 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Logical Reasoning for Task Oriented Dialogue Systems
Feb 08, 2022
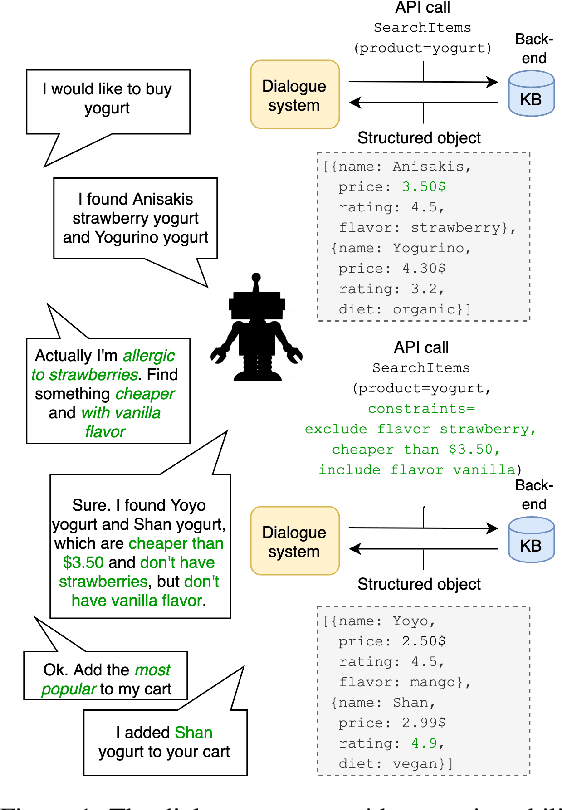

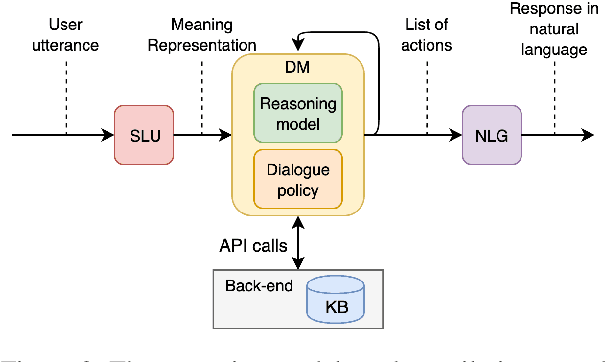

In recent years, large pretrained models have been used in dialogue systems to improve successful task completion rates. However, lack of reasoning capabilities of dialogue platforms make it difficult to provide relevant and fluent responses, unless the designers of a conversational experience spend a considerable amount of time implementing these capabilities in external rule based modules. In this work, we propose a novel method to fine-tune pretrained transformer models such as Roberta and T5. to reason over a set of facts in a given dialogue context. Our method includes a synthetic data generation mechanism which helps the model learn logical relations, such as comparison between list of numerical values, inverse relations (and negation), inclusion and exclusion for categorical attributes, and application of a combination of attributes over both numerical and categorical values, and spoken form for numerical values, without need for additional training dataset. We show that the transformer based model can perform logical reasoning to answer questions when the dialogue context contains all the required information, otherwise it is able to extract appropriate constraints to pass to downstream components (e.g. a knowledge base) when partial information is available. We observe that transformer based models such as UnifiedQA-T5 can be fine-tuned to perform logical reasoning (such as numerical and categorical attributes' comparison) over attributes that been seen in training time (e.g., accuracy of 90\%+ for comparison of smaller than $k_{\max}$=5 values over heldout test dataset).
"If you could see me through my eyes": Predicting Pedestrian Perception
Feb 28, 2022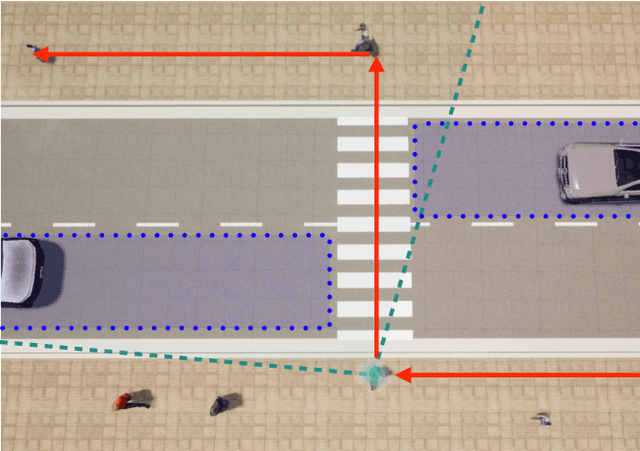
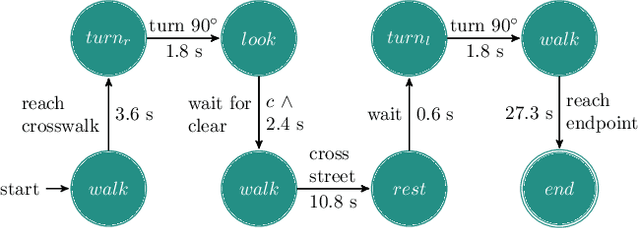
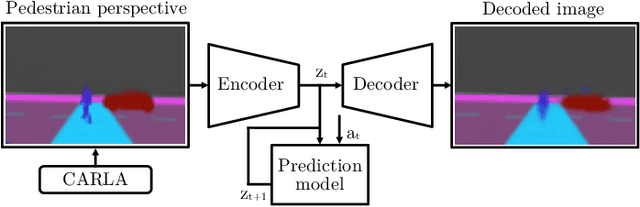

Pedestrians are particularly vulnerable road users in urban traffic. With the arrival of autonomous driving, novel technologies can be developed specifically to protect pedestrians. We propose a~machine learning toolchain to train artificial neural networks as models of pedestrian behavior. In a~preliminary study, we use synthetic data from simulations of a~specific pedestrian crossing scenario to train a~variational autoencoder and a~long short-term memory network to predict a~pedestrian's future visual perception. We can accurately predict a~pedestrian's future perceptions within relevant time horizons. By iteratively feeding these predicted frames into these networks, they can be used as simulations of pedestrians as indicated by our results. Such trained networks can later be used to predict pedestrian behaviors even from the perspective of the autonomous car. Another future extension will be to re-train these networks with real-world video data.
A Compact Deep Architecture for Real-time Saliency Prediction
Aug 30, 2020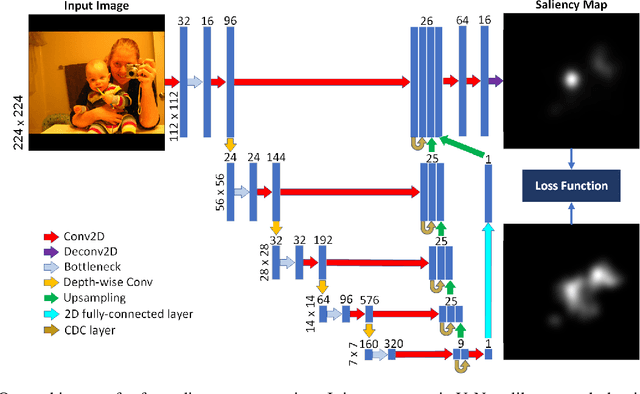

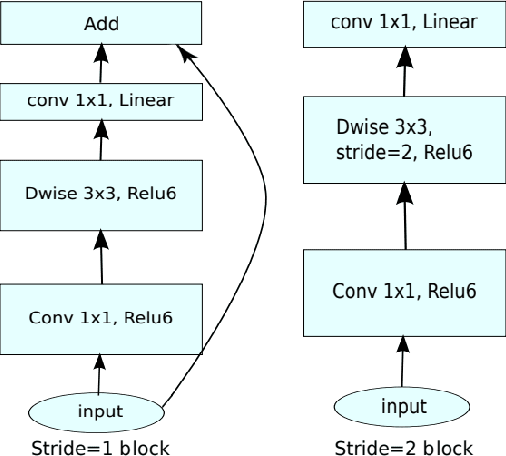
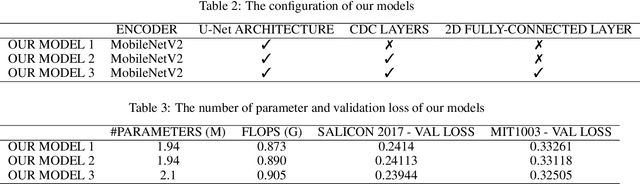
Saliency computation models aim to imitate the attention mechanism in the human visual system. The application of deep neural networks for saliency prediction has led to a drastic improvement over the last few years. However, deep models have a high number of parameters which makes them less suitable for real-time applications. Here we propose a compact yet fast model for real-time saliency prediction. Our proposed model consists of a modified U-net architecture, a novel fully connected layer, and central difference convolutional layers. The modified U-Net architecture promotes compactness and efficiency. The novel fully-connected layer facilitates the implicit capturing of the location-dependent information. Using the central difference convolutional layers at different scales enables capturing more robust and biologically motivated features. We compare our model with state of the art saliency models using traditional saliency scores as well as our newly devised scheme. Experimental results over four challenging saliency benchmark datasets demonstrate the effectiveness of our approach in striking a balance between accuracy and speed. Our model can be run in real-time which makes it appealing for edge devices and video processing.
GANTL: Towards Practical and Real-Time Topology Optimization with Conditional GANs and Transfer Learning
May 07, 2021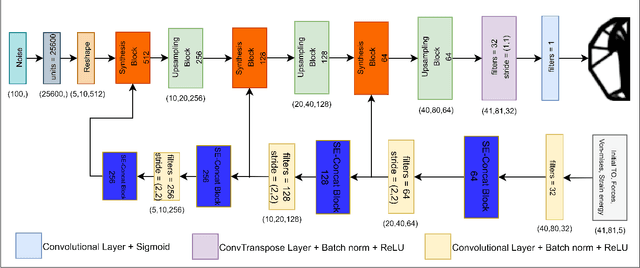
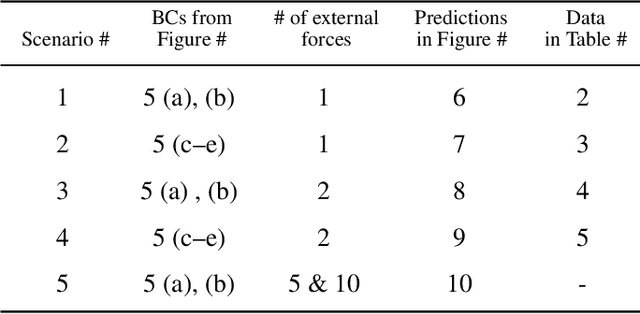
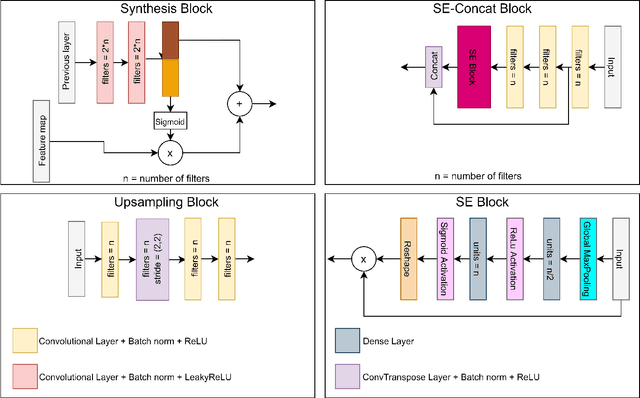
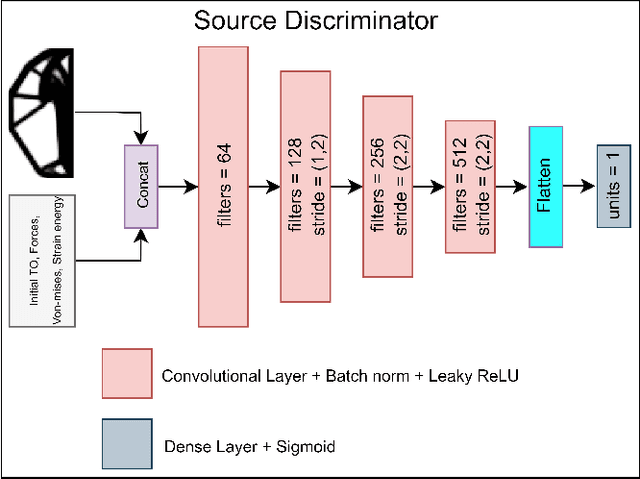
Many machine learning methods have been recently developed to circumvent the high computational cost of the gradient-based topology optimization. These methods typically require extensive and costly datasets for training, have a difficult time generalizing to unseen boundary and loading conditions and to new domains, and do not take into consideration topological constraints of the predictions, which produces predictions with inconsistent topologies. We present a deep learning method based on generative adversarial networks for generative design exploration. The proposed method combines the generative power of conditional GANs with the knowledge transfer capabilities of transfer learning methods to predict optimal topologies for unseen boundary conditions. We also show that the knowledge transfer capabilities embedded in the design of the proposed algorithm significantly reduces the size of the training dataset compared to the traditional deep learning neural or adversarial networks. Moreover, we formulate a topological loss function based on the bottleneck distance obtained from the persistent diagram of the structures and demonstrate a significant improvement in the topological connectivity of the predicted structures. We use numerous examples to explore the efficiency and accuracy of the proposed approach for both seen and unseen boundary conditions in 2D.
Language Generation for Broad-Coverage, Explainable Cognitive Systems
Jan 25, 2022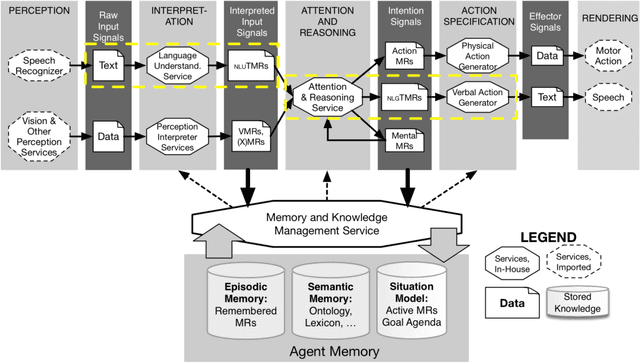

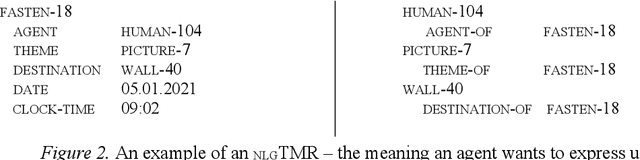

This paper describes recent progress on natural language generation (NLG) for language-endowed intelligent agents (LEIAs) developed within the OntoAgent cognitive architecture. The approach draws heavily from past work on natural language understanding in this paradigm: it uses the same knowledge bases, theory of computational linguistics, agent architecture, and methodology of developing broad-coverage capabilities over time while still supporting near-term applications.
Time-of-Flight LiDAR-based Precise Mapping
Sep 21, 2020Last two decades, the problem of robotic mapping has made a lot of progress in the research community. However, since the data provided by the sensor still contains noise, how to obtain an accurate map is still an open problem. In this note, we analyze the problem from the perspective of mathematical analysis and propose a probabilistic map update method based on multiple explorations. The proposed method can help us estimate the number of rounds of robot exploration, which is meaningful for the hardware and time costs of the task.
Predicting the probability distribution of bus travel time to move towards reliable planning of public transport services
Feb 03, 2021
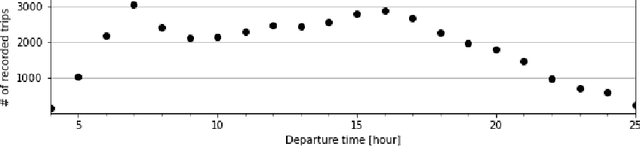
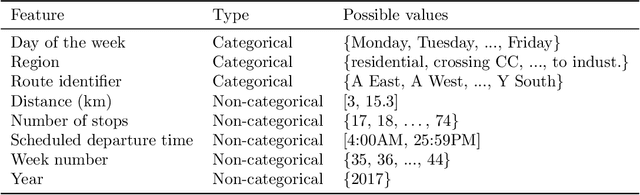
An important aspect of the quality of a public transport service is its reliability, which is defined as the invariability of the service attributes. Preventive measures taken during planning can reduce risks of unreliability throughout operations. In order to tackle reliability during the service planning phase, a key piece of information is the long-term prediction of the density of the travel time, which conveys the uncertainty of travel times. We introduce a reliable approach to one of the problems of service planning in public transport, namely the Multiple Depot Vehicle Scheduling Problem (MDVSP), which takes as input a set of trips and the probability density function (p.d.f.) of the travel time of each trip in order to output delay-tolerant vehicle schedules. This work empirically compares probabilistic models for the prediction of the conditional p.d.f. of the travel time, as a first step towards reliable MDVSP solutions. Two types of probabilistic models, namely similarity-based density estimation models and a smoothed Logistic Regression for probabilistic classification model, are compared on a dataset of more than 41,000 trips and 50 bus routes of the city of Montr\'eal. The result of a vast majority of probabilistic models outperforms that of a Random Forests model, which is not inherently probabilistic, thus highlighting the added value of modeling the conditional p.d.f. of the travel time with probabilistic models. A similarity-based density estimation model using a $k$ Nearest Neighbors method and a Kernel Density Estimation predicted the best estimate of the true conditional p.d.f. on this dataset.
End-to-End Learning to Grasp from Object Point Clouds
Mar 10, 2022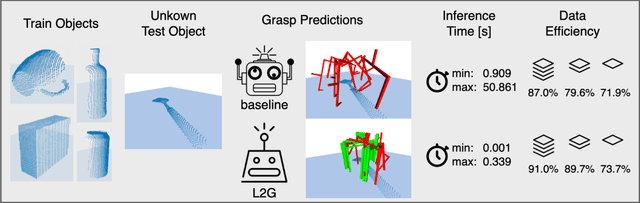
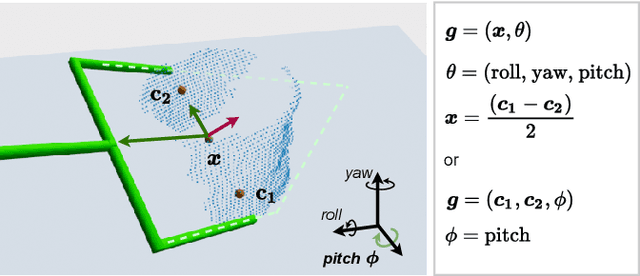
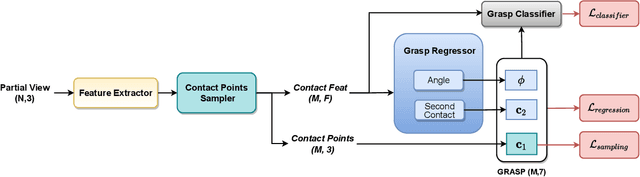
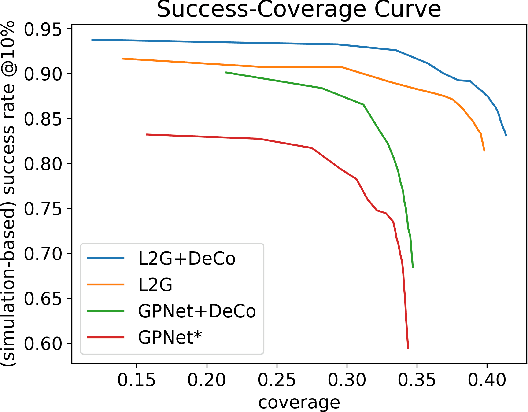
The ability to grasp objects is an essential skill that enables many robotic manipulation tasks. Recent works have studied point cloud-based methods for object grasping by starting from simulated datasets and have shown promising performance in real-world scenarios. Nevertheless, many of them still strongly rely on ad-hoc geometric heuristics to generate grasp candidates, which fail to generalize to objects with significantly different shapes with respect to those observed during training. Moreover, these methods are generally inefficient with respect to the number of training samples and the time needed during deployment. In this paper, we propose an end-to-end learning solution to generate 6-DOF parallel-jaw grasps starting from the partial view of the object. Our Learning to Grasp (L2G) method takes as input object point clouds and is guided by a principled multi-task optimization objective that generates a diverse set of grasps combining contact point sampling, grasp regression, and grasp evaluation. With a thorough experimental analysis, we show the effectiveness of the proposed method as well as its robustness and generalization abilities.
Deep Dual-resolution Networks for Real-time and Accurate Semantic Segmentation of Road Scenes
Jan 15, 2021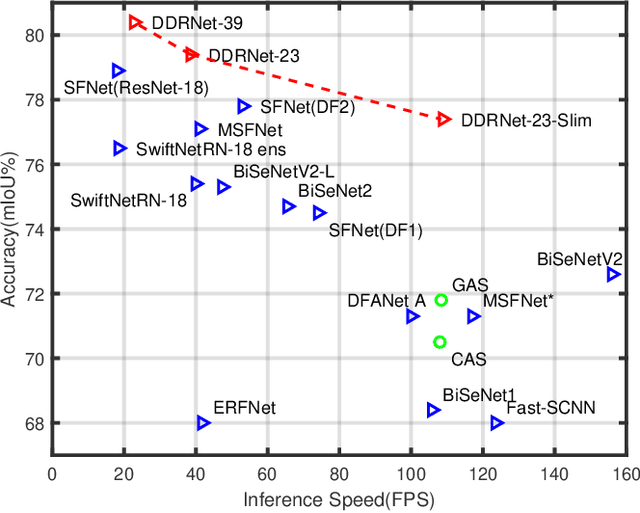
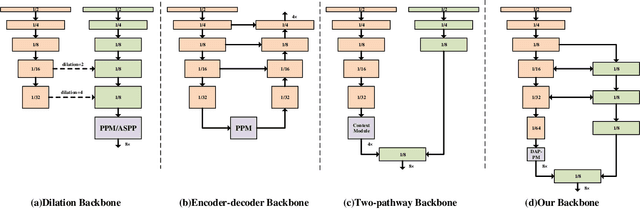
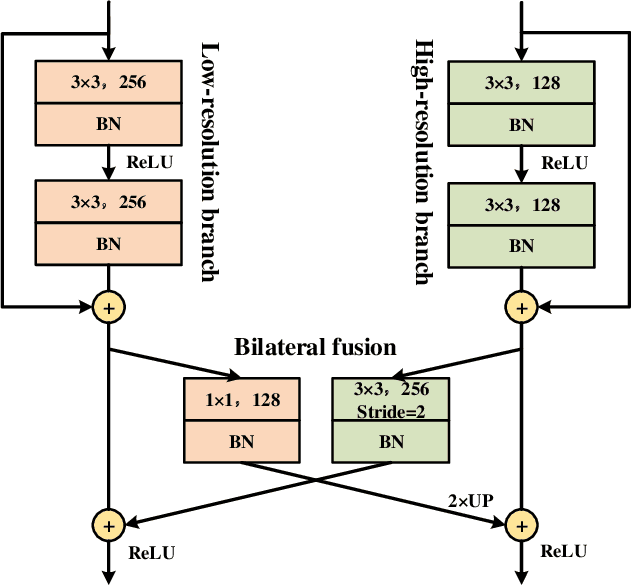
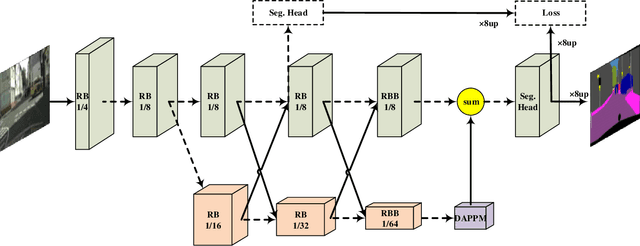
Semantic segmentation is a critical technology for autonomous vehicles to understand surrounding scenes. For practical autonomous vehicles, it is undesirable to spend a considerable amount of inference time to achieve high-accuracy segmentation results. Using light-weight architectures (encoder-decoder or two-pathway) or reasoning on low-resolution images, recent methods realize very fast scene parsing which even run at more than 100 FPS on single 1080Ti GPU. However, there are still evident gaps in performance between these real-time methods and models based on dilation backbones. To tackle this problem, we propose novel deep dual-resolution networks (DDRNets) for real-time semantic segmentation of road scenes. Besides, we design a new contextual information extractor named Deep Aggregation Pyramid Pooling Module (DAPPM) to enlarge effective receptive fields and fuse multi-scale context. Our method achieves new state-of-the-art trade-off between accuracy and speed on both Cityscapes and CamVid dataset. Specially, on single 2080Ti GPU, DDRNet-23-slim yields 77.4% mIoU at 109 FPS on Cityscapes test set and 74.4% mIoU at 230 FPS on CamVid test set. Without utilizing attention mechanism, pre-training on larger semantic segmentation dataset or inference acceleration, DDRNet-39 attains 80.4% test mIoU at 23 FPS on Cityscapes. With widely used test augmentation, our method is still superior to most state-of-the-art models, requiring much less computation. Codes and trained models will be made publicly available.
Geodesic Quantum Walks
Feb 22, 2022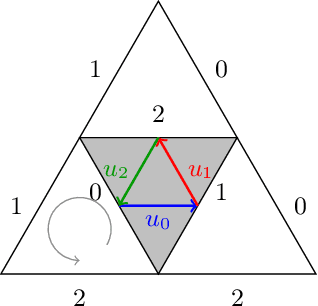
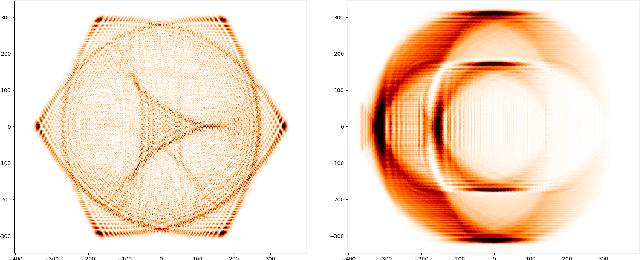
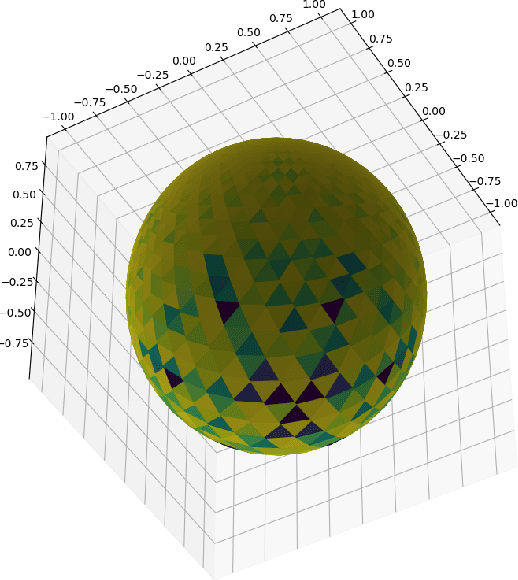
We propose a new family of discrete-spacetime quantum walks capable to propagate on any arbitrary triangulations. Moreover we also extend and generalize the duality principle introduced by one of the authors, linking continuous local deformations of a given triangulation and the inhomogeneity of the local unitaries that guide the quantum walker. We proved that in the formal continuous limit, in both space and time, this new family of quantum walks converges to the (1+2)D massless Dirac equation on curved manifolds. We believe that this result has relevance in both modelling/simulating quantum transport on discrete curved structures, such as fullerene molecules or dynamical causal triangulation, and in addressing fast and efficient optimization problems in the context of the curved space optimization methods.