 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Adjustable Real-time Style Transfer
Nov 21, 2018
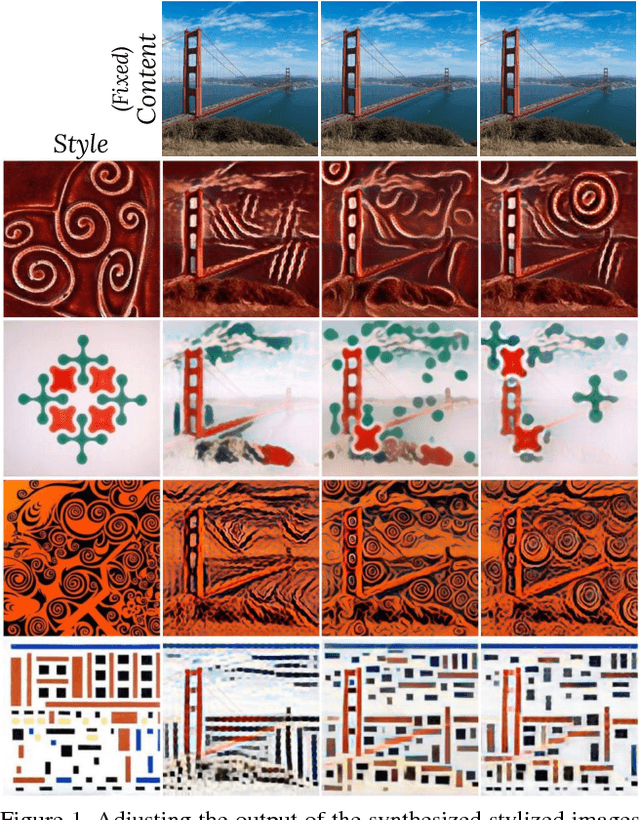

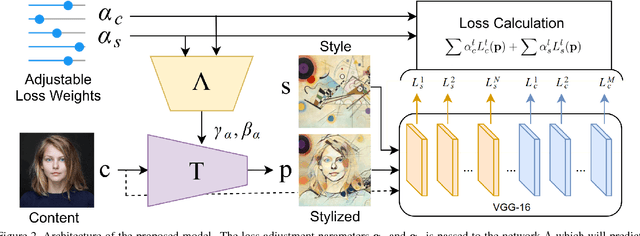
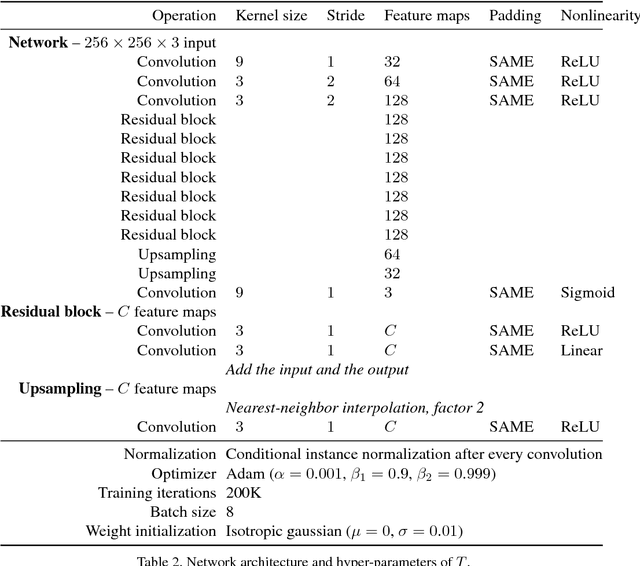
Artistic style transfer is the problem of synthesizing an image with content similar to a given image and style similar to another. Although recent feed-forward neural networks can generate stylized images in real-time, these models produce a single stylization given a pair of style/content images, and the user doesn't have control over the synthesized output. Moreover, the style transfer depends on the hyper-parameters of the model with varying "optimum" for different input images. Therefore, if the stylized output is not appealing to the user, she/he has to try multiple models or retrain one with different hyper-parameters to get a favorite stylization. In this paper, we address these issues by proposing a novel method which allows adjustment of crucial hyper-parameters, after the training and in real-time, through a set of manually adjustable parameters. These parameters enable the user to modify the synthesized outputs from the same pair of style/content images, in search of a favorite stylized image. Our quantitative and qualitative experiments indicate how adjusting these parameters is comparable to retraining the model with different hyper-parameters. We also demonstrate how these parameters can be randomized to generate results which are diverse but still very similar in style and content.
On-the-Fly Controlled Text Generation with Experts and Anti-Experts
May 07, 2021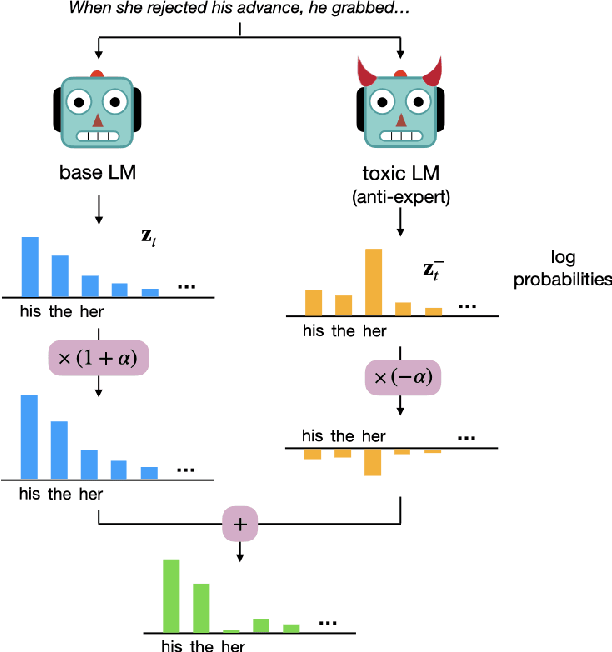
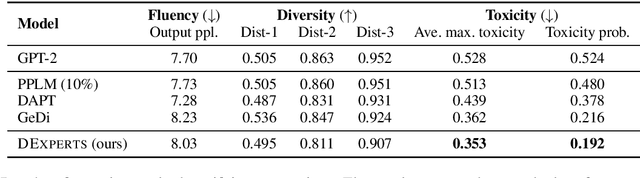
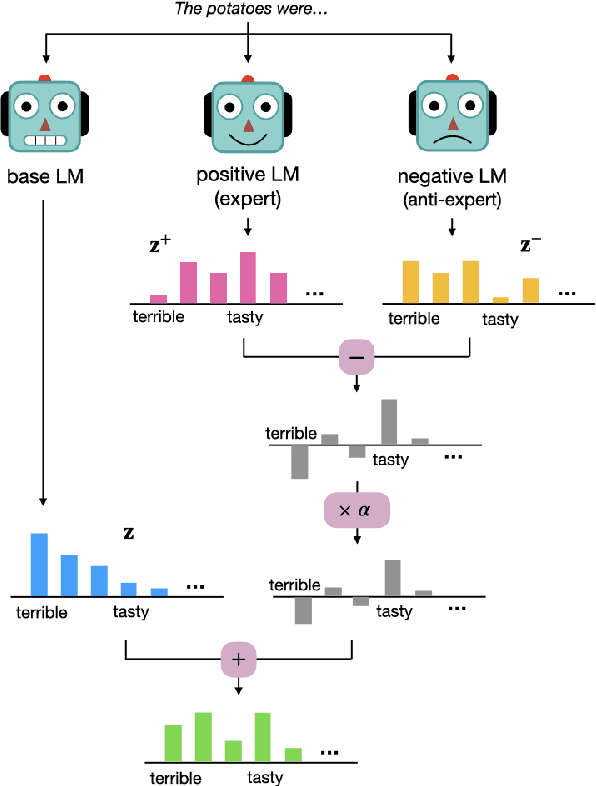
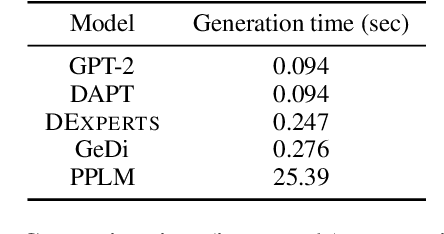
Despite recent advances in natural language generation, it remains challenging to control attributes of generated text. We propose DExperts: Decoding-time Experts, a decoding-time method for controlled text generation which combines a pretrained language model with experts and/or anti-experts in an ensemble of language models. Intuitively, under our ensemble, output tokens only get high probability if they are considered likely by the experts, and unlikely by the anti-experts. We apply DExperts to language detoxification and sentiment-controlled generation, where we outperform existing controllable generation methods on both automatic and human evaluations. Our work highlights the promise of using LMs trained on text with (un)desired attributes for efficient decoding-time controlled language generation.
Proof of Reference(PoR): A unified informetrics based consensus mechanism
Jul 01, 2021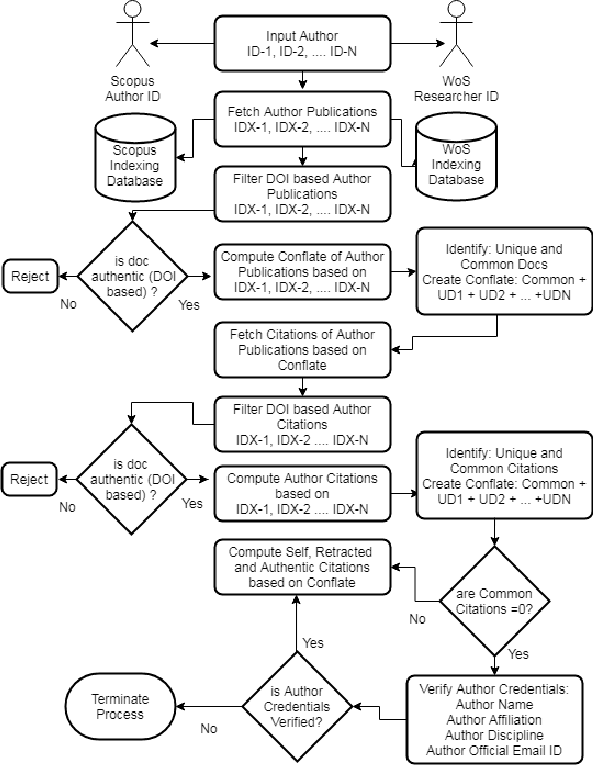
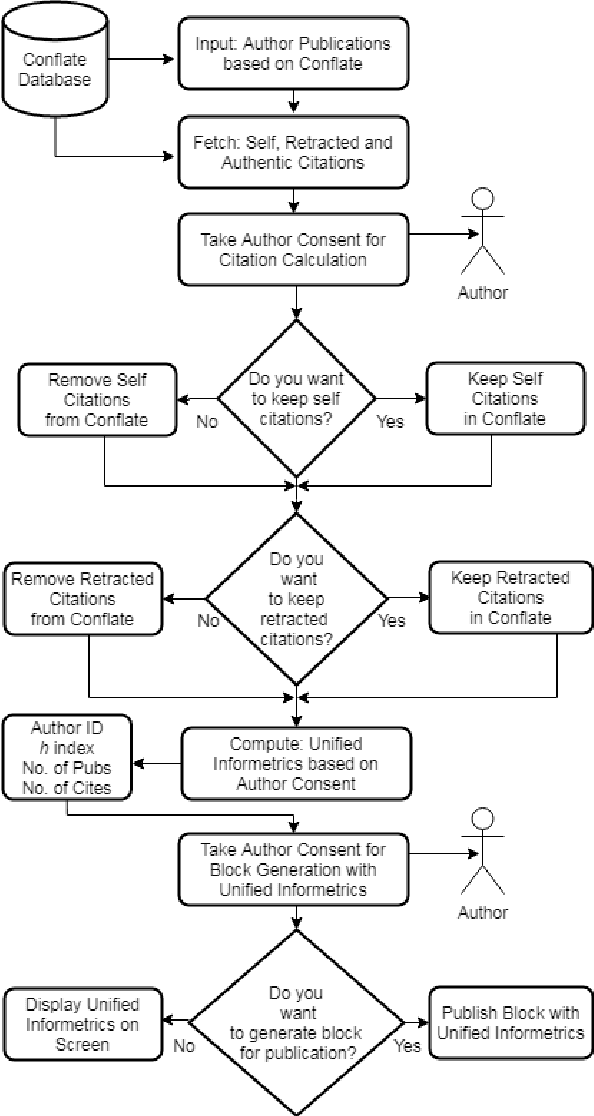

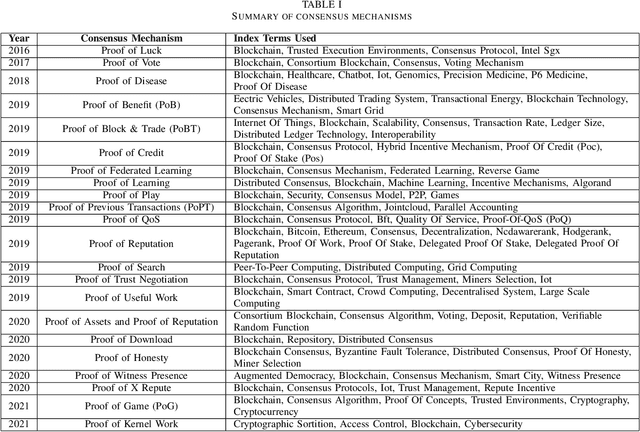
Bibliometrics is useful to analyze the research impact for measuring the research quality. Different bibliographic databases like Scopus, Web of Science, Google Scholar etc. are accessed for evaluating the trend of publications and citations from time to time. Some of these databases are free and some are subscription based. Its always debatable that which bibliographic database is better and in what terms. To provide an optimal solution to availability of multiple bibliographic databases, we have implemented a single authentic database named as ``conflate'' which can be used for fetching publication and citation trend of an author. To further strengthen the generated database and to provide the transparent system to the stakeholders, a consensus mechanism ``proof of reference (PoR)'' is proposed. Due to three consent based checks implemented in PoR, we feel that it could be considered as a authentic and honest citation data source for the calculation of unified informetrics for an author.
Solving Large Break Minimization Problems in a Mirrored Double Round-robin Tournament Using Quantum Annealing
Oct 18, 2021
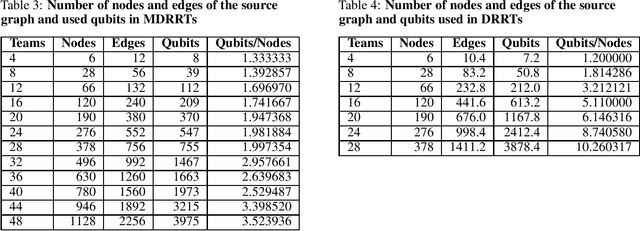
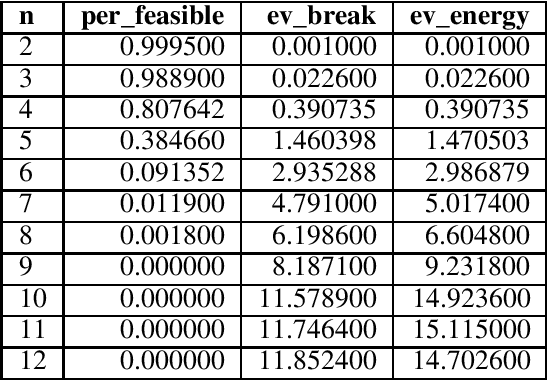
Quantum annealing (QA) has gained considerable attention because it can be applied to combinatorial optimization problems, which have numerous applications in logistics, scheduling, and finance. In recent years, research on solving practical combinatorial optimization problems using them has accelerated. However, researchers struggle to find practical combinatorial optimization problems, for which quantum annealers outperform other mathematical optimization solvers. Moreover, there are only a few studies that compare the performance of quantum annealers with one of the most sophisticated mathematical optimization solvers, such as Gurobi and CPLEX. In our study, we determine that QA demonstrates better performance than the solvers in the break minimization problem in a mirrored double round-robin tournament (MDRRT). We also explain the desirable performance of QA for the sparse interaction between variables and a problem without constraints. In this process, we demonstrate that the break minimization problem in an MDRRT can be expressed as a 4-regular graph. Through computational experiments, we solve this problem using our QA approach and two-integer programming approaches, which were performed using the latest quantum annealer D-Wave Advantage, and the sophisticated mathematical optimization solver, Gurobi, respectively. Further, we compare the quality of the solutions and the computational time. QA was able to determine the exact solution in 0.05 seconds for problems with 20 teams, which is a practical size. In the case of 36 teams, it took 84.8 s for the integer programming method to reach the objective function value, which was obtained by the quantum annealer in 0.05 s. These results not only present the break minimization problem in an MDRRT as an example of applying QA to practical optimization problems, but also contribute to find problems that can be effectively solved by QA.
Permute Me Softly: Learning Soft Permutations for Graph Representations
Oct 05, 2021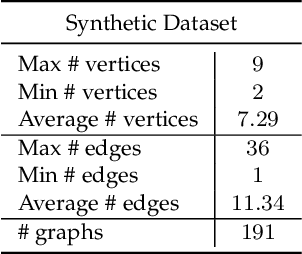
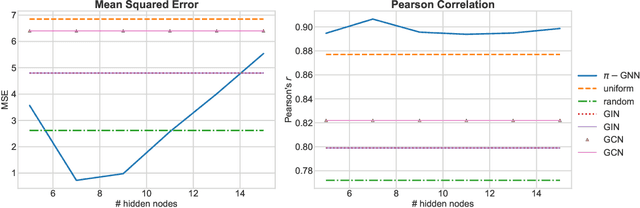
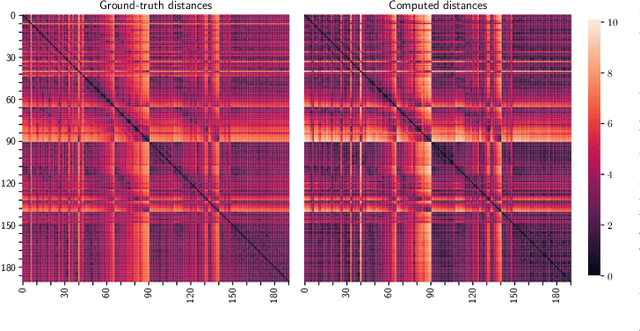
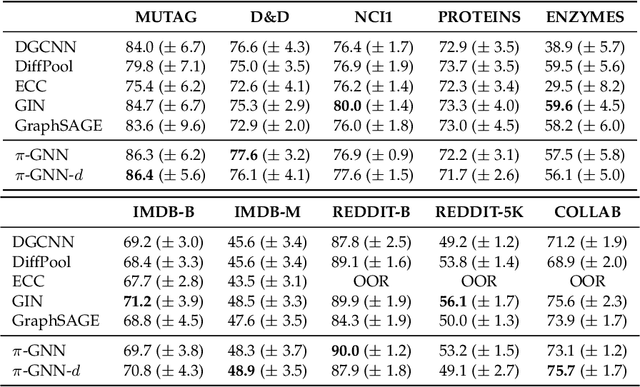
Graph neural networks (GNNs) have recently emerged as a dominant paradigm for machine learning with graphs. Research on GNNs has mainly focused on the family of message passing neural networks (MPNNs). Similar to the Weisfeiler-Leman (WL) test of isomorphism, these models follow an iterative neighborhood aggregation procedure to update vertex representations, and they next compute graph representations by aggregating the representations of the vertices. Although very successful, MPNNs have been studied intensively in the past few years. Thus, there is a need for novel architectures which will allow research in the field to break away from MPNNs. In this paper, we propose a new graph neural network model, so-called $\pi$-GNN which learns a "soft" permutation (i.e., doubly stochastic) matrix for each graph, and thus projects all graphs into a common vector space. The learned matrices impose a "soft" ordering on the vertices of the input graphs, and based on this ordering, the adjacency matrices are mapped into vectors. These vectors can be fed into fully-connected or convolutional layers to deal with supervised learning tasks. In case of large graphs, to make the model more efficient in terms of running time and memory, we further relax the doubly stochastic matrices to row stochastic matrices. We empirically evaluate the model on graph classification and graph regression datasets and show that it achieves performance competitive with state-of-the-art models.
Transformed ROIs for Capturing Visual Transformations in Videos
Jun 06, 2021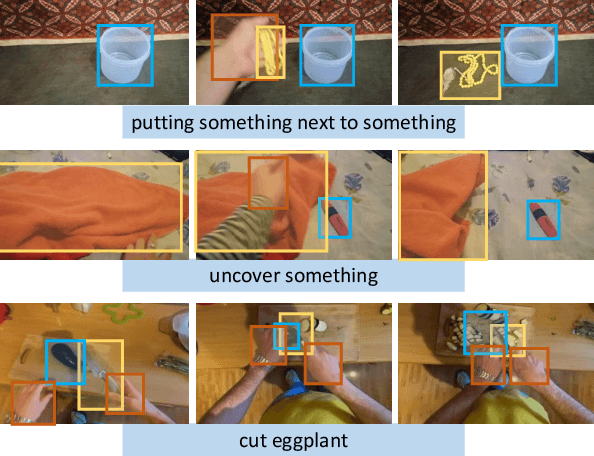
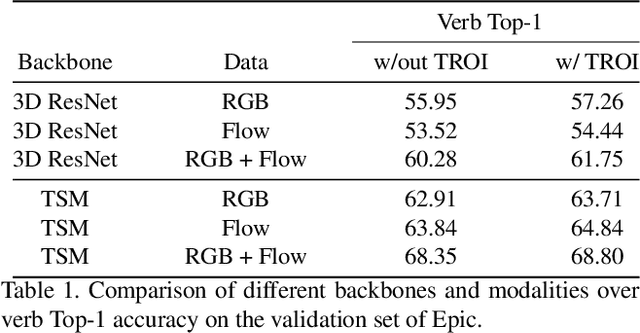
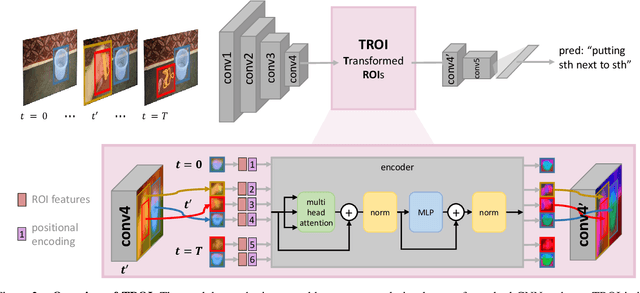
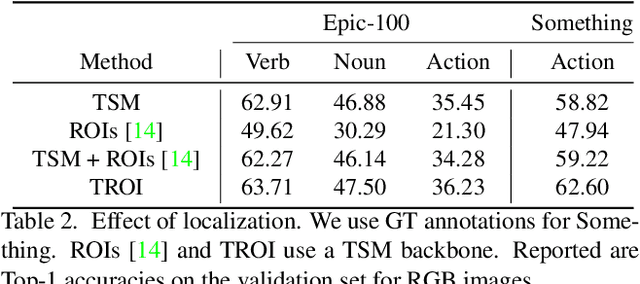
Modeling the visual changes that an action brings to a scene is critical for video understanding. Currently, CNNs process one local neighbourhood at a time, so contextual relationships over longer ranges, while still learnable, are indirect. We present TROI, a plug-and-play module for CNNs to reason between mid-level feature representations that are otherwise separated in space and time. The module relates localized visual entities such as hands and interacting objects and transforms their corresponding regions of interest directly in the feature maps of convolutional layers. With TROI, we achieve state-of-the-art action recognition results on the large-scale datasets Something-Something-V2 and Epic-Kitchens-100.
A Bayesian Approach to (Online) Transfer Learning: Theory and Algorithms
Sep 30, 2021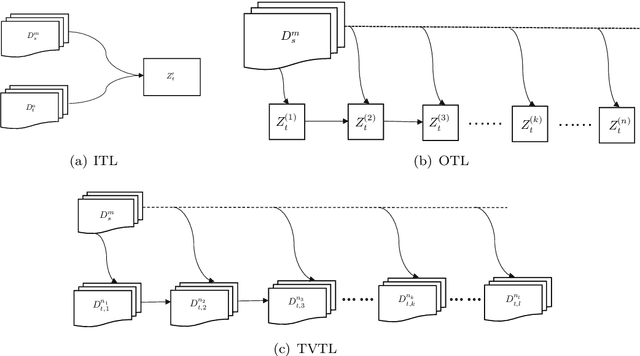

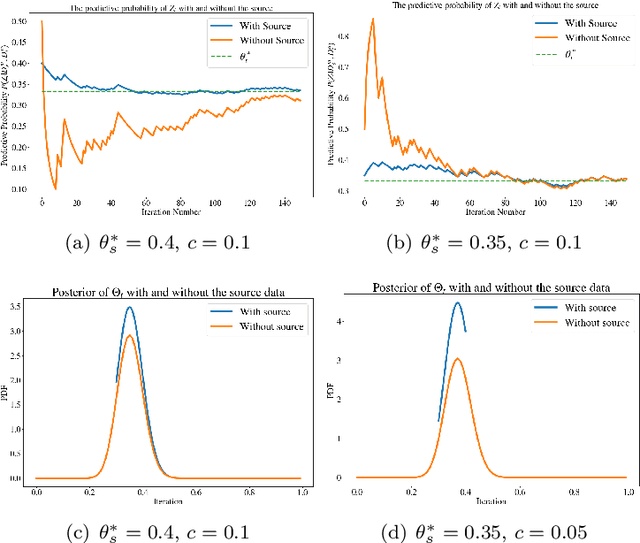
Transfer learning is a machine learning paradigm where knowledge from one problem is utilized to solve a new but related problem. While conceivable that knowledge from one task could be useful for solving a related task, if not executed properly, transfer learning algorithms can impair the learning performance instead of improving it -- commonly known as negative transfer. In this paper, we study transfer learning from a Bayesian perspective, where a parametric statistical model is used. Specifically, we study three variants of transfer learning problems, instantaneous, online, and time-variant transfer learning. For each problem, we define an appropriate objective function, and provide either exact expressions or upper bounds on the learning performance using information-theoretic quantities, which allow simple and explicit characterizations when the sample size becomes large. Furthermore, examples show that the derived bounds are accurate even for small sample sizes. The obtained bounds give valuable insights into the effect of prior knowledge for transfer learning, at least with respect to our Bayesian formulation of the transfer learning problem. In particular, we formally characterize the conditions under which negative transfer occurs. Lastly, we devise two (online) transfer learning algorithms that are amenable to practical implementations, one of which does not require the parametric assumption. We demonstrate the effectiveness of our algorithms with real data sets, focusing primarily on when the source and target data have strong similarities.
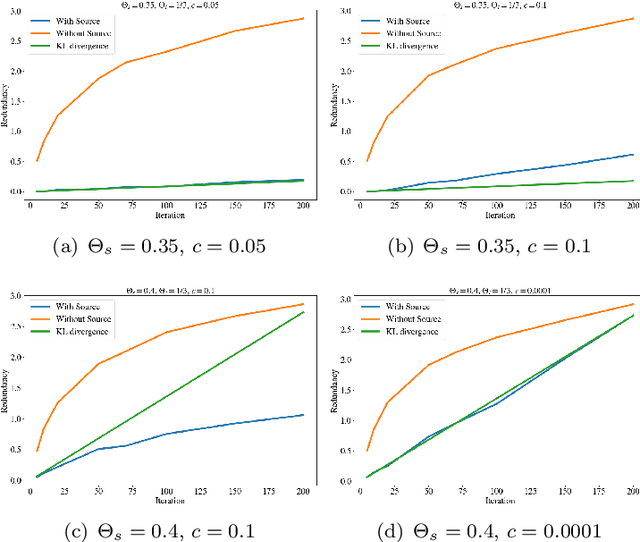
A stochastic metapopulation state-space approach to modeling and estimating Covid-19 spread
Jun 15, 2021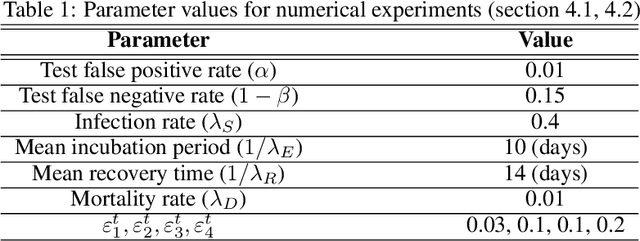
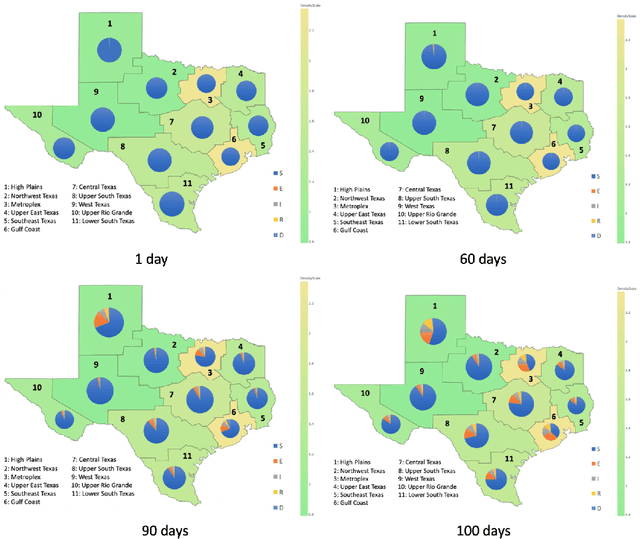

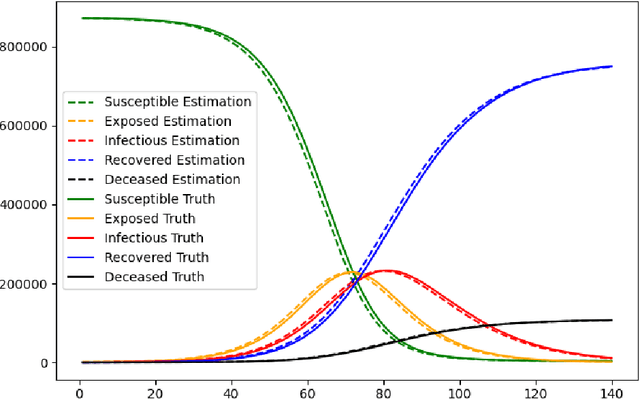
Mathematical models are widely recognized as an important tool for analyzing and understanding the dynamics of infectious disease outbreaks, predict their future trends, and evaluate public health intervention measures for disease control and elimination. We propose a novel stochastic metapopulation state-space model for COVID-19 transmission, based on a discrete-time spatio-temporal susceptible/exposed/infected/recovered/deceased (SEIRD) model. The proposed framework allows the hidden SEIRD states and unknown transmission parameters to be estimated from noisy, incomplete time series of reported epidemiological data, by application of unscented Kalman filtering (UKF), maximum-likelihood adaptive filtering, and metaheuristic optimization. Experiments using both synthetic data and real data from the Fall 2020 Covid-19 wave in the state of Texas demonstrate the effectiveness of the proposed model.
On the Explanatory Power of Decision Trees
Aug 11, 2021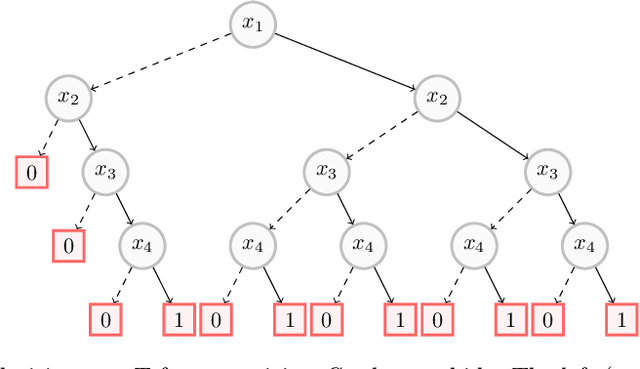
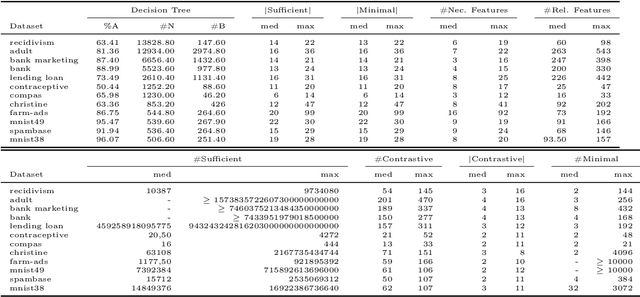
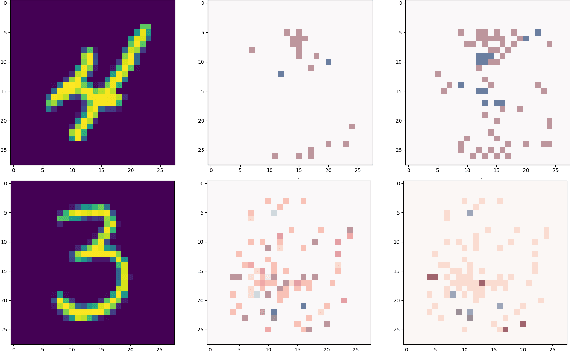
Decision trees have long been recognized as models of choice in sensitive applications where interpretability is of paramount importance. In this paper, we examine the computational ability of Boolean decision trees in deriving, minimizing, and counting sufficient reasons and contrastive explanations. We prove that the set of all sufficient reasons of minimal size for an instance given a decision tree can be exponentially larger than the size of the input (the instance and the decision tree). Therefore, generating the full set of sufficient reasons can be out of reach. In addition, computing a single sufficient reason does not prove enough in general; indeed, two sufficient reasons for the same instance may differ on many features. To deal with this issue and generate synthetic views of the set of all sufficient reasons, we introduce the notions of relevant features and of necessary features that characterize the (possibly negated) features appearing in at least one or in every sufficient reason, and we show that they can be computed in polynomial time. We also introduce the notion of explanatory importance, that indicates how frequent each (possibly negated) feature is in the set of all sufficient reasons. We show how the explanatory importance of a feature and the number of sufficient reasons can be obtained via a model counting operation, which turns out to be practical in many cases. We also explain how to enumerate sufficient reasons of minimal size. We finally show that, unlike sufficient reasons, the set of all contrastive explanations for an instance given a decision tree can be derived, minimized and counted in polynomial time.
Early warning of pedestrians and cyclists
Jul 12, 2021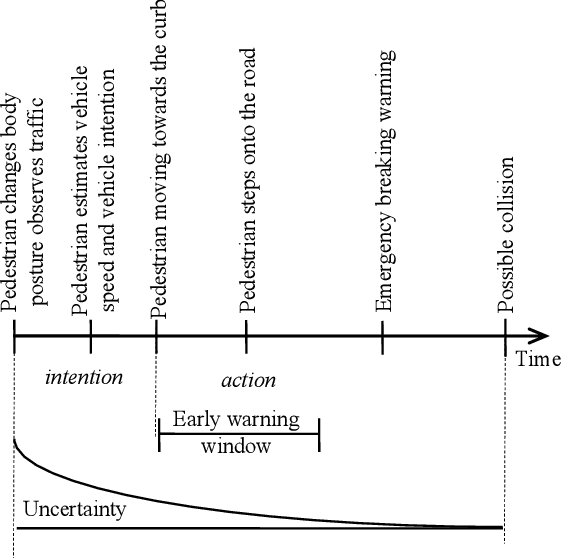
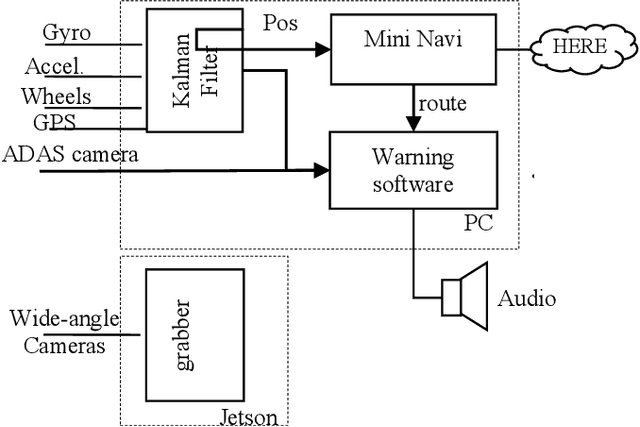

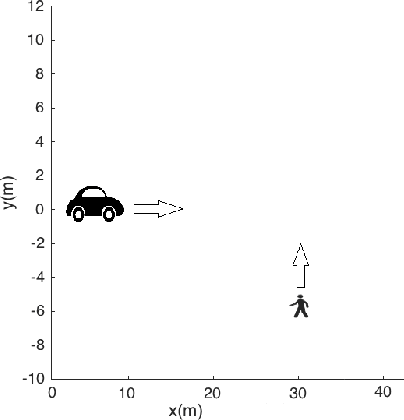
State-of-the-art motor vehicles are able to break for pedestrians in an emergency. We investigate what it would take to issue an early warning to the driver so he/she has time to react. We have identified that predicting the intention of a pedestrian reliably by position is a particularly hard challenge. This paper describes an early pedestrian warning demonstration system.