 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Gradient Descent in Materio
May 15, 2021
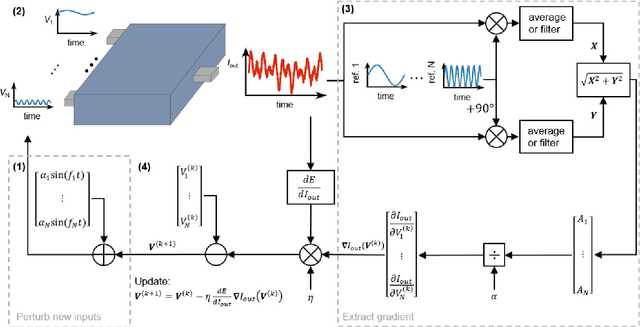
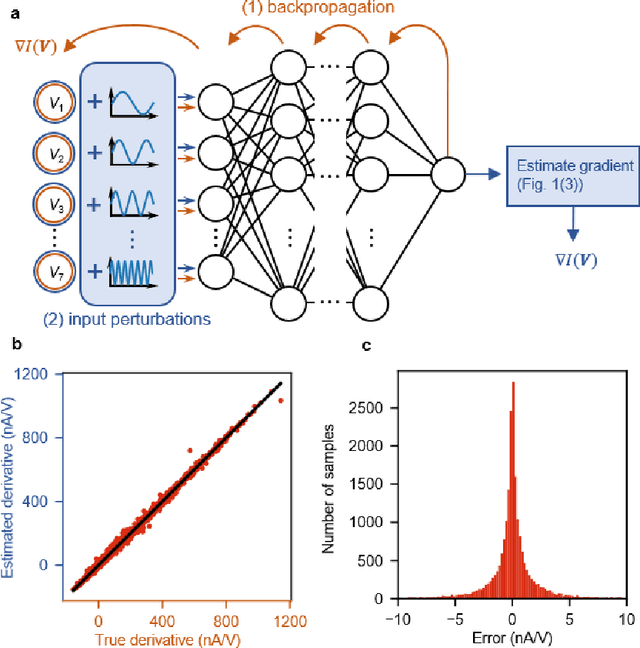
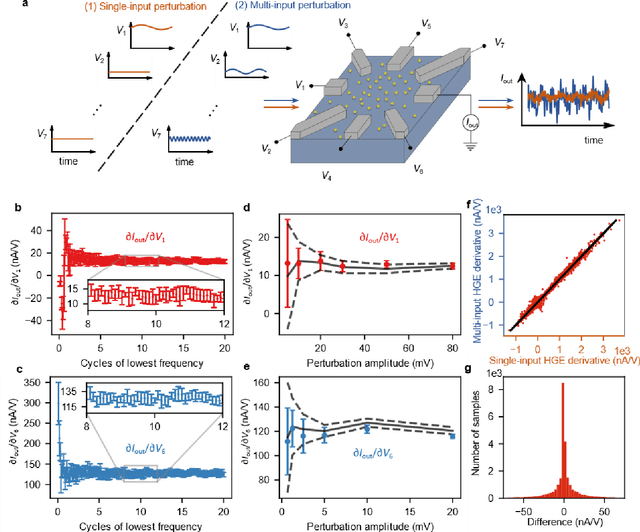
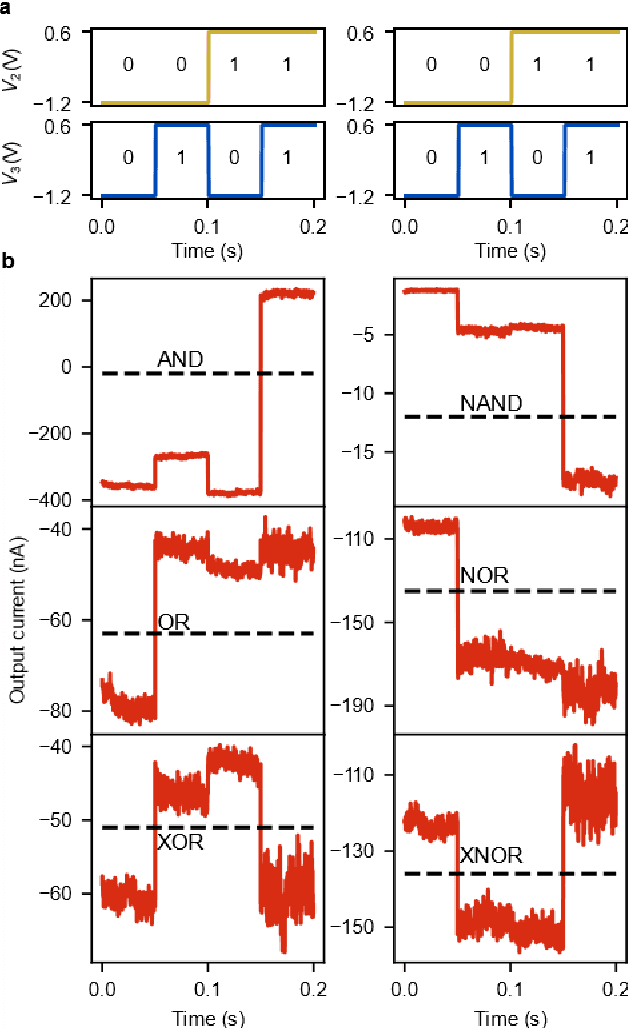
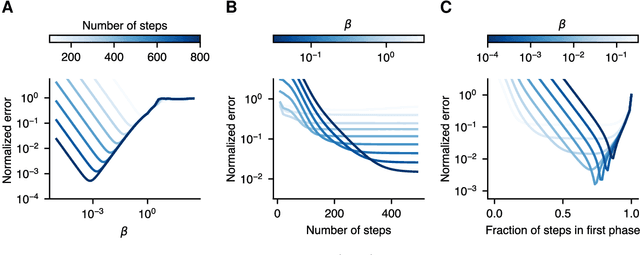
Deep learning, a multi-layered neural network approach inspired by the brain, has revolutionized machine learning. One of its key enablers has been backpropagation, an algorithm that computes the gradient of a loss function with respect to the weights in the neural network model, in combination with its use in gradient descent. However, the implementation of deep learning in digital computers is intrinsically wasteful, with energy consumption becoming prohibitively high for many applications. This has stimulated the development of specialized hardware, ranging from neuromorphic CMOS integrated circuits and integrated photonic tensor cores to unconventional, material-based computing systems. The learning process in these material systems, taking place, e.g., by artificial evolution or surrogate neural network modelling, is still a complicated and time-consuming process. Here, we demonstrate an efficient and accurate homodyne gradient extraction method for performing gradient descent on the loss function directly in the material system. We demonstrate the method in our recently developed dopant network processing units, where we readily realize all Boolean gates. This shows that gradient descent can in principle be fully implemented in materio using simple electronics, opening up the way to autonomously learning material systems.
Tractable Regularization of Probabilistic Circuits
Jun 04, 2021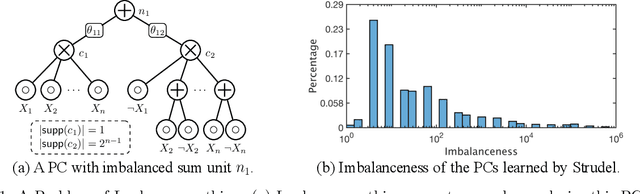

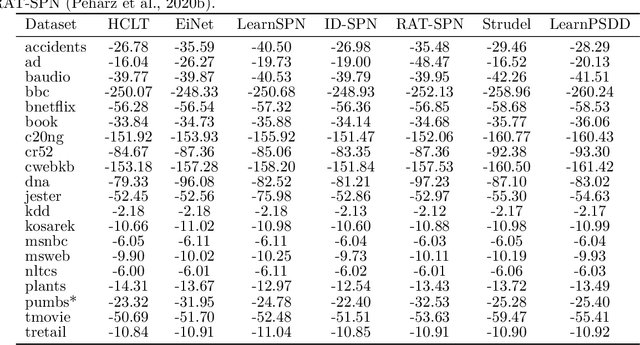
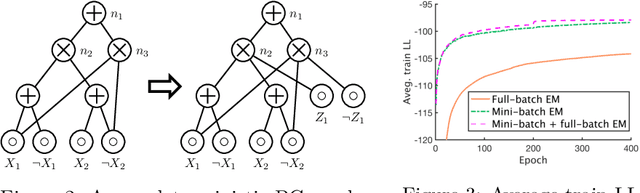
Probabilistic Circuits (PCs) are a promising avenue for probabilistic modeling. They combine advantages of probabilistic graphical models (PGMs) with those of neural networks (NNs). Crucially, however, they are tractable probabilistic models, supporting efficient and exact computation of many probabilistic inference queries, such as marginals and MAP. Further, since PCs are structured computation graphs, they can take advantage of deep-learning-style parameter updates, which greatly improves their scalability. However, this innovation also makes PCs prone to overfitting, which has been observed in many standard benchmarks. Despite the existence of abundant regularization techniques for both PGMs and NNs, they are not effective enough when applied to PCs. Instead, we re-think regularization for PCs and propose two intuitive techniques, data softening and entropy regularization, that both take advantage of PCs' tractability and still have an efficient implementation as a computation graph. Specifically, data softening provides a principled way to add uncertainty in datasets in closed form, which implicitly regularizes PC parameters. To learn parameters from a softened dataset, PCs only need linear time by virtue of their tractability. In entropy regularization, the exact entropy of the distribution encoded by a PC can be regularized directly, which is again infeasible for most other density estimation models. We show that both methods consistently improve the generalization performance of a wide variety of PCs. Moreover, when paired with a simple PC structure, we achieved state-of-the-art results on 10 out of 20 standard discrete density estimation benchmarks.
Correlation in Neuronal Calcium Spiking: Quantification based on Empirical Mutual Information Rate
May 07, 2021

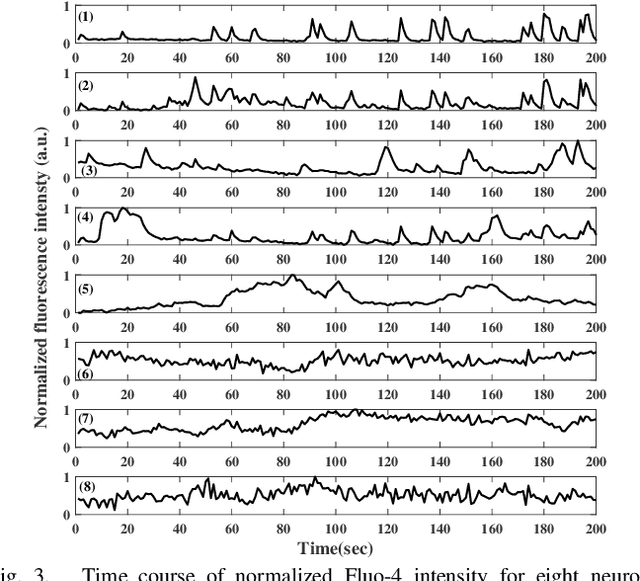

Quantification of neuronal correlations in neuron populations helps us to understand neural coding rules. Such quantification could also reveal how neurons encode information in normal and disease conditions like Alzheimer's and Parkinson's. While neurons communicate with each other by transmitting spikes, there would be a change in calcium concentration within the neurons inherently. Accordingly, there would be correlations in calcium spike trains and they could have heterogeneous memory structures. In this context, estimation of mutual information rate in calcium spike trains assumes primary significance. However, such estimation is difficult with available methods which would consider longer blocks for convergence without noticing that neuronal information changes in short time windows. Against this backdrop, we propose a faster method that exploits the memory structures in pair of calcium spike trains to quantify mutual information shared between them. Our method has shown superior performance with example Markov processes as well as experimental spike trains. Such mutual information rate analysis could be used to identify signatures of neuronal behavior in large populations in normal and abnormal conditions.
Increasing Energy Efficiency of Massive-MIMO Network via Base Stations Switching using Reinforcement Learning and Radio Environment Maps
Mar 08, 2021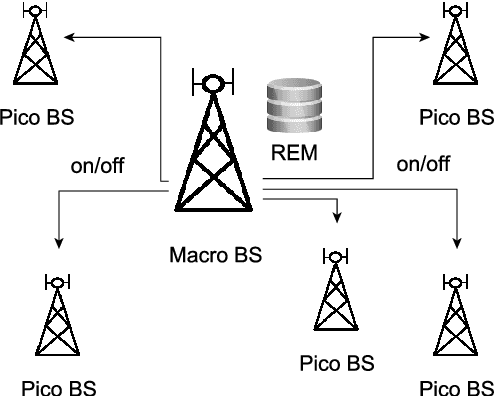
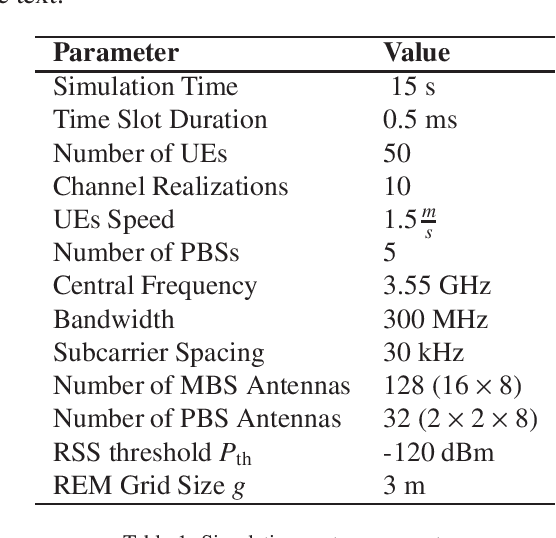
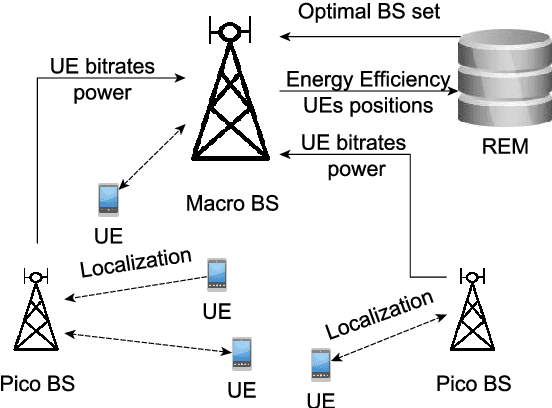
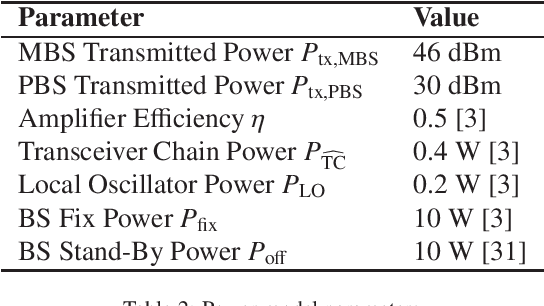
Energy Efficiency (EE) is of high importance while considering Massive Multiple-Input Multiple-Output (M-MIMO) networks where base stations (BSs) are equipped with an antenna array composed of up to hundreds of elements. M-MIMO transmission, although highly spectrally efficient, results in high energy consumption growing with the number of antennas. This paper investigates EE improvement through switching on/off underutilized BSs. It is proposed to use the location-aware approach, where data about an optimal active BSs set is stored in a Radio Environment Map (REM). For efficient acquisition, processing and utilization of the REM data, reinforcement learning (RL) algorithms are used. State-of-the-art exploration/exploitation methods including e-greedy, Upper Confidence Bound (UCB), and Gradient Bandit are evaluated. Then analytical action filtering, and an REM-based Exploration Algorithm (REM-EA) are proposed to improve the RL convergence time. Algorithms are evaluated using an advanced, system-level simulator of an M-MIMO Heterogeneous Network (HetNet) utilizing an accurate 3D-ray-tracing radio channel model. The proposed RL-based BSs switching algorithm is proven to provide 70% gains in EE over a state-of-the-art algorithm using an analytical heuristic. Moreover, the proposed action filtering and REM-EA can reduce RL convergence time in relation to the best-performing state-of-the-art exploration method by 60% and 83%, respectively.
Deep 3D-to-2D Watermarking: Embedding Messages in 3D Meshes and Extracting Them from 2D Renderings
Apr 29, 2021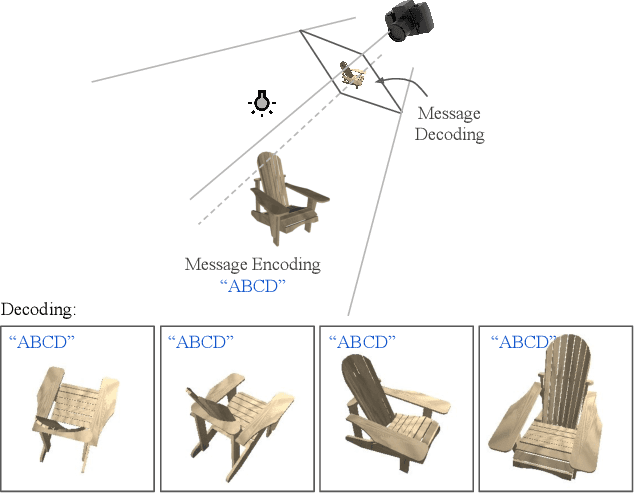
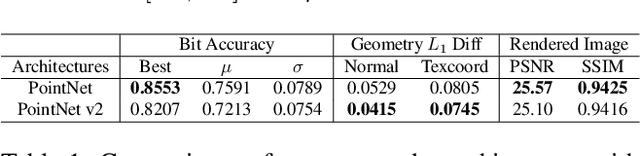
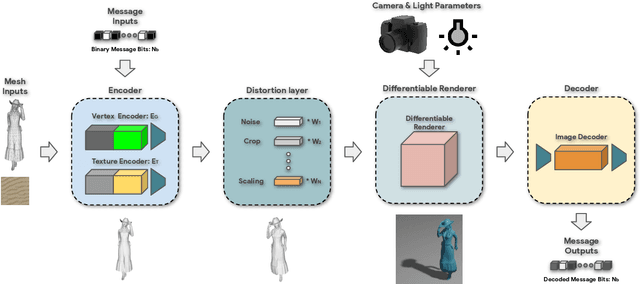

Digital watermarking is widely used for copyright protection. Traditional 3D watermarking approaches or commercial software are typically designed to embed messages into 3D meshes, and later retrieve the messages directly from distorted/undistorted watermarked 3D meshes. Retrieving messages from 2D renderings of such meshes, however, is still challenging and underexplored. We introduce a novel end-to-end learning framework to solve this problem through: 1) an encoder to covertly embed messages in both mesh geometry and textures; 2) a differentiable renderer to render watermarked 3D objects from different camera angles and under varied lighting conditions; 3) a decoder to recover the messages from 2D rendered images. From extensive experiments, we show that our models learn to embed information visually imperceptible to humans, and to reconstruct the embedded information from 2D renderings robust to 3D distortions. In addition, we demonstrate that our method can be generalized to work with different renderers, such as ray tracers and real-time renderers.
Make Bipedal Robots Learn How to Imitate
May 15, 2021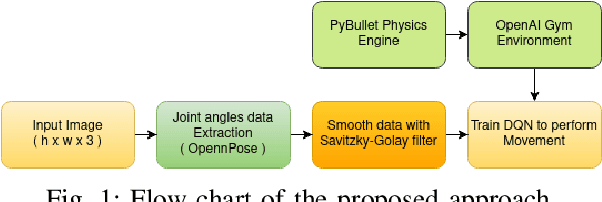
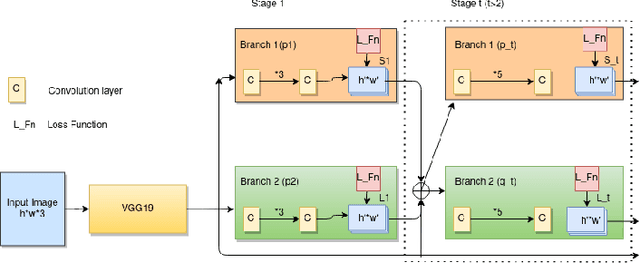

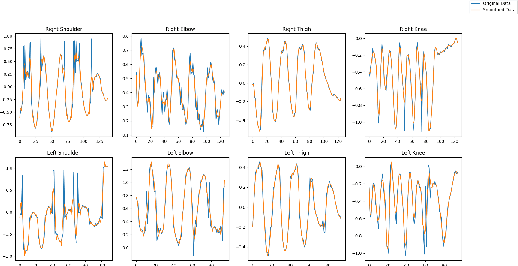
Bipedal robots do not perform well as humans since they do not learn to walk like we do. In this paper we propose a method to train a bipedal robot to perform some basic movements with the help of imitation learning (IL) in which an instructor will perform the movement and the robot will try to mimic the instructor movement. To the best of our knowledge, this is the first time we train the robot to perform movements with a single video of the instructor and as the training is done based on joint angles the robot will keep its joint angles always in physical limits which in return help in faster training. The joints of the robot are identified by OpenPose architecture and then joint angle data is extracted with the help of angle between three points resulting in a noisy solution. We smooth the data using Savitzky-Golay filter and preserve the Simulatore data anatomy. An ingeniously written Deep Q Network (DQN) is trained with experience replay to make the robot learn to perform the movements as similar as the instructor. The implementation of the paper is made publicly available.
Audio feature ranking for sound-based COVID-19 patient detection
Apr 14, 2021



Audio classification using breath and cough samples has recently emerged as a low-cost, non-invasive, and accessible COVID-19 screening method. However, no application has been approved for official use at the time of writing due to the stringent reliability and accuracy requirements of the critical healthcare setting. To support the development of the Machine Learning classification models, we performed an extensive comparative investigation and ranking of 15 audio features, including less well-known ones. The results were verified on two independent COVID-19 sound datasets. By using the identified top-performing features, we have increased the COVID-19 classification accuracy by up to 17% on the Cambridge dataset, and up to 10% on the Coswara dataset, compared to the original baseline accuracy without our feature ranking.
A contrastive rule for meta-learning
Apr 19, 2021


Meta-learning algorithms leverage regularities that are present on a set of tasks to speed up and improve the performance of a subsidiary learning process. Recent work on deep neural networks has shown that prior gradient-based learning of meta-parameters can greatly improve the efficiency of subsequent learning. Here, we present a biologically plausible meta-learning algorithm based on equilibrium propagation. Instead of explicitly differentiating the learning process, our contrastive meta-learning rule estimates meta-parameter gradients by executing the subsidiary process more than once. This avoids reversing the learning dynamics in time and computing second-order derivatives. In spite of this, and unlike previous first-order methods, our rule recovers an arbitrarily accurate meta-parameter update given enough compute. We establish theoretical bounds on its performance and present experiments on a set of standard benchmarks and neural network architectures.
COBRAS-TS: A new approach to Semi-Supervised Clustering of Time Series
May 02, 2018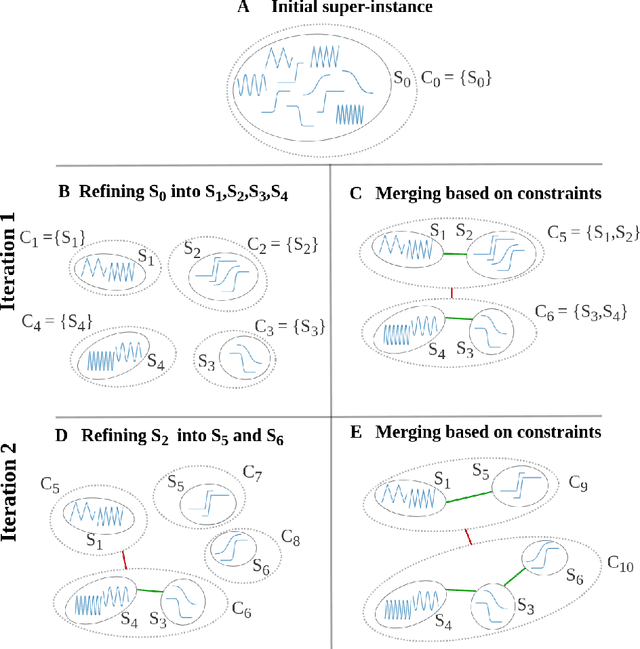
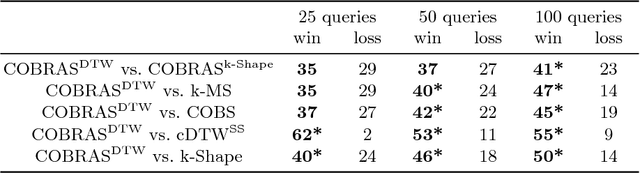
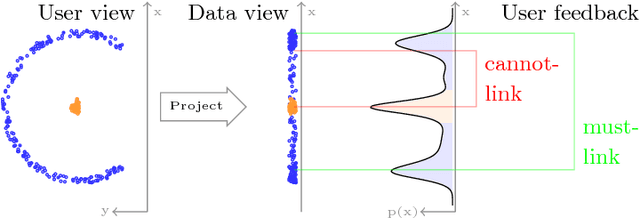
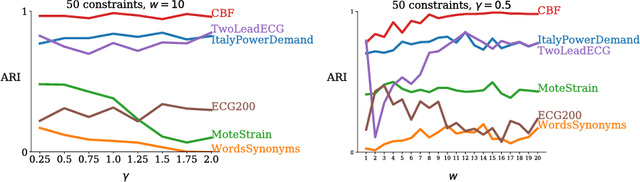
Clustering is ubiquitous in data analysis, including analysis of time series. It is inherently subjective: different users may prefer different clusterings for a particular dataset. Semi-supervised clustering addresses this by allowing the user to provide examples of instances that should (not) be in the same cluster. This paper studies semi-supervised clustering in the context of time series. We show that COBRAS, a state-of-the-art semi-supervised clustering method, can be adapted to this setting. We refer to this approach as COBRAS-TS. An extensive experimental evaluation supports the following claims: (1) COBRAS-TS far outperforms the current state of the art in semi-supervised clustering for time series, and thus presents a new baseline for the field; (2) COBRAS-TS can identify clusters with separated components; (3) COBRAS-TS can identify clusters that are characterized by small local patterns; (4) a small amount of semi-supervision can greatly improve clustering quality for time series; (5) the choice of the clustering algorithm matters (contrary to earlier claims in the literature).
Parameter-free Stochastic Optimization of Variationally Coherent Functions
Jan 30, 2021We design and analyze an algorithm for first-order stochastic optimization of a large class of functions on $\mathbb{R}^d$. In particular, we consider the \emph{variationally coherent} functions which can be convex or non-convex. The iterates of our algorithm on variationally coherent functions converge almost surely to the global minimizer $\boldsymbol{x}^*$. Additionally, the very same algorithm with the same hyperparameters, after $T$ iterations guarantees on convex functions that the expected suboptimality gap is bounded by $\widetilde{O}(\|\boldsymbol{x}^* - \boldsymbol{x}_0\| T^{-1/2+\epsilon})$ for any $\epsilon>0$. It is the first algorithm to achieve both these properties at the same time. Also, the rate for convex functions essentially matches the performance of parameter-free algorithms. Our algorithm is an instance of the Follow The Regularized Leader algorithm with the added twist of using \emph{rescaled gradients} and time-varying linearithmic regularizers.