 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Optimizing Neural Architecture Search using Limited GPU Time in a Dynamic Search Space: A Gene Expression Programming Approach
May 15, 2020
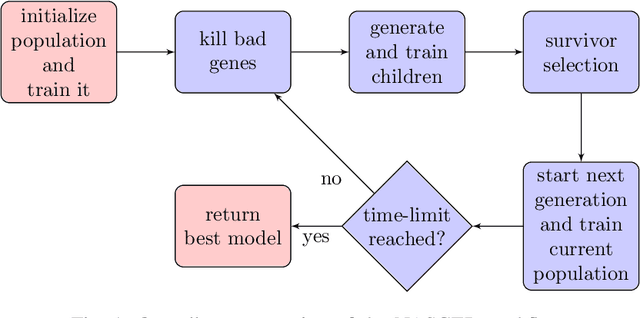
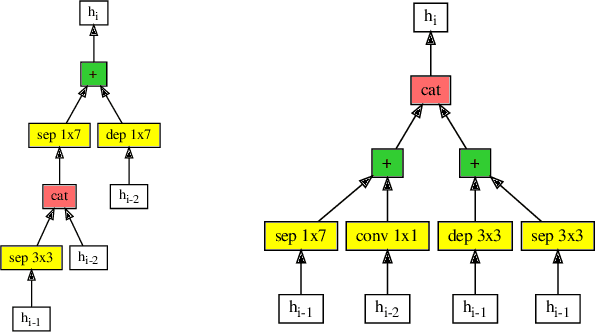

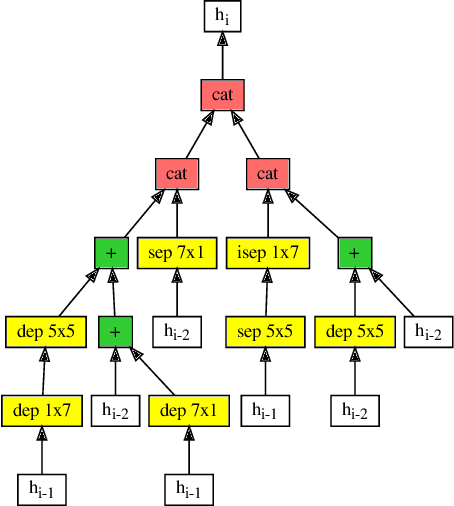
Efficient identification of people and objects, segmentation of regions of interest and extraction of relevant data in images, texts, audios and videos are evolving considerably in these past years, which deep learning methods, combined with recent improvements in computational resources, contributed greatly for this achievement. Although its outstanding potential, development of efficient architectures and modules requires expert knowledge and amount of resource time available. In this paper, we propose an evolutionary-based neural architecture search approach for efficient discovery of convolutional models in a dynamic search space, within only 24 GPU hours. With its efficient search environment and phenotype representation, Gene Expression Programming is adapted for network's cell generation. Despite having limited GPU resource time and broad search space, our proposal achieved similar state-of-the-art to manually-designed convolutional networks and also NAS-generated ones, even beating similar constrained evolutionary-based NAS works. The best cells in different runs achieved stable results, with a mean error of 2.82% in CIFAR-10 dataset (which the best model achieved an error of 2.67%) and 18.83% for CIFAR-100 (best model with 18.16%). For ImageNet in the mobile setting, our best model achieved top-1 and top-5 errors of 29.51% and 10.37%, respectively. Although evolutionary-based NAS works were reported to require a considerable amount of GPU time for architecture search, our approach obtained promising results in little time, encouraging further experiments in evolutionary-based NAS, for search and network representation improvements.
Deep learning approaches to Earth Observation change detection
Jul 13, 2021



The interest for change detection in the field of remote sensing has increased in the last few years. Searching for changes in satellite images has many useful applications, ranging from land cover and land use analysis to anomaly detection. In particular, urban change detection provides an efficient tool to study urban spread and growth through several years of observation. At the same time, change detection is often a computationally challenging and time-consuming task, which requires innovative methods to guarantee optimal results with unquestionable value and within reasonable time. In this paper we present two different approaches to change detection (semantic segmentation and classification) that both exploit convolutional neural networks to achieve good results, which can be further refined and used in a post-processing workflow for a large variety of applications.
Why don't people use character-level machine translation?
Oct 15, 2021
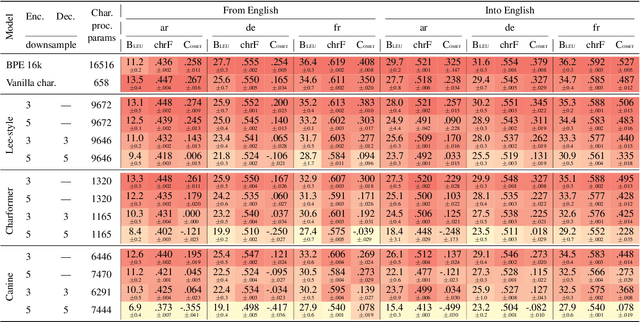
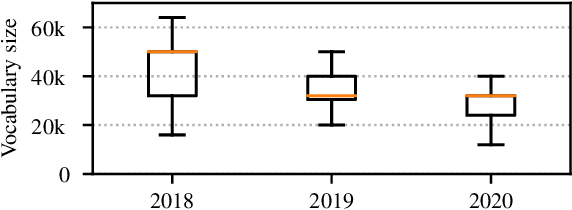
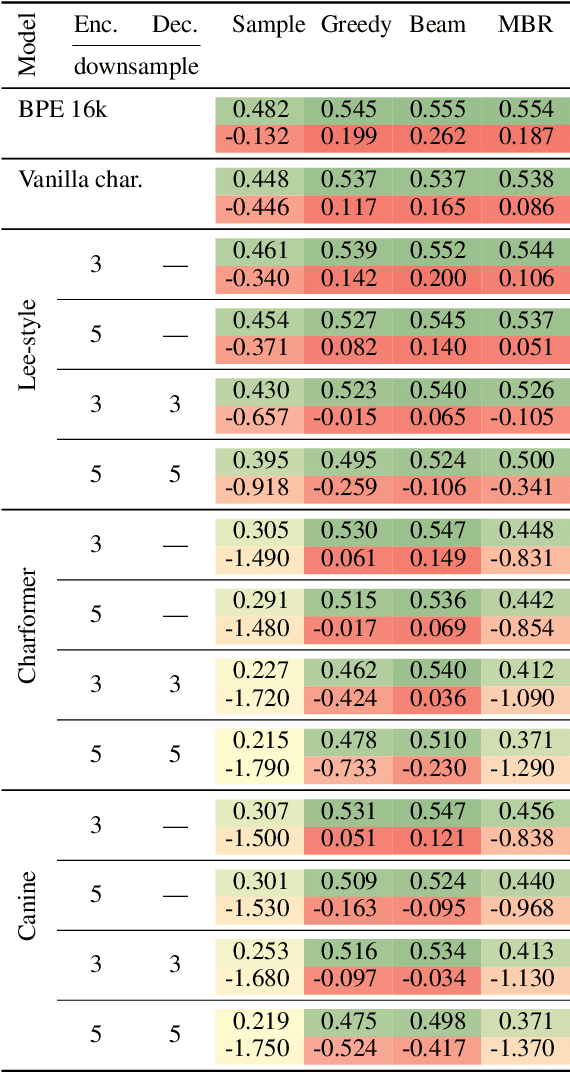
We present a literature and empirical survey that critically assesses the state of the art in character-level modeling for machine translation (MT). Despite evidence in the literature that character-level systems are comparable with subword systems, they are virtually never used in competitive setups in WMT competitions. We empirically show that even with recent modeling innovations in character-level natural language processing, character-level MT systems still struggle to match their subword-based counterparts both in terms of translation quality and training and inference speed. Character-level MT systems show neither better domain robustness, nor better morphological generalization, despite being often so motivated. On the other hand, they tend to be more robust towards source side noise and the translation quality does not degrade with increasing beam size at decoding time.
Deep Learning for Ultrasound Beamforming
Sep 23, 2021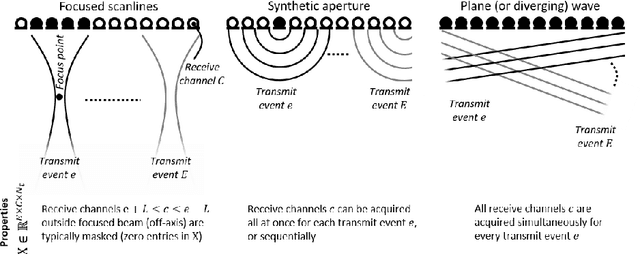

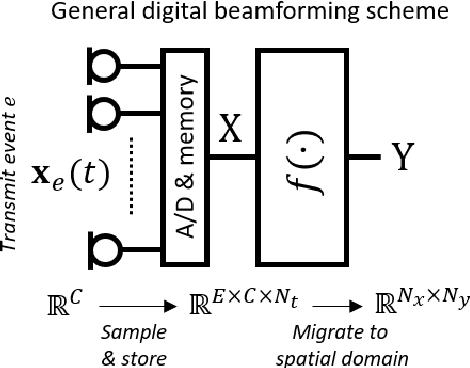
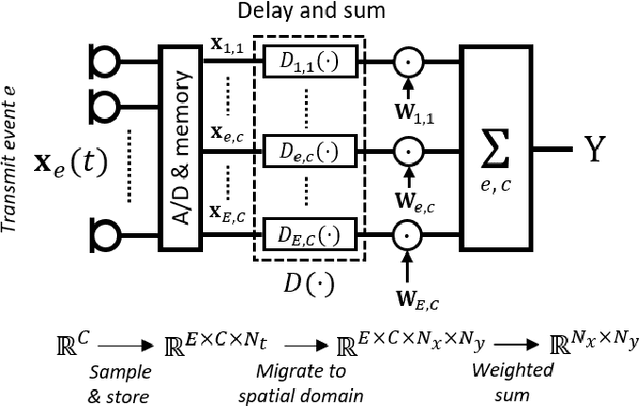
Diagnostic imaging plays a critical role in healthcare, serving as a fundamental asset for timely diagnosis, disease staging and management as well as for treatment choice, planning, guidance, and follow-up. Among the diagnostic imaging options, ultrasound imaging is uniquely positioned, being a highly cost-effective modality that offers the clinician an unmatched and invaluable level of interaction, enabled by its real-time nature. Ultrasound probes are becoming increasingly compact and portable, with the market demand for low-cost pocket-sized and (in-body) miniaturized devices expanding. At the same time, there is a strong trend towards 3D imaging and the use of high-frame-rate imaging schemes; both accompanied by dramatically increasing data rates that pose a heavy burden on the probe-system communication and subsequent image reconstruction algorithms. With the demand for high-quality image reconstruction and signal extraction from less (e.g unfocused or parallel) transmissions that facilitate fast imaging, and a push towards compact probes, modern ultrasound imaging leans heavily on innovations in powerful digital receive channel processing. Beamforming, the process of mapping received ultrasound echoes to the spatial image domain, naturally lies at the heart of the ultrasound image formation chain. In this chapter on Deep Learning for Ultrasound Beamforming, we discuss why and when deep learning methods can play a compelling role in the digital beamforming pipeline, and then show how these data-driven systems can be leveraged for improved ultrasound image reconstruction.
Flow Plugin Network for conditional generation
Oct 07, 2021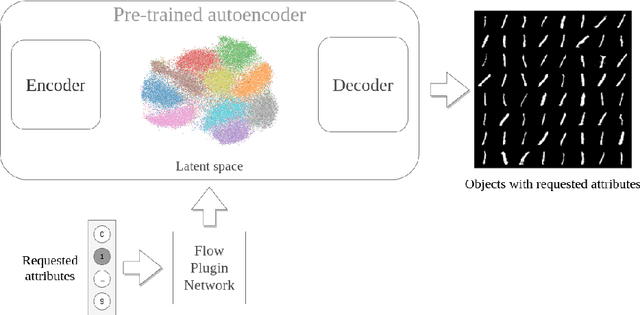
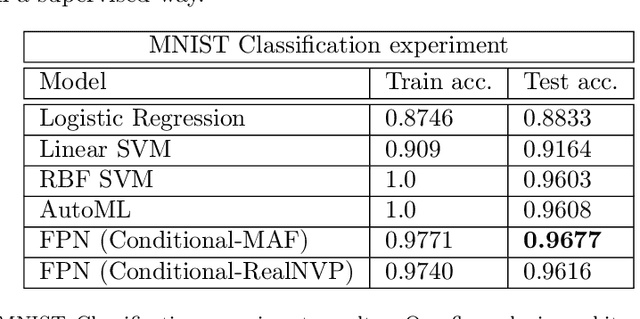
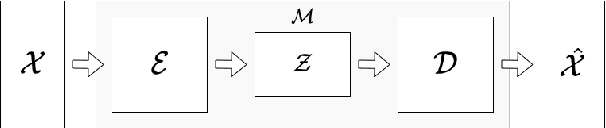
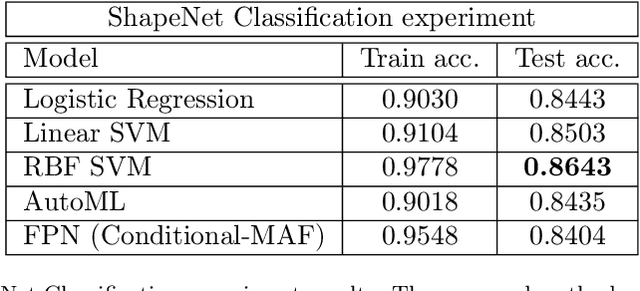
Generative models have gained many researchers' attention in the last years resulting in models such as StyleGAN for human face generation or PointFlow for the 3D point cloud generation. However, by default, we cannot control its sampling process, i.e., we cannot generate a sample with a specific set of attributes. The current approach is model retraining with additional inputs and different architecture, which requires time and computational resources. We propose a novel approach that enables to a generation of objects with a given set of attributes without retraining the base model. For this purpose, we utilize the normalizing flow models - Conditional Masked Autoregressive Flow and Conditional Real NVP, as a Flow Plugin Network (FPN).
Attention Guided Cosine Margin For Overcoming Class-Imbalance in Few-Shot Road Object Detection
Nov 12, 2021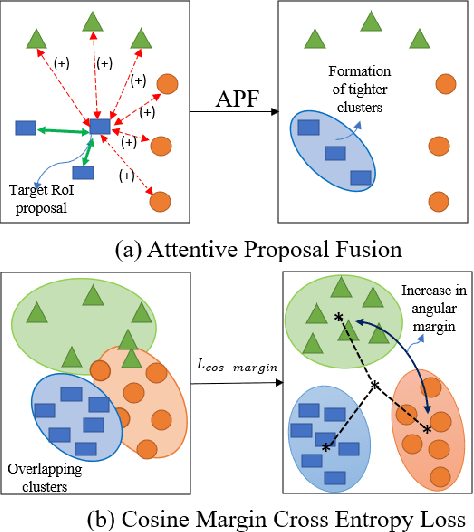
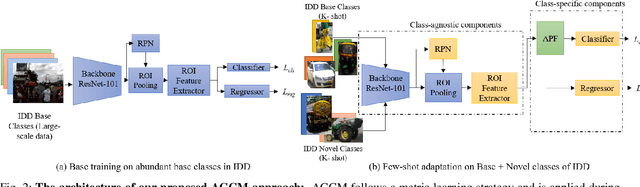
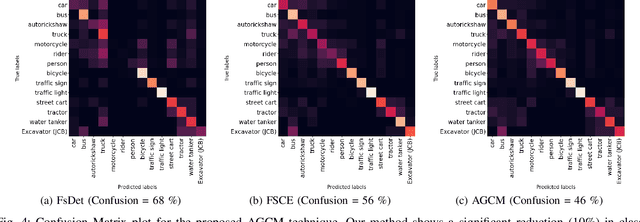
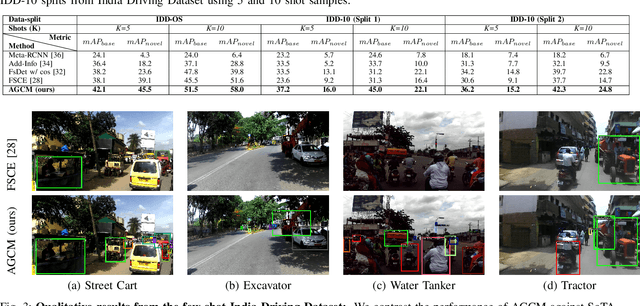
Few-shot object detection (FSOD) localizes and classifies objects in an image given only a few data samples. Recent trends in FSOD research show the adoption of metric and meta-learning techniques, which are prone to catastrophic forgetting and class confusion. To overcome these pitfalls in metric learning based FSOD techniques, we introduce Attention Guided Cosine Margin (AGCM) that facilitates the creation of tighter and well separated class-specific feature clusters in the classification head of the object detector. Our novel Attentive Proposal Fusion (APF) module minimizes catastrophic forgetting by reducing the intra-class variance among co-occurring classes. At the same time, the proposed Cosine Margin Cross-Entropy loss increases the angular margin between confusing classes to overcome the challenge of class confusion between already learned (base) and newly added (novel) classes. We conduct our experiments on the challenging India Driving Dataset (IDD), which presents a real-world class-imbalanced setting alongside popular FSOD benchmark PASCAL-VOC. Our method outperforms State-of-the-Art (SoTA) approaches by up to 6.4 mAP points on the IDD-OS and up to 2.0 mAP points on the IDD-10 splits for the 10-shot setting. On the PASCAL-VOC dataset, we outperform existing SoTA approaches by up to 4.9 mAP points.
Towards Toxic and Narcotic Medication Detection with Rotated Object Detector
Oct 19, 2021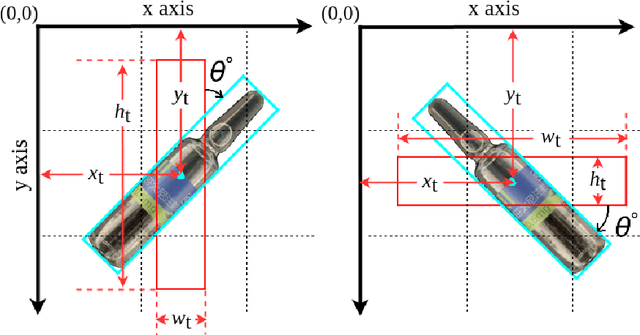

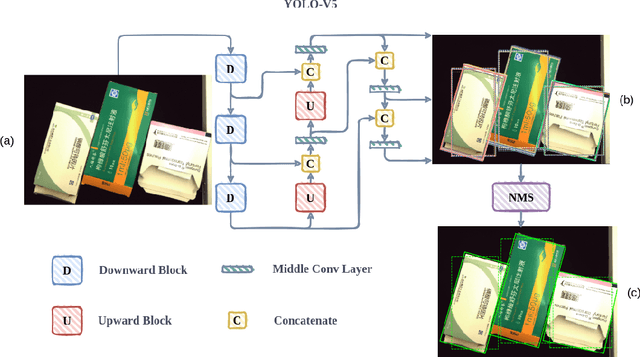
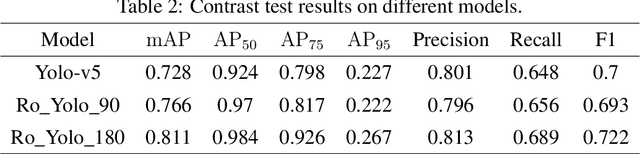
Recent years have witnessed the advancement of deep learning vision technologies and applications in the medical industry. Intelligent devices for special medication management are in great need of, which requires more precise detection algorithms to identify the specifications and locations. In this work, YOLO (You only look once) based object detectors are tailored for toxic and narcotic medications detection tasks. Specifically, a more flexible annotation with rotated degree ranging from $0^\circ$ to $90^\circ$ and a mask-mapping-based non-maximum suppression method are proposed to achieve a feasible and efficient medication detector aiming at arbitrarily oriented bounding boxes. Extensive experiments demonstrate that the rotated YOLO detectors are more suitable for identifying densely arranged drugs. The best shot mean average precision of the proposed network reaches 0.811 while the inference time is less than 300ms.
Multi-label Classification of Aircraft Heading Changes Using Neural Network to Resolve Conflicts
Sep 18, 2021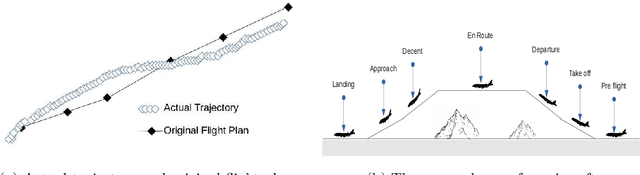

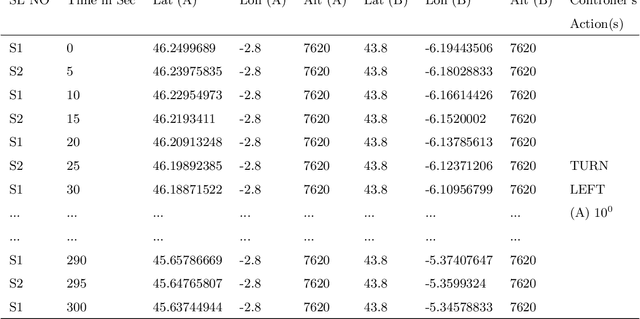
An aircraft conflict occurs when two or more aircraft cross at a certain distance at the same time. Specific air traffic controllers are assigned to solve such conflicts. A controller needs to consider various types of information in order to solve a conflict. The most common and preliminary information is the coordinate position of the involved aircraft. Additionally, a controller has to take into account more information such as flight planning, weather, restricted territory, etc. The most important challenges a controller has to face are: to think about the issues involved and make a decision in a very short time. Due to the increased number of aircraft, it is crucial to reduce the workload of the controllers and help them make quick decisions. A conflict can be solved in many ways, therefore, we consider this problem as a multi-label classification problem. In doing so, we are proposing a multi-label classification model which provides multiple heading advisories for a given conflict. This model we named CRMLnet is based on a novel application of a multi-layer neural network and helps the controllers in their decisions. When compared to other machine learning models, our CRMLnet has achieved the best results with an accuracy of 98.72% and ROC of 0.999. The simulated data set that we have developed and used in our experiments will be delivered to the research community.
CPPNet: A Coverage Path Planning Network
Aug 03, 2021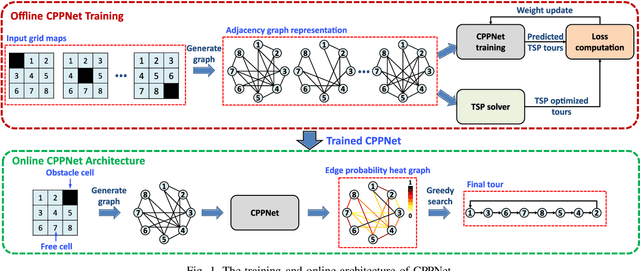
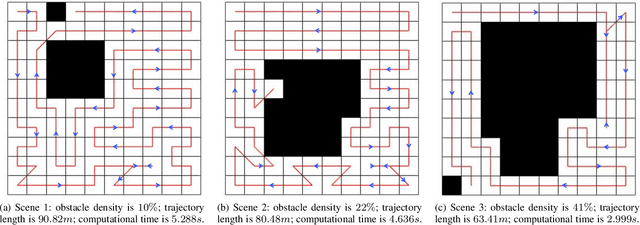
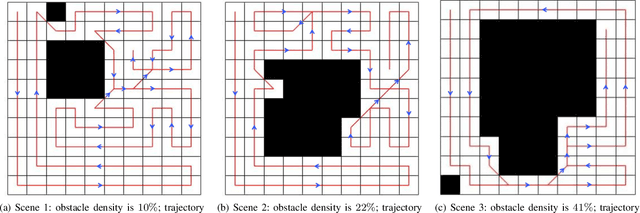
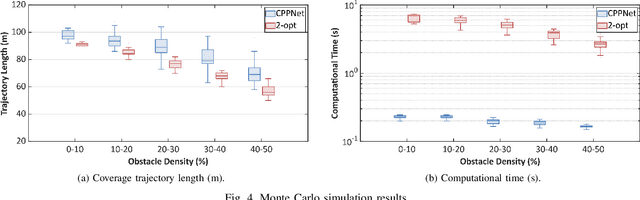
This paper presents a deep-learning based CPP algorithm, called Coverage Path Planning Network (CPPNet). CPPNet is built using a convolutional neural network (CNN) whose input is a graph-based representation of the occupancy grid map while its output is an edge probability heat graph, where the value of each edge is the probability of belonging to the optimal TSP tour. Finally, a greedy search is used to select the final optimized tour. CPPNet is trained and comparatively evaluated against the TSP tour. It is shown that CPPNet provides near-optimal solutions while requiring significantly less computational time, thus enabling real-time coverage path planning in partially unknown and dynamic environments.
Contextual Combinatorial Volatile Bandits with Satisfying via Gaussian Processes
Nov 29, 2021
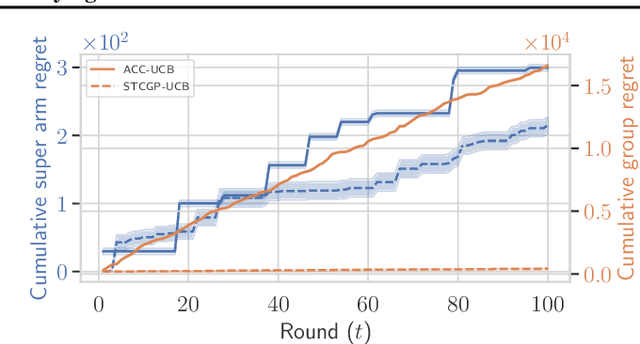
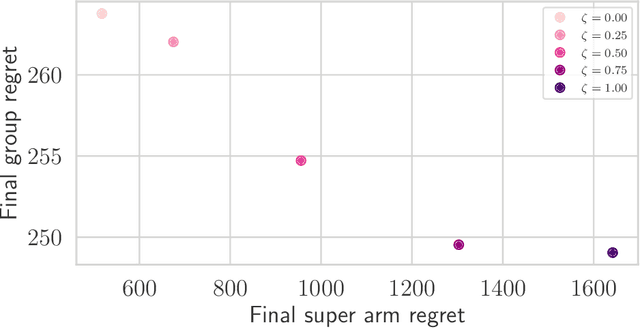
In many real-world applications of combinatorial bandits such as content caching, rewards must be maximized while satisfying minimum service requirements. In addition, base arm availabilities vary over time, and actions need to be adapted to the situation to maximize the rewards. We propose a new bandit model called Contextual Combinatorial Volatile Bandits with Group Thresholds to address these challenges. Our model subsumes combinatorial bandits by considering super arms to be subsets of groups of base arms. We seek to maximize super arm rewards while satisfying thresholds of all base arm groups that constitute a super arm. To this end, we define a new notion of regret that merges super arm reward maximization with group reward satisfaction. To facilitate learning, we assume that the mean outcomes of base arms are samples from a Gaussian Process indexed by the context set ${\cal X}$, and the expected reward is Lipschitz continuous in expected base arm outcomes. We propose an algorithm, called Thresholded Combinatorial Gaussian Process Upper Confidence Bounds (TCGP-UCB), that balances between maximizing cumulative reward and satisfying group reward thresholds and prove that it incurs $\tilde{O}(K\sqrt{T\overline{\gamma}_{T}} )$ regret with high probability, where $\overline{\gamma}_{T}$ is the maximum information gain associated with the set of base arm contexts that appeared in the first $T$ rounds and $K$ is the maximum super arm cardinality of any feasible action over all rounds. We show in experiments that our algorithm accumulates a reward comparable with that of the state-of-the-art combinatorial bandit algorithm while picking actions whose groups satisfy their thresholds.