 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn objective function for order preserving hierarchical clustering
Sep 09, 2021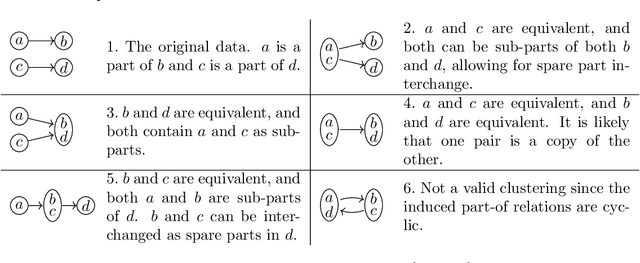
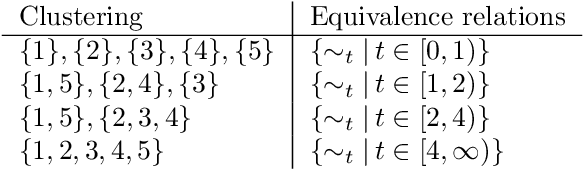
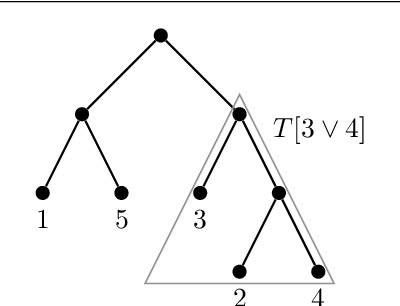
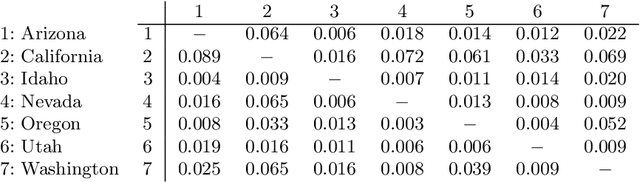
We present an objective function for similarity based hierarchical clustering of partially ordered data that preserves the partial order in the sense that if $x \leq y$, and if $[x]$ and $[y]$ are the respective clusters of $x$ and $y$, then there is an order relation $\leq'$ on the clusters for which $[x] \leq' |y]$. The model distinguishes itself from existing methods and models for clustering of ordered data in that the order relation and the similarity are combined to obtain an optimal hierarchical clustering seeking to satisfy both, and that the order relation is equipped with a pairwise level of comparability in the range $[0,1]$. In particular, if the similarity and the order relation are not aligned, then order preservation may have to yield in favor of clustering. Finding an optimal solution is NP-hard, so we provide a polynomial time approximation algorithm, with a relative performance guarantee of $O(\log^{3/2}n)$, based on successive applications of directed sparsest cut. The model is an extension of the Dasgupta cost function for divisive hierarchical clustering.
Order preserving hierarchical agglomerative clustering of strict posets
Apr 26, 2020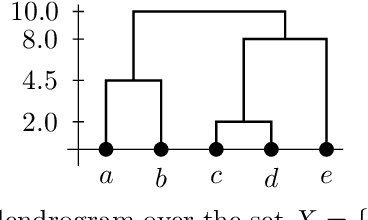
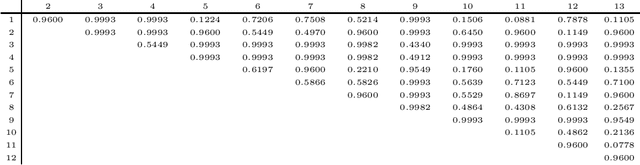
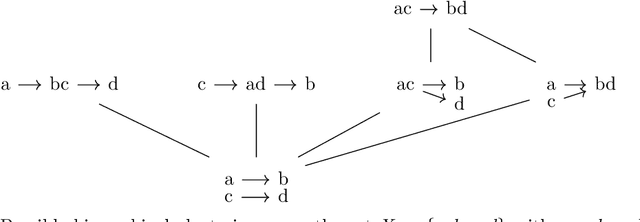
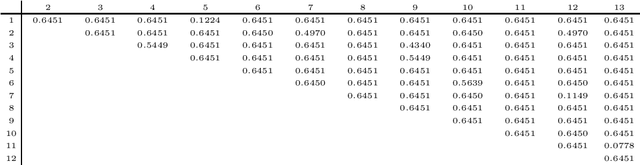
We present a method for hierarchical clustering of directed acyclic graphs and other strictly partially ordered data that preserves the data structure. In particular, if we have $a < b$ in the original data and denote their respective clusters by $[a]$ and $[b]$, we get $[a] < [b]$ in the produced clustering. The clustering uses standard linkage functions, such as single- and complete linkage, and is a generalisation of hierarchical clustering of non-ordered sets. To achieve this, we define the output from running hierarchical clustering algorithms on strictly ordered data to be partial dendrograms; sub-trees of classical dendrograms with several connected components. We then construct an embedding of partial dendrograms over a set into the family of ultrametrics over the same set. An optimal hierarchical clustering is now defined as follows: Given a collection of partial dendrograms, the optimal clustering is the partial dendrogram corresponding to the ultrametric closest to the original dissimilarity measure, measured in the $p$-norm. Thus, the method is a combination of classical hierarchical clustering and ultrametric fitting.