 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Analysis of Frame-skipping in Reinforcement Learning
Paper and Code
Feb 07, 2021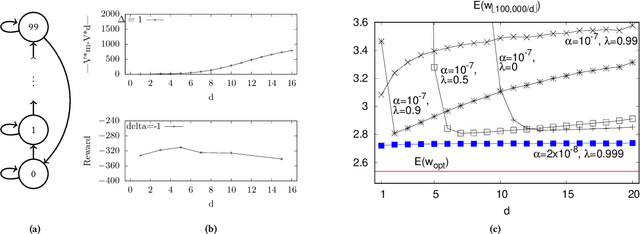
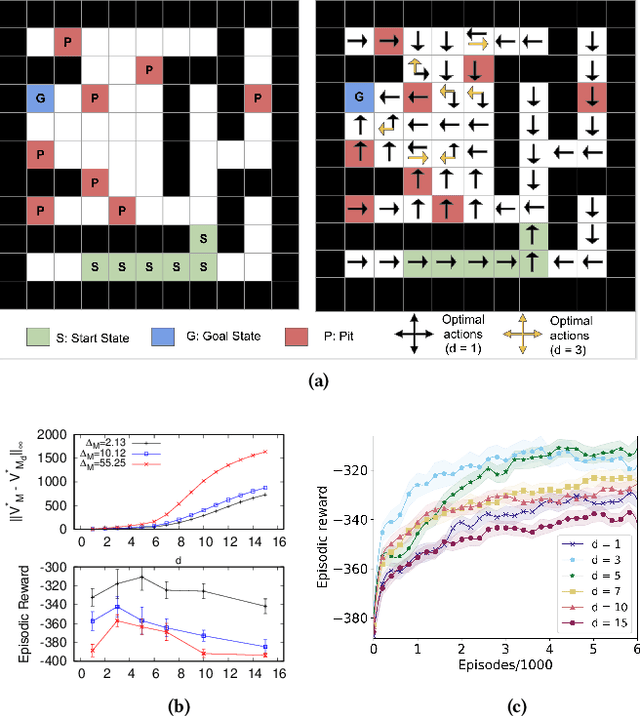
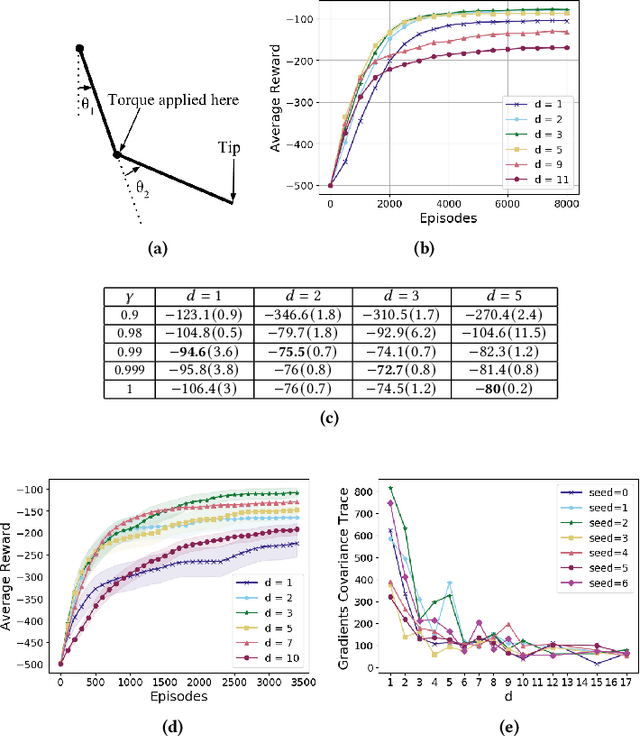
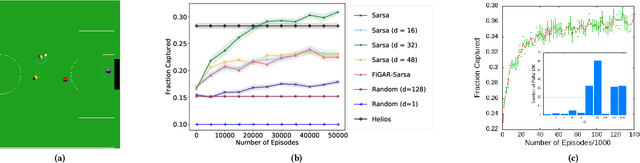
In the practice of sequential decision making, agents are often designed to sense state at regular intervals of $d$ time steps, $d > 1$, ignoring state information in between sensing steps. While it is clear that this practice can reduce sensing and compute costs, recent results indicate a further benefit. On many Atari console games, reinforcement learning (RL) algorithms deliver substantially better policies when run with $d > 1$ -- in fact with $d$ even as high as $180$. In this paper, we investigate the role of the parameter $d$ in RL; $d$ is called the "frame-skip" parameter, since states in the Atari domain are images. For evaluating a fixed policy, we observe that under standard conditions, frame-skipping does not affect asymptotic consistency. Depending on other parameters, it can possibly even benefit learning. To use $d > 1$ in the control setting, one must first specify which $d$-step open-loop action sequences can be executed in between sensing steps. We focus on "action-repetition", the common restriction of this choice to $d$-length sequences of the same action. We define a task-dependent quantity called the "price of inertia", in terms of which we upper-bound the loss incurred by action-repetition. We show that this loss may be offset by the gain brought to learning by a smaller task horizon. Our analysis is supported by experiments on different tasks and learning algorithms.