 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
"Weak AI" is Likely to Never Become "Strong AI", So What is its Greatest Value for us?
Mar 29, 2021
AI has surpassed humans across a variety of tasks such as image classification, playing games (e.g., go, "Starcraft" and poker), and protein structure prediction. However, at the same time, AI is also bearing serious controversies. Many researchers argue that little substantial progress has been made for AI in recent decades. In this paper, the author (1) explains why controversies about AI exist; (2) discriminates two paradigms of AI research, termed "weak AI" and "strong AI" (a.k.a. artificial general intelligence); (3) clarifies how to judge which paradigm a research work should be classified into; (4) discusses what is the greatest value of "weak AI" if it has no chance to develop into "strong AI".
3D Convolutional Neural Networks for Ultrasound-Based Silent Speech Interfaces
Apr 23, 2021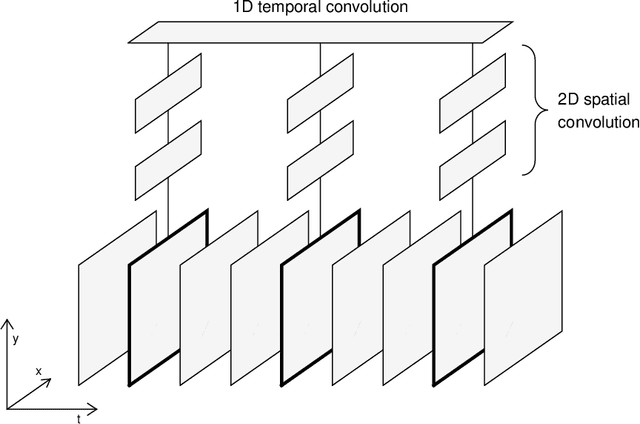
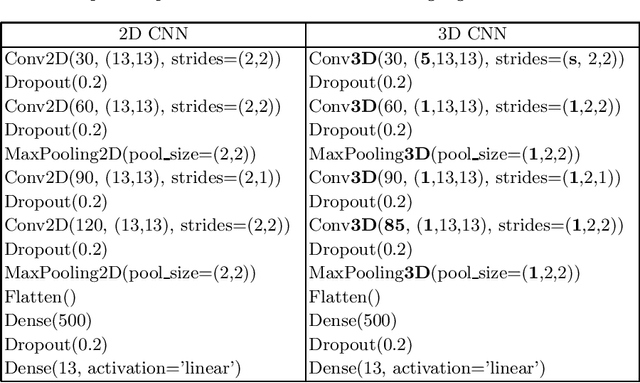

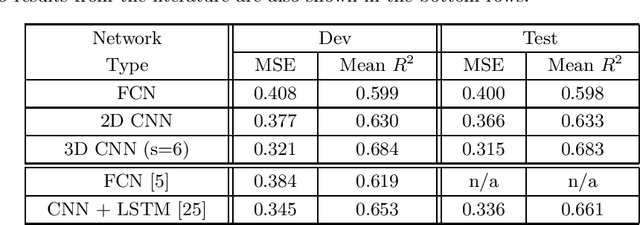
Silent speech interfaces (SSI) aim to reconstruct the speech signal from a recording of the articulatory movement, such as an ultrasound video of the tongue. Currently, deep neural networks are the most successful technology for this task. The efficient solution requires methods that do not simply process single images, but are able to extract the tongue movement information from a sequence of video frames. One option for this is to apply recurrent neural structures such as the long short-term memory network (LSTM) in combination with 2D convolutional neural networks (CNNs). Here, we experiment with another approach that extends the CNN to perform 3D convolution, where the extra dimension corresponds to time. In particular, we apply the spatial and temporal convolutions in a decomposed form, which proved very successful recently in video action recognition. We find experimentally that our 3D network outperforms the CNN+LSTM model, indicating that 3D CNNs may be a feasible alternative to CNN+LSTM networks in SSI systems.
Lighthouse Positioning System: Dataset, Accuracy, and Precision for UAV Research
Apr 23, 2021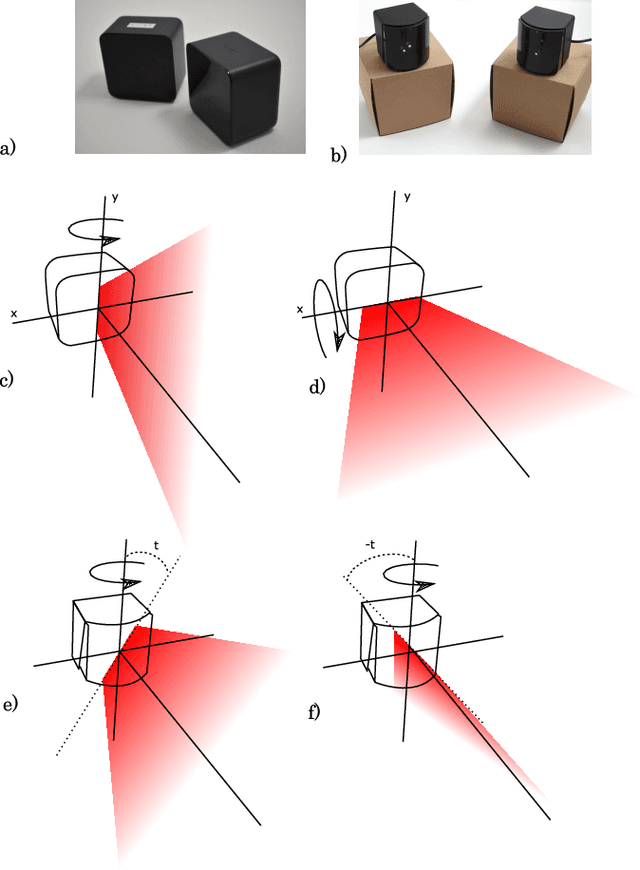

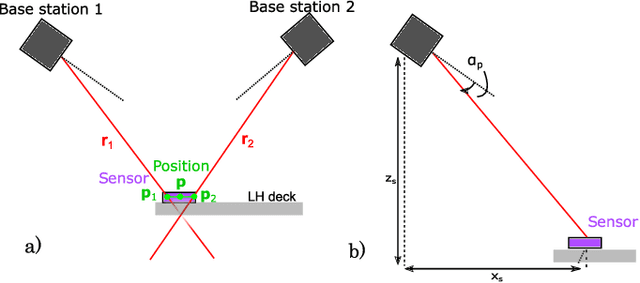

The Lighthouse system was originally developed as tracking system for virtual reality applications. Due to its affordable price, it has also found attractive use-cases in robotics in the past. However, existing works frequently rely on the centralized official tracking software, which make the solution less attractive for UAV swarms. In this work, we consider an open-source tracking software that can run onboard small Unmanned Aerial Vehicles (UAVs) in real-time and enable distributed swarming algorithms. We provide a dataset specifically for the use cases i) flight; and ii) as ground truth for other commonly-used distributed swarming localization systems such as ultra-wideband. We then use this dataset to analyze both accuracy and precision of the Lighthouse system in different use-cases. To our knowledge, we are the first to compare two different Lighthouse hardware versions with a motion capture system and the first to analyze the accuracy using tracking software that runs onboard a microcontroller.
Conditional Deep Convolutional Neural Networks for Improving the Automated Screening of Histopathological Images
May 29, 2021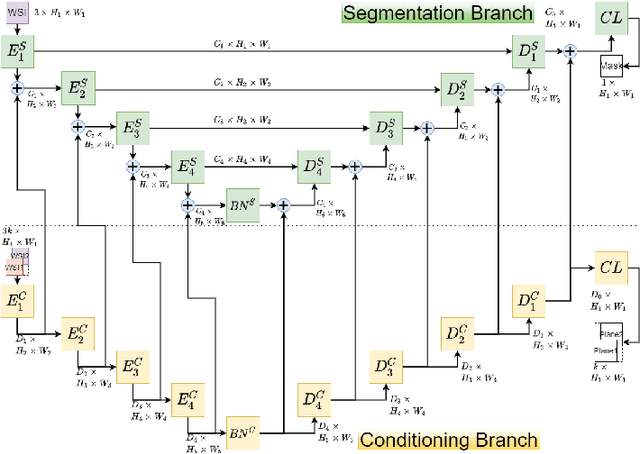
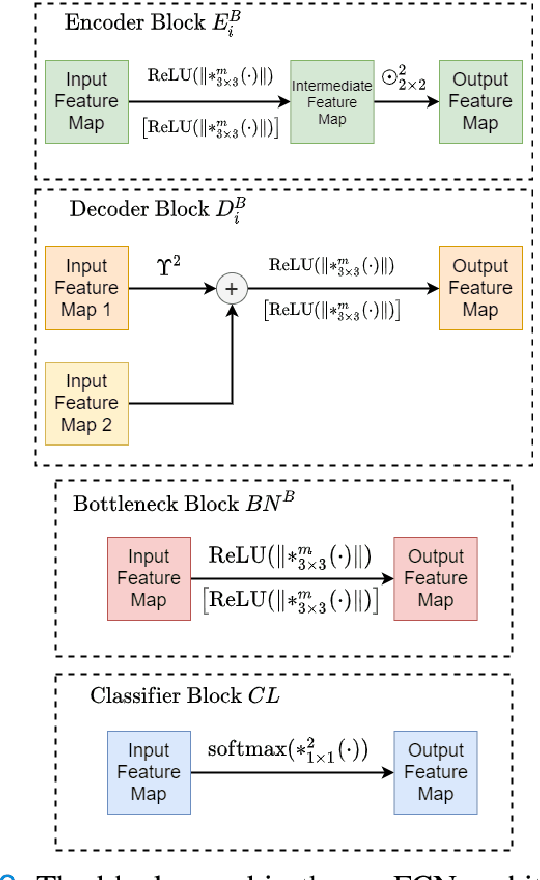
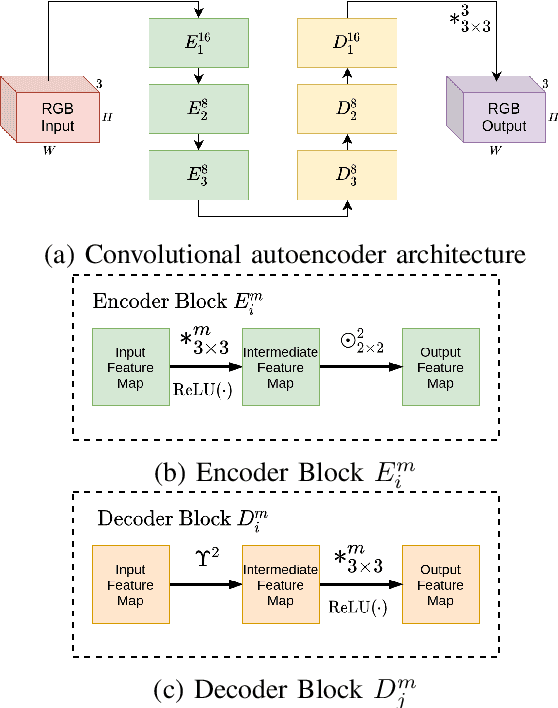
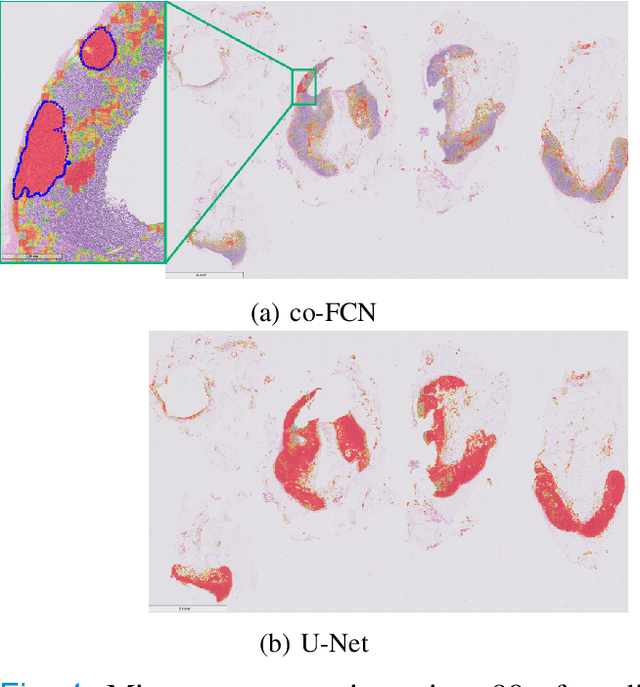
Semantic segmentation of breast cancer metastases in histopathological slides is a challenging task. In fact, significant variation in data characteristics of histopathology images (domain shift) make generalization of deep learning to unseen data difficult. Our goal is to address this challenge by using a conditional Fully Convolutional Network (co-FCN) whose output can be conditioned at run time, and which can improve its performance when a properly selected set of reference slides are used to condition the output. We adapted to our task a co-FCN originally applied to organs segmentation in volumetric medical images and we trained it on the Whole Slide Images (WSIs) from three out of five medical centers present in the CAMELYON17 dataset. We tested the performance of the network on the WSIs of the remaining centers. We also developed an automated selection strategy for selecting the conditioning subset, based on an unsupervised clustering process applied to a target-specific set of reference patches, followed by a selection policy that relies on the cluster similarities with the input patch. We benchmarked our proposed method against a U-Net trained on the same dataset with no conditioning. The conditioned network shows better performance that the U-Net on the WSIs with Isolated Tumor Cells and micro-metastases from the medical centers used as test. Our contributions are an architecture which can be applied to the histopathology domain and an automated procedure for the selection of conditioning data.
Estimating Buildings' Parameters over Time Including Prior Knowledge
Jan 09, 2019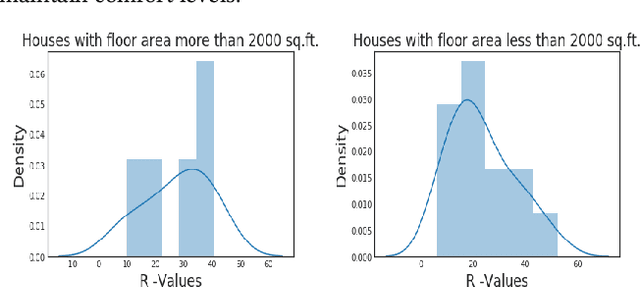
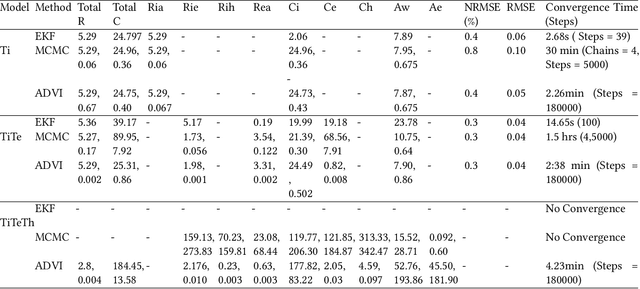
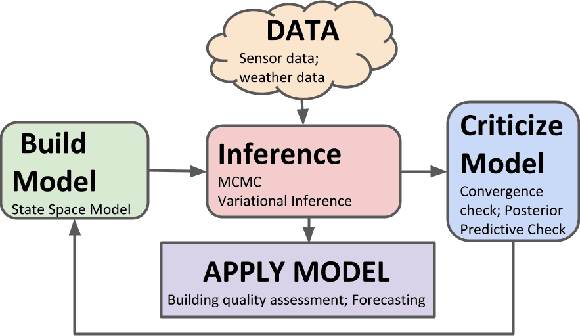
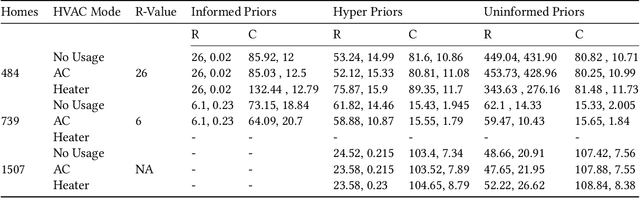
Modeling buildings' heat dynamics is a complex process which depends on various factors including weather, building thermal capacity, insulation preservation, and residents' behavior. Gray-box models offer a causal inference of those dynamics expressed in few parameters specific to built environments. These parameters can provide compelling insights into the characteristics of building artifacts and have various applications such as forecasting HVAC usage, indoor temperature control monitoring of built environments, etc. In this paper, we present a systematic study of modeling buildings' thermal characteristics and thus derive the parameters of built conditions with a Bayesian approach. We build a Bayesian state-space model that can adapt and incorporate buildings' thermal equations and propose a generalized solution that can easily adapt prior knowledge regarding the parameters. We show that a faster approximate approach using variational inference for parameter estimation can provide similar parameters as that of a more time-consuming Markov Chain Monte Carlo (MCMC) approach. We perform extensive evaluations on two datasets to understand the generative process and show that the Bayesian approach is more interpretable. We further study the effects of prior selection for the model parameters and transfer learning, where we learn parameters from one season and use them to fit the model in the other. We perform extensive evaluations on controlled and real data traces to enumerate buildings' parameter within a 95% credible interval.
Private Facial Diagnosis as an Edge Service for Parkinson's DBS Treatment Valuation
May 16, 2021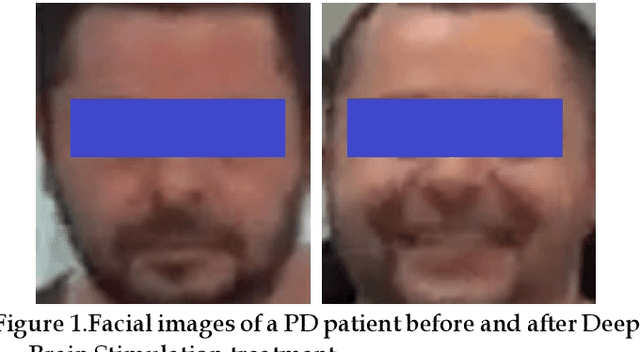

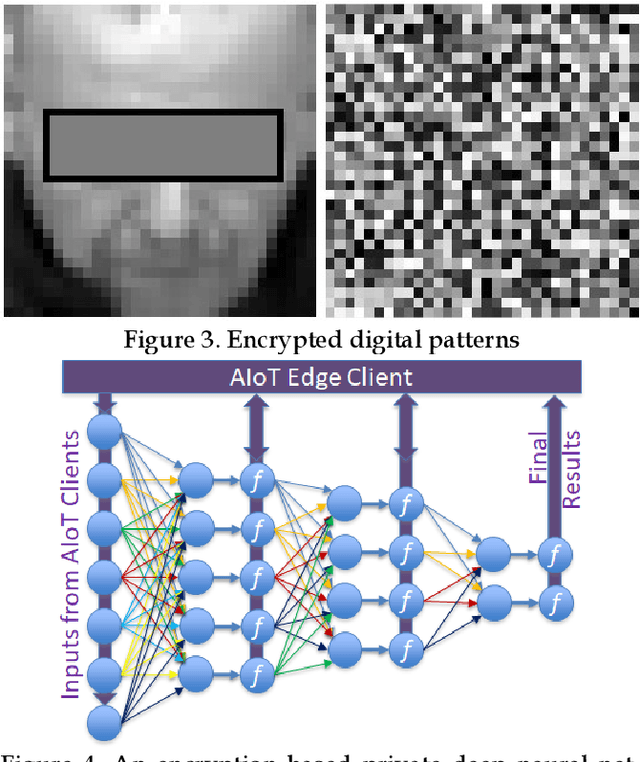
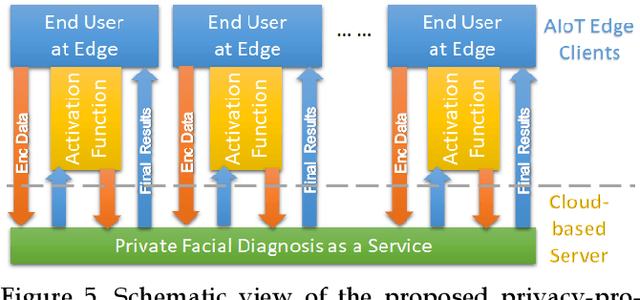
Facial phenotyping has recently been successfully exploited for medical diagnosis as a novel way to diagnose a range of diseases, where facial biometrics has been revealed to have rich links to underlying genetic or medical causes. In this paper, taking Parkinson's Diseases (PD) as a case study, we proposed an Artificial-Intelligence-of-Things (AIoT) edge-oriented privacy-preserving facial diagnosis framework to analyze the treatment of Deep Brain Stimulation (DBS) on PD patients. In the proposed framework, a new edge-based information theoretically secure framework is proposed to implement private deep facial diagnosis as a service over a privacy-preserving AIoT-oriented multi-party communication scheme, where partial homomorphic encryption (PHE) is leveraged to enable privacy-preserving deep facial diagnosis directly on encrypted facial patterns. In our experiments with a collected facial dataset from PD patients, for the first time, we demonstrated that facial patterns could be used to valuate the improvement of PD patients undergoing DBS treatment. We further implemented a privacy-preserving deep facial diagnosis framework that can achieve the same accuracy as the non-encrypted one, showing the potential of our privacy-preserving facial diagnosis as an trustworthy edge service for grading the severity of PD in patients.
Fast Beam Tracking for Reconfigurable Intelligent Surface Assisted Mobile mmWave Networks
Feb 22, 2021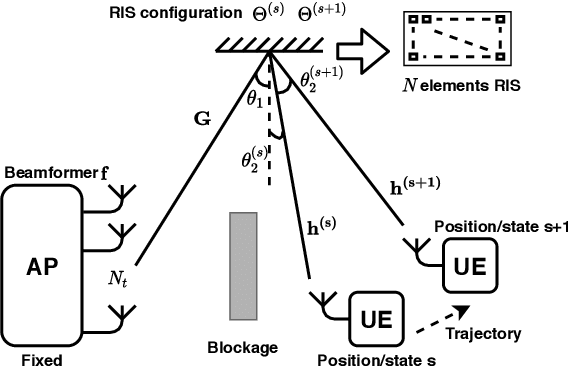
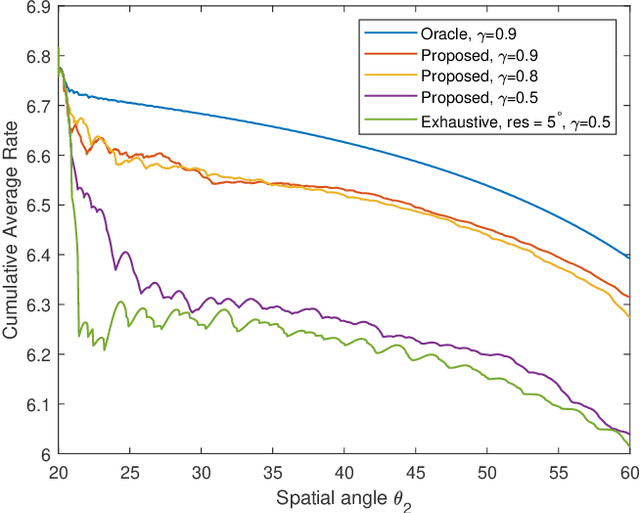
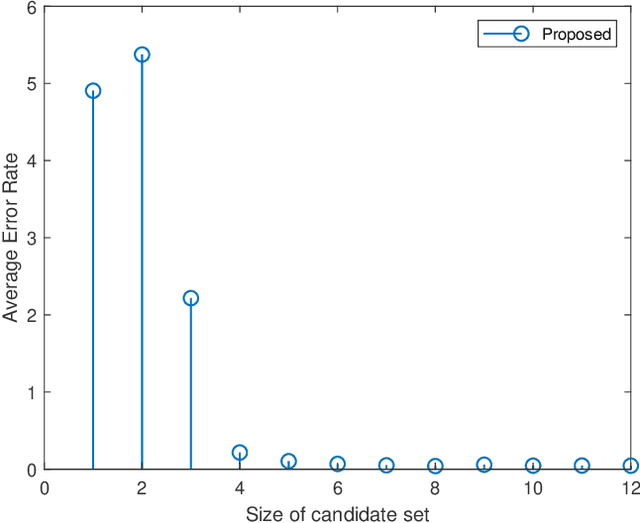
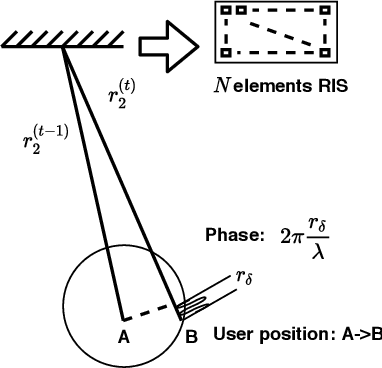
Millimeter wave (mmWave) communications are vulnerable to blockages and node mobility due to the highly directional signal beams. The emerging Reconfigurable Intelligent Surfaces (RISs) technique can effectively mitigate the blockage problem by exploring the non-line-of-sight (NLOS) path, where the beam switching is realized by digitally configuring the phases of RIS elements. To date, most efforts have been made in the stationary scenario. However, when considering node mobility, beam tracking algorithms designed specifically for RIS are needed in order to maintain the NLOS link. In this paper, a fast RIS-based beam tracking algorithm is developed by partly transforming the large amount of signaling time into the calculation happens at base station in a mmWave system with mobile users. Specifically, the differential form of optimal RIS configuration is exploited as the updating beam tracking parameter to avoid complex channel estimation procedure. The RIS-based beam tracking problem is then transformed into an optimization problem whose solution is found by a calculation-based search. Finally, by training on a small set candidate, RIS-based beam tracking is realized. The effectiveness and efficiency of the proposed RIS-based beam tracking algorithm is evaluated by simulations. It shows that the proposed algorithm has near-optimal performance with dramatic savings in terms of signaling time.
Exploring Supervised and Unsupervised Rewards in Machine Translation
Feb 22, 2021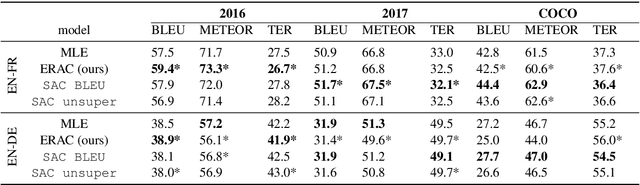
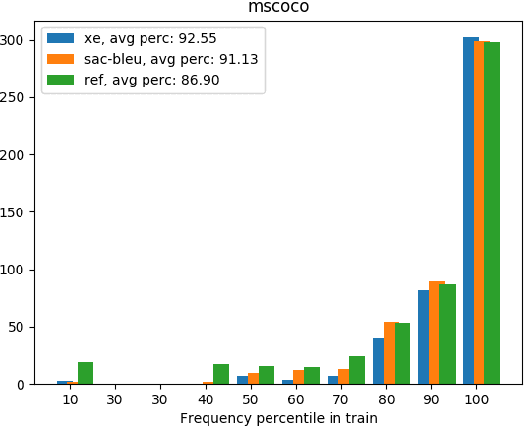

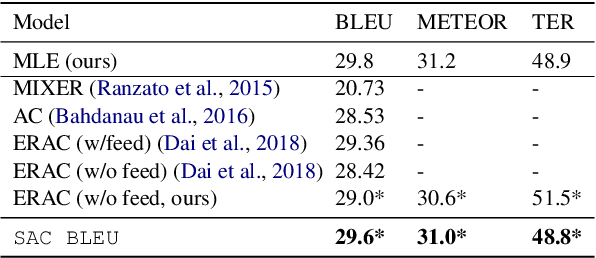
Reinforcement Learning (RL) is a powerful framework to address the discrepancy between loss functions used during training and the final evaluation metrics to be used at test time. When applied to neural Machine Translation (MT), it minimises the mismatch between the cross-entropy loss and non-differentiable evaluation metrics like BLEU. However, the suitability of these metrics as reward function at training time is questionable: they tend to be sparse and biased towards the specific words used in the reference texts. We propose to address this problem by making models less reliant on such metrics in two ways: (a) with an entropy-regularised RL method that does not only maximise a reward function but also explore the action space to avoid peaky distributions; (b) with a novel RL method that explores a dynamic unsupervised reward function to balance between exploration and exploitation. We base our proposals on the Soft Actor-Critic (SAC) framework, adapting the off-policy maximum entropy model for language generation applications such as MT. We demonstrate that SAC with BLEU reward tends to overfit less to the training data and performs better on out-of-domain data. We also show that our dynamic unsupervised reward can lead to better translation of ambiguous words.
Modular Procedural Generation for Voxel Maps
Apr 18, 2021

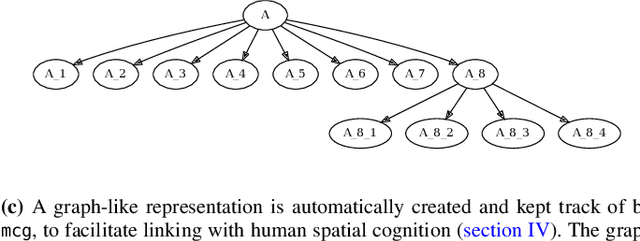
Task environments developed in Minecraft are becoming increasingly popular for artificial intelligence (AI) research. However, most of these are currently constructed manually, thus failing to take advantage of procedural content generation (PCG), a capability unique to virtual task environments. In this paper, we present mcg, an open-source library to facilitate implementing PCG algorithms for voxel-based environments such as Minecraft. The library is designed with human-machine teaming research in mind, and thus takes a 'top-down' approach to generation, simultaneously generating low and high level machine-readable representations that are suitable for empirical research. These can be consumed by downstream AI applications that consider human spatial cognition. The benefits of this approach include rapid, scalable, and efficient development of virtual environments, the ability to control the statistics of the environment at a semantic level, and the ability to generate novel environments in response to player actions in real time.
Alpha Matte Generation from Single Input for Portrait Matting
Jun 14, 2021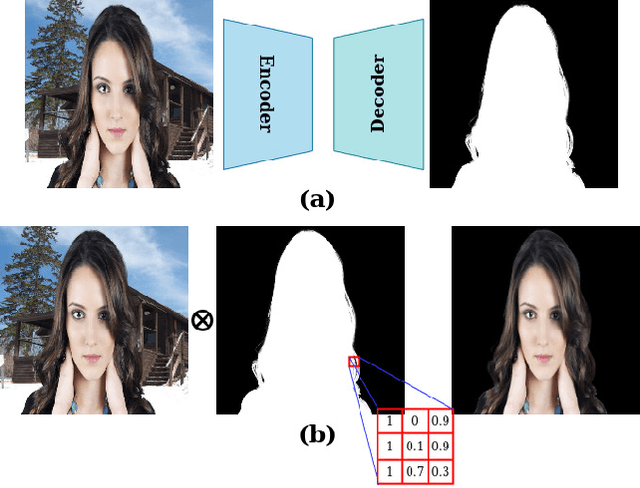
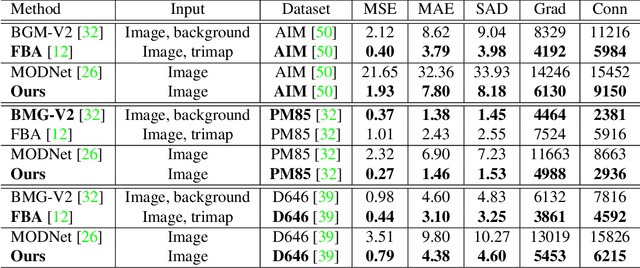
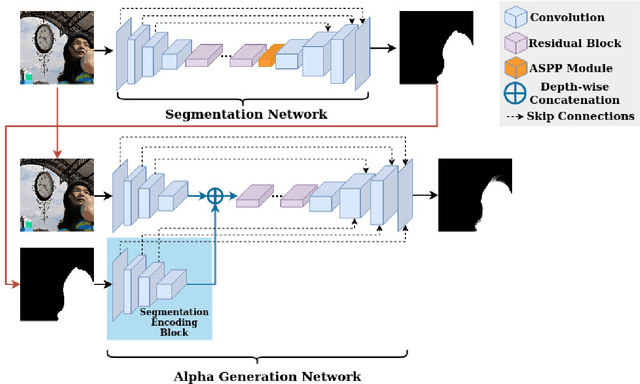
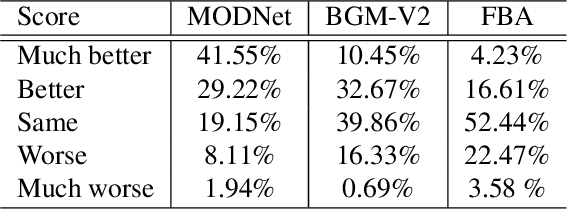
Portrait matting is an important research problem with a wide range of applications, such as video conference app, image/video editing, and post-production. The goal is to predict an alpha matte that identifies the effect of each pixel on the foreground subject. Traditional approaches and most of the existing works utilized an additional input, e.g., trimap, background image, to predict alpha matte. However, providing additional input is not always practical. Besides, models are too sensitive to these additional inputs. In this paper, we introduce an additional input-free approach to perform portrait matting using Generative Adversarial Nets (GANs). We divide the main task into two subtasks. For this, we propose a segmentation network for the person segmentation and the alpha generation network for alpha matte prediction. While the segmentation network takes an input image and produces a coarse segmentation map, the alpha generation network utilizes the same input image as well as a coarse segmentation map that is produced by the segmentation network to predict the alpha matte. Besides, we present a segmentation encoding block to downsample the coarse segmentation map and provide feature representation to the residual block. Furthermore, we propose border loss to penalize only the borders of the subject separately which is more likely to be challenging and we also adapt perceptual loss for portrait matting. To train the proposed system, we combine two different popular training datasets to improve the amount of data as well as diversity to address domain shift problems in the inference time. We tested our model on three different benchmark datasets, namely Adobe Image Matting dataset, Portrait Matting dataset, and Distinctions dataset. The proposed method outperformed the MODNet method that also takes a single input.