 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
WHO-Hand Hygiene Gesture Classification System
Oct 06, 2021
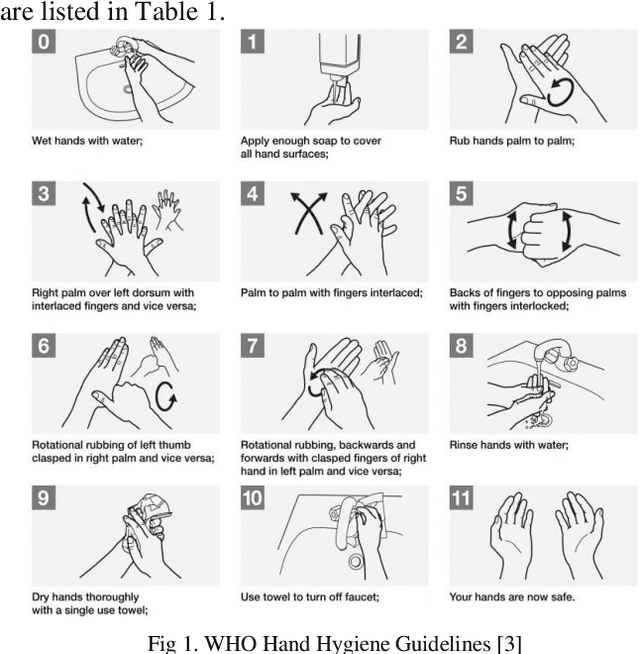
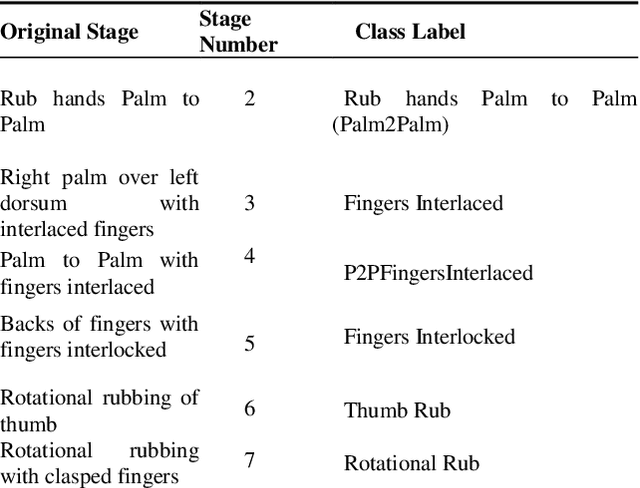

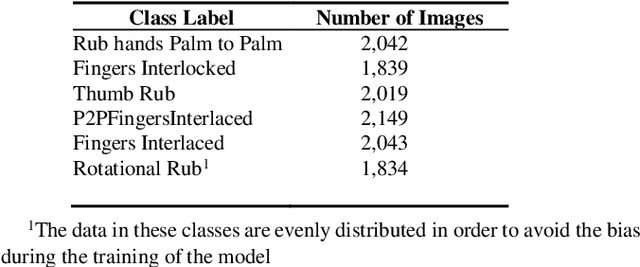
The recent ongoing coronavirus pandemic highlights the importance of hand hygiene practices in our daily lives, with governments and worldwide health authorities promoting good hand hygiene practices. More than one million cases of hospital-acquired infections occur in Europe annually. Hand hygiene compliance may reduce the risk of transmission by reducing the number of infections as well as healthcare expenditures. In this paper, the World Health Organization, hand hygiene gestures are recorded and analyzed with the construction of an aluminum frame, placed at the laboratory sink. The hand hygiene gestures are recorded for thirty participants after conducting a training session about hand hygiene gestures demonstration. The video recordings are converted into image files and are organized into six different hand hygiene classes. The Resnet50 framework selection for the classification of multiclass hand hygiene stages. The model is trained with the first set of classes; Fingers Interlaced, P2PFingers Interlaced, and Rotational Rub for 25 epochs. An accuracy of 44 percent for the first set of experiments with a loss score greater than 1.5 in the validation set is achieved. The training steps for the second set of classes; Rub hands palm to palm, Fingers Interlocked, Thumb Rub are 50 epochs. An accuracy of 72 percent is achieved for the second set with a loss score of less than 0.8 for the validation set. In this work, a preliminary analysis of a robust hand hygiene dataset with transfer learning takes place. The future aim for deploying a hand hygiene prediction system for healthcare workers in real-time.
Aggregate Learning for Mixed Frequency Data
May 20, 2021
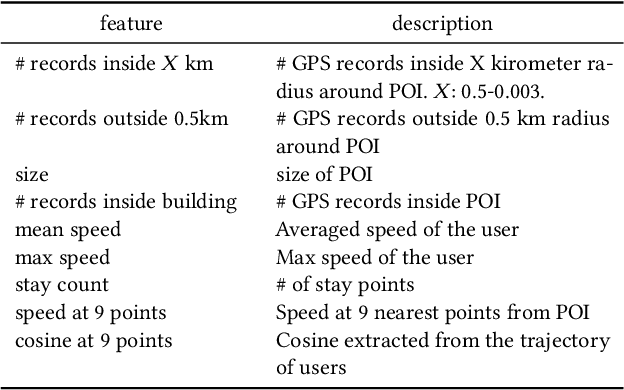
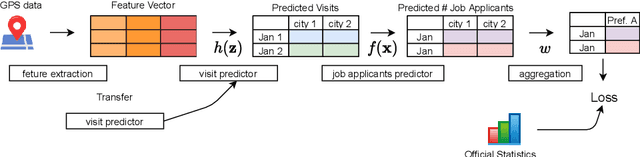
Large and acute economic shocks such as the 2007-2009 financial crisis and the current COVID-19 infections rapidly change the economic environment. In such a situation, the importance of real-time economic analysis using alternative datais emerging. Alternative data such as search query and location data are closer to real-time and richer than official statistics that are typically released once a month in an aggregated form. We take advantage of spatio-temporal granularity of alternative data and propose a mixed-FrequencyAggregate Learning (MF-AGL)model that predicts economic indicators for the smaller areas in real-time. We apply the model for the real-world problem; prediction of the number of job applicants which is closely related to the unemployment rates. We find that the proposed model predicts (i) the regional heterogeneity of the labor market condition and (ii) the rapidly changing economic status. The model can be applied to various tasks, especially economic analysis
Social Media Monitoring for IoT Cyber-Threats
Sep 09, 2021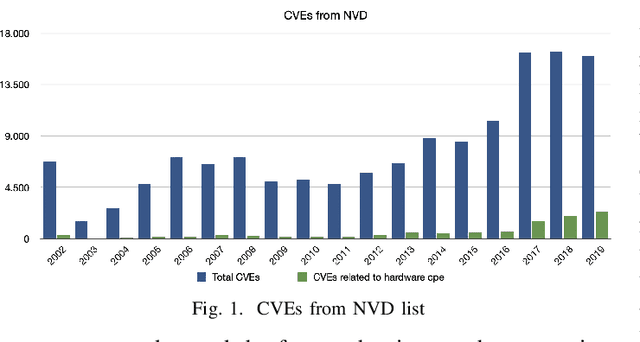
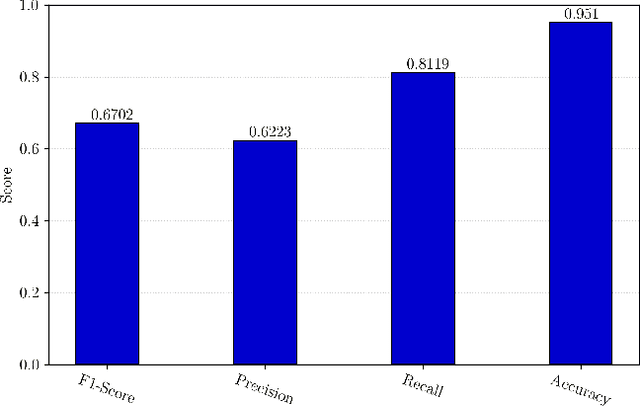


The rapid development of IoT applications and their use in various fields of everyday life has resulted in an escalated number of different possible cyber-threats, and has consequently raised the need of securing IoT devices. Collecting Cyber-Threat Intelligence (e.g., zero-day vulnerabilities or trending exploits) from various online sources and utilizing it to proactively secure IoT systems or prepare mitigation scenarios has proven to be a promising direction. In this work, we focus on social media monitoring and investigate real-time Cyber-Threat Intelligence detection from the Twitter stream. Initially, we compare and extensively evaluate six different machine-learning based classification alternatives trained with vulnerability descriptions and tested with real-world data from the Twitter stream to identify the best-fitting solution. Subsequently, based on our findings, we propose a novel social media monitoring system tailored to the IoT domain; the system allows users to identify recent/trending vulnerabilities and exploits on IoT devices. Finally, to aid research on the field and support the reproducibility of our results we publicly release all annotated datasets created during this process.
* 6 pages, 2 figures
A new CP-approach for a parallel machine scheduling problem with time constraints on machine qualifications
Oct 16, 2019


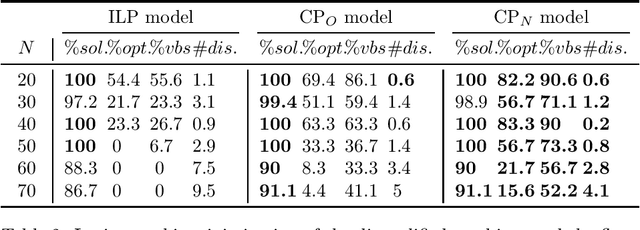
This paper considers the scheduling of job families on parallel machines with time constraints on machine qualifications. In this problem, each job belongs to a family and a family can only be executed on a subset of qualified machines. In addition, machines can lose their qualifications during the schedule. Indeed, if no job of a family is scheduled on a machine during a given amount of time, the machine loses its qualification for this family. The goal is to minimize the sum of job completion times, i.e. the flow time, while maximizing the number of qualifications at the end of the schedule. The paper presents a new Constraint Programming (CP) model taking more advantages of the CP feature to model machine disqualifications. This model is compared with two existing models: an Integer Linear Programming (ILP) model and a Constraint Programming model. The experiments show that the new CP model outperforms the other model when the priority is given to the number of disqualifications objective. Furthermore, it is competitive with the other model when the flow time objective is prioritized.
An objective function for order preserving hierarchical clustering
Sep 09, 2021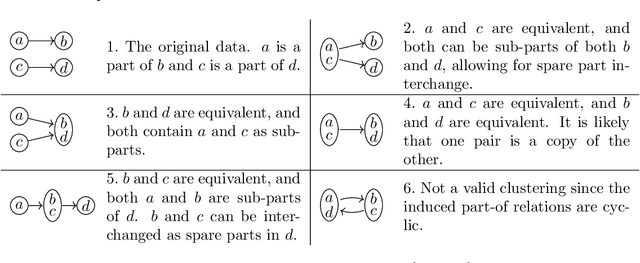
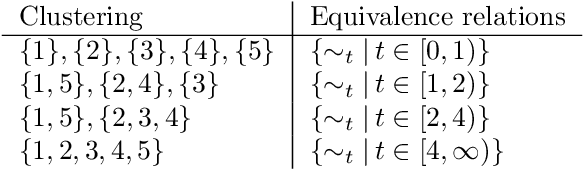
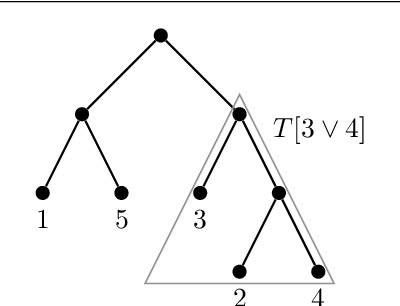
We present an objective function for similarity based hierarchical clustering of partially ordered data that preserves the partial order in the sense that if $x \leq y$, and if $[x]$ and $[y]$ are the respective clusters of $x$ and $y$, then there is an order relation $\leq'$ on the clusters for which $[x] \leq' |y]$. The model distinguishes itself from existing methods and models for clustering of ordered data in that the order relation and the similarity are combined to obtain an optimal hierarchical clustering seeking to satisfy both, and that the order relation is equipped with a pairwise level of comparability in the range $[0,1]$. In particular, if the similarity and the order relation are not aligned, then order preservation may have to yield in favor of clustering. Finding an optimal solution is NP-hard, so we provide a polynomial time approximation algorithm, with a relative performance guarantee of $O(\log^{3/2}n)$, based on successive applications of directed sparsest cut. The model is an extension of the Dasgupta cost function for divisive hierarchical clustering.
Seeker: Real-Time Interactive Search
May 17, 2019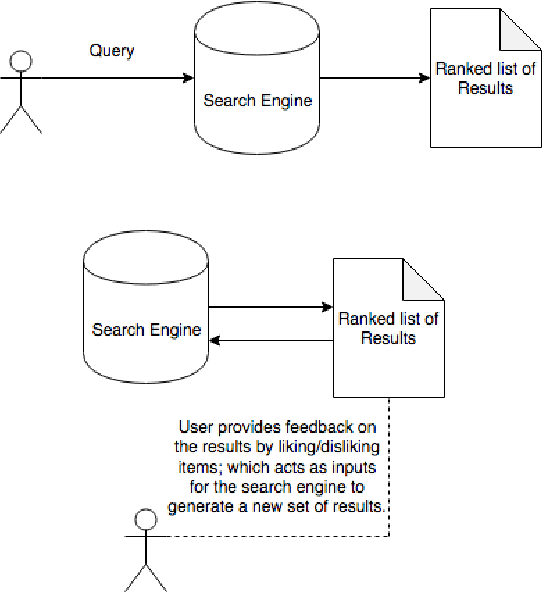
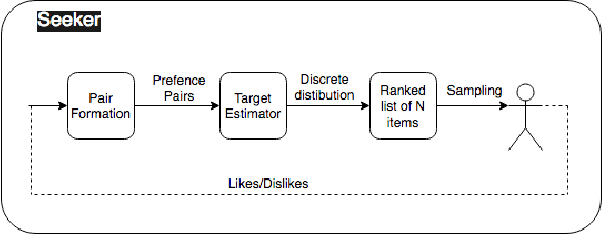

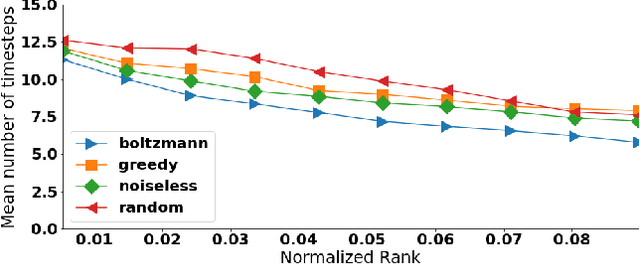
This paper introduces Seeker, a system that allows users to interactively refine search rankings in real time, through feedback in the form of likes and dislikes. When searching online, users may not know how to accurately describe their product of choice in words. An alternative approach is to search an embedding space, allowing the user to query using a representation of the item (like a tune for a song, or a picture for an object). However, this approach requires the user to possess an example representation of their desired item. Additionally, most current search systems do not allow the user to dynamically adapt the results with further feedback. On the other hand, users often have a mental picture of the desired item and are able to answer ordinal questions of the form: "Is this item similar to what you have in mind?" With this assumption, our algorithm allows for users to provide sequential feedback on search results to adapt the search feed. We show that our proposed approach works well both qualitatively and quantitatively. Unlike most previous representation-based search systems, we can quantify the quality of our algorithm by evaluating humans-in-the-loop experiments.
CounterNet: End-to-End Training of Counterfactual Aware Predictions
Sep 15, 2021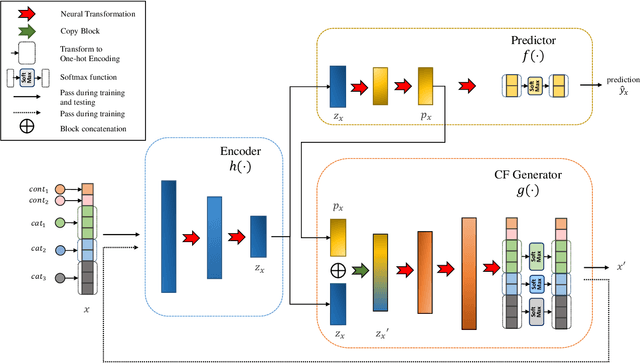
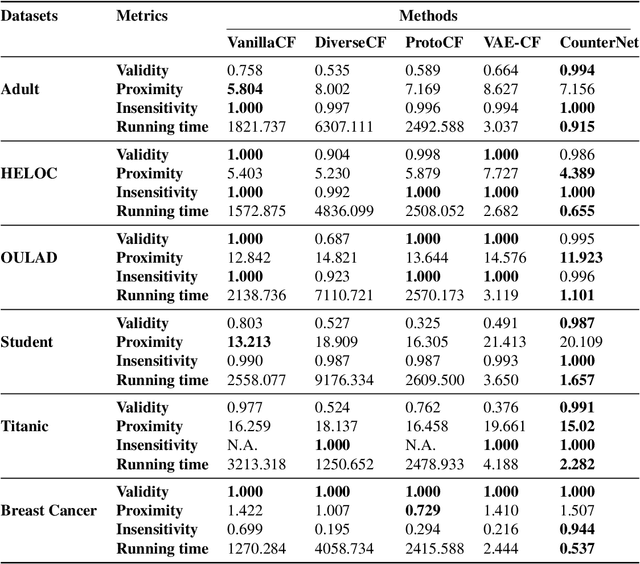
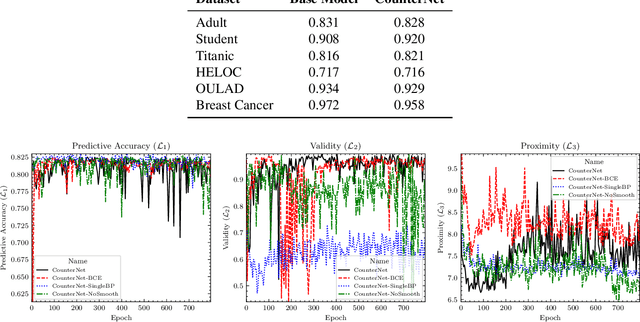
This work presents CounterNet, a novel end-to-end learning framework which integrates the predictive model training and counterfactual (CF) explanation generation into a single end-to-end pipeline. Counterfactual explanations attempt to find the smallest modification to the feature values of an instance that changes the prediction of the ML model to a predefined output. Prior CF explanation techniques rely on solving separate time-intensive optimization problems for every single input instance to find CF examples, and also suffer from the misalignment of objectives between model predictions and explanations, which leads to significant shortcomings in the quality of CF explanations. CounterNet, on the other hand, integrates both prediction and explanation in the same framework, which enables the optimization of the CF example generation only once together with the predictive model. We propose a novel variant of back-propagation which can help in effectively training CounterNet's network. Finally, we conduct extensive experiments on multiple real-world datasets. Our results show that CounterNet generates high-quality predictions, and corresponding CF examples (with high validity) for any new input instance significantly faster than existing state-of-the-art baselines.
Rapid Replanning in Consecutive Pick-and-Place Tasks with Lazy Experience Graph
Sep 21, 2021
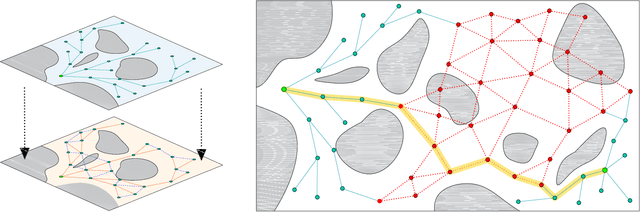
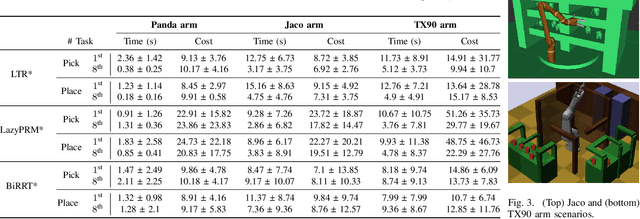
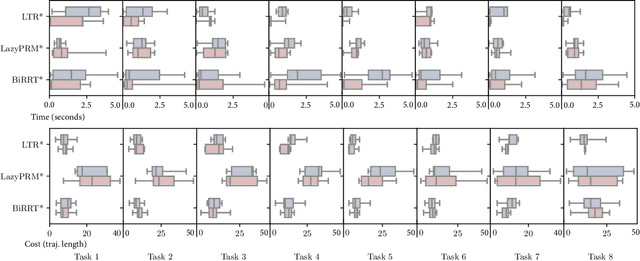
In an environment where a manipulator needs to execute multiple pick-and-place tasks, the act of object manoeuvre will change the underlying configuration space, which in turn affects all subsequent tasks. Previously free configurations might now be occupied by the newly placed objects, and previously occupied space might now open up new paths. We propose Lazy Tree-based Replanner (LTR*) -- a novel hybrid planner that inherits the rapid planning nature of existing anytime incremental sampling-based planners, and at the same time allows subsequent tasks to leverage prior experience via a lazy experience graph. Previous experience is summarised in a lazy graph structure, and LTR* is formulated such that it is robust and beneficial regardless of the extent of changes in the workspace. Our hybrid approach attains a faster speed in obtaining an initial solution than existing roadmap-based planners and often with a lower cost in trajectory length. Subsequent tasks can utilise the lazy experience graph to speed up finding a solution and take advantage of the optimised graph to minimise the cost objective. We provide rigorous proofs of probabilistic completeness and asymptotic optimal guarantees. Experimentally, we show that in repeated pick-and-place tasks, LTR* attains a high gain in performance when planning for subsequent tasks.
A new weakly supervised approach for ALS point cloud semantic segmentation
Oct 06, 2021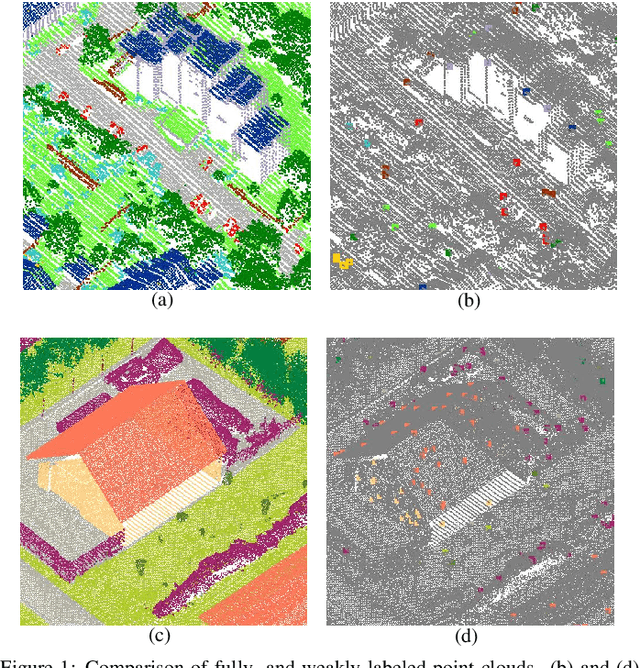
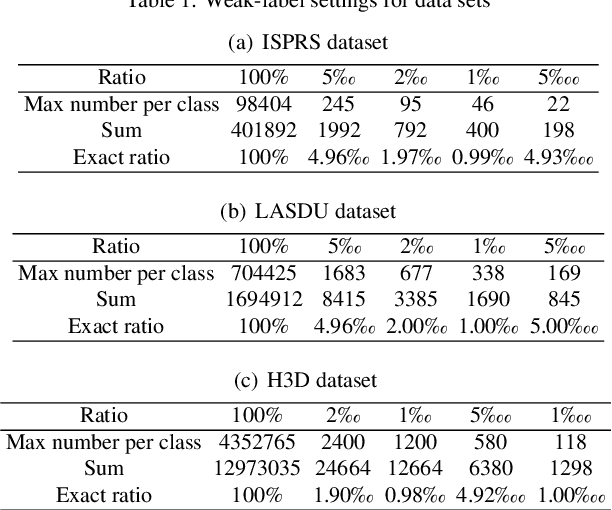
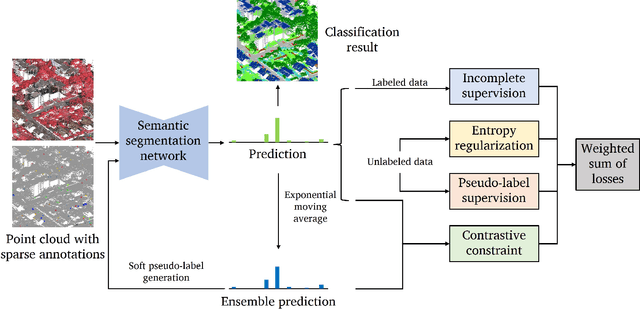
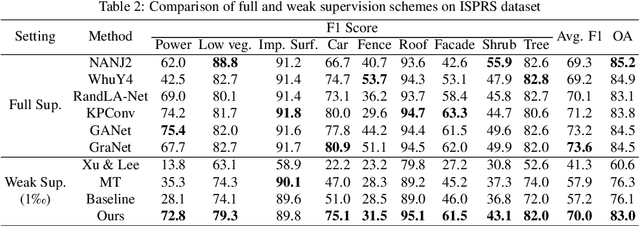
While there are novel point cloud semantic segmentation schemes that continuously surpass state-of-the-art results, the success of learning an effective model usually rely on the availability of abundant labeled data. However, data annotation is a time-consuming and labor-intensive task, particularly for large-scale airborne laser scanning (ALS) point clouds involving multiple classes in urban areas. Thus, how to attain promising results while largely reducing labeling works become an essential issue. In this study, we propose a deep-learning based weakly supervised framework for semantic segmentation of ALS point clouds, exploiting potential information from unlabeled data subject to incomplete and sparse labels. Entropy regularization is introduced to penalize the class overlap in predictive probability. Additionally, a consistency constraint by minimizing the discrepancy distance between instant and ensemble predictions is designed to improve the robustness of predictions. Finally, we propose an online soft pseudo-labeling strategy to create extra supervisory sources in an efficient and nonpaprametric way. Extensive experimental analysis using three benchmark datasets demonstrates that in case of sparse point annotations, our proposed method significantly boosts the classification performance without compromising the computational efficiency. It outperforms current weakly supervised methods and achieves a comparable result against full supervision competitors. For the ISPRS 3D Labeling Vaihingen data, by using only 0.1% of labels, our method achieves an overall accuracy of 83.0% and an average F1 score of 70.0%, which have increased by 6.9% and 12.8% respectively, compared to model trained by sparse label information only.
Safe, Deterministic Trajectory Planning for Unstructured and Partially Occluded Environments
Sep 09, 2021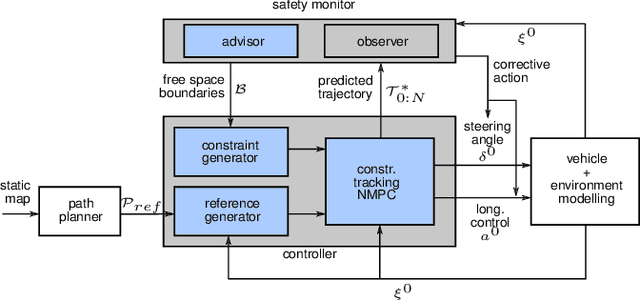

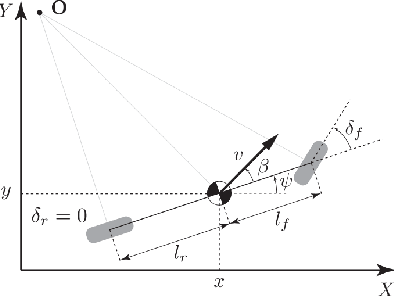
Ensuring safe behavior for automated vehicles in unregulated traffic areas poses a complex challenge for the industry. It is an open problem to provide scalable and certifiable solutions to this challenge. We derive a trajectory planner based on model predictive control which interoperates with a monitoring system for pedestrian safety based on cellular automata. The combined planner-monitor system is demonstrated on the example of a narrow indoor parking environment. The system features deterministic behavior, mitigating the immanent risk of black boxes and offering full certifiability. By using fundamental and conservative prediction models of pedestrians the monitor is able to determine a safe drivable area in the partially occluded and unstructured parking environment. The information is fed to the trajectory planner which ensures the vehicle remains in the safe drivable area at any time through constrained optimization. We show how the approach enables solving plenty of situations in tight parking garage scenarios. Even though conservative prediction models are applied, evaluations indicate a performant system for the tested low-speed navigation.