 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding the limitations of self-supervised learning for tabular anomaly detection
Oct 02, 2023While self-supervised learning has improved anomaly detection in computer vision and natural language processing, it is unclear whether tabular data can benefit from it. This paper explores the limitations of self-supervision for tabular anomaly detection. We conduct several experiments spanning various pretext tasks on 26 benchmark datasets to understand why this is the case. Our results confirm representations derived from self-supervision do not improve tabular anomaly detection performance compared to using the raw representations of the data. We show this is due to neural networks introducing irrelevant features, which reduces the effectiveness of anomaly detectors. However, we demonstrate that using a subspace of the neural network's representation can recover performance.
Warning: Humans Cannot Reliably Detect Speech Deepfakes
Jan 19, 2023



Speech deepfakes are artificial voices generated by machine learning models. Previous literature has highlighted deepfakes as one of the biggest threats to security arising from progress in AI due to their potential for misuse. However, studies investigating human detection capabilities are limited. We presented genuine and deepfake audio to $n$ = 529 individuals and asked them to identify the deepfakes. We ran our experiments in English and Mandarin to understand if language affects detection performance and decision-making rationale. Detection capability is unreliable. Listeners only correctly spotted the deepfakes 73% of the time, and there was no difference in detectability between the two languages. Increasing listener awareness by providing examples of speech deepfakes only improves results slightly. The difficulty of detecting speech deepfakes confirms their potential for misuse and signals that defenses against this threat are needed.
Self-Supervised Losses for One-Class Textual Anomaly Detection
Apr 12, 2022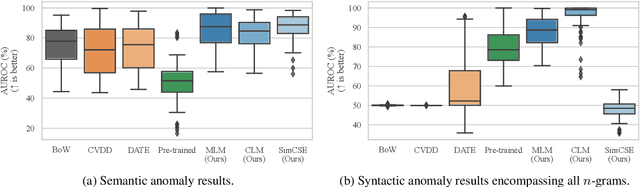
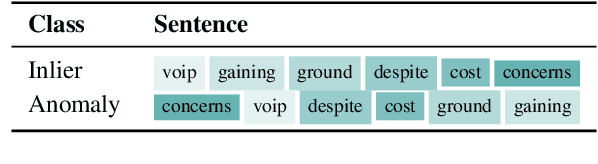
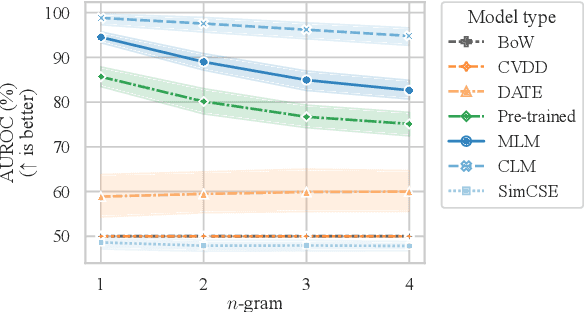
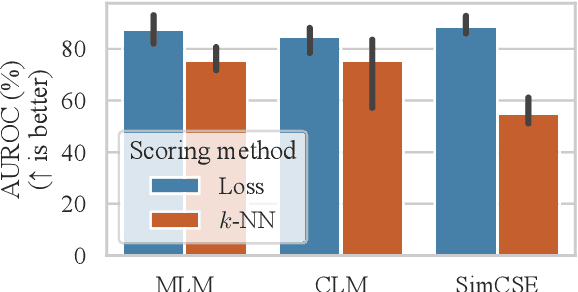
Current deep learning methods for anomaly detection in text rely on supervisory signals in inliers that may be unobtainable or bespoke architectures that are difficult to tune. We study a simpler alternative: fine-tuning Transformers on the inlier data with self-supervised objectives and using the losses as an anomaly score. Overall, the self-supervision approach outperforms other methods under various anomaly detection scenarios, improving the AUROC score on semantic anomalies by 11.6% and on syntactic anomalies by 22.8% on average. Additionally, the optimal objective and resultant learnt representation depend on the type of downstream anomaly. The separability of anomalies and inliers signals that a representation is more effective for detecting semantic anomalies, whilst the presence of narrow feature directions signals a representation that is effective for detecting syntactic anomalies.
Brittle Features May Help Anomaly Detection
Apr 21, 2021
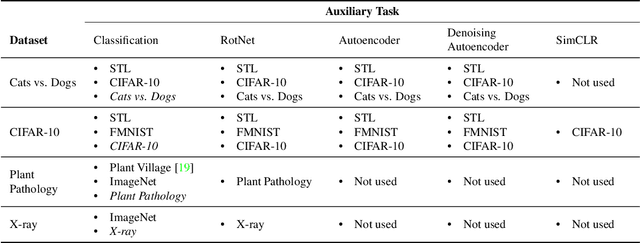
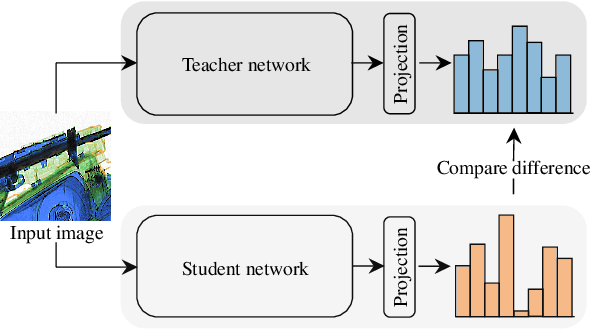
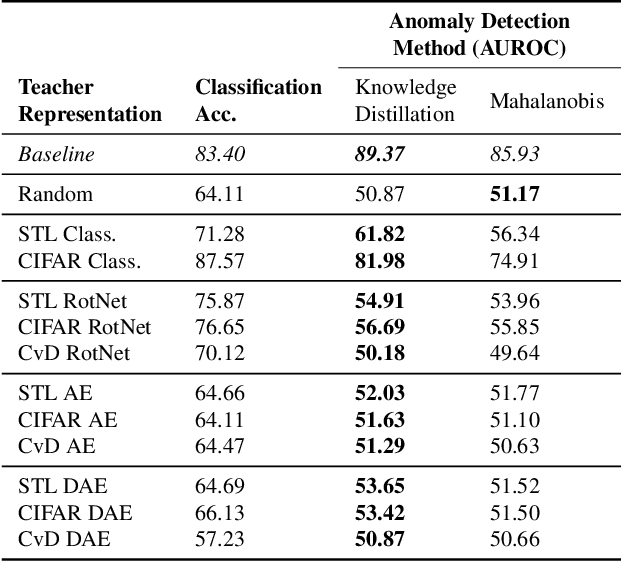
One-class anomaly detection is challenging. A representation that clearly distinguishes anomalies from normal data is ideal, but arriving at this representation is difficult since only normal data is available at training time. We examine the performance of representations, transferred from auxiliary tasks, for anomaly detection. Our results suggest that the choice of representation is more important than the anomaly detector used with these representations, although knowledge distillation can work better than using the representations directly. In addition, separability between anomalies and normal data is important but not the sole factor for a good representation, as anomaly detection performance is also correlated with more adversarially brittle features in the representation space. Finally, we show our configuration can detect 96.4% of anomalies in a genuine X-ray security dataset, outperforming previous results.