 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
SRDCNN: Strongly Regularized Deep Convolution Neural Network Architecture for Time-series Sensor Signal Classification Tasks
Jul 14, 2020
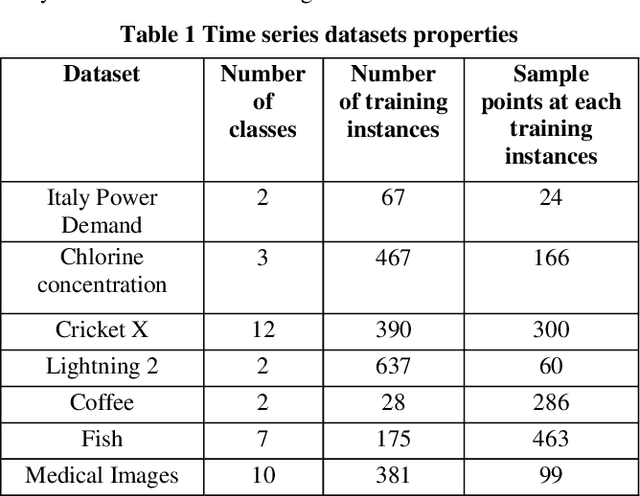


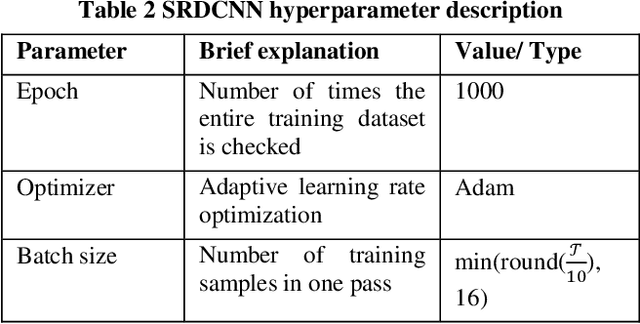
Deep Neural Networks (DNN) have been successfully used to perform classification and regression tasks, particularly in computer vision based applications. Recently, owing to the widespread deployment of Internet of Things (IoT), we identify that the classification tasks for time series data, specifically from different sensors are of utmost importance. In this paper, we present SRDCNN: Strongly Regularized Deep Convolution Neural Network (DCNN) based deep architecture to perform time series classification tasks. The novelty of the proposed approach is that the network weights are regularized by both L1 and L2 norm penalties. Both of the regularization approaches jointly address the practical issues of smaller number of training instances, requirement of quicker training process, avoiding overfitting problem by incorporating sparsification of weight vectors as well as through controlling of weight values. We compare the proposed method (SRDCNN) with relevant state-of-the-art algorithms including different DNNs using publicly available time series classification benchmark (the UCR/UEA archive) time series datasets and demonstrate that the proposed method provides superior performance. We feel that SRDCNN warrants better generalization capability to the deep architecture by profoundly controlling the network parameters to combat the training instance insufficiency problem of real-life time series sensor signals.
Tensor Recovery Based on Tensor Equivalent Minimax-Concave Penalty
Jan 30, 2022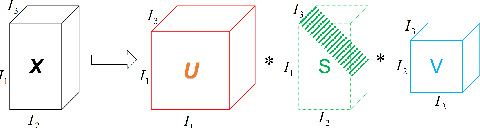

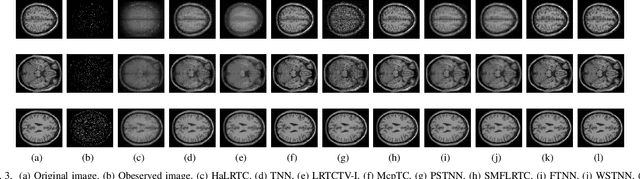

Tensor recovery is an important problem in computer vision and machine learning. It usually uses the convex relaxation of tensor rank and $l_{0}$ norm, i.e., the nuclear norm and $l_{1}$ norm respectively, to solve the problem. It is well known that convex approximations produce biased estimators. In order to overcome this problem, a corresponding non-convex regularizer has been proposed to solve it. Inspired by matrix equivalent Minimax-Concave Penalty (EMCP), we propose and prove theorems of tensor equivalent Minimax-Concave Penalty (TEMCP). The tensor equivalent MCP (TEMCP) as a non-convex regularizer and the equivalent weighted tensor $\gamma$ norm (EWTGN) which can represent the low-rank part are obtained. Both of them can realize weight adaptive. At the same time, we propose two corresponding adaptive models for two classical tensor recovery problems, low-rank tensor completion (LRTC) and tensor robust principal component analysis (TRPCA), and the optimization algorithm is based on alternating direction multiplier (ADMM). This novel iterative adaptive algorithm can produce more accurate tensor recovery effect. For the tensor completion model, multispectral image (MSI), magnetic resonance imaging (MRI) and color video (CV) data sets are considered, while for the tensor robust principal component analysis model, hyperspectral image (HSI) denoising under gaussian noise plus salt and pepper noise is considered. The proposed algorithm is superior to the state-of-arts method, and the algorithm is guaranteed to meet the reduction and convergence through experiments.
Automatic Segmentation of Head and Neck Tumor: How Powerful Transformers Are?
Jan 17, 2022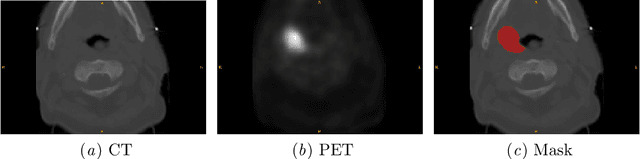

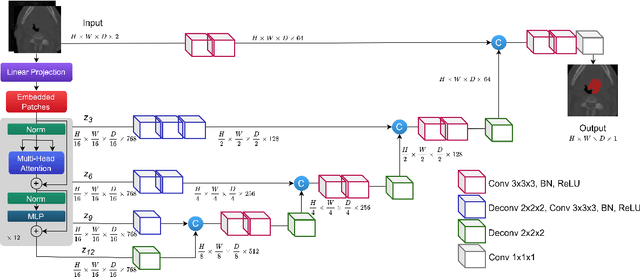
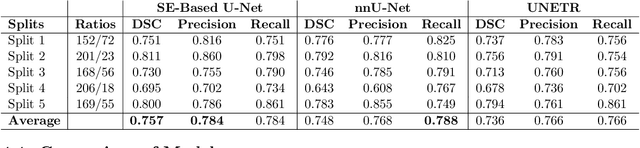
Cancer is one of the leading causes of death worldwide, and head and neck (H&N) cancer is amongst the most prevalent types. Positron emission tomography and computed tomography are used to detect and segment the tumor region. Clinically, tumor segmentation is extensively time-consuming and prone to error. Machine learning, and deep learning in particular, can assist to automate this process, yielding results as accurate as the results of a clinician. In this research study, we develop a vision transformers-based method to automatically delineate H&N tumor, and compare its results to leading convolutional neural network (CNN)-based models. We use multi-modal data of CT and PET scans to do this task. We show that the selected transformer-based model can achieve results on a par with CNN-based ones. With cross validation, the model achieves a mean dice similarity coefficient of 0.736, mean precision of 0.766 and mean recall of 0.766. This is only 0.021 less than the 2020 competition winning model in terms of the DSC score. This indicates that the exploration of transformer-based models is a promising research area.
Safeguarding test signals for acoustic measurement using arbitrary sounds
Dec 21, 2021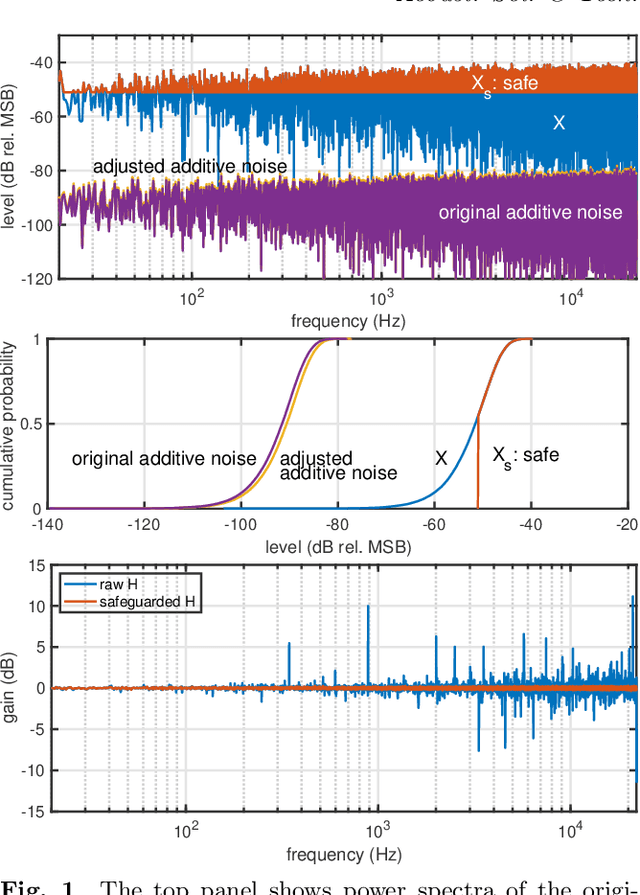
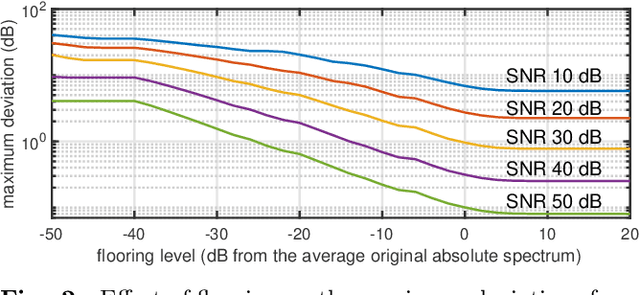
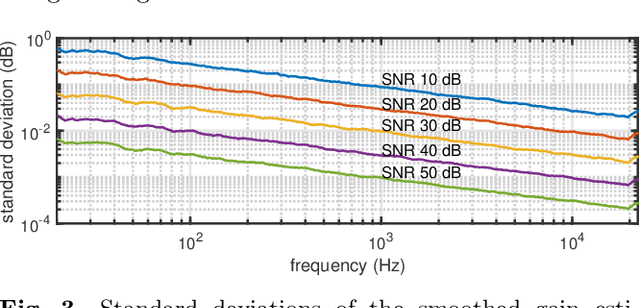
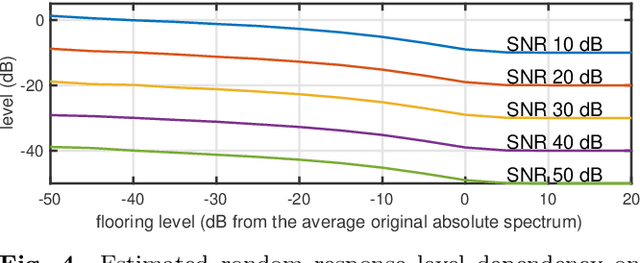
We propose a simple method to measure acoustic responses using any sounds by converting them suitable for measurement. This method enables us to use music pieces for measuring acoustic conditions. It is advantageous to measure such conditions without annoying test sounds to listeners. In addition, applying the underlying idea of simultaneous measurement of multiple paths provides practically valuable features. For example, it is possible to measure deviations (temporally stable, random, and time-varying) and the impulse response while reproducing slightly modified contents under target conditions. The key idea of the proposed method is to add relatively small deterministic signals that sound like noise to the original sounds. We call the converted sounds safeguarded test signals.
WiSig: A Large-Scale WiFi Signal Dataset for Receiver and Channel Agnostic RF Fingerprinting
Jan 12, 2022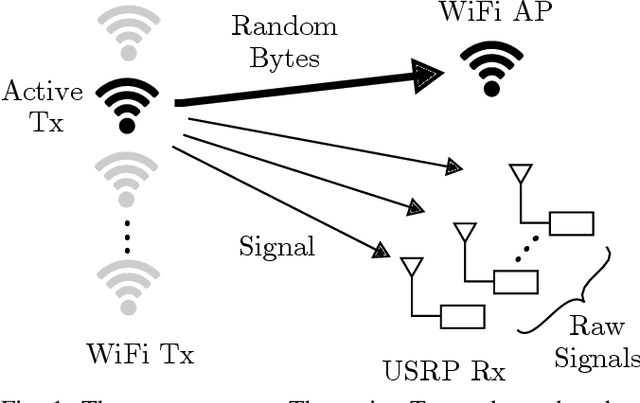
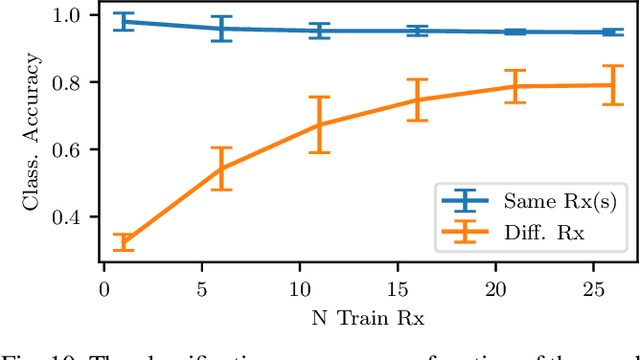
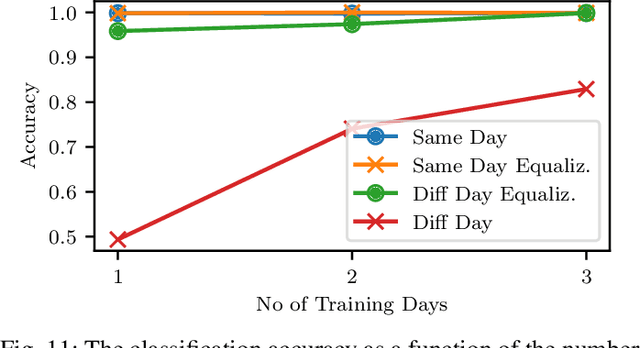
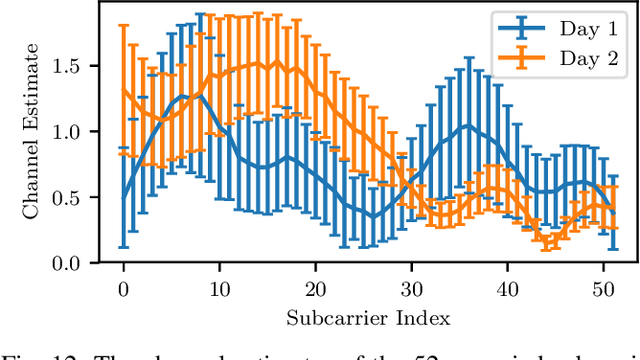
RF fingerprinting leverages circuit-level variability of transmitters to identify them using signals they send. Signals used for identification are impacted by a wireless channel and receiver circuitry, creating additional impairments that can confuse transmitter identification. Eliminating these impairments or just evaluating them, requires data captured over a prolonged period of time, using many spatially separated transmitters and receivers. In this paper, we present WiSig; a large scale WiFi dataset containing 10 million packets captured from 174 off-the-shelf WiFi transmitters and 41 USRP receivers over 4 captures spanning a month. WiSig is publicly available, not just as raw captures, but as conveniently pre-processed subsets of limited size, along with the scripts and examples. A preliminary evaluation performed using WiSig shows that changing receivers, or using signals captured on a different day can significantly degrade a trained classifier's performance. While capturing data over more days or more receivers limits the degradation, it is not always feasible and novel data-driven approaches are needed. WiSig provides the data to develop and evaluate these approaches towards channel and receiver agnostic transmitter fingerprinting.
Efficient DNN Training with Knowledge-Guided Layer Freezing
Jan 17, 2022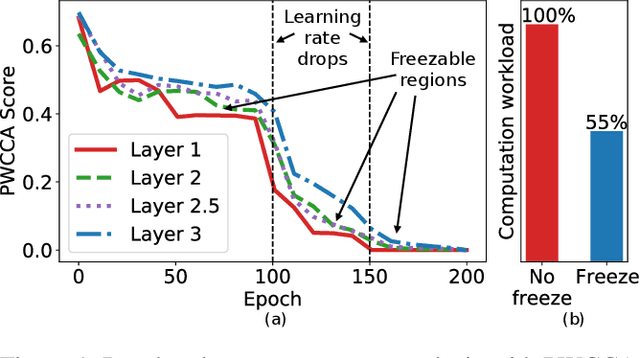
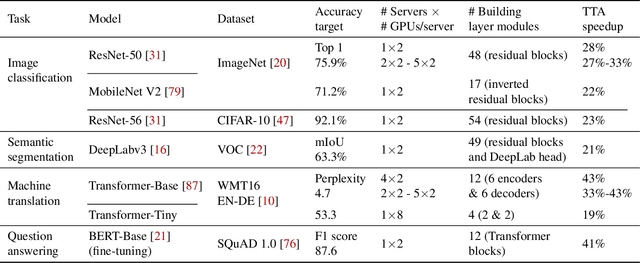
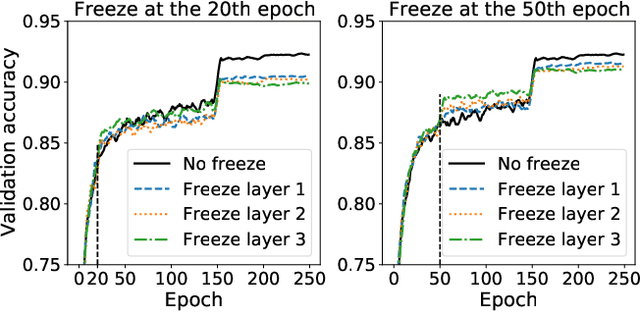
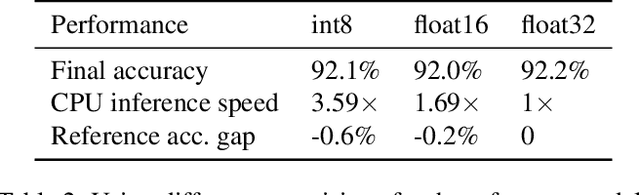
Training deep neural networks (DNNs) is time-consuming. While most existing solutions try to overlap/schedule computation and communication for efficient training, this paper goes one step further by skipping computing and communication through DNN layer freezing. Our key insight is that the training progress of internal DNN layers differs significantly, and front layers often become well-trained much earlier than deep layers. To explore this, we first introduce the notion of training plasticity to quantify the training progress of internal DNN layers. Then we design KGT, a knowledge-guided DNN training system that employs semantic knowledge from a reference model to accurately evaluate individual layers' training plasticity and safely freeze the converged ones, saving their corresponding backward computation and communication. Our reference model is generated on the fly using quantization techniques and runs forward operations asynchronously on available CPUs to minimize the overhead. In addition, KGT caches the intermediate outputs of the frozen layers with prefetching to further skip the forward computation. Our implementation and testbed experiments with popular vision and language models show that KGT achieves 19%-43% training speedup w.r.t. the state-of-the-art without sacrificing accuracy.
It's Time to Play Safe: Shield Synthesis for Timed Systems
Jun 30, 2020
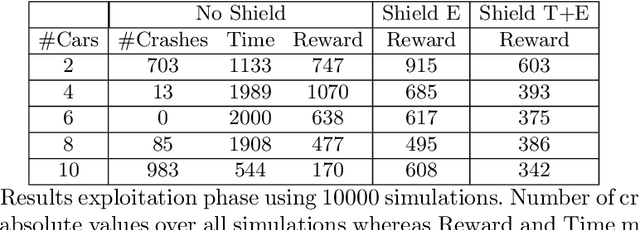
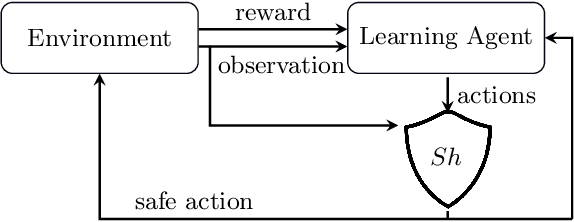
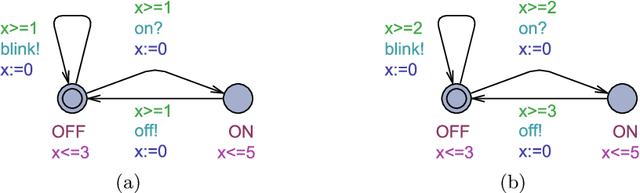
Erroneous behaviour in safety critical real-time systems may inflict serious consequences. In this paper, we show how to synthesize timed shields from timed safety properties given as timed automata. A timed shield enforces the safety of a running system while interfering with the system as little as possible. We present timed post-shields and timed pre-shields. A timed pre-shield is placed before the system and provides a set of safe outputs. This set restricts the choices of the system. A timed post-shield is implemented after the system. It monitors the system and corrects the system's output only if necessary. We further extend the timed post-shield construction to provide a guarantee on the recovery phase, i.e., the time between a specification violation and the point at which full control can be handed back to the system. In our experimental results, we use timed post-shields to ensure the safety in a reinforcement learning setting for controlling a platoon of cars, during the learning and execution phase, and study the effect.
Language Models Explain Word Reading Times Better Than Empirical Predictability
Feb 02, 2022
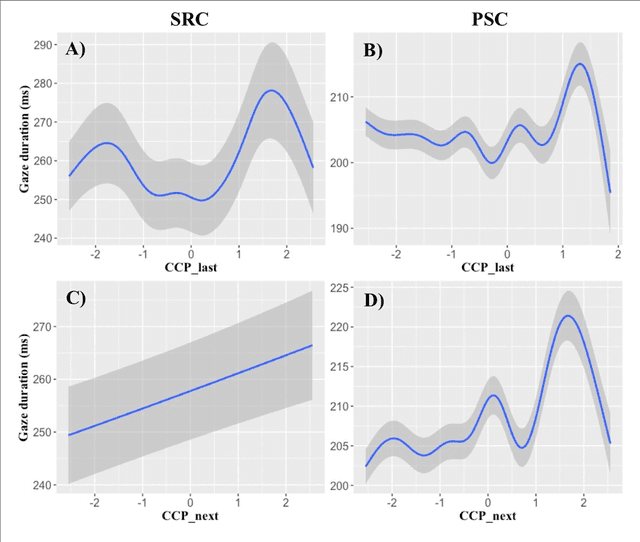
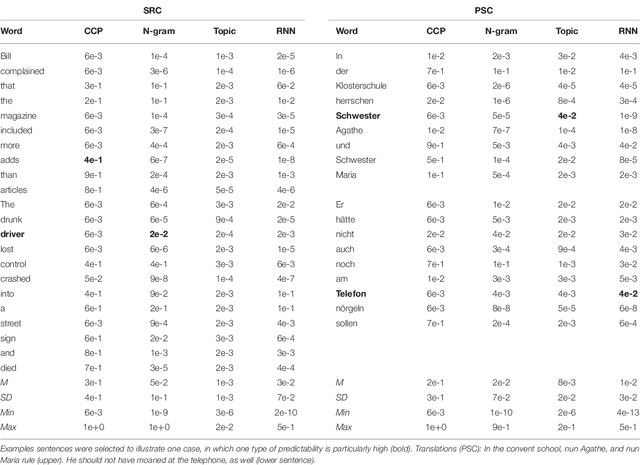
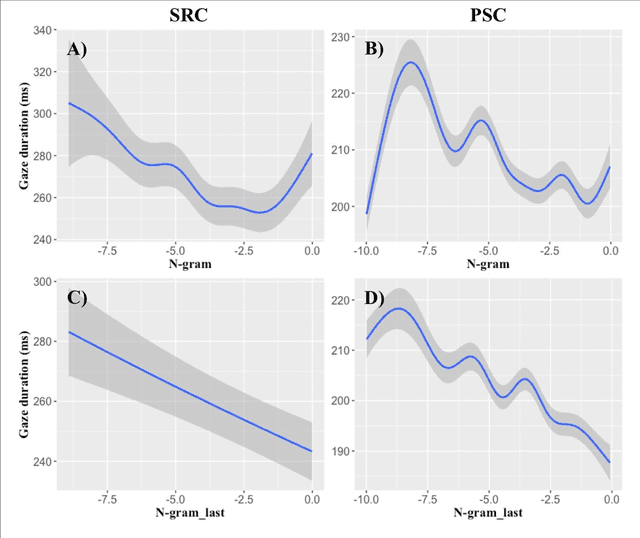
Though there is a strong consensus that word length and frequency are the most important single-word features determining visual-orthographic access to the mental lexicon, there is less agreement as how to best capture syntactic and semantic factors. The traditional approach in cognitive reading research assumes that word predictability from sentence context is best captured by cloze completion probability (CCP) derived from human performance data. We review recent research suggesting that probabilistic language models provide deeper explanations for syntactic and semantic effects than CCP. Then we compare CCP with (1) Symbolic n-gram models consolidate syntactic and semantic short-range relations by computing the probability of a word to occur, given two preceding words. (2) Topic models rely on subsymbolic representations to capture long-range semantic similarity by word co-occurrence counts in documents. (3) In recurrent neural networks (RNNs), the subsymbolic units are trained to predict the next word, given all preceding words in the sentences. To examine lexical retrieval, these models were used to predict single fixation durations and gaze durations to capture rapidly successful and standard lexical access, and total viewing time to capture late semantic integration. The linear item-level analyses showed greater correlations of all language models with all eye-movement measures than CCP. Then we examined non-linear relations between the different types of predictability and the reading times using generalized additive models. N-gram and RNN probabilities of the present word more consistently predicted reading performance compared with topic models or CCP.
Integrated Time Series Summarization and Prediction Algorithm and its Application to COVID-19 Data Mining
May 01, 2020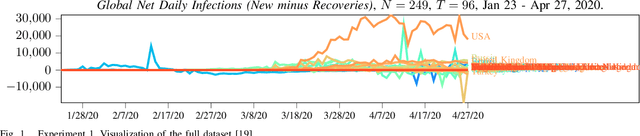
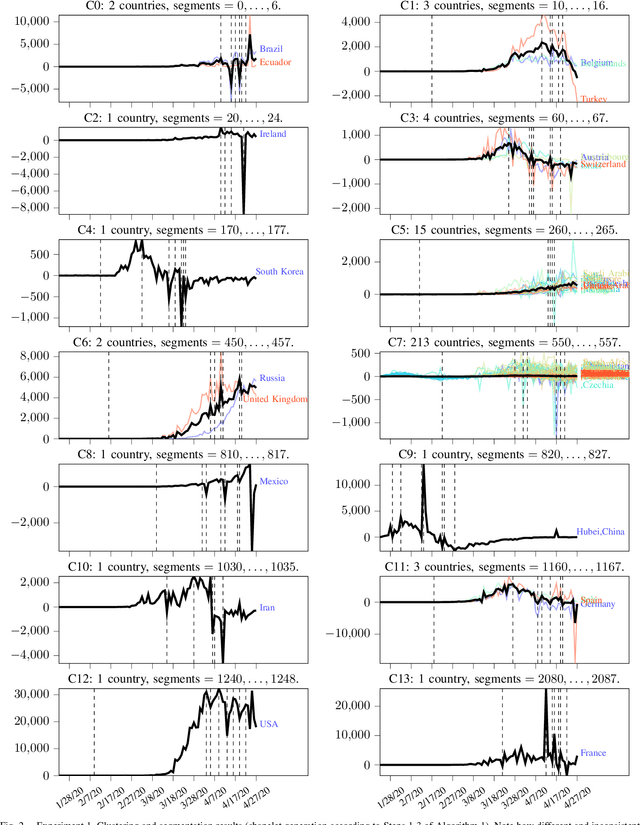
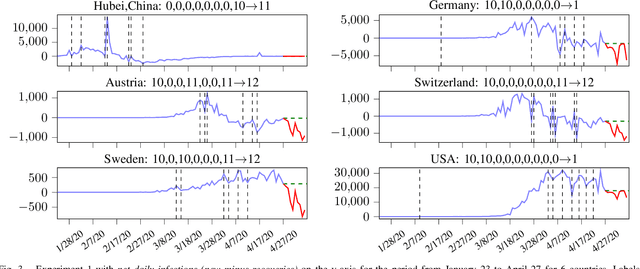
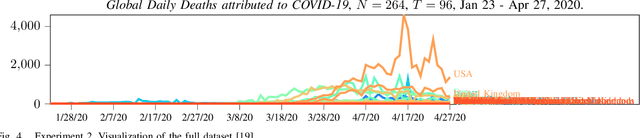
This paper proposes a simple method to extract from a set of multiple related time series a compressed representation for each time series based on statistics for the entire set of all time series. This is achieved by a hierarchical algorithm that first generates an alphabet of shapelets based on the segmentation of centroids for clustered data, before labels of these shapelets are assigned to the segmentation of each single time series via nearest neighbor search using unconstrained dynamic time warping as distance measure to deal with non-uniform time series lenghts. Thereby, a sequence of labels is assigned for each time series. Completion of the last label sequence permits prediction of individual time series. Proposed method is evaluated on two global COVID-19 datasets, first, for the number of daily net cases (daily new infections minus daily recoveries), and, second, for the number of daily deaths attributed to COVID-19 as of April 27, 2020. The first dataset involves 249 time series for different countries, each of length 96. The second dataset involves 264 time series, each of length 96. Based on detected anomalies in available data a decentralized exit strategy from lockdowns is advocated.
Occupancy Information Ratio: Infinite-Horizon, Information-Directed, Parameterized Policy Search
Jan 21, 2022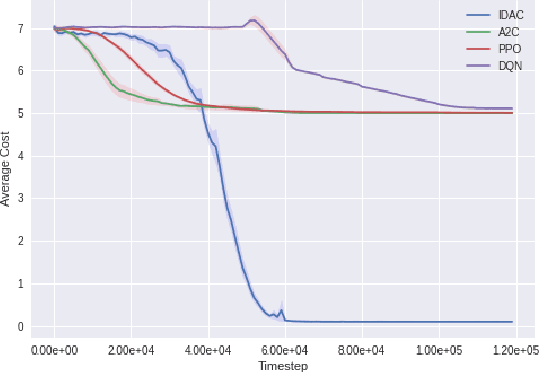
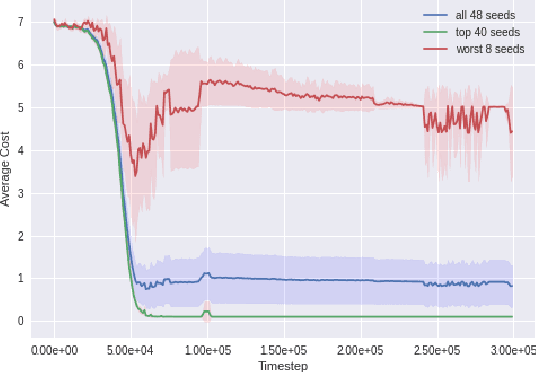
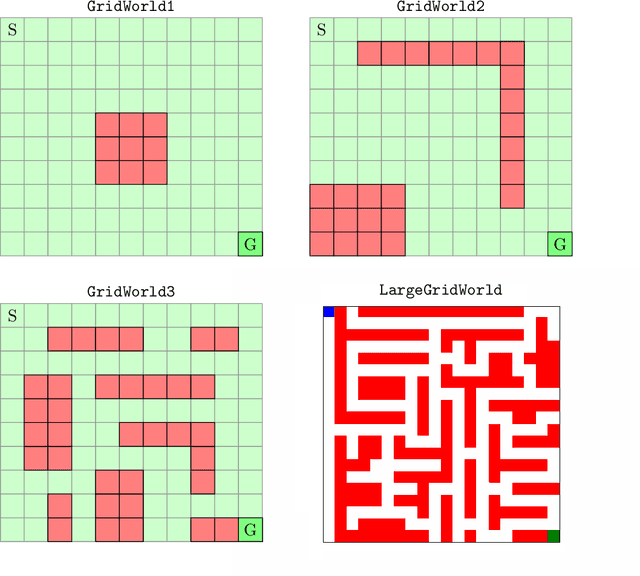
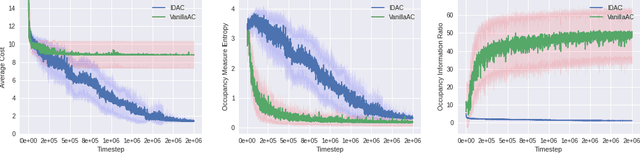
We develop a new measure of the exploration/exploitation trade-off in infinite-horizon reinforcement learning problems called the occupancy information ratio (OIR), which is comprised of a ratio between the infinite-horizon average cost of a policy and the entropy of its long-term state occupancy measure. The OIR ensures that no matter how many trajectories an RL agent traverses or how well it learns to minimize cost, it maintains a healthy skepticism about its environment, in that it defines an optimal policy which induces a high-entropy occupancy measure. Different from earlier information ratio notions, OIR is amenable to direct policy search over parameterized families, and exhibits hidden quasiconcavity through invocation of the perspective transformation. This feature ensures that under appropriate policy parameterizations, the OIR optimization problem has no spurious stationary points, despite the overall problem's nonconvexity. We develop for the first time policy gradient and actor-critic algorithms for OIR optimization based upon a new entropy gradient theorem, and establish both asymptotic and non-asymptotic convergence results with global optimality guarantees. In experiments, these methodologies outperform several deep RL baselines in problems with sparse rewards, where many trajectories may be uninformative and skepticism about the environment is crucial to success.