality input of the remaining service processing time for individual MEC requests. Our designed constrained DRL effectively attains the optimal resource allocations that are adapted to the dynamic DoS requirements. We provide extensive simulation results and analysis to} validate that our BC-DRL framework achieves higher security, reliability, and resource utilization efficiency than benchmark blockchain consensus protocols and {MEC} resource allocation algorithms.
Markov Decision Processes with Noisy State Observation
Dec 13, 2023This paper addresses the challenge of a particular class of noisy state observations in Markov Decision Processes (MDPs), a common issue in various real-world applications. We focus on modeling this uncertainty through a confusion matrix that captures the probabilities of misidentifying the true state. Our primary goal is to estimate the inherent measurement noise, and to this end, we propose two novel algorithmic approaches. The first, the method of second-order repetitive actions, is designed for efficient noise estimation within a finite time window, providing identifiable conditions for system analysis. The second approach comprises a family of Bayesian algorithms, which we thoroughly analyze and compare in terms of performance and limitations. We substantiate our theoretical findings with simulations, demonstrating the effectiveness of our methods in different scenarios, particularly highlighting their behavior in environments with varying stationary distributions. Our work advances the understanding of reinforcement learning in noisy environments, offering robust techniques for more accurate state estimation in MDPs.
Distributional Latent Variable Models with an Application in Active Cognitive Testing
Dec 14, 2023
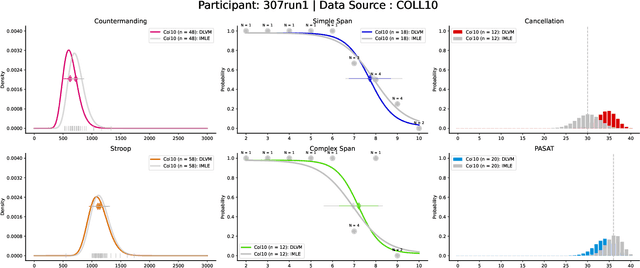
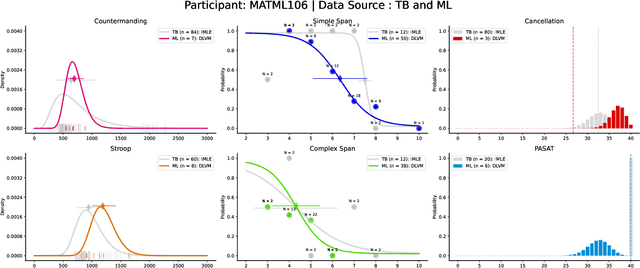
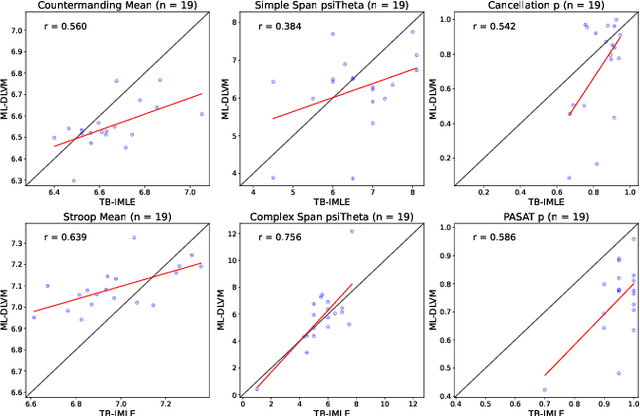
Cognitive modeling commonly relies on asking participants to complete a battery of varied tests in order to estimate attention, working memory, and other latent variables. In many cases, these tests result in highly variable observation models. A near-ubiquitous approach is to repeat many observations for each test, resulting in a distribution over the outcomes from each test given to each subject. In this paper, we explore the usage of latent variable modeling to enable learning across many correlated variables simultaneously. We extend latent variable models (LVMs) to the setting where observed data for each subject are a series of observations from many different distributions, rather than simple vectors to be reconstructed. By embedding test battery results for individuals in a latent space that is trained jointly across a population, we are able to leverage correlations both between tests for a single participant and between multiple participants. We then propose an active learning framework that leverages this model to conduct more efficient cognitive test batteries. We validate our approach by demonstrating with real-time data acquisition that it performs comparably to conventional methods in making item-level predictions with fewer test items.
Learning Long Sequences in Spiking Neural Networks
Dec 14, 2023Spiking neural networks (SNNs) take inspiration from the brain to enable energy-efficient computations. Since the advent of Transformers, SNNs have struggled to compete with artificial networks on modern sequential tasks, as they inherit limitations from recurrent neural networks (RNNs), with the added challenge of training with non-differentiable binary spiking activations. However, a recent renewed interest in efficient alternatives to Transformers has given rise to state-of-the-art recurrent architectures named state space models (SSMs). This work systematically investigates, for the first time, the intersection of state-of-the-art SSMs with SNNs for long-range sequence modelling. Results suggest that SSM-based SNNs can outperform the Transformer on all tasks of a well-established long-range sequence modelling benchmark. It is also shown that SSM-based SNNs can outperform current state-of-the-art SNNs with fewer parameters on sequential image classification. Finally, a novel feature mixing layer is introduced, improving SNN accuracy while challenging assumptions about the role of binary activations in SNNs. This work paves the way for deploying powerful SSM-based architectures, such as large language models, to neuromorphic hardware for energy-efficient long-range sequence modelling.
Efficient speech detection in environmental audio using acoustic recognition and knowledge distillation
Dec 14, 2023The ongoing biodiversity crisis, driven by factors such as land-use change and global warming, emphasizes the need for effective ecological monitoring methods. Acoustic monitoring of biodiversity has emerged as an important monitoring tool. Detecting human voices in soundscape monitoring projects is useful both for analysing human disturbance and for privacy filtering. Despite significant strides in deep learning in recent years, the deployment of large neural networks on compact devices poses challenges due to memory and latency constraints. Our approach focuses on leveraging knowledge distillation techniques to design efficient, lightweight student models for speech detection in bioacoustics. In particular, we employed the MobileNetV3-Small-Pi model to create compact yet effective student architectures to compare against the larger EcoVAD teacher model, a well-regarded voice detection architecture in eco-acoustic monitoring. The comparative analysis included examining various configurations of the MobileNetV3-Small-Pi derived student models to identify optimal performance. Additionally, a thorough evaluation of different distillation techniques was conducted to ascertain the most effective method for model selection. Our findings revealed that the distilled models exhibited comparable performance to the EcoVAD teacher model, indicating a promising approach to overcoming computational barriers for real-time ecological monitoring.
On The Expressivity of Recurrent Neural Cascades
Dec 14, 2023Recurrent Neural Cascades (RNCs) are the recurrent neural networks with no cyclic dependencies among recurrent neurons. This class of recurrent networks has received a lot of attention in practice. Besides training methods for a fixed architecture such as backpropagation, the cascade architecture naturally allows for constructive learning methods, where recurrent nodes are added incrementally one at a time, often yielding smaller networks. Furthermore, acyclicity amounts to a structural prior that even for the same number of neurons yields a more favourable sample complexity compared to a fully-connected architecture. A central question is whether the advantages of the cascade architecture come at the cost of a reduced expressivity. We provide new insights into this question. We show that the regular languages captured by RNCs with sign and tanh activation with positive recurrent weights are the star-free regular languages. In order to establish our results we developed a novel framework where capabilities of RNCs are accessed by analysing which semigroups and groups a single neuron is able to implement. A notable implication of our framework is that RNCs can achieve the expressivity of all regular languages by introducing neurons that can implement groups.
Mixed Reality Communication for Medical Procedures: Teaching the Placement of a Central Venous Catheter
Dec 14, 2023Medical procedures are an essential part of healthcare delivery, and the acquisition of procedural skills is a critical component of medical education. Unfortunately, procedural skill is not evenly distributed among medical providers. Skills may vary within departments or institutions, and across geographic regions, depending on the provider's training and ongoing experience. We present a mixed reality real-time communication system to increase access to procedural skill training and to improve remote emergency assistance. Our system allows a remote expert to guide a local operator through a medical procedure. RGBD cameras capture a volumetric view of the local scene including the patient, the operator, and the medical equipment. The volumetric capture is augmented onto the remote expert's view to allow the expert to spatially guide the local operator using visual and verbal instructions. We evaluated our mixed reality communication system in a study in which experts teach the ultrasound-guided placement of a central venous catheter (CVC) to students in a simulation setting. The study compares state-of-the-art video communication against our system. The results indicate that our system enhances and offers new possibilities for visual communication compared to video teleconference-based training.
ChatSOS: LLM-based knowledge Q&A system for safety engineering
Dec 14, 2023Recent advancements in large language models (LLMs) have notably propelled natural language processing (NLP) capabilities, demonstrating significant potential in safety engineering applications. Despite these advancements, LLMs face constraints in processing specialized tasks, attributed to factors such as corpus size, input processing limitations, and privacy concerns. Obtaining useful information from reliable sources in a limited time is crucial for LLM. Addressing this, our study introduces an LLM-based Q&A system for safety engineering, enhancing the comprehension and response accuracy of the model. We employed prompt engineering to incorporate external knowledge databases, thus enriching the LLM with up-to-date and reliable information. The system analyzes historical incident reports through statistical methods, utilizes vector embedding to construct a vector database, and offers an efficient similarity-based search functionality. Our findings indicate that the integration of external knowledge significantly augments the capabilities of LLM for in-depth problem analysis and autonomous task assignment. It effectively summarizes accident reports and provides pertinent recommendations. This integration approach not only expands LLM applications in safety engineering but also sets a precedent for future developments towards automation and intelligent systems.
LFG: A Generative Network for Real-Time Recommendation
Oct 31, 2023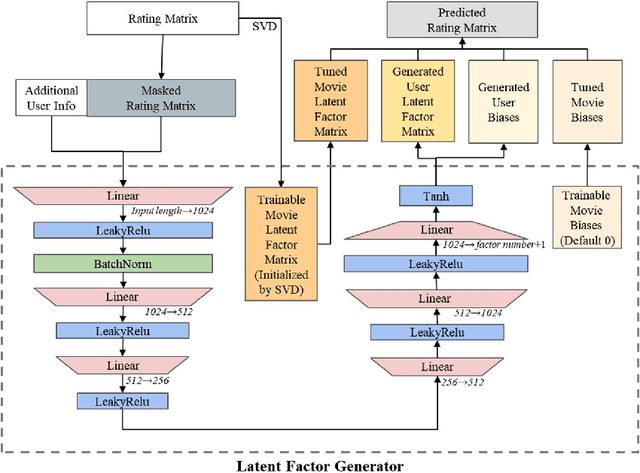
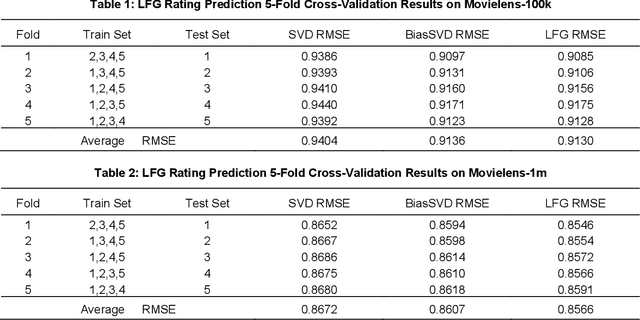
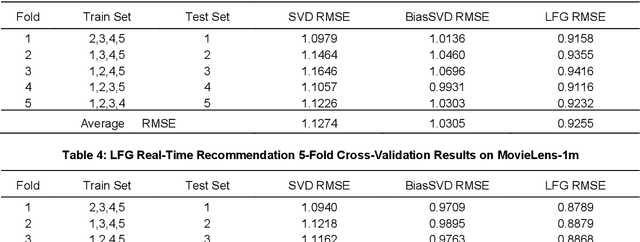

Recommender systems are essential information technologies today, and recommendation algorithms combined with deep learning have become a research hotspot in this field. The recommendation model known as LFM (Latent Factor Model), which captures latent features through matrix factorization and gradient descent to fit user preferences, has given rise to various recommendation algorithms that bring new improvements in recommendation accuracy. However, collaborative filtering recommendation models based on LFM lack flexibility and has shortcomings for real-time recommendations, as they need to redo the matrix factorization and retrain using gradient descent when new users arrive. In response to this, this paper innovatively proposes a Latent Factor Generator (LFG) network, and set the movie recommendation as research theme. The LFG dynamically generates user latent factors through deep neural networks without the need for re-factorization or retrain. Experimental results indicate that the LFG recommendation model outperforms traditional matrix factorization algorithms in recommendation accuracy, providing an effective solution to the challenges of real-time recommendations with LFM.