 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Deep Neural Networks and Neuro-Fuzzy Networks for Intellectual Analysis of Economic Systems
Nov 11, 2020
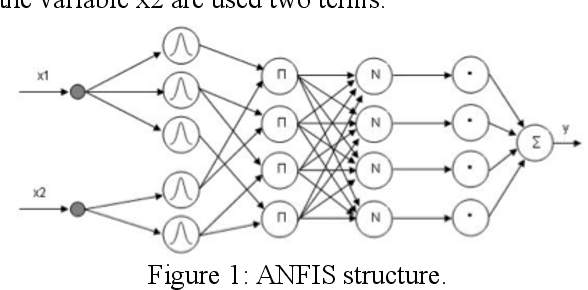
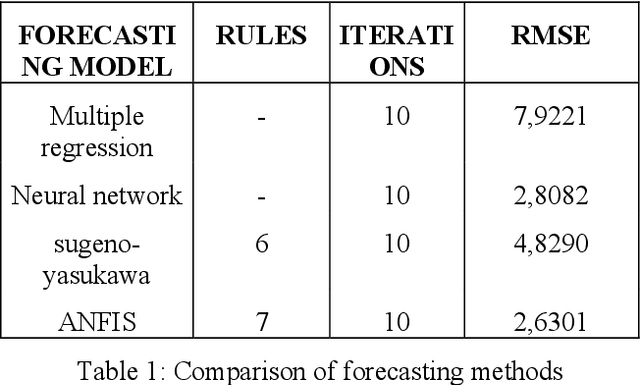
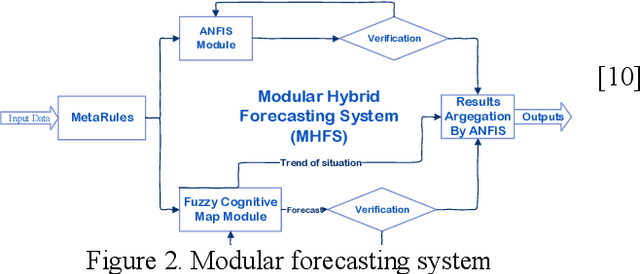
In tis paper we consider approaches for time series forecasting based on deep neural networks and neuro-fuzzy nets. Also, we make short review of researches in forecasting based on various models of ANFIS models. Deep Learning has proven to be an effective method for making highly accurate predictions from complex data sources. Also, we propose our models of DL and Neuro-Fuzzy Networks for this task. Finally, we show possibility of using these models for data science tasks. This paper presents also an overview of approaches for incorporating rule-based methodology into deep learning neural networks.
PAQ: 65 Million Probably-Asked Questions and What You Can Do With Them
Feb 13, 2021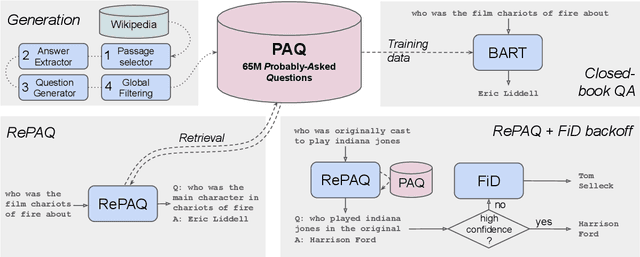
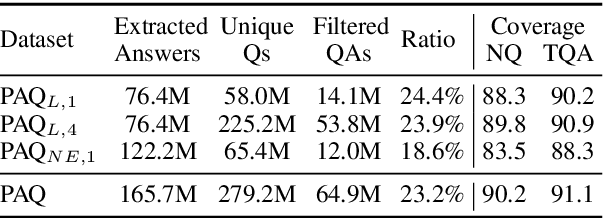

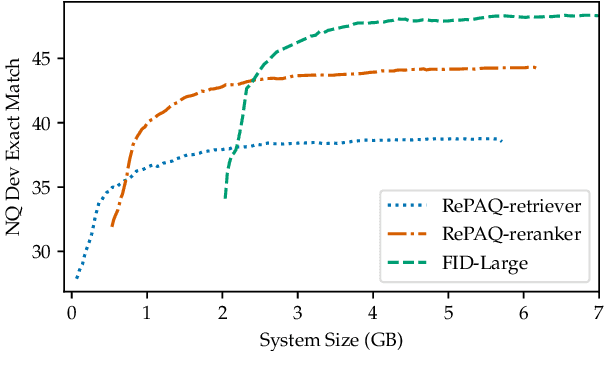
Open-domain Question Answering models which directly leverage question-answer (QA) pairs, such as closed-book QA (CBQA) models and QA-pair retrievers, show promise in terms of speed and memory compared to conventional models which retrieve and read from text corpora. QA-pair retrievers also offer interpretable answers, a high degree of control, and are trivial to update at test time with new knowledge. However, these models lack the accuracy of retrieve-and-read systems, as substantially less knowledge is covered by the available QA-pairs relative to text corpora like Wikipedia. To facilitate improved QA-pair models, we introduce Probably Asked Questions (PAQ), a very large resource of 65M automatically-generated QA-pairs. We introduce a new QA-pair retriever, RePAQ, to complement PAQ. We find that PAQ preempts and caches test questions, enabling RePAQ to match the accuracy of recent retrieve-and-read models, whilst being significantly faster. Using PAQ, we train CBQA models which outperform comparable baselines by 5%, but trail RePAQ by over 15%, indicating the effectiveness of explicit retrieval. RePAQ can be configured for size (under 500MB) or speed (over 1K questions per second) whilst retaining high accuracy. Lastly, we demonstrate RePAQ's strength at selective QA, abstaining from answering when it is likely to be incorrect. This enables RePAQ to ``back-off" to a more expensive state-of-the-art model, leading to a combined system which is both more accurate and 2x faster than the state-of-the-art model alone.
EfficientQA : a RoBERTa Based Phrase-Indexed Question-Answering System
Jan 30, 2021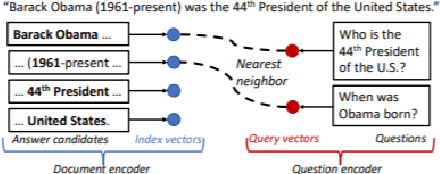
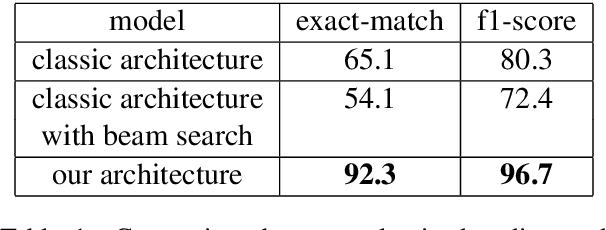
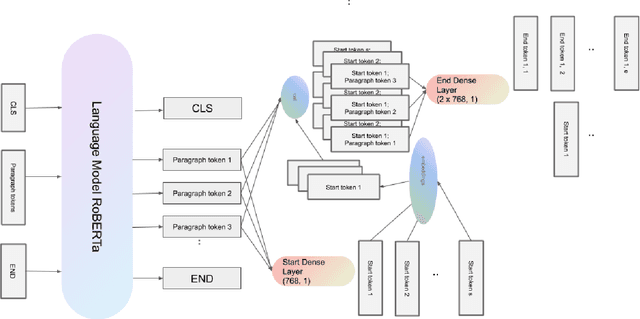
State-of-the-art extractive question answering models achieve superhuman performances on the SQuAD benchmark. Yet, they are unreasonably heavy and need expensive GPU computing to answer questions in a reasonable time. Thus, they cannot be used for real-world queries on hundreds of thousands of documents in the open-domain question answering paradigm. In this paper, we explore the possibility to transfer the natural language understanding of language models into dense vectors representing questions and answer candidates, in order to make the task of question-answering compatible with a simple nearest neighbor search task. This new model, that we call EfficientQA, takes advantage from the pair of sequences kind of input of BERT-based models to build meaningful dense representations of candidate answers. These latter are extracted from the context in a question-agnostic fashion. Our model achieves state-of-the-art results in Phrase-Indexed Question Answering (PIQA) beating the previous state-of-art by 1.3 points in exact-match and 1.4 points in f1-score. These results show that dense vectors are able to embed very rich semantic representations of sequences, although these ones were built from language models not originally trained for the use-case. Thus, in order to build more resource efficient NLP systems in the future, training language models that are better adapted to build dense representations of phrases is one of the possibilities.
Autism Spectrum Disorder Classification using Graph Kernels on Multidimensional Time Series
Nov 29, 2016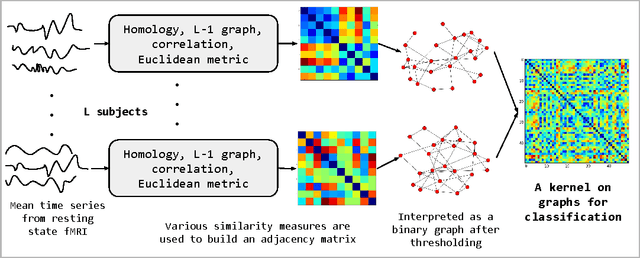
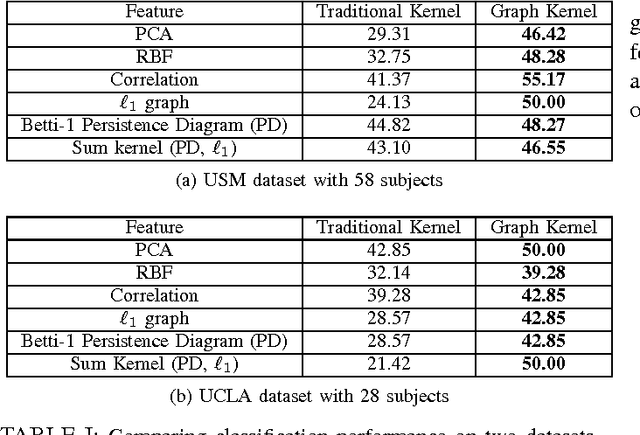
We present an approach to model time series data from resting state fMRI for autism spectrum disorder (ASD) severity classification. We propose to adopt kernel machines and employ graph kernels that define a kernel dot product between two graphs. This enables us to take advantage of spatio-temporal information to capture the dynamics of the brain network, as opposed to aggregating them in the spatial or temporal dimension. In addition to the conventional similarity graphs, we explore the use of L1 graph using sparse coding, and the persistent homology of time delay embeddings, in the proposed pipeline for ASD classification. In our experiments on two datasets from the ABIDE collection, we demonstrate a consistent and significant advantage in using graph kernels over traditional linear or non linear kernels for a variety of time series features.
An Analysis of Frame-skipping in Reinforcement Learning
Feb 07, 2021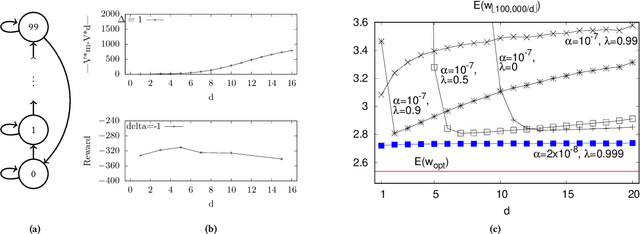
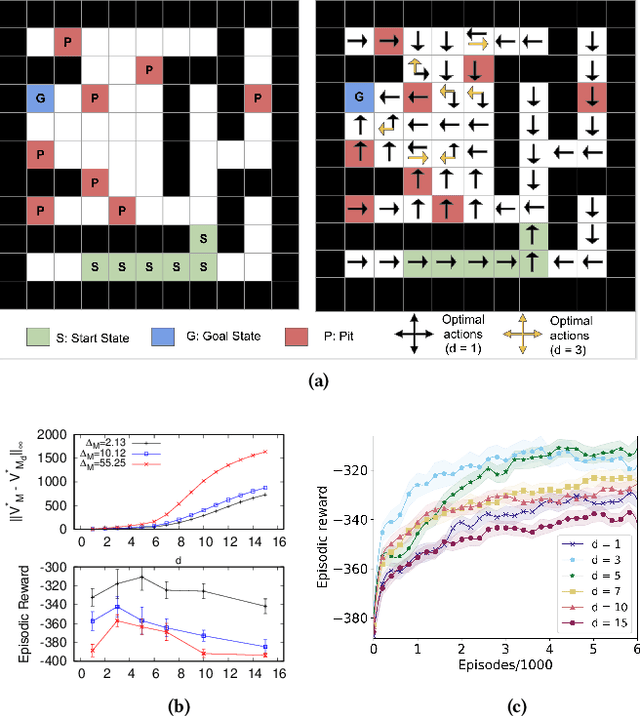
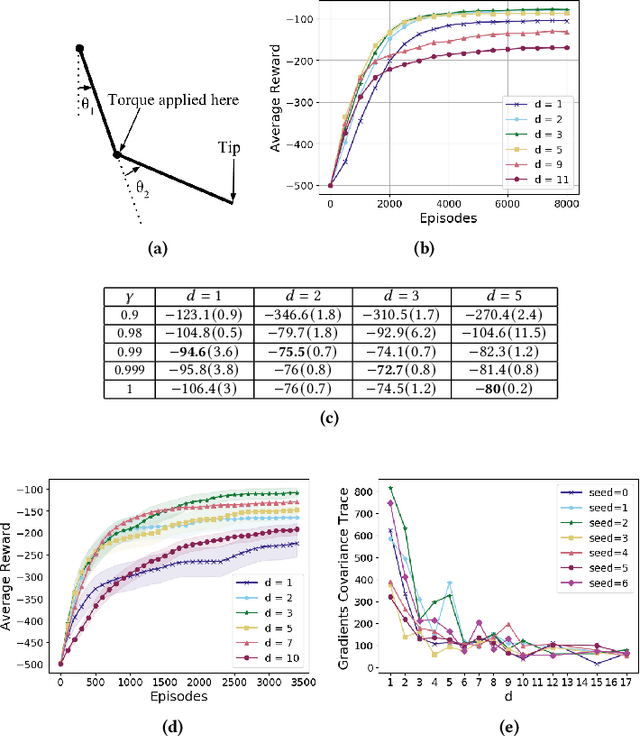
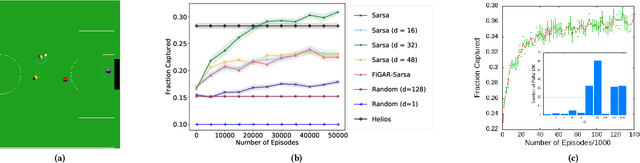
In the practice of sequential decision making, agents are often designed to sense state at regular intervals of $d$ time steps, $d > 1$, ignoring state information in between sensing steps. While it is clear that this practice can reduce sensing and compute costs, recent results indicate a further benefit. On many Atari console games, reinforcement learning (RL) algorithms deliver substantially better policies when run with $d > 1$ -- in fact with $d$ even as high as $180$. In this paper, we investigate the role of the parameter $d$ in RL; $d$ is called the "frame-skip" parameter, since states in the Atari domain are images. For evaluating a fixed policy, we observe that under standard conditions, frame-skipping does not affect asymptotic consistency. Depending on other parameters, it can possibly even benefit learning. To use $d > 1$ in the control setting, one must first specify which $d$-step open-loop action sequences can be executed in between sensing steps. We focus on "action-repetition", the common restriction of this choice to $d$-length sequences of the same action. We define a task-dependent quantity called the "price of inertia", in terms of which we upper-bound the loss incurred by action-repetition. We show that this loss may be offset by the gain brought to learning by a smaller task horizon. Our analysis is supported by experiments on different tasks and learning algorithms.
Joint Resource Block and Beamforming Optimization for Cellular-Connected UAV Networks: A Hybrid D3QN-DDPG Approach
Feb 25, 2021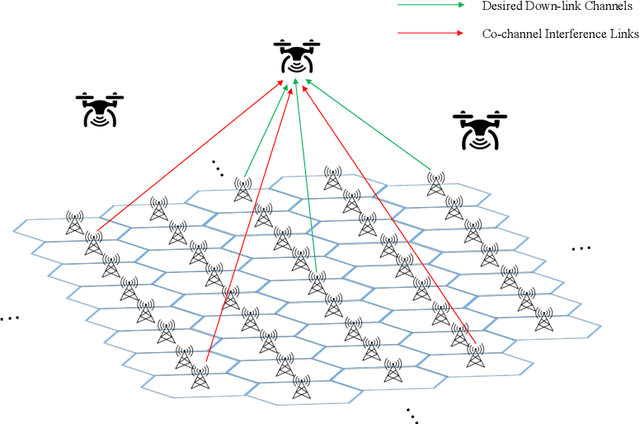
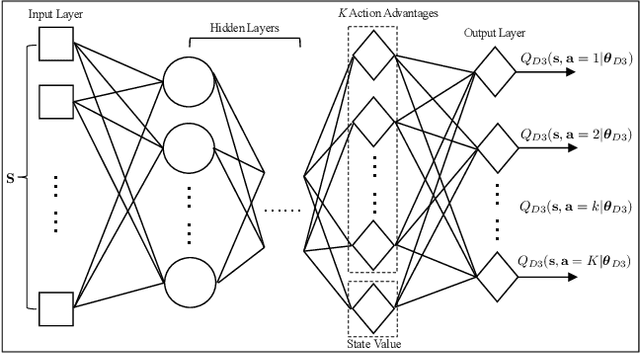
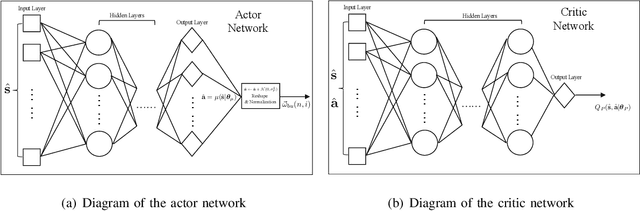
Integrating unmanned aerial vehicle (UAV) into the existing cellular networks that are delicately designed for terrestrial transmissions faces lots of challenges, in which one of the most striking concerns is how to adopt UAV into the cellular networks with less (or even without) adverse effects to ground users. In this paper, a cellular-connected UAV network is considered, in which multiple UAVs receive messages from terrestrial base stations (BSs) in the down-link, while BSs are serving ground users in their cells. Besides, the line-of-sight (LoS) wireless links are more likely to be established in ground-to-air (G2A) transmission scenarios. On one hand, UAVs may potentially get access to more BSs. On the other hand, more co-channel interferences could be involved. To enhance wireless transmission quality between UAVs and BSs while protecting the ground users from being interfered by the G2A communications, a joint time-frequency resource block (RB) and beamforming optimization problem is proposed and investigated in this paper. Specifically, with given flying trajectory, the ergodic outage duration (EOD) of UAV is minimized with the aid of RB resource allocation and beamforming design. Unfortunately, the proposed optimization problem is hard to be solved via standard optimization techniques, if not impossible. To crack this nut, a deep reinforcement learning (DRL) solution is proposed, where deep double duelling Q network (D3QN) and deep deterministic policy gradient (DDPG) are invoked to deal with RB allocation in discrete action domain and beamforming design in continuous action regime, respectively. The hybrid D3QN-DDPG solution is applied to solve the outer Markov decision process (MDP) and the inner MDP interactively so that it can achieve the sub-optimal result for the considered optimization problem.
MeInGame: Create a Game Character Face from a Single Portrait
Feb 07, 2021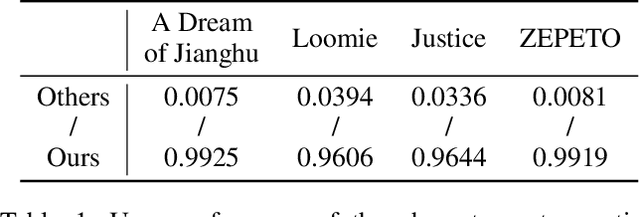
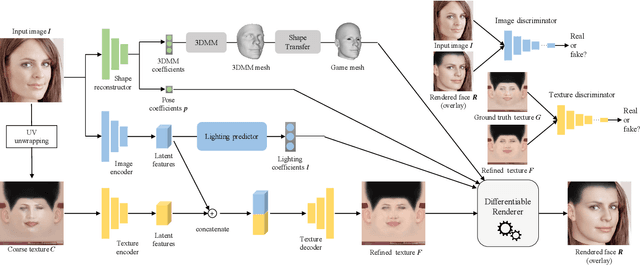
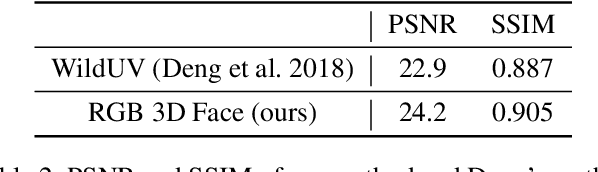

Many deep learning based 3D face reconstruction methods have been proposed recently, however, few of them have applications in games. Current game character customization systems either require players to manually adjust considerable face attributes to obtain the desired face, or have limited freedom of facial shape and texture. In this paper, we propose an automatic character face creation method that predicts both facial shape and texture from a single portrait, and it can be integrated into most existing 3D games. Although 3D Morphable Face Model (3DMM) based methods can restore accurate 3D faces from single images, the topology of 3DMM mesh is different from the meshes used in most games. To acquire fidelity texture, existing methods require a large amount of face texture data for training, while building such datasets is time-consuming and laborious. Besides, such a dataset collected under laboratory conditions may not generalized well to in-the-wild situations. To tackle these problems, we propose 1) a low-cost facial texture acquisition method, 2) a shape transfer algorithm that can transform the shape of a 3DMM mesh to games, and 3) a new pipeline for training 3D game face reconstruction networks. The proposed method not only can produce detailed and vivid game characters similar to the input portrait, but can also eliminate the influence of lighting and occlusions. Experiments show that our method outperforms state-of-the-art methods used in games.
ProLab: perceptually uniform projective colour coordinate system
Dec 14, 2020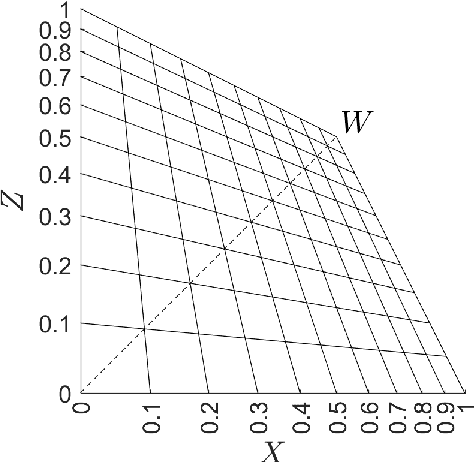
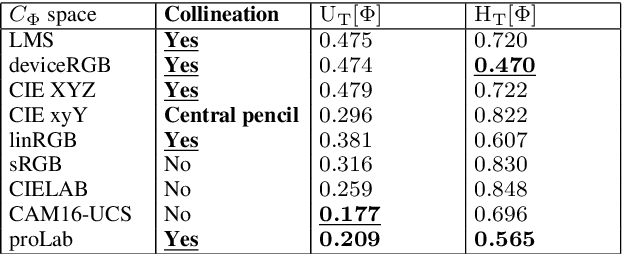
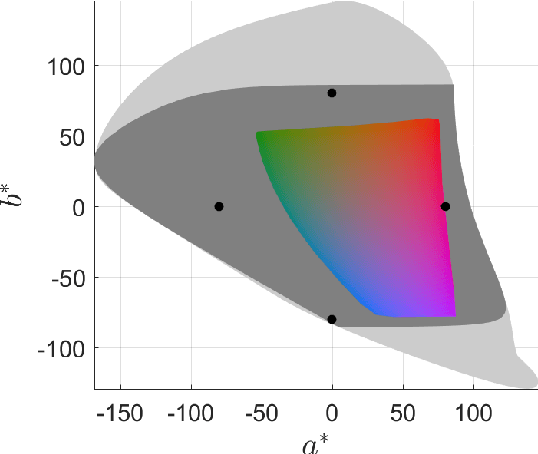

In this work, we propose proLab: a new colour coordinate system derived as a 3D projective transformation of CIE XYZ. We show that proLab is far ahead of the widely used CIELAB coordinate system (though inferior to the modern CAM16-UCS) according to perceptual uniformity evaluated by the STRESS metric in reference to the CIEDE2000 colour difference formula. At the same time, angular errors of chromaticity estimation that are standard for linear colour spaces can also be used in proLab since projective transformations preserve the linearity of manifolds. Unlike in linear spaces, angular errors for different hues are normalized according to human colour discrimination thresholds within proLab. We also demonstrate that shot noise in proLab is more homoscedastic than in CAM16-UCS or other standard colour spaces. This makes proLab a convenient coordinate system in which to perform linear colour analysis.
WaveFuse: A Unified Deep Framework for Image Fusion with Discrete Wavelet Transform
Sep 03, 2020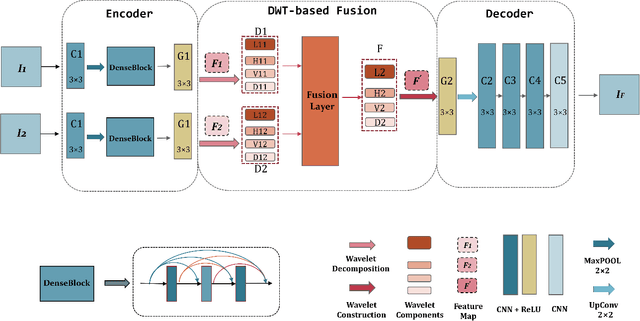
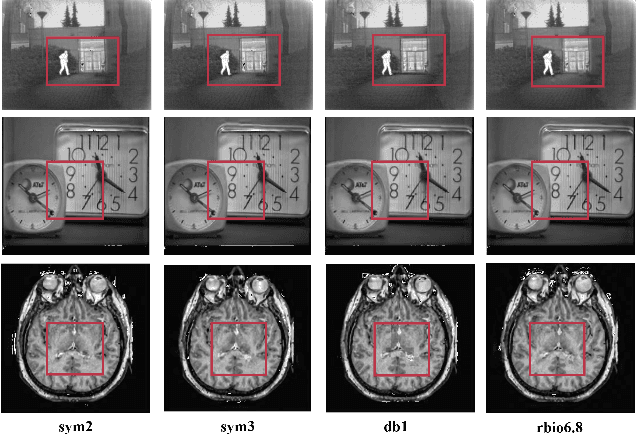
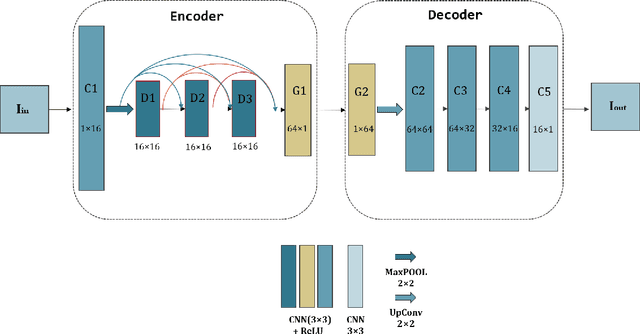
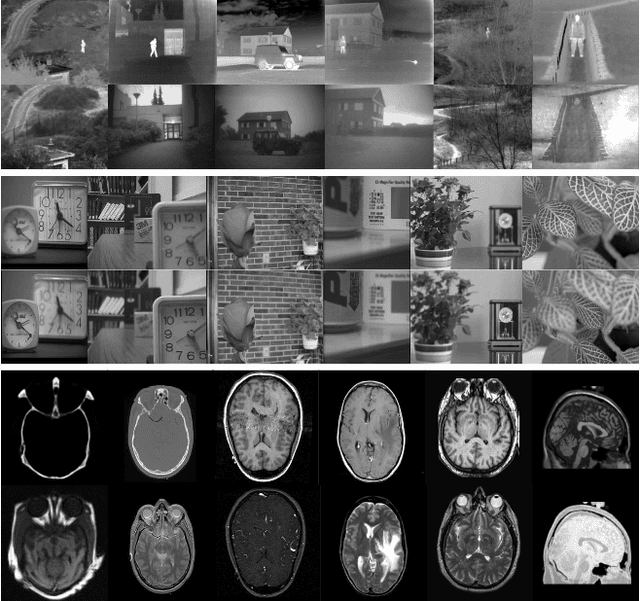
We propose an unsupervised image fusion architecture for multiple application scenarios based on the combination of multi-scale discrete wavelet transform through regional energy and deep learning. To our best knowledge, this is the first time the conventional image fusion method has been combined with deep learning. The useful information of feature maps can be utilized adequately through multi-scale discrete wavelet transform in our proposed method.Compared with other state-of-the-art fusion method, the proposed algorithm exhibits better fusion performance in both subjective and objective evaluation. Moreover, it's worth mentioning that comparable fusion performance trained in COCO dataset can be obtained by training with a much smaller dataset with only hundreds of images chosen randomly from COCO. Hence, the training time is shortened substantially, leading to the improvement of the model's performance both in practicality and training efficiency.
A Novel Face-tracking Mouth Controller and its Application to Interacting with Bioacoustic Models
Oct 07, 2020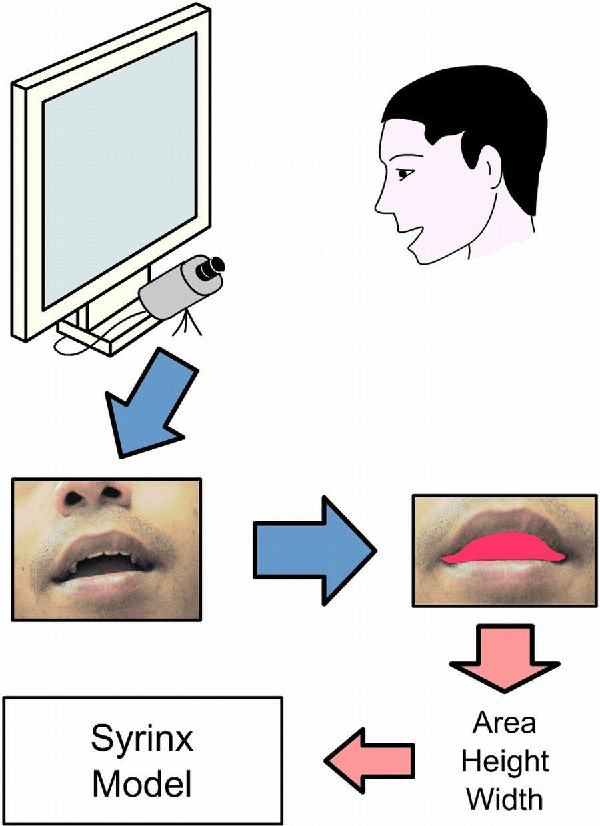
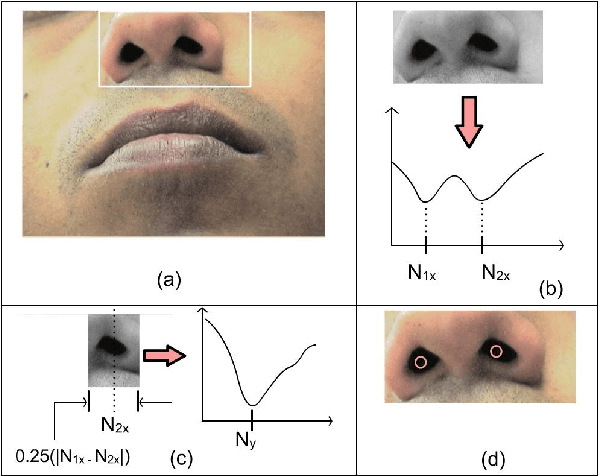
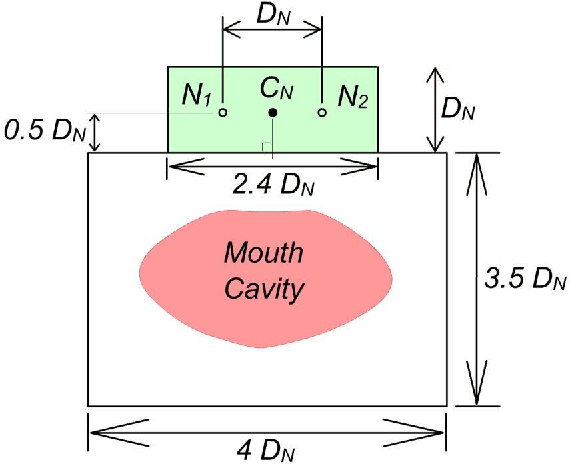
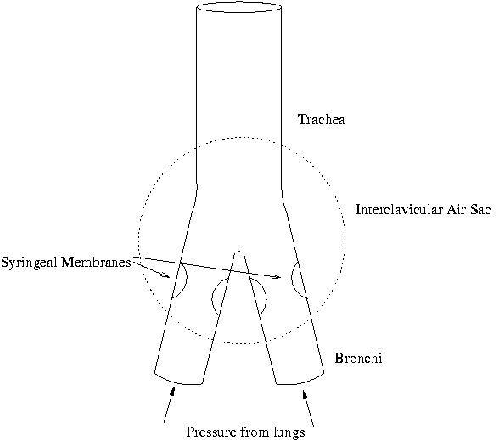
We describe a simple, computationally light, real-time system for tracking the lower face and extracting information about the shape of the open mouth from a video sequence. The system allows unencumbered control of audio synthesis modules by the action of the mouth. We report work in progress to use the mouth controller to interact with a physical model of sound production by the avian syrinx.