 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Generalization Error Bound for Hyperbolic Ordinal Embedding
May 21, 2021
Hyperbolic ordinal embedding (HOE) represents entities as points in hyperbolic space so that they agree as well as possible with given constraints in the form of entity i is more similar to entity j than to entity k. It has been experimentally shown that HOE can obtain representations of hierarchical data such as a knowledge base and a citation network effectively, owing to hyperbolic space's exponential growth property. However, its theoretical analysis has been limited to ideal noiseless settings, and its generalization error in compensation for hyperbolic space's exponential representation ability has not been guaranteed. The difficulty is that existing generalization error bound derivations for ordinal embedding based on the Gramian matrix do not work in HOE, since hyperbolic space is not inner-product space. In this paper, through our novel characterization of HOE with decomposed Lorentz Gramian matrices, we provide a generalization error bound of HOE for the first time, which is at most exponential with respect to the embedding space's radius. Our comparison between the bounds of HOE and Euclidean ordinal embedding shows that HOE's generalization error is reasonable as a cost for its exponential representation ability.
Automated Detection of Abnormal EEGs in Epilepsy With a Compact and Efficient CNN Model
May 21, 2021

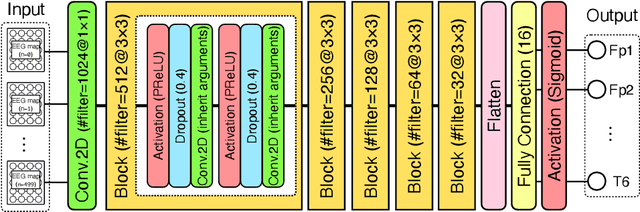
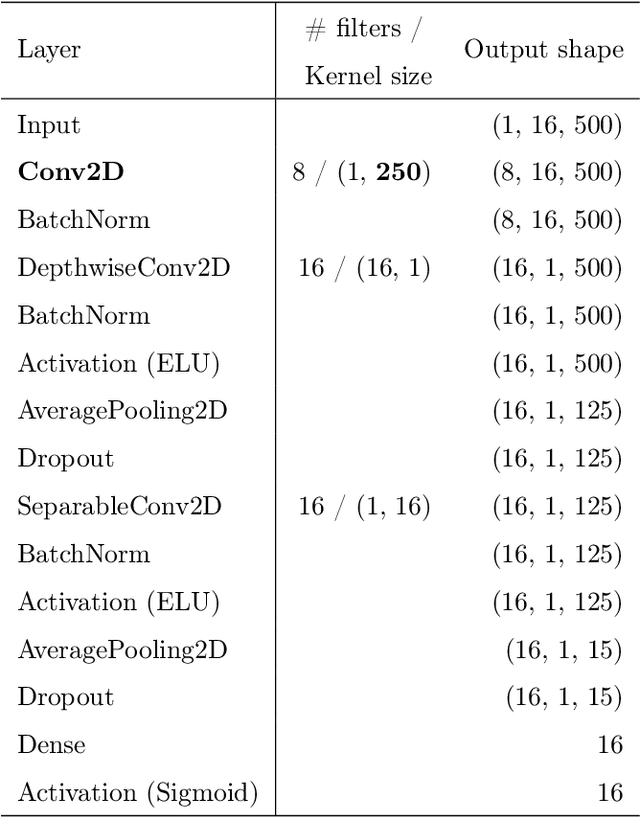
Electroencephalography (EEG) is essential for the diagnosis of epilepsy, but it requires expertise and experience to identify abnormalities. It is thus crucial to develop automated models for the detection of abnormal EEGs related to epilepsy. This paper describes the development of a novel class of compact and efficient convolutional neural networks (CNNs) for detecting abnormal time intervals and electrodes in EEGs for epilepsy. The designed model is inspired by a CNN developed for brain-computer interfacing called multichannel EEGNet (mEEGNet). Unlike the EEGNet, the proposed model, mEEGNet, has the same number of electrode inputs and outputs to detect abnormalities. The mEEGNet was evaluated with a clinical dataset consisting of 29 cases of juvenile and childhood absence epilepsy labeled by a clinical expert. The labels were given to paroxysmal discharges visually observed in both ictal (seizure) and interictal (nonseizure) intervals. Results showed that the mEEGNet detected abnormal EEGs with the area under the curve, F1-values, and sensitivity equivalent to or higher than those of existing CNNs. Moreover, the number of parameters is much smaller than other CNN models. To our knowledge, the dataset of absence epilepsy validated with machine learning through this research is the largest in the literature.
Brittle Features May Help Anomaly Detection
Apr 21, 2021
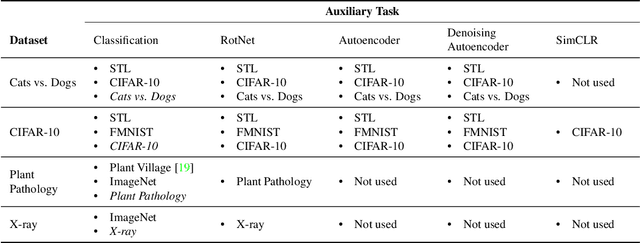
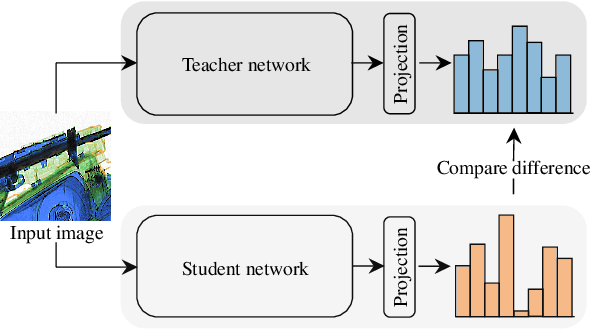
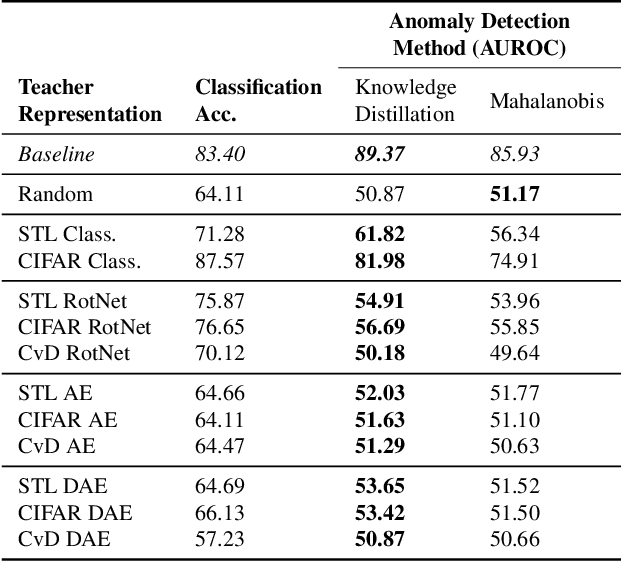
One-class anomaly detection is challenging. A representation that clearly distinguishes anomalies from normal data is ideal, but arriving at this representation is difficult since only normal data is available at training time. We examine the performance of representations, transferred from auxiliary tasks, for anomaly detection. Our results suggest that the choice of representation is more important than the anomaly detector used with these representations, although knowledge distillation can work better than using the representations directly. In addition, separability between anomalies and normal data is important but not the sole factor for a good representation, as anomaly detection performance is also correlated with more adversarially brittle features in the representation space. Finally, we show our configuration can detect 96.4% of anomalies in a genuine X-ray security dataset, outperforming previous results.
Multi-objective Optimisation of Digital Circuits based on Cell Mapping in an Industrial EDA Flow
May 21, 2021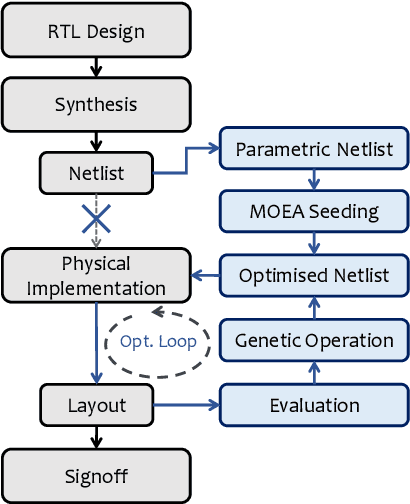
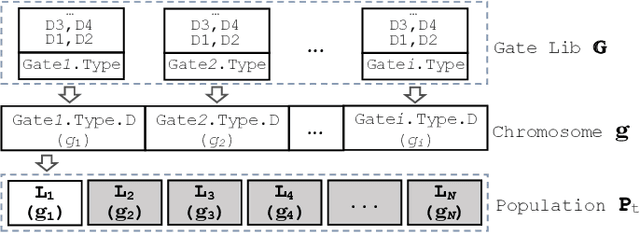
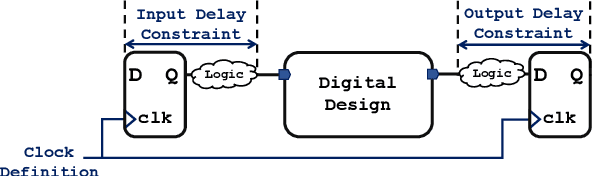
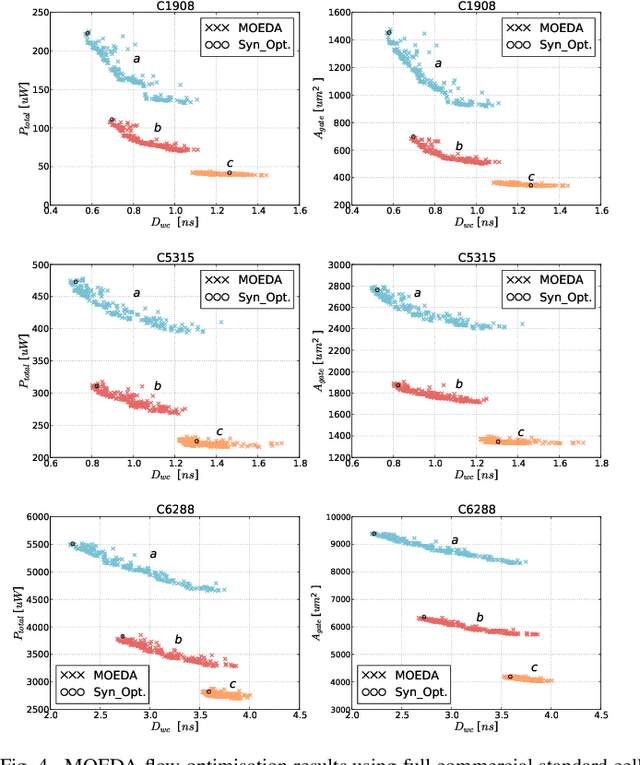
Modern electronic design automation (EDA) tools can handle the complexity of state-of-the-art electronic systems by decomposing them into smaller blocks or cells, introducing different levels of abstraction and staged design flows. However, throughout each independent-optimised design step, overhead and inefficiency can accumulate in the resulting overall design. Performing design-specific optimisation from a more global viewpoint requires more time due to the larger search space, but has the potential to provide solutions with improved performance. In this work, a fully-automated, multi-objective (MO) EDA flow is introduced to address this issue. It specifically tunes drive strength mapping, preceding physical implementation, through multi-objective population-based search algorithms. Designs are evaluated with respect to their power, performance and area (PPA). The proposed approach is capable of expanding the design space, offering a set of Pareto-optimised trade-off solutions for different case-specific utilisation. We have applied the proposed MOEDA framework to ISCAS-85 benchmark circuits using a commercial 65nm standard cell library. The experimental results demonstrate how the MOEDA flow enhances the solutions initially generated by the standard digital flow, and how simultaneously a significant improvement in PPA metrics is achieved.
Word-level Text Highlighting of Medical Texts forTelehealth Services
May 21, 2021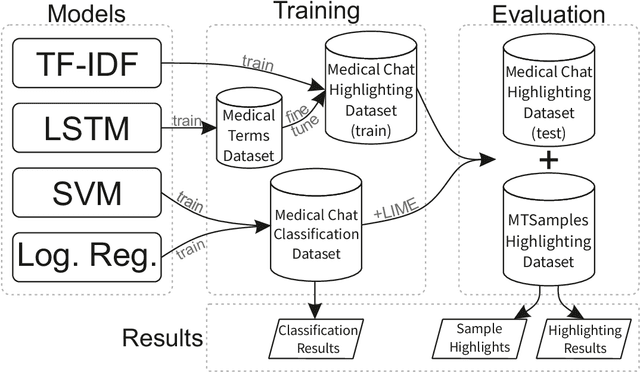
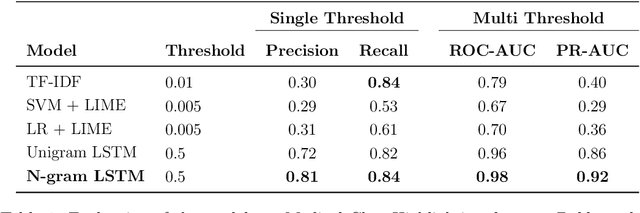

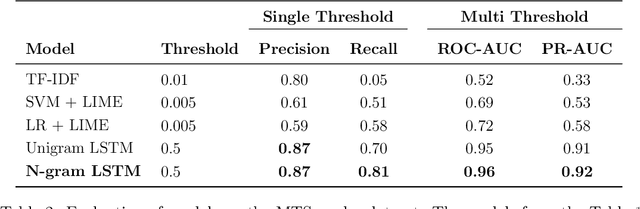
The medical domain is often subject to information overload. The digitization of healthcare, constant updates to online medical repositories, and increasing availability of biomedical datasets make it challenging to effectively analyze the data. This creates additional work for medical professionals who are heavily dependent on medical data to complete their research and consult their patients. This paper aims to show how different text highlighting techniques can capture relevant medical context. This would reduce the doctors' cognitive load and response time to patients by facilitating them in making faster decisions, thus improving the overall quality of online medical services. Three different word-level text highlighting methodologies are implemented and evaluated. The first method uses TF-IDF scores directly to highlight important parts of the text. The second method is a combination of TF-IDF scores and the application of Local Interpretable Model-Agnostic Explanations to classification models. The third method uses neural networks directly to make predictions on whether or not a word should be highlighted. The results of our experiments show that the neural network approach is successful in highlighting medically-relevant terms and its performance is improved as the size of the input segment increases.
Wasserstein distance estimates for the distributions of numerical approximations to ergodic stochastic differential equations
Apr 26, 2021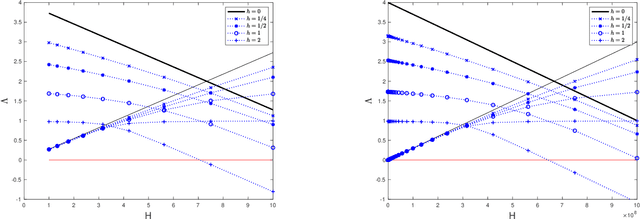
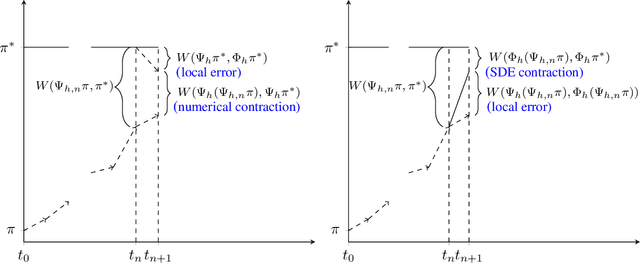
We present a framework that allows for the non-asymptotic study of the $2$-Wasserstein distance between the invariant distribution of an ergodic stochastic differential equation and the distribution of its numerical approximation in the strongly log-concave case. This allows us to study in a unified way a number of different integrators proposed in the literature for the overdamped and underdamped Langevin dynamics. In addition, we analyse a novel splitting method for the underdamped Langevin dynamics which only requires one gradient evaluation per time step. Under an additional smoothness assumption on a $d$--dimensional strongly log-concave distribution with condition number $\kappa$, the algorithm is shown to produce with an $\mathcal{O}\big(\kappa^{5/4} d^{1/4}\epsilon^{-1/2} \big)$ complexity samples from a distribution that, in Wasserstein distance, is at most $\epsilon>0$ away from the target distribution.
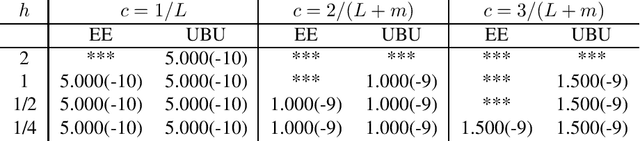
An Improved Online Penalty Parameter Selection Procedure for $\ell_1$-Penalized Autoregressive with Exogenous Variables
Oct 15, 2020
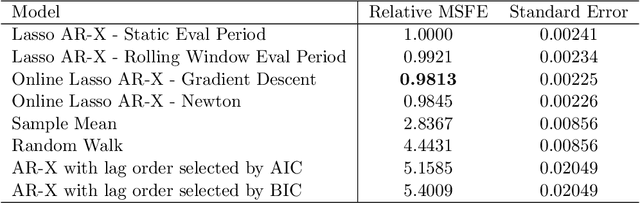


Many recent developments in the high-dimensional statistical time series literature have centered around time-dependent applications that can be adapted to regularized least squares. Of particular interest is the lasso, which both serves to regularize and provide feature selection. The lasso requires the specification of a penalty parameter that determines the degree of sparsity to impose. The most popular penalty parameter selection approaches that respect time dependence are very computationally intensive and are not appropriate for modeling certain classes of time series. We propose enhancing a canonical time series model, the autoregressive model with exogenous variables, with a novel online penalty parameter selection procedure that takes advantage of the sequential nature of time series data to improve both computational performance and forecast accuracy relative to existing methods in both a simulation and empirical application involving macroeconomic indicators.
A Novel Approach for Earthquake Early Warning System Design using Deep Learning Techniques
Jan 16, 2021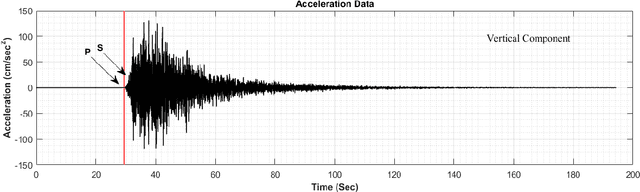
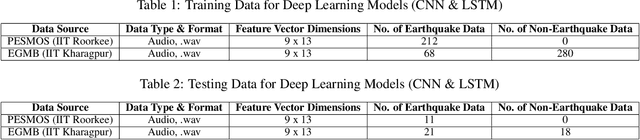
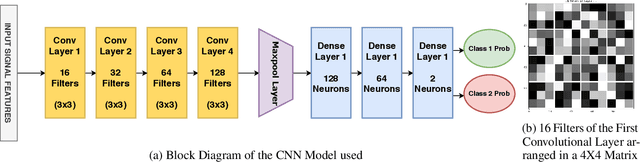
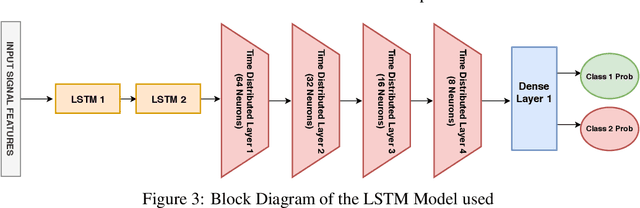
Earthquake signals are non-stationary in nature and thus in real-time, it is difficult to identify and classify events based on classical approaches like peak ground displacement, peak ground velocity. Even the popular algorithm of STA/LTA requires extensive research to determine basic thresholding parameters so as to trigger an alarm. Also, many times due to human error or other unavoidable natural factors such as thunder strikes or landslides, the algorithm may end up raising a false alarm. This work focuses on detecting earthquakes by converting seismograph recorded data into corresponding audio signals for better perception and then uses popular Speech Recognition techniques of Filter bank coefficients and Mel Frequency Cepstral Coefficients (MFCC) to extract the features. These features were then used to train a Convolutional Neural Network(CNN) and a Long Short Term Memory(LSTM) network. The proposed method can overcome the above-mentioned problems and help in detecting earthquakes automatically from the waveforms without much human intervention. For the 1000Hz audio data set the CNN model showed a testing accuracy of 91.1% for 0.2-second sample window length while the LSTM model showed 93.99% for the same. A total of 610 sounds consisting of 310 earthquake sounds and 300 non-earthquake sounds were used to train the models. While testing, the total time required for generating the alarm was approximately 2 seconds which included individual times for data collection, processing, and prediction taking into consideration the processing and prediction delays. This shows the effectiveness of the proposed method for Earthquake Early Warning (EEW) applications. Since the input of the method is only the waveform, it is suitable for real-time processing, thus the models can also be used as an onsite EEW system requiring a minimum amount of preparation time and workload.
Dynamic Sample Complexity for Exact Sparse Recovery using Sequential Iterative Hard Thresholding
Feb 28, 2021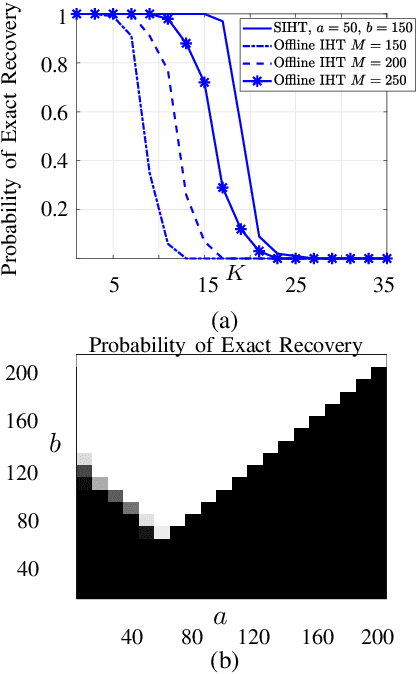
In this paper we consider the problem of exact recovery of a fixed sparse vector with the measurement matrices sequentially arriving along with corresponding measurements. We propose an extension of the iterative hard thresholding (IHT) algorithm, termed as sequential IHT (SIHT) which breaks the total time horizon into several phases such that IHT is executed in each of these phases using a fixed measurement matrix obtained at the beginning of that phase. We consider a stochastic setting where the measurement matrices obtained at each phase are independent samples of a sub Gaussian random matrix. We prove that if a certain dynamic sample complexity that depends on the sizes of the measurement matrices at each phase, along with their duration and the number of phases, satisfy certain lower bound, the estimation error of SIHT over a fixed time horizon decays rapidly. Interestingly, this bound reveals that the probability of decay of estimation error is hardly affected even if very small number measurements are sporadically used in different phases. This theoretical observation is also corroborated using numerical experiments demonstrating that SIHT enjoys improved probability of recovery compared to offline IHT.
Temp-Frustum Net: 3D Object Detection with Temporal Fusion
May 21, 2021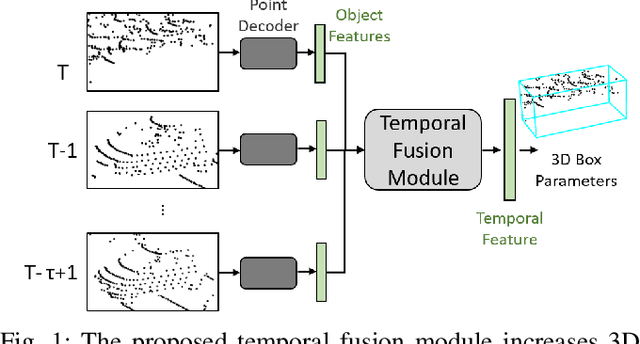
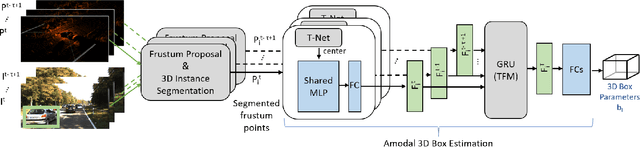


3D object detection is a core component of automated driving systems. State-of-the-art methods fuse RGB imagery and LiDAR point cloud data frame-by-frame for 3D bounding box regression. However, frame-by-frame 3D object detection suffers from noise, field-of-view obstruction, and sparsity. We propose a novel Temporal Fusion Module (TFM) to use information from previous time-steps to mitigate these problems. First, a state-of-the-art frustum network extracts point cloud features from raw RGB and LiDAR point cloud data frame-by-frame. Then, our TFM module fuses these features with a recurrent neural network. As a result, 3D object detection becomes robust against single frame failures and transient occlusions. Experiments on the KITTI object tracking dataset show the efficiency of the proposed TFM, where we obtain ~6%, ~4%, and ~6% improvements on Car, Pedestrian, and Cyclist classes, respectively, compared to frame-by-frame baselines. Furthermore, ablation studies reinforce that the subject of improvement is temporal fusion and show the effects of different placements of TFM in the object detection pipeline. Our code is open-source and available at https://github.com/emecercelik/Temp-Frustum-Net.git.