 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Computer Users Have Unique Yet Temporally Inconsistent Computer Usage Profiles
May 20, 2021
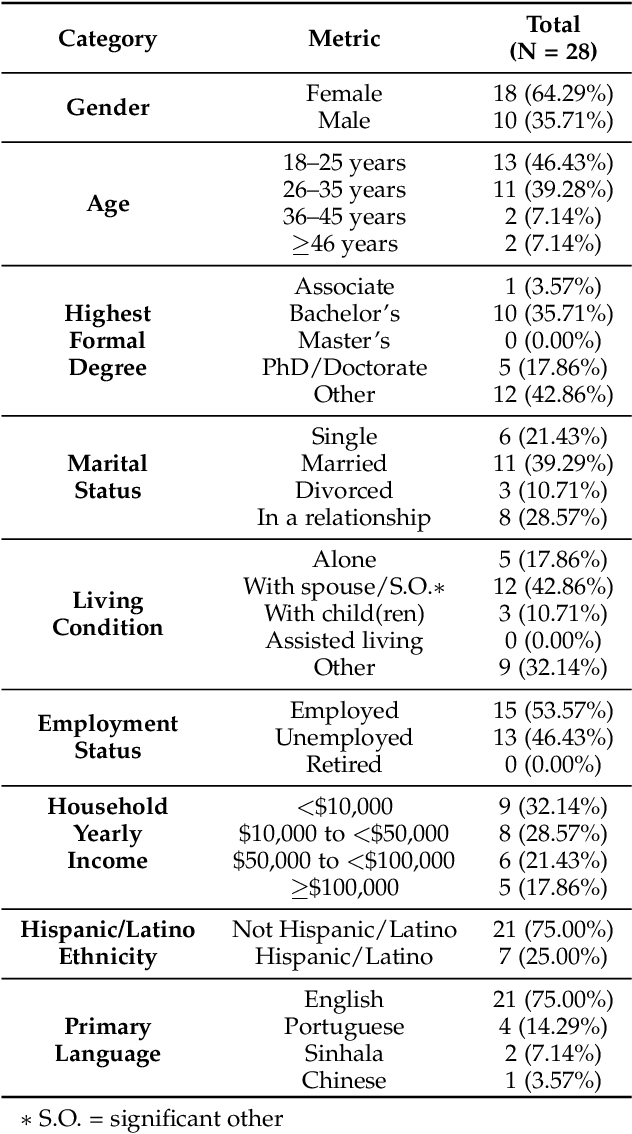
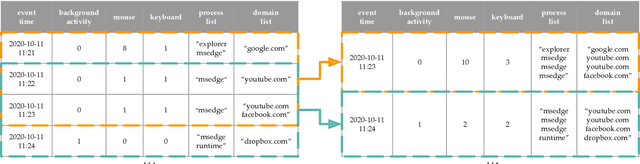
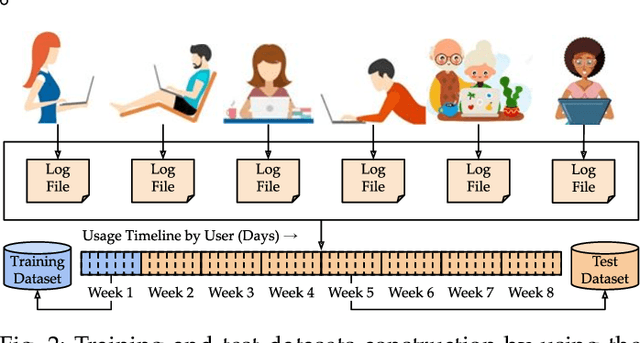
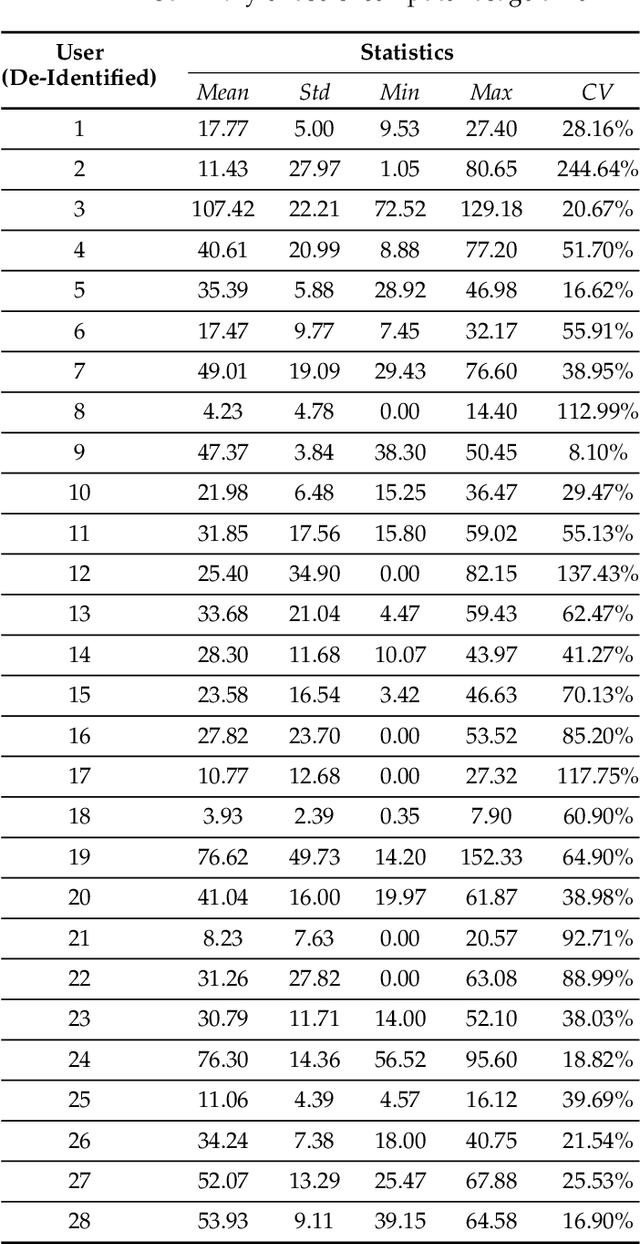
This paper investigates whether computer usage profiles comprised of process-, network-, mouse- and keystroke-related events are unique and temporally consistent in a naturalistic setting, discussing challenges and opportunities of using such profiles in applications of continuous authentication. We collected ecologically-valid computer usage profiles from 28 MS Windows 10 computer users over 8 weeks and submitted this data to comprehensive machine learning analysis involving a diverse set of online and offline classifiers. We found that (i) computer usage profiles have the potential to uniquely characterize computer users (with a maximum F-score of 99.94%); (ii) network-related events were the most useful features to properly recognize profiles (95.14% of the top features distinguishing users being network-related); (iii) user profiles were mostly inconsistent over the 8-week data collection period, with 92.86% of users exhibiting drifts in terms of time and usage habits; and (iv) online models are better suited to handle computer usage profiles compared to offline models (maximum F-score for each approach was 95.99% and 99.94%, respectively).
Real-Time Freespace Segmentation on Autonomous Robots for Detection of Obstacles and Drop-Offs
Feb 03, 2019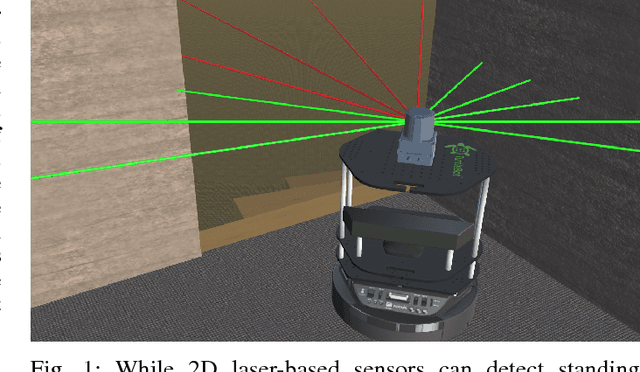


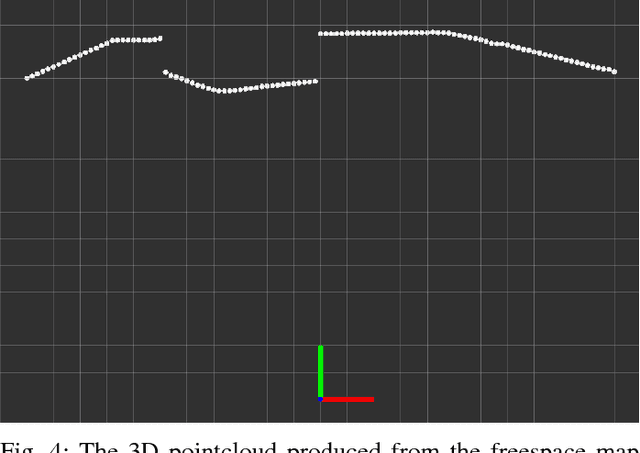
Mobile robots navigating in indoor and outdoor environments must be able to identify and avoid unsafe terrain. Although a significant amount of work has been done on the detection of standing obstacles (solid obstructions), not much work has been done on the detection of negative obstacles (e.g. dropoffs, ledges, downward stairs). We propose a method of terrain safety segmentation using deep convolutional networks. Our custom semantic segmentation architecture uses a single camera as input and creates a freespace map distinguishing safe terrain and obstacles. We then show how this freespace map can be used for real-time navigation on an indoor robot. The results show that our system generalizes well, is suitable for real-time operation, and runs at around 55 fps on a small indoor robot powered by a low-power embedded GPU.
Hypervector Design for Efficient Hyperdimensional Computing on Edge Devices
Mar 08, 2021
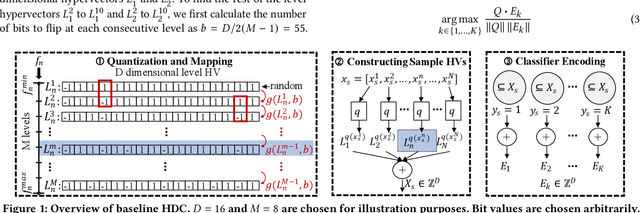
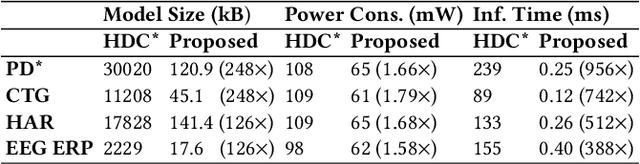
Hyperdimensional computing (HDC) has emerged as a new light-weight learning algorithm with smaller computation and energy requirements compared to conventional techniques. In HDC, data points are represented by high-dimensional vectors (hypervectors), which are mapped to high-dimensional space (hyperspace). Typically, a large hypervector dimension ($\geq1000$) is required to achieve accuracies comparable to conventional alternatives. However, unnecessarily large hypervectors increase hardware and energy costs, which can undermine their benefits. This paper presents a technique to minimize the hypervector dimension while maintaining the accuracy and improving the robustness of the classifier. To this end, we formulate the hypervector design as a multi-objective optimization problem for the first time in the literature. The proposed approach decreases the hypervector dimension by more than $32\times$ while maintaining or increasing the accuracy achieved by conventional HDC. Experiments on a commercial hardware platform show that the proposed approach achieves more than one order of magnitude reduction in model size, inference time, and energy consumption. We also demonstrate the trade-off between accuracy and robustness to noise and provide Pareto front solutions as a design parameter in our hypervector design.
End-to-End Deep Fault Tolerant Control
May 28, 2021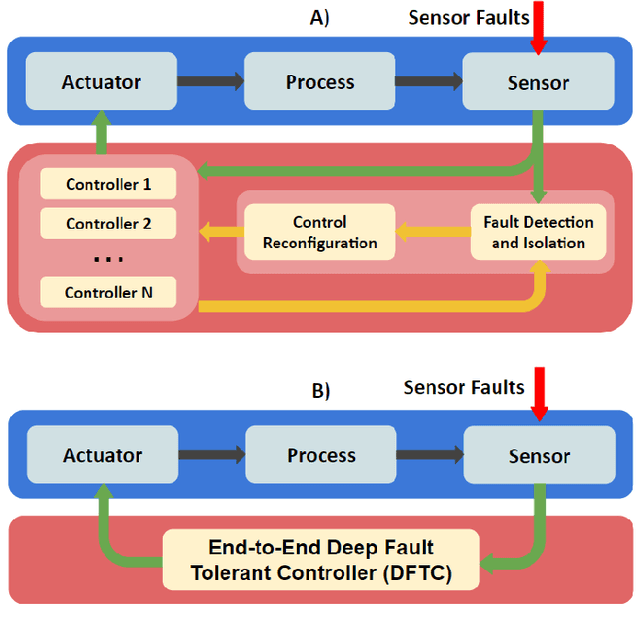
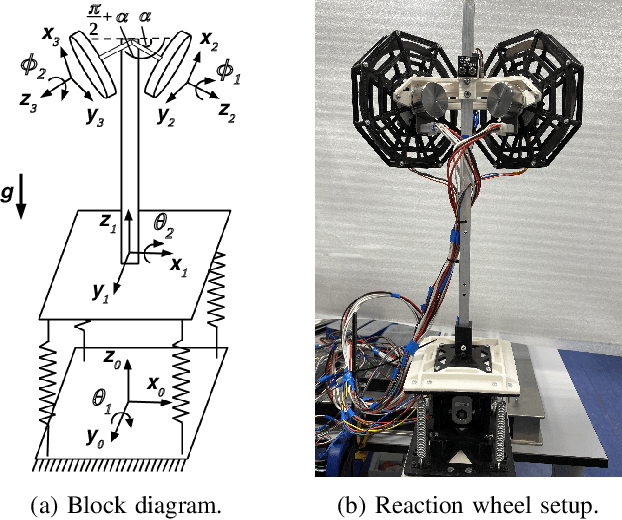
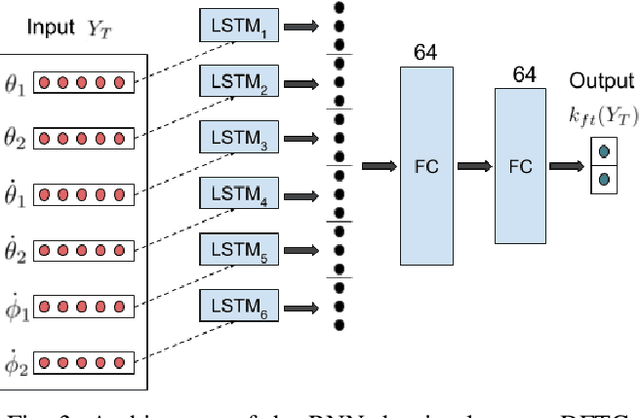
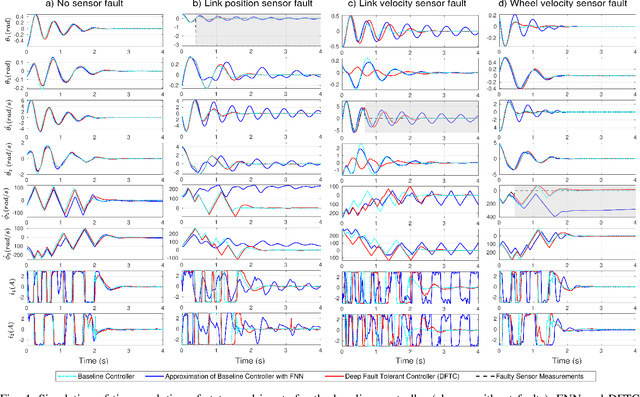
Ideally, accurate sensor measurements are needed to achieve a good performance in the closed-loop control of mechatronic systems. As a consequence, sensor faults will prevent the system from working correctly, unless a fault-tolerant control (FTC) architecture is adopted. As model-based FTC algorithms for nonlinear systems are often challenging to design, this paper focuses on a new method for FTC in the presence of sensor faults, based on deep learning. The considered approach replaces the phases of fault detection and isolation and controller design with a single recurrent neural network, which has the value of past sensor measurements in a given time window as input, and the current values of the control variables as output. This end-to-end deep FTC method is applied to a mechatronic system composed of a spherical inverted pendulum, whose configuration is changed via reaction wheels, in turn actuated by electric motors. The simulation and experimental results show that the proposed method can handle abrupt faults occurring in link position/velocity sensors. The provided supplementary material includes a video of real-world experiments and the software source code.
Improving Lexically Constrained Neural Machine Translation with Source-Conditioned Masked Span Prediction
May 12, 2021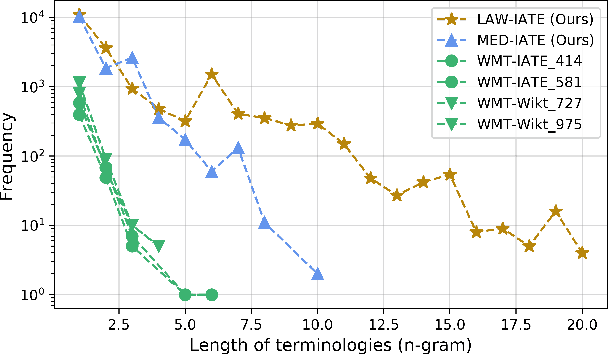
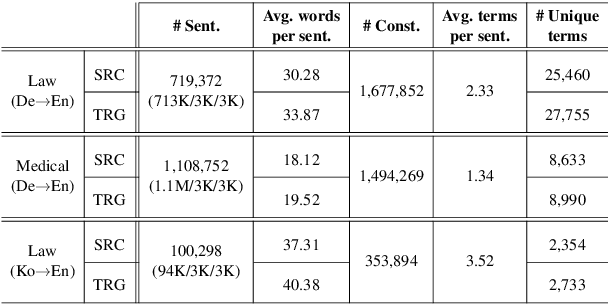
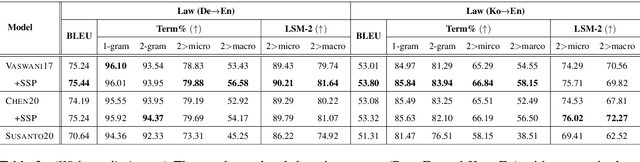

Generating accurate terminology is a crucial component for the practicality and reliability of neural machine translation (NMT) systems. To address this, lexically constrained NMT explores various methods to ensure pre-specified words and phrases to appear in the translations. In many cases, however, those methods are evaluated on general domain corpora, where the terms are mostly uni- and bi-grams (>98%). In this paper, we instead tackle a more challenging setup consisting of domain-specific corpora with much longer n-gram and highly specialized terms. To encourage span-level representations in generation, we additionally impose a source-sentence conditioned masked span prediction loss in the decoder and observe improvements on both terminology translation as well as BLEU scores. Experimental results on three domain-specific corpora in two language pairs demonstrate that the proposed training scheme can improve the performance of existing lexically constrained methods that can operate both with or without a term dictionary at test time.
Analyzing Non-Textual Content Elements to Detect Academic Plagiarism
Jun 10, 2021Identifying academic plagiarism is a pressing problem, among others, for research institutions, publishers, and funding organizations. Detection approaches proposed so far analyze lexical, syntactical, and semantic text similarity. These approaches find copied, moderately reworded, and literally translated text. However, reliably detecting disguised plagiarism, such as strong paraphrases, sense-for-sense translations, and the reuse of non-textual content and ideas, is an open research problem. The thesis addresses this problem by proposing plagiarism detection approaches that implement a different concept: analyzing non-textual content in academic documents, specifically citations, images, and mathematical content. To validate the effectiveness of the proposed detection approaches, the thesis presents five evaluations that use real cases of academic plagiarism and exploratory searches for unknown cases. The evaluation results show that non-textual content elements contain a high degree of semantic information, are language-independent, and largely immutable to the alterations that authors typically perform to conceal plagiarism. Analyzing non-textual content complements text-based detection approaches and increases the detection effectiveness, particularly for disguised forms of academic plagiarism. To demonstrate the benefit of combining non-textual and text-based detection methods, the thesis describes the first plagiarism detection system that integrates the analysis of citation-based, image-based, math-based, and text-based document similarity. The system's user interface employs visualizations that significantly reduce the effort and time users must invest in examining content similarity.
Symplectic Adjoint Method for Exact Gradient of Neural ODE with Minimal Memory
Feb 19, 2021
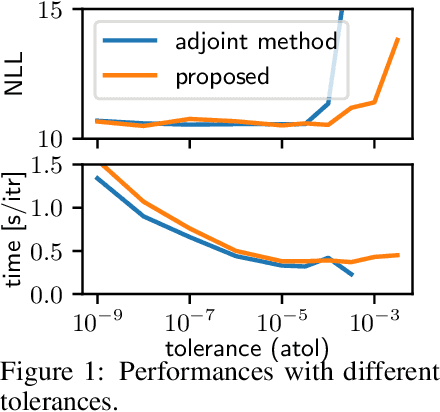
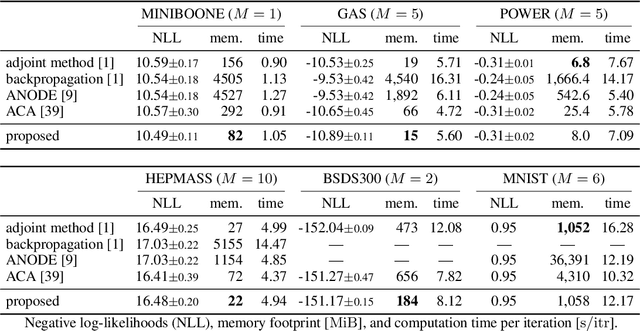
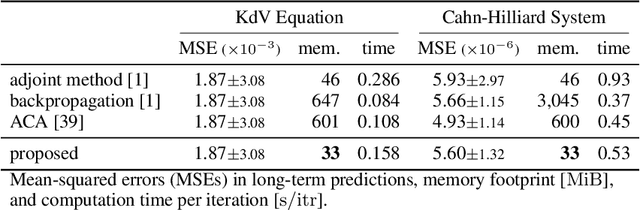
A neural network model of a differential equation, namely neural ODE, has enabled us to learn continuous-time dynamical systems and probabilistic distributions with a high accuracy. It uses the same network repeatedly during a numerical integration. Hence, the backpropagation algorithm requires a memory footprint proportional to the number of uses times the network size. This is true even if a checkpointing scheme divides the computational graph into sub-graphs. Otherwise, the adjoint method obtains a gradient by a numerical integration backward in time with a minimal memory footprint; however, it suffers from numerical errors. This study proposes the symplectic adjoint method, which obtains the exact gradient (up to rounding error) with a footprint proportional to the number of uses plus the network size. The experimental results demonstrate the symplectic adjoint method occupies the smallest footprint in most cases, functions faster in some cases, and is robust to a rounding error among competitive methods.
An efficient projection neural network for $\ell_1$-regularized logistic regression
May 12, 2021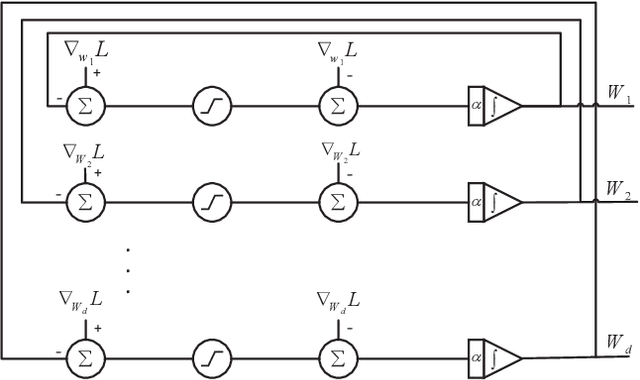
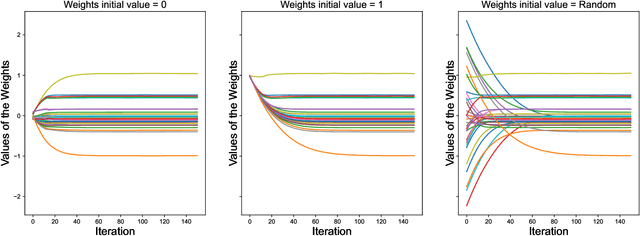
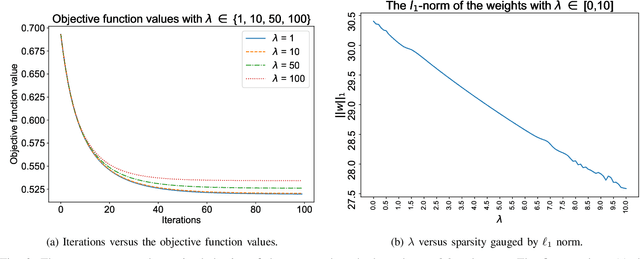
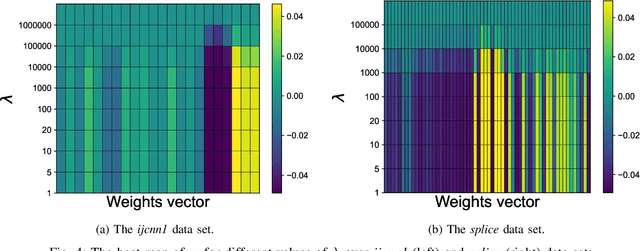
$\ell_1$ regularization has been used for logistic regression to circumvent the overfitting and use the estimated sparse coefficient for feature selection. However, the challenge of such a regularization is that the $\ell_1$ norm is not differentiable, making the standard algorithms for convex optimization not applicable to this problem. This paper presents a simple projection neural network for $\ell_1$-regularized logistics regression. In contrast to many available solvers in the literature, the proposed neural network does not require any extra auxiliary variable nor any smooth approximation, and its complexity is almost identical to that of the gradient descent for logistic regression without $\ell_1$ regularization, thanks to the projection operator. We also investigate the convergence of the proposed neural network by using the Lyapunov theory and show that it converges to a solution of the problem with any arbitrary initial value. The proposed neural solution significantly outperforms state-of-the-art methods with respect to the execution time and is competitive in terms of accuracy and AUROC.
Efficient Riccati recursion for optimal control problems with pure-state equality constraints
Feb 19, 2021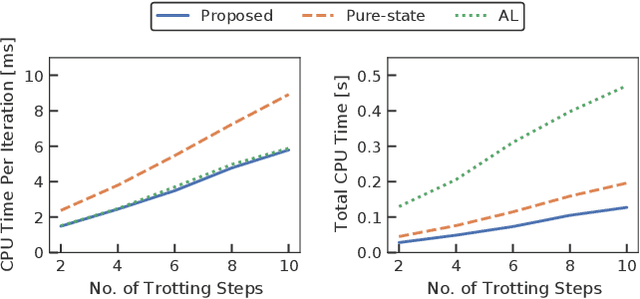
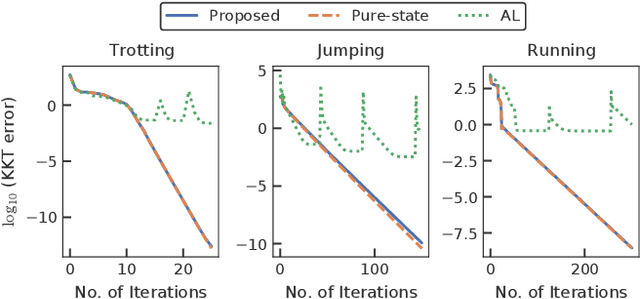
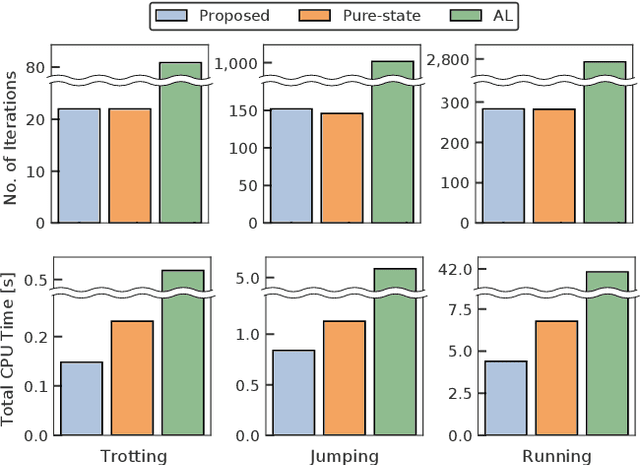
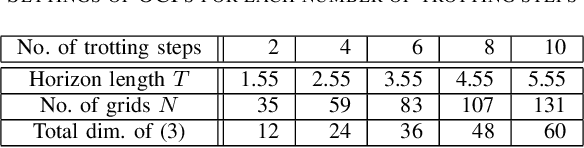
A novel approach to efficiently treat pure-state equality constraints in optimal control problems (OCPs) using a Riccati recursion algorithm is proposed. The proposed method transforms a pure-state equality constraint into a mixed state-control constraint such that the constraint is expressed by variables at a certain previous time stage. It is showed that if the solution satisfies the second-order sufficient conditions of the OCP with the transformed mixed state-control constraints, it is a local minimum of the OCP with the original pure-state constraints. A Riccati recursion algorithm is derived to solve the OCP using the transformed constraints with linear time complexity in the grid number of the horizon, in contrast to a previous approach that scales cubically with respect to the total dimension of the pure-state equality constraints. Numerical experiments on the whole-body optimal control of quadrupedal gaits that involve pure-state equality constraints owing to contact switches demonstrate the effectiveness of the proposed method over existing approaches.
Spatiotemporal Spike-Pattern Selectivity in Single Mixed-Signal Neurons with Balanced Synapses
Jun 10, 2021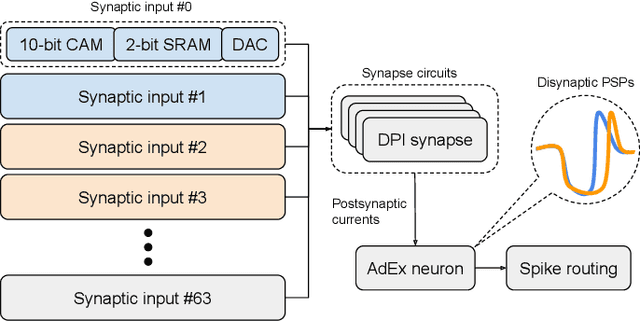
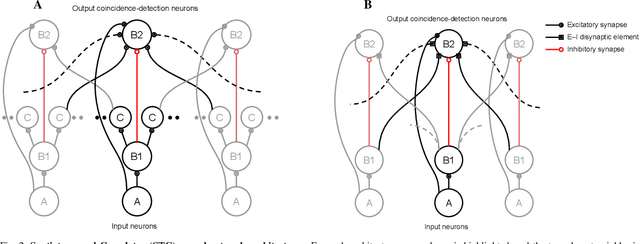
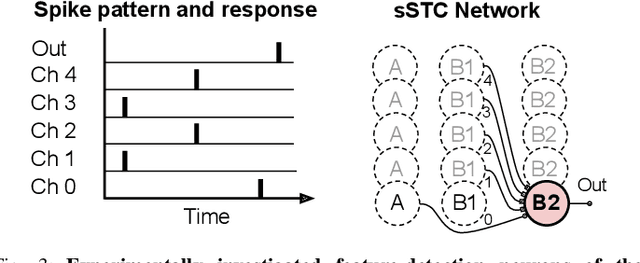
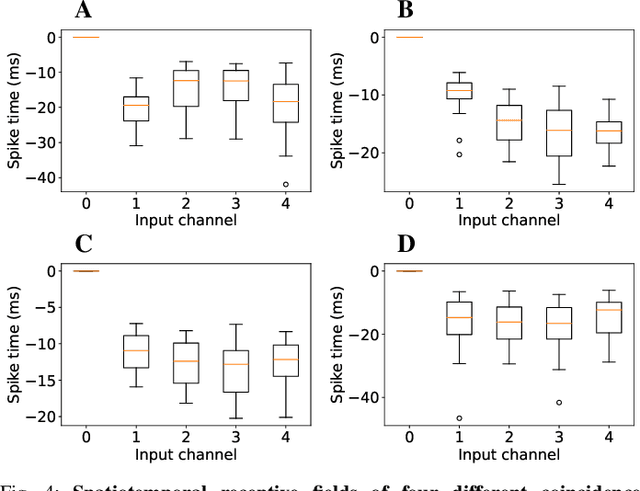
Realizing the potential of mixed-signal neuromorphic processors for ultra-low-power inference and learning requires efficient use of their inhomogeneous analog circuitry as well as sparse, time-based information encoding and processing. Here, we investigate spike-timing-based spatiotemporal receptive fields of output-neurons in the Spatiotemporal Correlator (STC) network, for which we used excitatory-inhibitory balanced disynaptic inputs instead of dedicated axonal or neuronal delays. We present hardware-in-the-loop experiments with a mixed-signal DYNAP-SE neuromorphic processor, in which five-dimensional receptive fields of hardware neurons were mapped by randomly sampling input spike-patterns from a uniform distribution. We find that, when the balanced disynaptic elements are randomly programmed, some of the neurons display distinct receptive fields. Furthermore, we demonstrate how a neuron was tuned to detect a particular spatiotemporal feature, to which it initially was non-selective, by activating a different subset of the inhomogeneous analog synaptic circuits. The energy dissipation of the balanced synaptic elements is one order of magnitude lower per lateral connection (0.65 nJ vs 9.3 nJ per spike) than former delay-based neuromorphic hardware implementations. Thus, we show how the inhomogeneous synaptic circuits could be utilized for resource-efficient implementation of STC network layers, in a way that enables synapse-address reprogramming as a discrete mechanism for feature tuning.