 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Fed-Sim: Federated Simulation for Medical Imaging
Sep 01, 2020
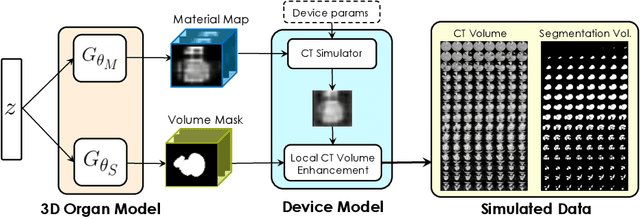
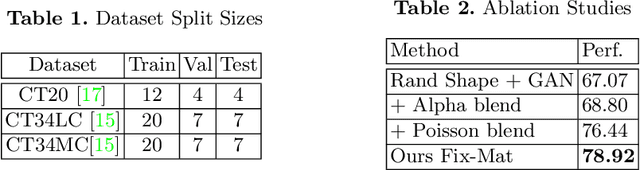
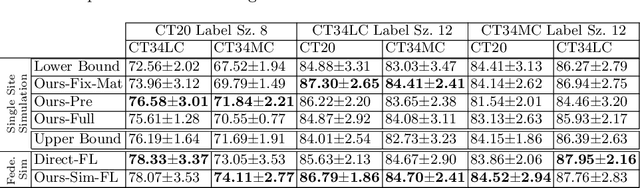

Labelling data is expensive and time consuming especially for domains such as medical imaging that contain volumetric imaging data and require expert knowledge. Exploiting a larger pool of labeled data available across multiple centers, such as in federated learning, has also seen limited success since current deep learning approaches do not generalize well to images acquired with scanners from different manufacturers. We aim to address these problems in a common, learning-based image simulation framework which we refer to as Federated Simulation. We introduce a physics-driven generative approach that consists of two learnable neural modules: 1) a module that synthesizes 3D cardiac shapes along with their materials, and 2) a CT simulator that renders these into realistic 3D CT Volumes, with annotations. Since the model of geometry and material is disentangled from the imaging sensor, it can effectively be trained across multiple medical centers. We show that our data synthesis framework improves the downstream segmentation performance on several datasets. Project Page: https://nv-tlabs.github.io/fed-sim/ .
Efficient Machine Learning Approach for Optimizing the Timing Resolution of a High Purity Germanium Detector
Mar 31, 2020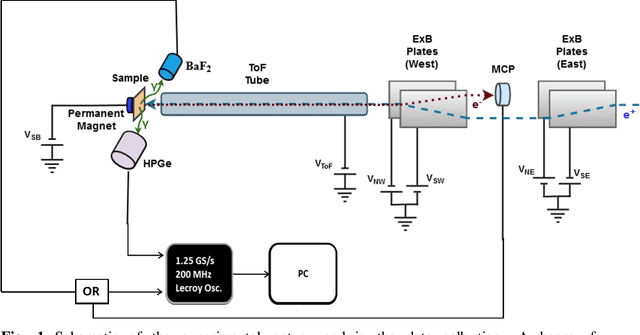
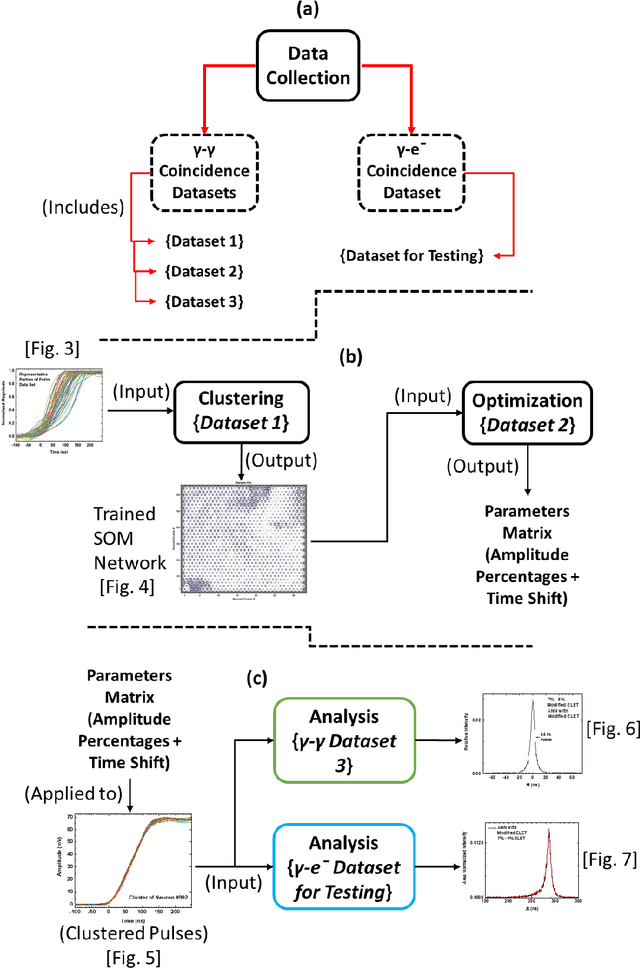
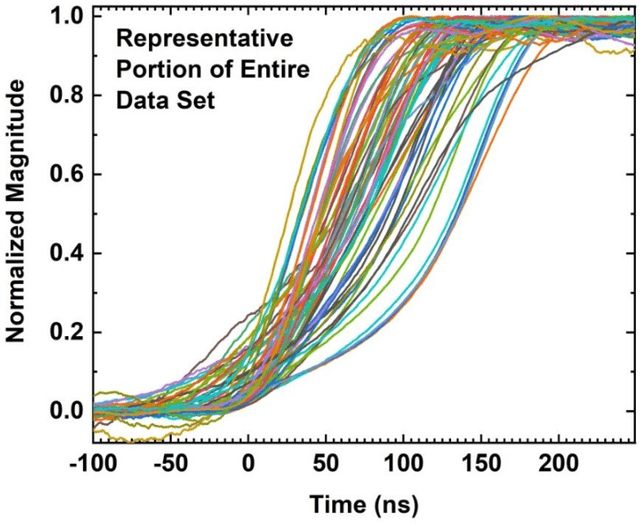
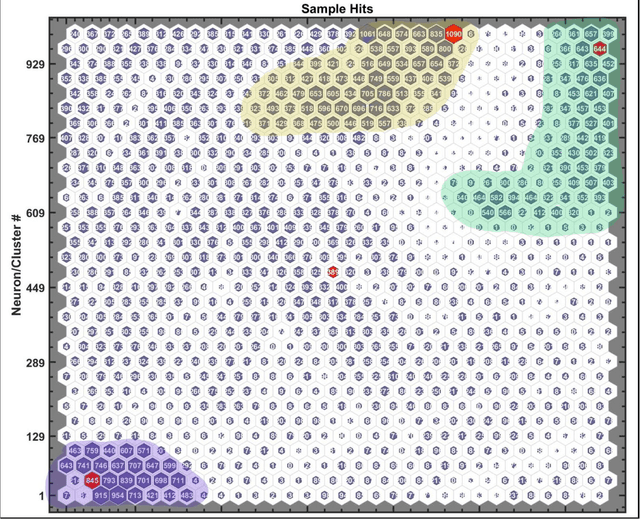
We describe here an efficient machine-learning based approach for the optimization of parameters used for extracting the arrival time of waveforms, in particular those generated by the detection of 511 keV annihilation gamma-rays by a 60 cm3 coaxial high purity germanium detector (HPGe). The method utilizes a type of artificial neural network (ANN) called a self-organizing map (SOM) to cluster the HPGe waveforms based on the shape of their rising edges. The optimal timing parameters for HPGe waveforms belonging to a particular cluster are found by minimizing the time difference between the HPGe signal and a signal produced by a BaF2 scintillation detector. Applying these variable timing parameters to the HPGe signals achieved a gamma-coincidence timing resolution of ~ 4.3 ns at the 511 keV photo peak (defined as 511 +- 50 keV) and a timing resolution of ~ 6.5 ns for the entire gamma spectrum--without rejecting any valid pulses. This timing resolution approaches the best obtained by analog nuclear electronics, without the corresponding complexities of analog optimization procedures. We further demonstrate the universality and efficacy of the machine learning approach by applying the method to the generation of secondary electron time-of-flight spectra following the implantation of energetic positrons on a sample.
Legal Document Classification: An Application to Law Area Prediction of Petitions to Public Prosecution Service
Oct 13, 2020
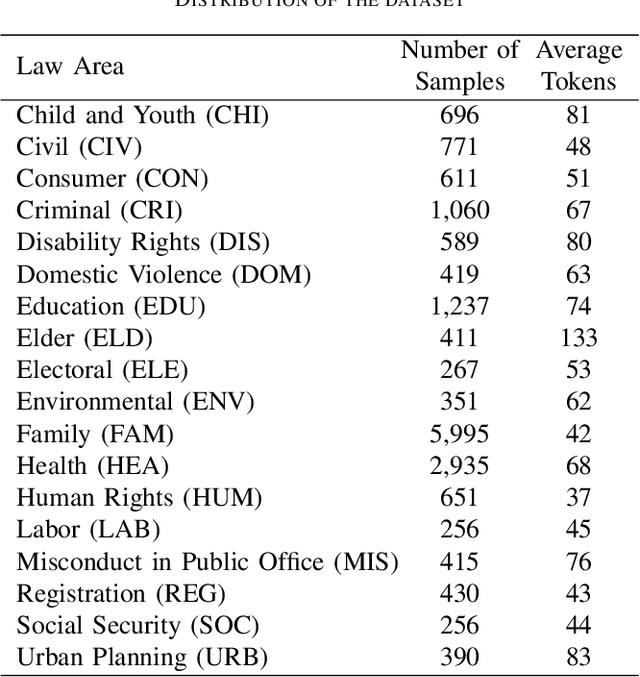
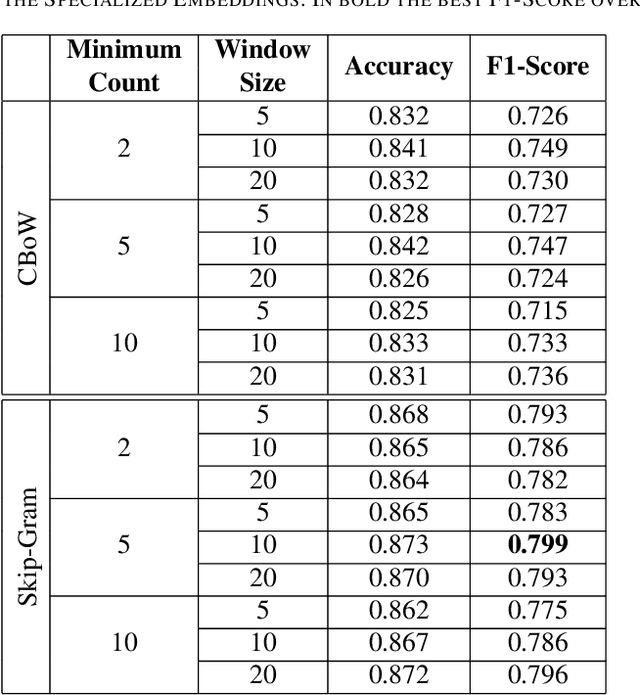
In recent years, there has been an increased interest in the application of Natural Language Processing (NLP) to legal documents. The use of convolutional and recurrent neural networks along with word embedding techniques have presented promising results when applied to textual classification problems, such as sentiment analysis and topic segmentation of documents. This paper proposes the use of NLP techniques for textual classification, with the purpose of categorizing the descriptions of the services provided by the Public Prosecutor's Office of the State of Paran\'a to the population in one of the areas of law covered by the institution. Our main goal is to automate the process of assigning petitions to their respective areas of law, with a consequent reduction in costs and time associated with such process while allowing the allocation of human resources to more complex tasks. In this paper, we compare different approaches to word representations in the aforementioned task: including document-term matrices and a few different word embeddings. With regards to the classification models, we evaluated three different families: linear models, boosted trees and neural networks. The best results were obtained with a combination of Word2Vec trained on a domain-specific corpus and a Recurrent Neural Network (RNN) architecture (more specifically, LSTM), leading to an accuracy of 90\% and F1-Score of 85\% in the classification of eighteen categories (law areas).
Optimizing fire allocation in a NCW-type model
Aug 12, 2020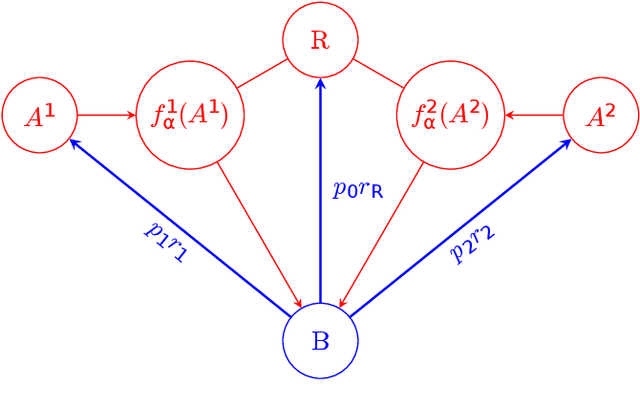
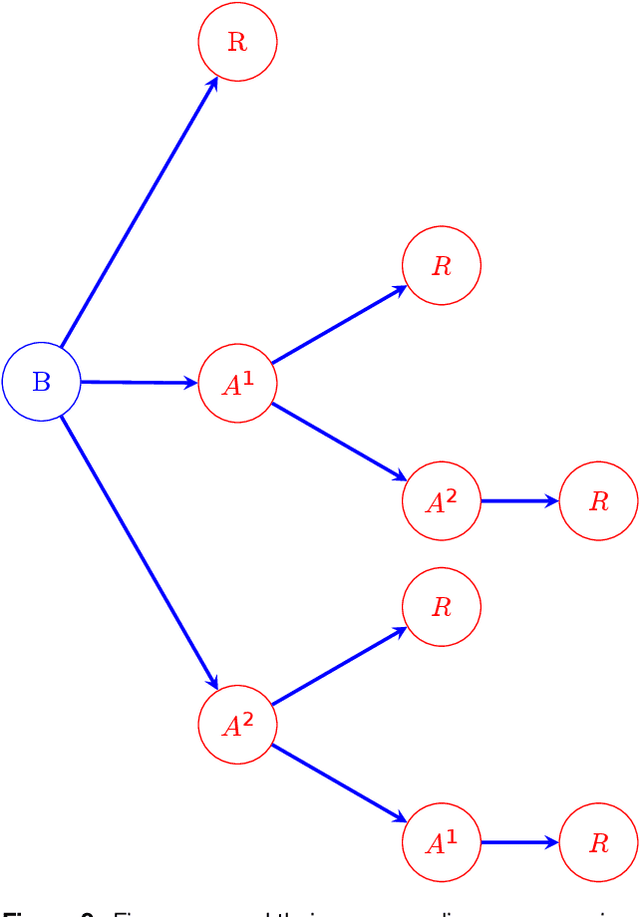
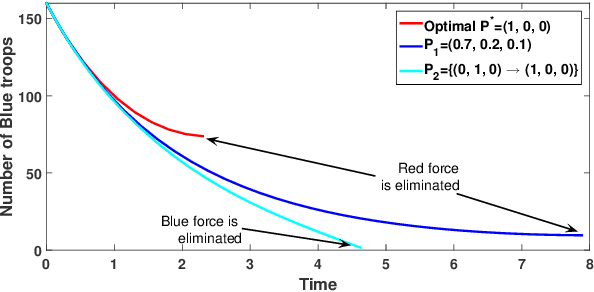
In this paper, we introduce a non-linear Lanchester model of NCW-type and investigate an optimization problem for this model, where only the Red force is supplied by several supply agents. Optimal fire allocation of the Blue force is sought in the form of a piece-wise constant function of time. A threatening rate is computed for the Red force and each of its supply agents at the beginning of each stage of the combat. These rates can be used to derive the optimal decision for the Blue force to focus its firepower to the Red force itself or one of its supply agents. This optimal fire allocation is derived and proved by considering an optimization problem of number of Blue force troops. Numerical experiments are included to demonstrate the theoretical results.
Learning to Learn from Mistakes: Robust Optimization for Adversarial Noise
Aug 12, 2020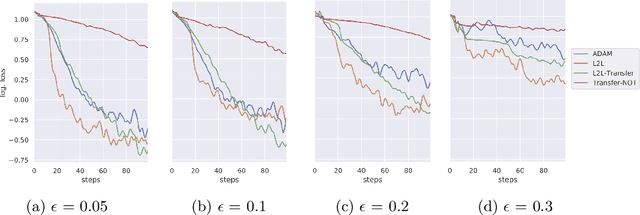
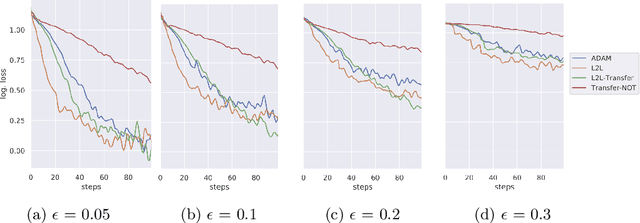
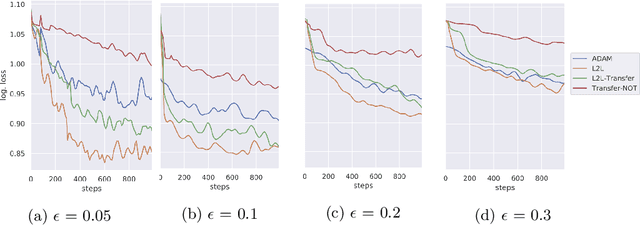
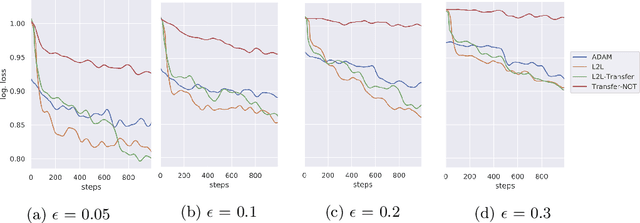
Sensitivity to adversarial noise hinders deployment of machine learning algorithms in security-critical applications. Although many adversarial defenses have been proposed, robustness to adversarial noise remains an open problem. The most compelling defense, adversarial training, requires a substantial increase in processing time and it has been shown to overfit on the training data. In this paper, we aim to overcome these limitations by training robust models in low data regimes and transfer adversarial knowledge between different models. We train a meta-optimizer which learns to robustly optimize a model using adversarial examples and is able to transfer the knowledge learned to new models, without the need to generate new adversarial examples. Experimental results show the meta-optimizer is consistent across different architectures and data sets, suggesting it is possible to automatically patch adversarial vulnerabilities.
Development and Validation of a Novel Prognostic Model for Predicting AMD Progression Using Longitudinal Fundus Images
Jul 10, 2020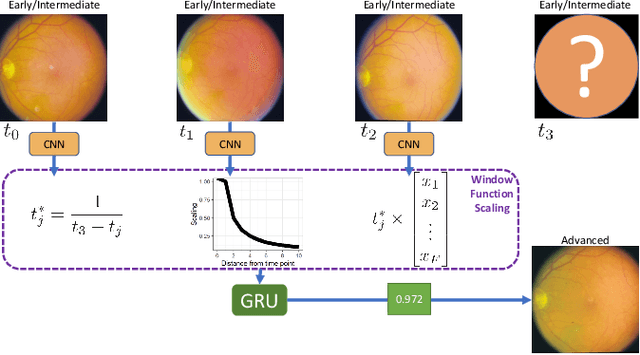
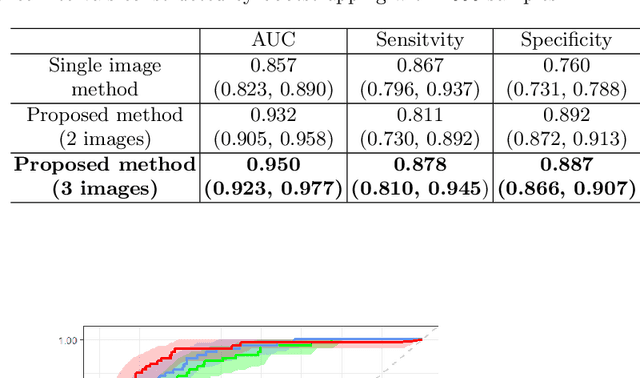
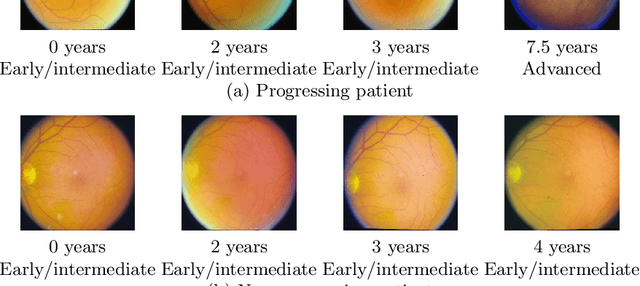
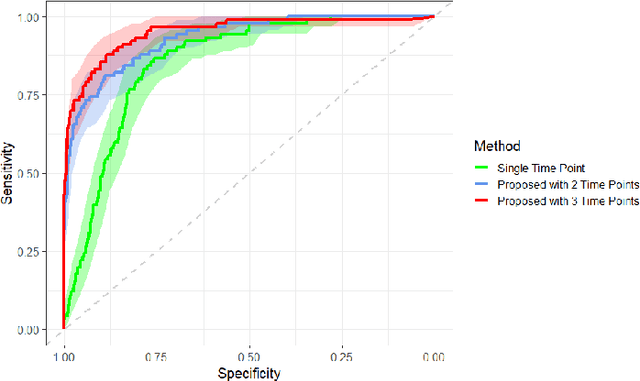
Prognostic models aim to predict the future course of a disease or condition and are a vital component of personalized medicine. Statistical models make use of longitudinal data to capture the temporal aspect of disease progression; however, these models require prior feature extraction. Deep learning avoids explicit feature extraction, meaning we can develop models for images where features are either unknown or impossible to quantify accurately. Previous prognostic models using deep learning with imaging data require annotation during training or only utilize a single time point. We propose a novel deep learning method to predict the progression of diseases using longitudinal imaging data with uneven time intervals, which requires no prior feature extraction. Given previous images from a patient, our method aims to predict whether the patient will progress onto the next stage of the disease. The proposed method uses InceptionV3 to produce feature vectors for each image. In order to account for uneven intervals, a novel interval scaling is proposed. Finally, a Recurrent Neural Network is used to prognosticate the disease. We demonstrate our method on a longitudinal dataset of color fundus images from 4903 eyes with age-related macular degeneration (AMD), taken from the Age-Related Eye Disease Study, to predict progression to late AMD. Our method attains a testing sensitivity of 0.878, a specificity of 0.887, and an area under the receiver operating characteristic of 0.950. We compare our method to previous methods, displaying superior performance in our model. Class activation maps display how the network reaches the final decision.
Isolation Distributional Kernel: A New Tool for Point & Group Anomaly Detection
Sep 24, 2020
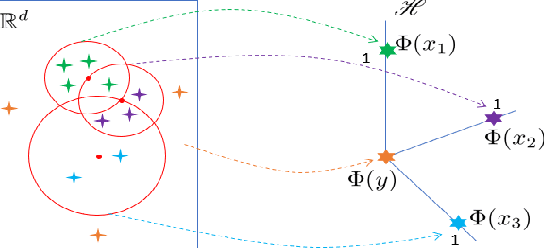
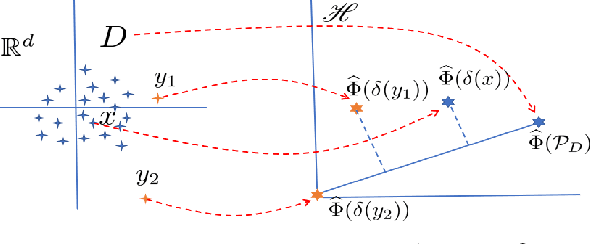
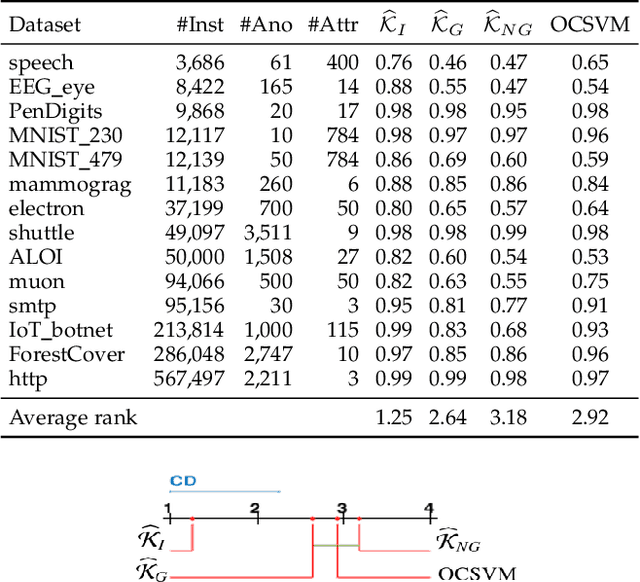
We introduce Isolation Distributional Kernel as a new way to measure the similarity between two distributions. Existing approaches based on kernel mean embedding, which convert a point kernel to a distributional kernel, have two key issues: the point kernel employed has a feature map with intractable dimensionality; and it is {\em data independent}. This paper shows that Isolation Distributional Kernel (IDK), which is based on a {\em data dependent} point kernel, addresses both key issues. We demonstrate IDK's efficacy and efficiency as a new tool for kernel based anomaly detection for both point and group anomalies. Without explicit learning, using IDK alone outperforms existing kernel based point anomaly detector OCSVM and other kernel mean embedding methods that rely on Gaussian kernel. For group anomaly detection,we introduce an IDK based detector called IDK$^2$. It reformulates the problem of group anomaly detection in input space into the problem of point anomaly detection in Hilbert space, without the need for learning. IDK$^2$ runs orders of magnitude faster than group anomaly detector OCSMM.We reveal for the first time that an effective kernel based anomaly detector based on kernel mean embedding must employ a characteristic kernel which is data dependent.
Satellite Image Classification with Deep Learning
Oct 13, 2020
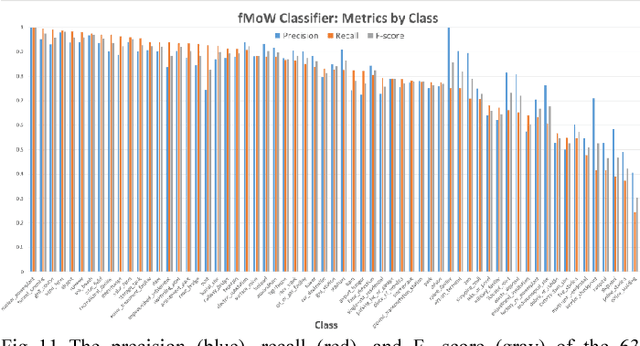
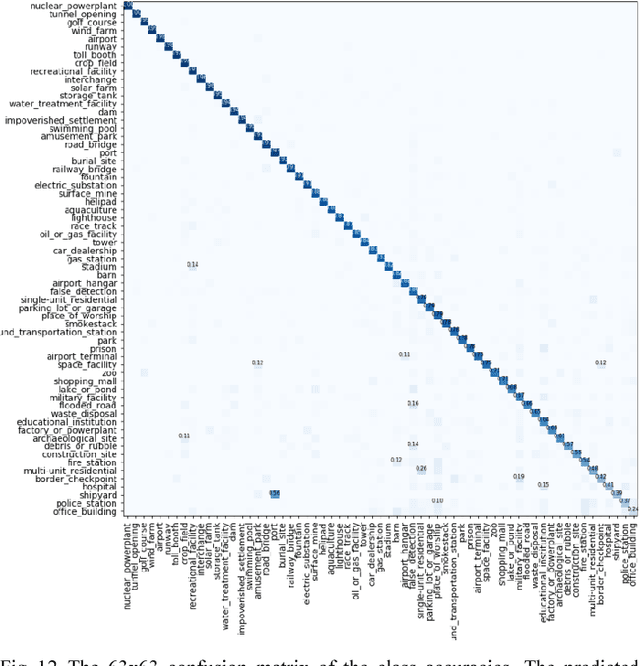

Satellite imagery is important for many applications including disaster response, law enforcement, and environmental monitoring. These applications require the manual identification of objects and facilities in the imagery. Because the geographic expanses to be covered are great and the analysts available to conduct the searches are few, automation is required. Yet traditional object detection and classification algorithms are too inaccurate and unreliable to solve the problem. Deep learning is a family of machine learning algorithms that have shown promise for the automation of such tasks. It has achieved success in image understanding by means of convolutional neural networks. In this paper we apply them to the problem of object and facility recognition in high-resolution, multi-spectral satellite imagery. We describe a deep learning system for classifying objects and facilities from the IARPA Functional Map of the World (fMoW) dataset into 63 different classes. The system consists of an ensemble of convolutional neural networks and additional neural networks that integrate satellite metadata with image features. It is implemented in Python using the Keras and TensorFlow deep learning libraries and runs on a Linux server with an NVIDIA Titan X graphics card. At the time of writing the system is in 2nd place in the fMoW TopCoder competition. Its total accuracy is 83%, the F1 score is 0.797, and it classifies 15 of the classes with accuracies of 95% or better.
* 7 pages, 18 figures, 2017 IEEE Applied Imagery Pattern Recognition Workshop (AIPR)
Data Augmentation for Training Dialog Models Robust to Speech Recognition Errors
Jun 10, 2020
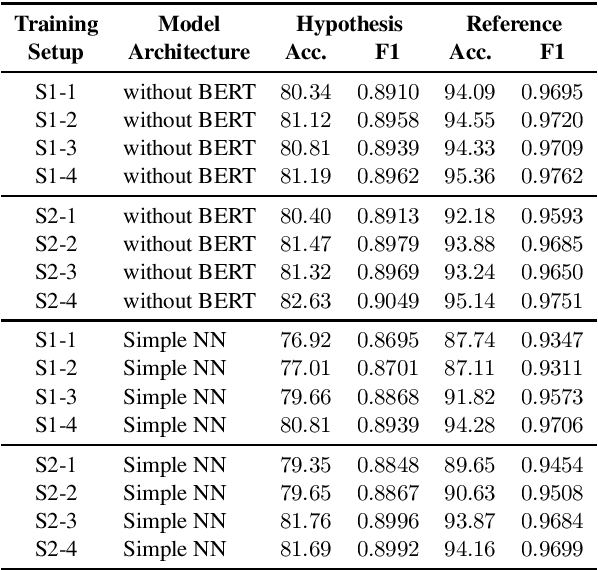
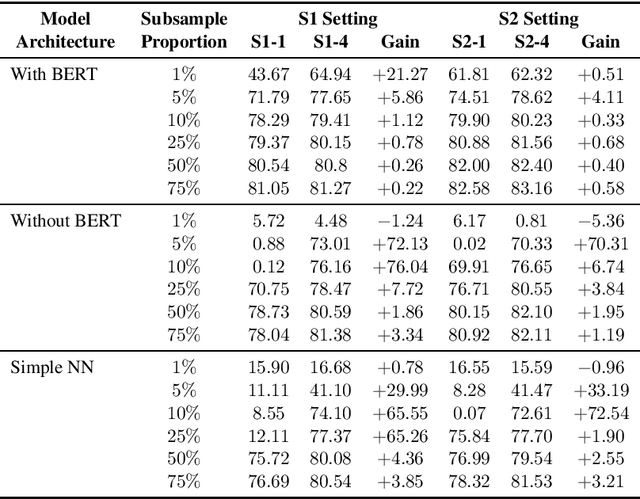
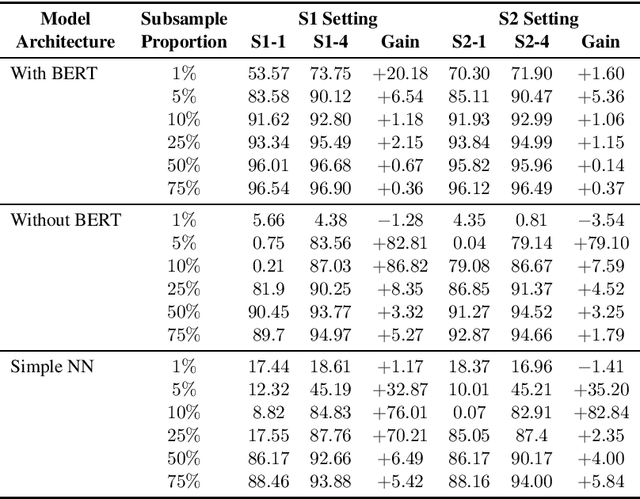
Speech-based virtual assistants, such as Amazon Alexa, Google assistant, and Apple Siri, typically convert users' audio signals to text data through automatic speech recognition (ASR) and feed the text to downstream dialog models for natural language understanding and response generation. The ASR output is error-prone; however, the downstream dialog models are often trained on error-free text data, making them sensitive to ASR errors during inference time. To bridge the gap and make dialog models more robust to ASR errors, we leverage an ASR error simulator to inject noise into the error-free text data, and subsequently train the dialog models with the augmented data. Compared to other approaches for handling ASR errors, such as using ASR lattice or end-to-end methods, our data augmentation approach does not require any modification to the ASR or downstream dialog models; our approach also does not introduce any additional latency during inference time. We perform extensive experiments on benchmark data and show that our approach improves the performance of downstream dialog models in the presence of ASR errors, and it is particularly effective in the low-resource situations where there are constraints on model size or the training data is scarce.
Gaussianizing the Earth: Multidimensional Information Measures for Earth Data Analysis
Oct 13, 2020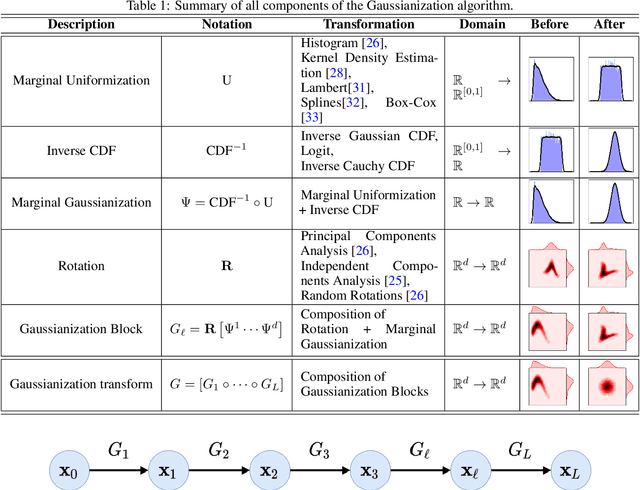
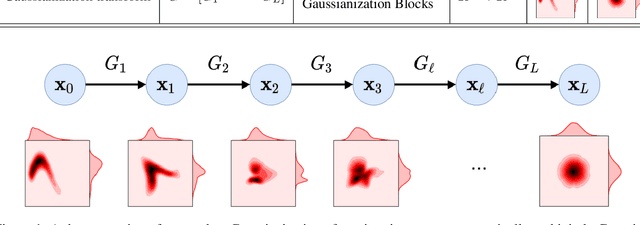
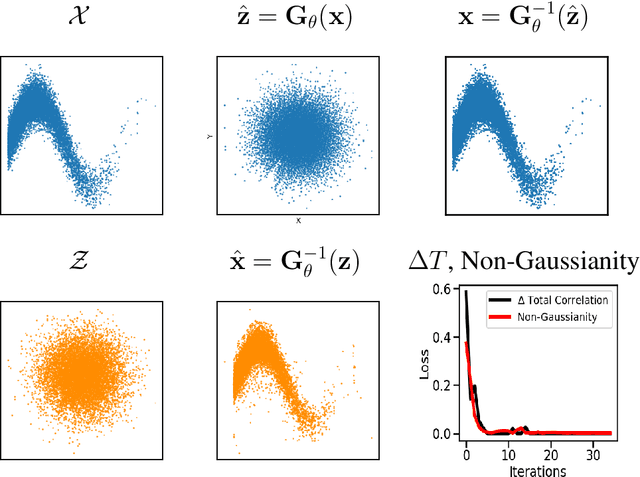
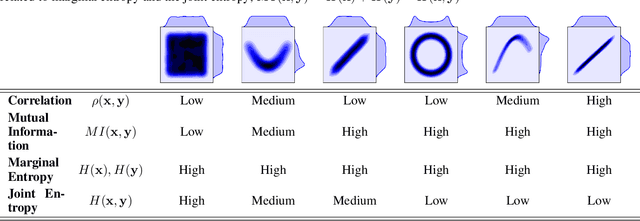
Information theory is an excellent framework for analyzing Earth system data because it allows us to characterize uncertainty and redundancy, and is universally interpretable. However, accurately estimating information content is challenging because spatio-temporal data is high-dimensional, heterogeneous and has non-linear characteristics. In this paper, we apply multivariate Gaussianization for probability density estimation which is robust to dimensionality, comes with statistical guarantees, and is easy to apply. In addition, this methodology allows us to estimate information-theoretic measures to characterize multivariate densities: information, entropy, total correlation, and mutual information. We demonstrate how information theory measures can be applied in various Earth system data analysis problems. First we show how the method can be used to jointly Gaussianize radar backscattering intensities, synthesize hyperspectral data, and quantify of information content in aerial optical images. We also quantify the information content of several variables describing the soil-vegetation status in agro-ecosystems, and investigate the temporal scales that maximize their shared information under extreme events such as droughts. Finally, we measure the relative information content of space and time dimensions in remote sensing products and model simulations involving long records of key variables such as precipitation, sensible heat and evaporation. Results confirm the validity of the method, for which we anticipate a wide use and adoption. Code and demos of the implemented algorithms and information-theory measures are provided.