 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Acoustic Source Localization in Shallow Water: A Probabilistic Focalization Approach
Sep 14, 2021
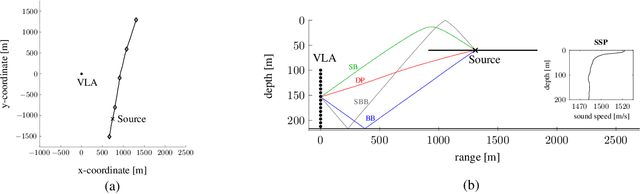

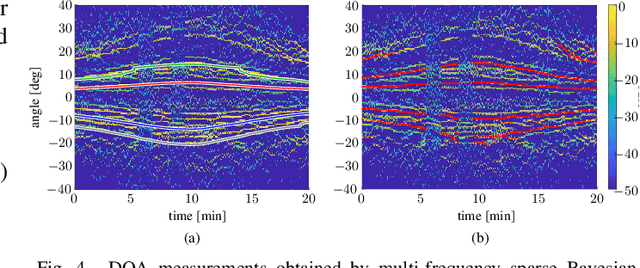
This paper presents a Bayesian estimation method for the passive localization of an acoustic source in shallow water. Our probabilistic focalization approach estimates the time-varying source location by associating direction of arrival (DOA) observations to DOAs predicted based on a statistical model. Embedded ray tracing makes it possible to incorporate environmental parameters and characterize the nonlinear acoustic waveguide. We demonstrate performance advantages of our approach compared to matched field processing using data collected during the SWellEx-96 experiment.
Stochastic Treatment Recommendation with Deep Survival Dose Response Function (DeepSDRF)
Aug 24, 2021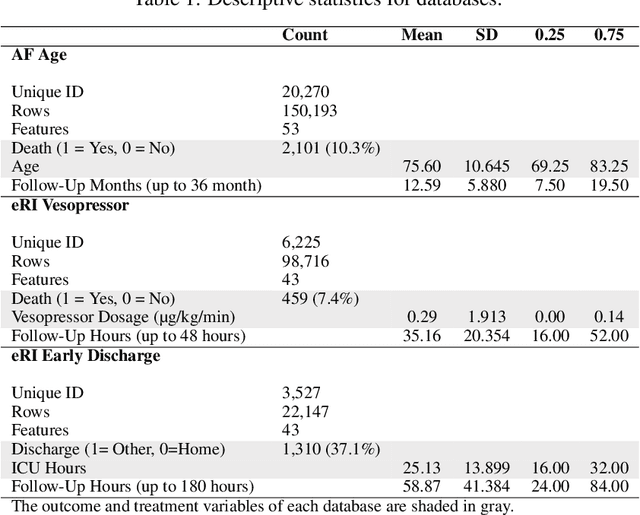
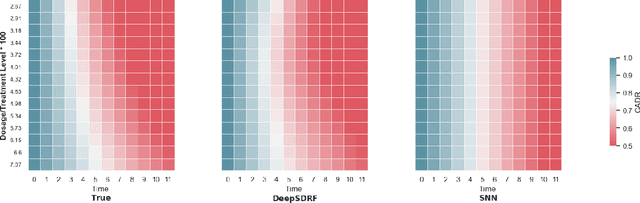
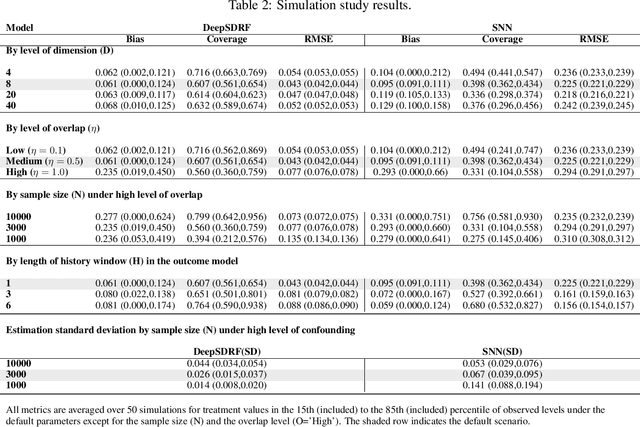
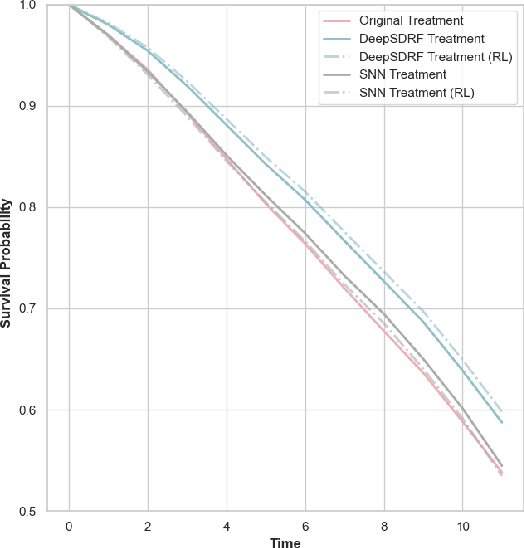
We propose a general formulation for stochastic treatment recommendation problems in settings with clinical survival data, which we call the Deep Survival Dose Response Function (DeepSDRF). That is, we consider the problem of learning the conditional average dose response (CADR) function solely from historical data in which unobserved factors (confounders) affect both observed treatment and time-to-event outcomes. The estimated treatment effect from DeepSDRF enables us to develop recommender algorithms with explanatory insights. We compared two recommender approaches based on random search and reinforcement learning and found similar performance in terms of patient outcome. We tested the DeepSDRF and the corresponding recommender on extensive simulation studies and two empirical databases: 1) the Clinical Practice Research Datalink (CPRD) and 2) the eICU Research Institute (eRI) database. To the best of our knowledge, this is the first time that confounders are taken into consideration for addressing the stochastic treatment effect with observational data in a medical context.
A Wideband Signal Recognition Dataset
Oct 01, 2021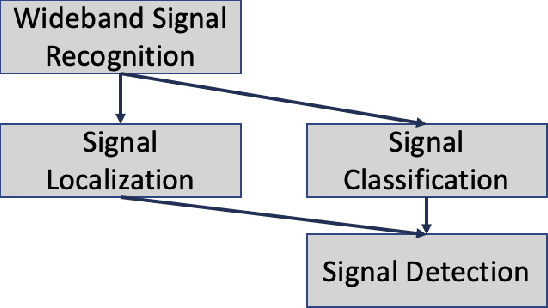
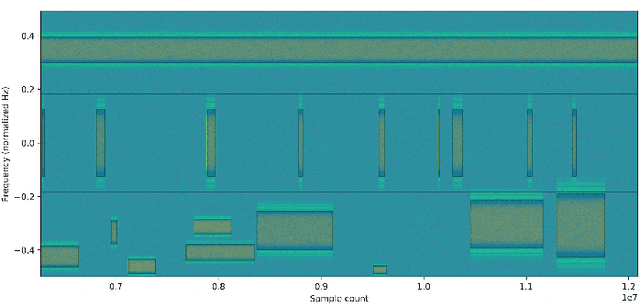
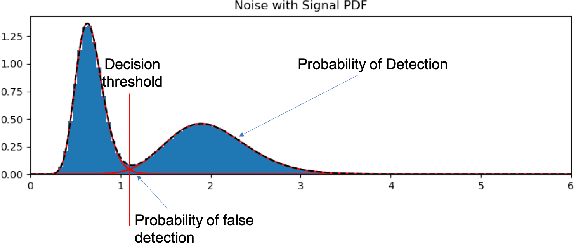
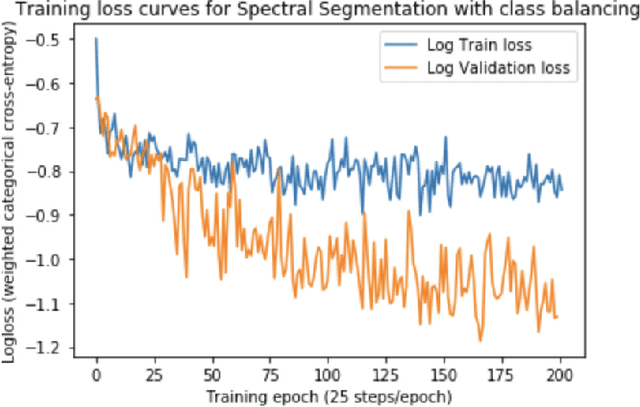
Signal recognition is a spectrum sensing problem that jointly requires detection, localization in time and frequency, and classification. This is a step beyond most spectrum sensing work which involves signal detection to estimate "present" or "not present" detections for either a single channel or fixed sized channels or classification which assumes a signal is present. We define the signal recognition task, present the metrics of precision and recall to the RF domain, and review recent machine-learning based approaches to this problem. We introduce a new dataset that is useful for training neural networks to perform these tasks and show a training framework to train wideband signal recognizers.
Improved Goal Oriented Dialogue via Utterance Generation and Look Ahead
Oct 24, 2021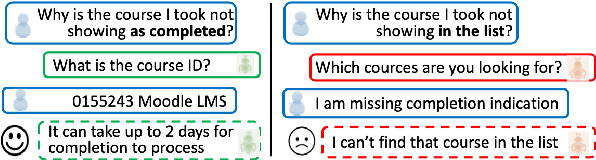
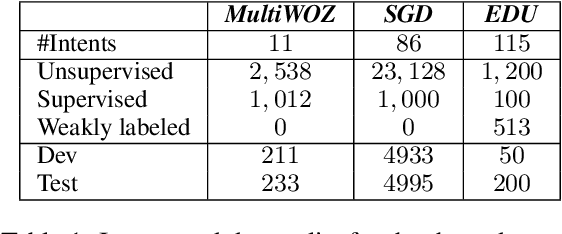
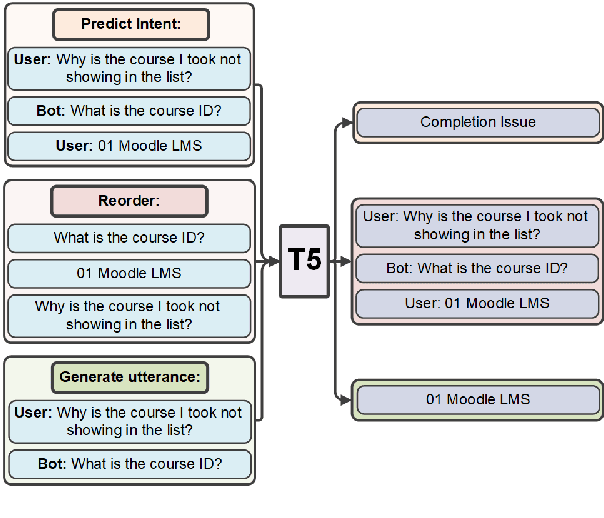
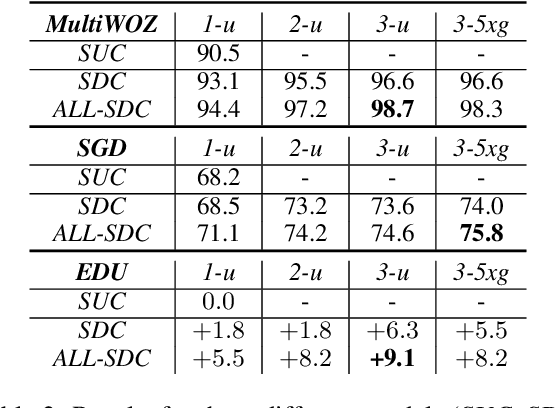
Goal oriented dialogue systems have become a prominent customer-care interaction channel for most businesses. However, not all interactions are smooth, and customer intent misunderstanding is a major cause of dialogue failure. We show that intent prediction can be improved by training a deep text-to-text neural model to generate successive user utterances from unlabeled dialogue data. For that, we define a multi-task training regime that utilizes successive user-utterance generation to improve the intent prediction. Our approach achieves the reported improvement due to two complementary factors: First, it uses a large amount of unlabeled dialogue data for an auxiliary generation task. Second, it uses the generated user utterance as an additional signal for the intent prediction model. Lastly, we present a novel look-ahead approach that uses user utterance generation to improve intent prediction in inference time. Specifically, we generate counterfactual successive user utterances for conversations with ambiguous predicted intents, and disambiguate the prediction by reassessing the concatenated sequence of available and generated utterances.
Get Fooled for the Right Reason: Improving Adversarial Robustness through a Teacher-guided Curriculum Learning Approach
Oct 30, 2021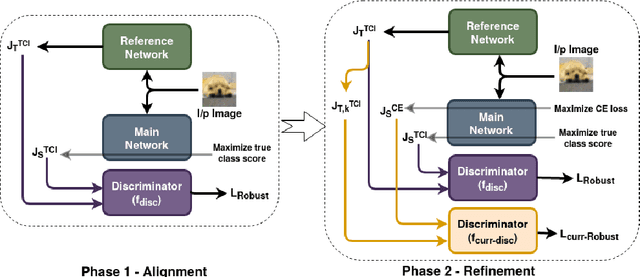
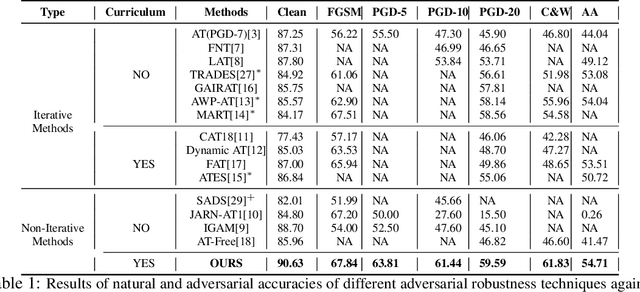
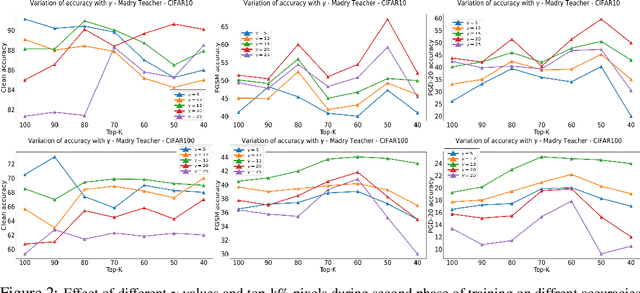
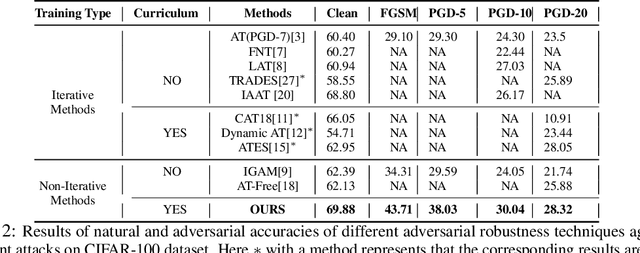
Current SOTA adversarially robust models are mostly based on adversarial training (AT) and differ only by some regularizers either at inner maximization or outer minimization steps. Being repetitive in nature during the inner maximization step, they take a huge time to train. We propose a non-iterative method that enforces the following ideas during training. Attribution maps are more aligned to the actual object in the image for adversarially robust models compared to naturally trained models. Also, the allowed set of pixels to perturb an image (that changes model decision) should be restricted to the object pixels only, which reduces the attack strength by limiting the attack space. Our method achieves significant performance gains with a little extra effort (10-20%) over existing AT models and outperforms all other methods in terms of adversarial as well as natural accuracy. We have performed extensive experimentation with CIFAR-10, CIFAR-100, and TinyImageNet datasets and reported results against many popular strong adversarial attacks to prove the effectiveness of our method.
Quantum Computer Music: Foundations and Initial Experiments
Oct 24, 2021
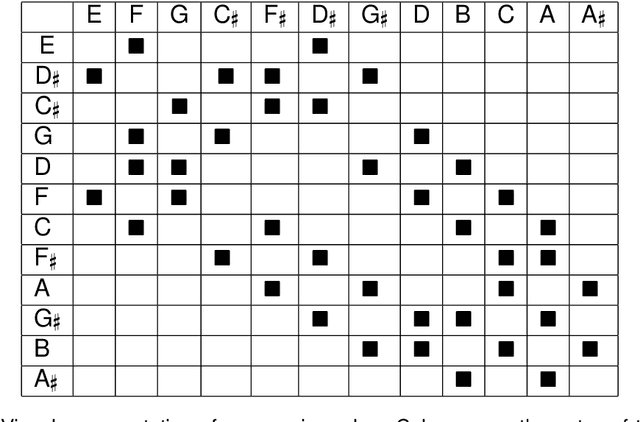

Quantum computing is a nascent technology, which is advancing rapidly. There is a long history of research into using computers for music. Nowadays computers are absolutely essential for the music economy. Thus, it is very likely that quantum computers will impact the music industry in time to come. This chapter lays the foundations of the new field of 'Quantum Computer Music'. It begins with an introduction to algorithmic computer music and methods to program computers to generate music, such as Markov chains and random walks. Then, it presents quantum computing versions of those methods. The discussions are supported by detailed explanations of quantum computing concepts and walk-through examples. A bespoke generative music algorithm is presented, the Basak-Miranda algorithm, which leverages a property of quantum mechanics known as constructive and destructive interference to operate a musical Markov chain. An Appendix introducing the fundamentals of quantum computing deemed necessary to understand the chapter and a link to access Jupyter Notebooks with examples are also provided.
Real-Time Lip Sync for Live 2D Animation
Oct 19, 2019
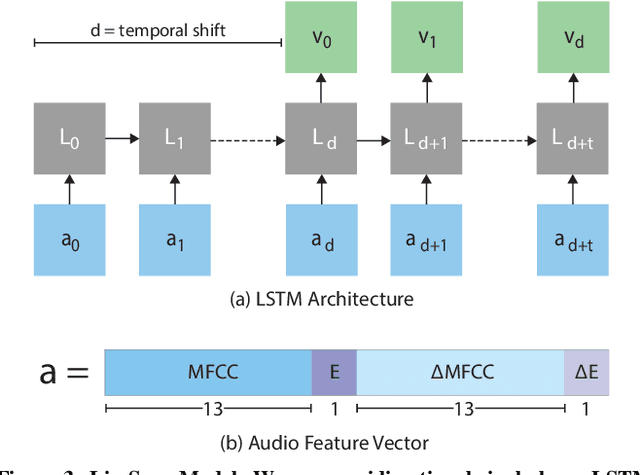
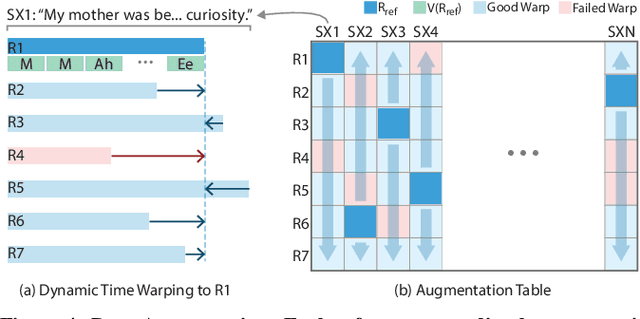
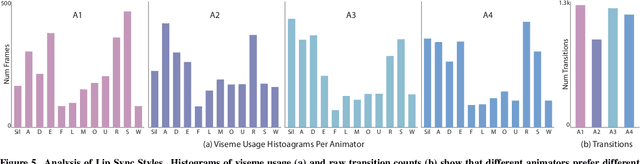
The emergence of commercial tools for real-time performance-based 2D animation has enabled 2D characters to appear on live broadcasts and streaming platforms. A key requirement for live animation is fast and accurate lip sync that allows characters to respond naturally to other actors or the audience through the voice of a human performer. In this work, we present a deep learning based interactive system that automatically generates live lip sync for layered 2D characters using a Long Short Term Memory (LSTM) model. Our system takes streaming audio as input and produces viseme sequences with less than 200ms of latency (including processing time). Our contributions include specific design decisions for our feature definition and LSTM configuration that provide a small but useful amount of lookahead to produce accurate lip sync. We also describe a data augmentation procedure that allows us to achieve good results with a very small amount of hand-animated training data (13-20 minutes). Extensive human judgement experiments show that our results are preferred over several competing methods, including those that only support offline (non-live) processing. Video summary and supplementary results at GitHub link: https://github.com/deepalianeja/CharacterLipSync2D
MobileXNet: An Efficient Convolutional Neural Network for Monocular Depth Estimation
Nov 24, 2021
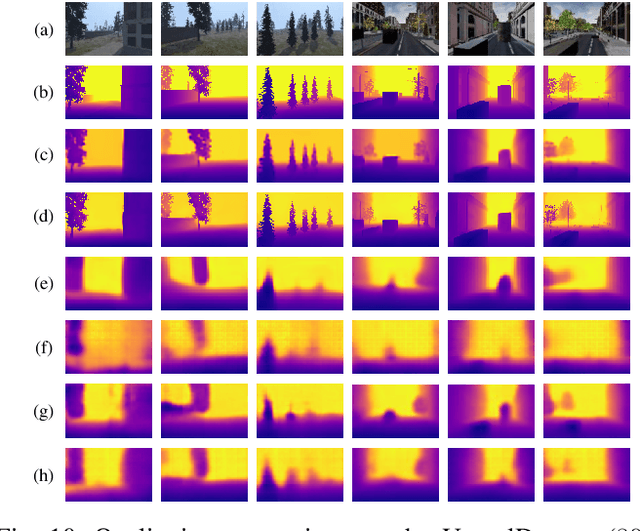
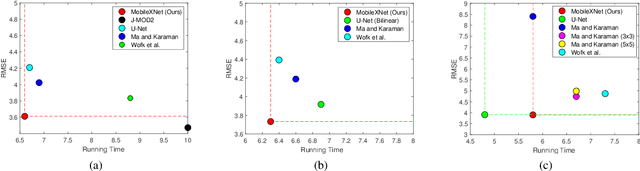
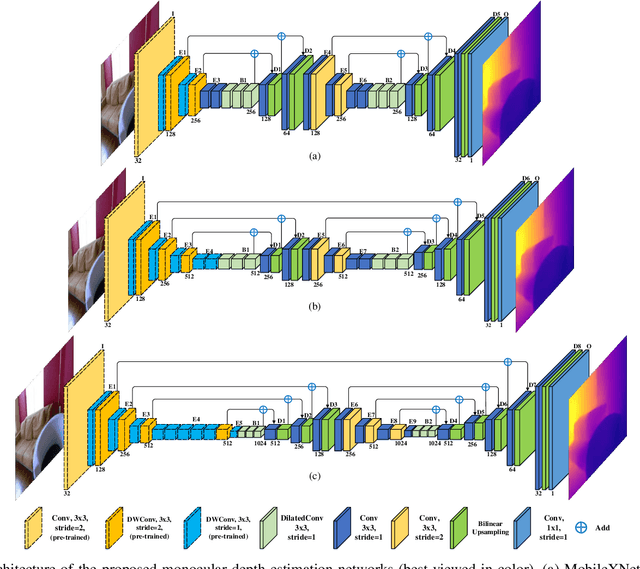
Depth is a vital piece of information for autonomous vehicles to perceive obstacles. Due to the relatively low price and small size of monocular cameras, depth estimation from a single RGB image has attracted great interest in the research community. In recent years, the application of Deep Neural Networks (DNNs) has significantly boosted the accuracy of monocular depth estimation (MDE). State-of-the-art methods are usually designed on top of complex and extremely deep network architectures, which require more computational resources and cannot run in real-time without using high-end GPUs. Although some researchers tried to accelerate the running speed, the accuracy of depth estimation is degraded because the compressed model does not represent images well. In addition, the inherent characteristic of the feature extractor used by the existing approaches results in severe spatial information loss in the produced feature maps, which also impairs the accuracy of depth estimation on small sized images. In this study, we are motivated to design a novel and efficient Convolutional Neural Network (CNN) that assembles two shallow encoder-decoder style subnetworks in succession to address these problems. In particular, we place our emphasis on the trade-off between the accuracy and speed of MDE. Extensive experiments have been conducted on the NYU depth v2, KITTI, Make3D and Unreal data sets. Compared with the state-of-the-art approaches which have an extremely deep and complex architecture, the proposed network not only achieves comparable performance but also runs at a much faster speed on a single, less powerful GPU.
Modelling of the Fender Bassman 5F6-A Tone Stack
Oct 05, 2021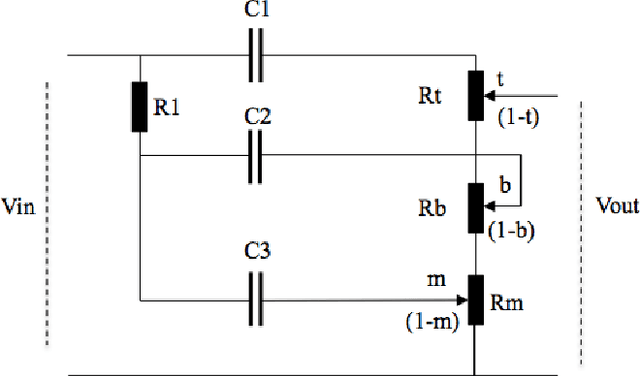
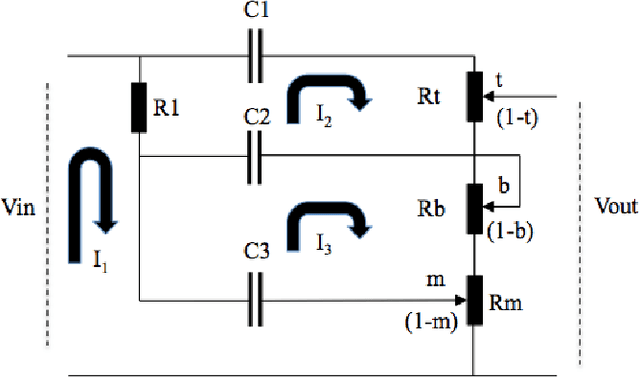
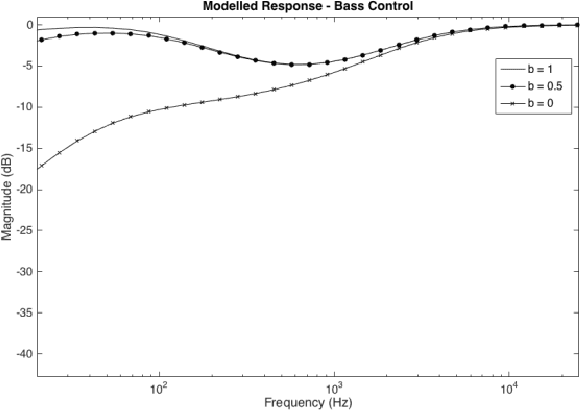
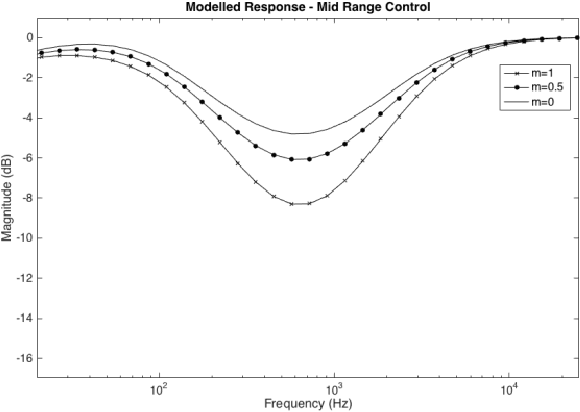
This paper outlines the procedure for the effective modelling of a complex analogue filter circuit. The Fender Bassman 5F6-A is a circuit commonly employed in guitar amplifiers to shape the tonal characteristics of the amplifier output. On first inspection this circuit may look rather simple, however the controls are not orthogonal, resulting in complicated filter coefficients as the controls are varied. This in turn can make the circuit difficult to analyse without the use of mathematical emulation tools such as PSPICE or MATLAB. First the circuit is described, a method of analysis is proposed and general expressions for continuous-time coefficients are given. A MATLAB model is then produced and the frequency responses of which are shown.
Package Delivery Using Autonomous Drones in Skyways
Aug 13, 2021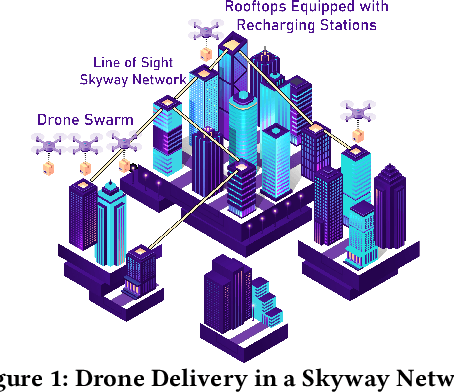

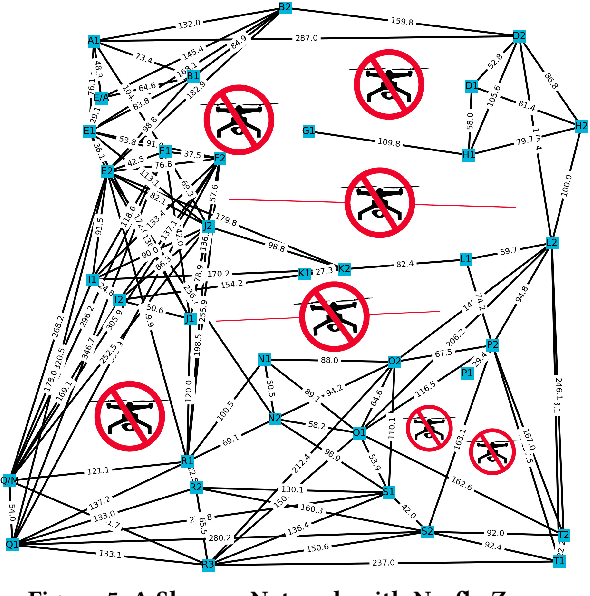
Current drone delivery systems mostly focus on point-to-point package delivery. We present a multi-stop drone service system to deliver packages anywhere anytime within a specified geographic area. We define a skyway network which takes into account flying regulations, including restricted areas and no-fly zones. The skyway nodes typically represent building rooftops which may act as both recharging stations and delivery destinations. A heuristic-based A* algorithm is used to compute an optimal path from source to destination taking into account a number of constraints, including delivery time, availability of recharging stations, etc. We deploy our drone delivery system in an indoor testbed environment using a 3D model of Sydney CBD. We describe a graphical user interface to monitor the real-time package delivery in the skyway network.