 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Intelligent Multi-channel Meta-imagers for Accelerating Machine Vision
Jun 12, 2023
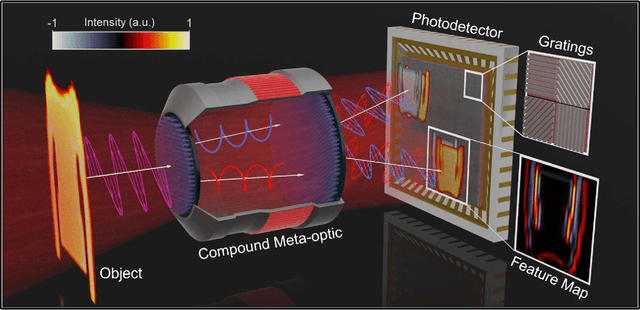
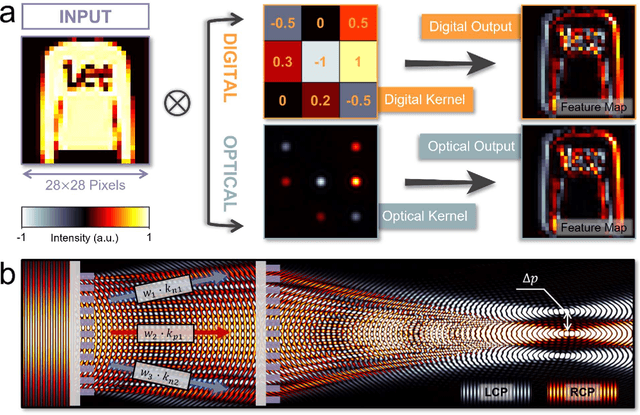
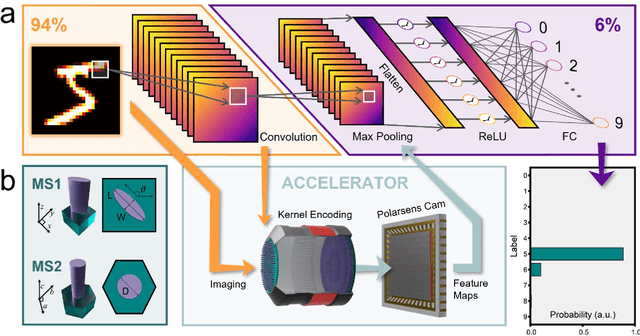
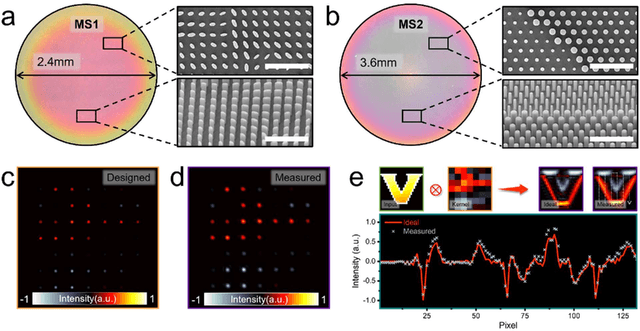
Rapid developments in machine vision have led to advances in a variety of industries, from medical image analysis to autonomous systems. These achievements, however, typically necessitate digital neural networks with heavy computational requirements, which are limited by high energy consumption and further hinder real-time decision-making when computation resources are not accessible. Here, we demonstrate an intelligent meta-imager that is designed to work in concert with a digital back-end to off-load computationally expensive convolution operations into high-speed and low-power optics. In this architecture, metasurfaces enable both angle and polarization multiplexing to create multiple information channels that perform positive and negatively valued convolution operations in a single shot. The meta-imager is employed for object classification, experimentally achieving 98.6% accurate classification of handwritten digits and 88.8% accuracy in classifying fashion images. With compactness, high speed, and low power consumption, this approach could find a wide range of applications in artificial intelligence and machine vision applications.
Transformer-based GAN for Terahertz Spatial-Temporal Channel Modeling and Generating
Jun 12, 2023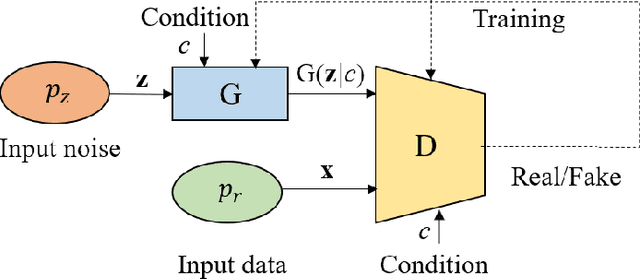
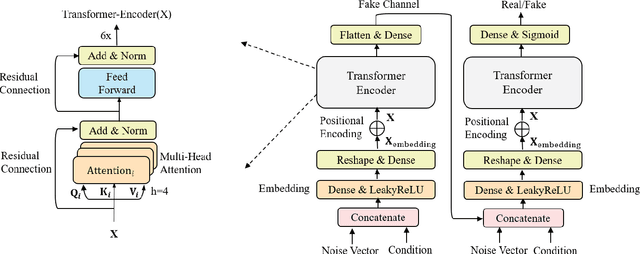
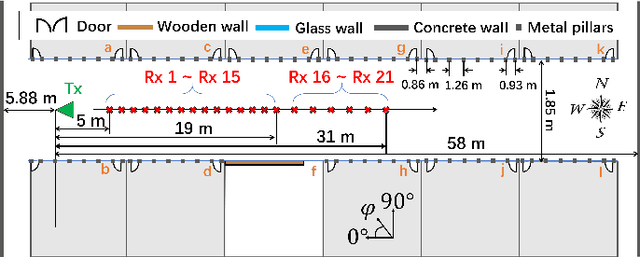
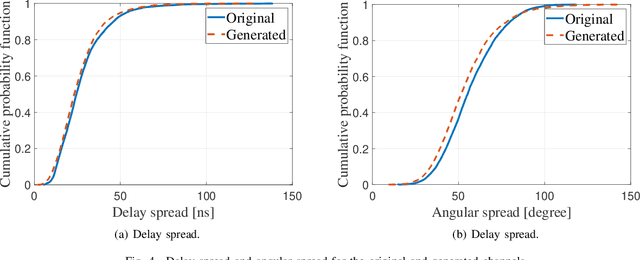
Terahertz (THz) communications are envisioned as a promising technology for 6G and beyond wireless systems, providing ultra-broad continuous bandwidth and thus Terabit-per-second (Tbps) data rates. However, as foundation of designing THz communications, channel modeling and characterization are fundamental to scrutinize the potential of the new spectrum. Relied on time-consuming and costly physical measurements, traditional statistical channel modeling methods suffer from the problem of low accuracy with the assumed certain distributions and empirical parameters. In this paper, a transformer-based generative adversarial network modeling method (T-GAN) is proposed in the THz band, which exploits the advantage of GAN in modeling the complex distribution, and the powerful expressive capability of transformer structure. Experimental results reveal that the distribution of channels generated by the proposed T-GAN method shows good agreement with the original channels in terms of the delay spread and angular spread. Moreover, T-GAN achieves good performance in modeling the power delay angular profile, with 2.18 dB root-mean-square error (RMSE).
High-speed Autonomous Racing using Trajectory-aided Deep Reinforcement Learning
Jun 12, 2023The classical method of autonomous racing uses real-time localisation to follow a precalculated optimal trajectory. In contrast, end-to-end deep reinforcement learning (DRL) can train agents to race using only raw LiDAR scans. While classical methods prioritise optimization for high-performance racing, DRL approaches have focused on low-performance contexts with little consideration of the speed profile. This work addresses the problem of using end-to-end DRL agents for high-speed autonomous racing. We present trajectory-aided learning (TAL) that trains DRL agents for high-performance racing by incorporating the optimal trajectory (racing line) into the learning formulation. Our method is evaluated using the TD3 algorithm on four maps in the open-source F1Tenth simulator. The results demonstrate that our method achieves a significantly higher lap completion rate at high speeds compared to the baseline. This is due to TAL training the agent to select a feasible speed profile of slowing down in the corners and roughly tracking the optimal trajectory.
Reconstructing Heterogeneous Cryo-EM Molecular Structures by Decomposing Them into Polymer Chains
Jun 12, 2023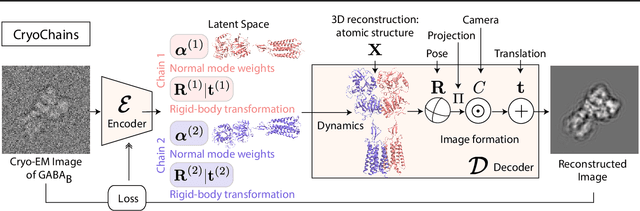
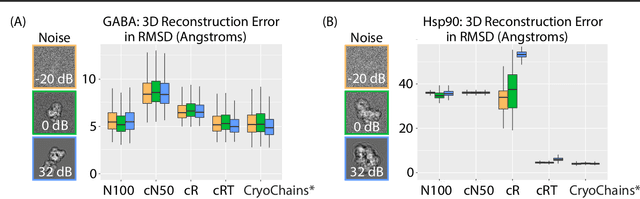
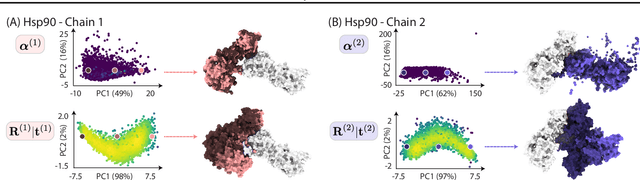

Cryogenic electron microscopy (cryo-EM) has transformed structural biology by allowing to reconstruct 3D biomolecular structures up to near-atomic resolution. However, the 3D reconstruction process remains challenging, as the 3D structures may exhibit substantial shape variations, while the 2D image acquisition suffers from a low signal-to-noise ratio, requiring to acquire very large datasets that are time-consuming to process. Current reconstruction methods are precise but computationally expensive, or faster but lack a physically-plausible model of large molecular shape variations. To fill this gap, we propose CryoChains that encodes large deformations of biomolecules via rigid body transformation of their polymer instances (chains), while representing their finer shape variations with the normal mode analysis framework of biophysics. Our synthetic data experiments on the human $\text{GABA}_{\text{B}}$ and heat shock protein show that CryoChains gives a biophysically-grounded quantification of the heterogeneous conformations of biomolecules, while reconstructing their 3D molecular structures at an improved resolution compared to the current fastest, interpretable deep learning method.
RITA: Group Attention is All You Need for Timeseries Analytics
Jun 02, 2023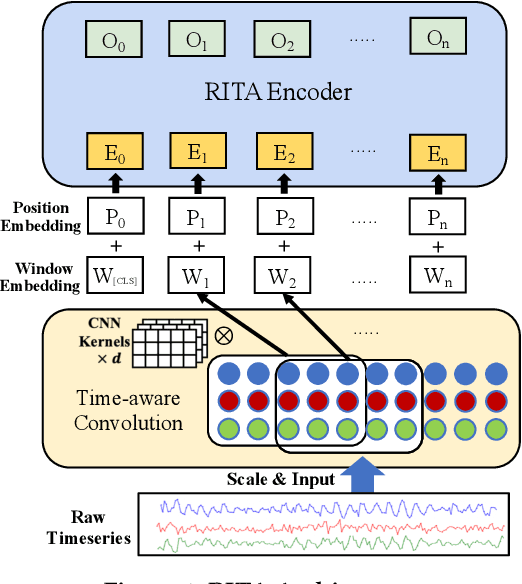
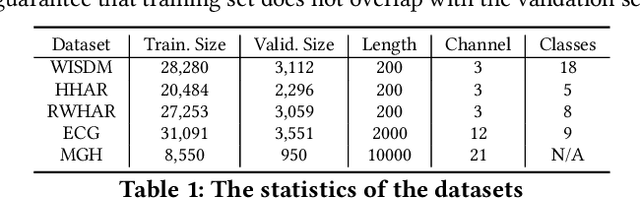
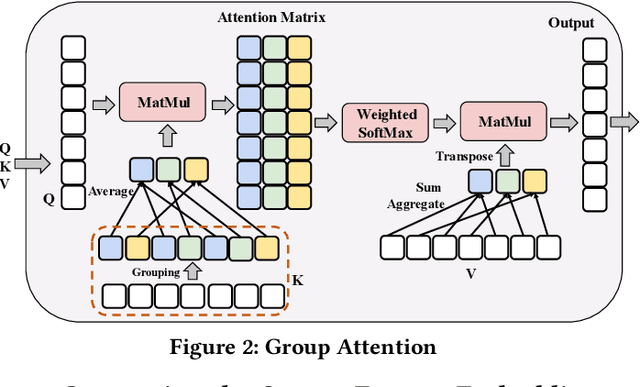
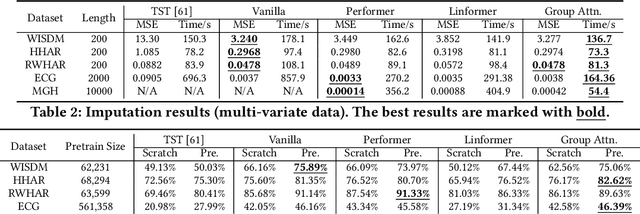
Timeseries analytics is of great importance in many real-world applications. Recently, the Transformer model, popular in natural language processing, has been leveraged to learn high quality feature embeddings from timeseries, core to the performance of various timeseries analytics tasks. However, the quadratic time and space complexities limit Transformers' scalability, especially for long timeseries. To address these issues, we develop a timeseries analytics tool, RITA, which uses a novel attention mechanism, named group attention, to address this scalability issue. Group attention dynamically clusters the objects based on their similarity into a small number of groups and approximately computes the attention at the coarse group granularity. It thus significantly reduces the time and space complexity, yet provides a theoretical guarantee on the quality of the computed attention. The dynamic scheduler of RITA continuously adapts the number of groups and the batch size in the training process, ensuring group attention always uses the fewest groups needed to meet the approximation quality requirement. Extensive experiments on various timeseries datasets and analytics tasks demonstrate that RITA outperforms the state-of-the-art in accuracy and is significantly faster -- with speedups of up to 63X.
Escaping mediocrity: how two-layer networks learn hard single-index models with SGD
May 29, 2023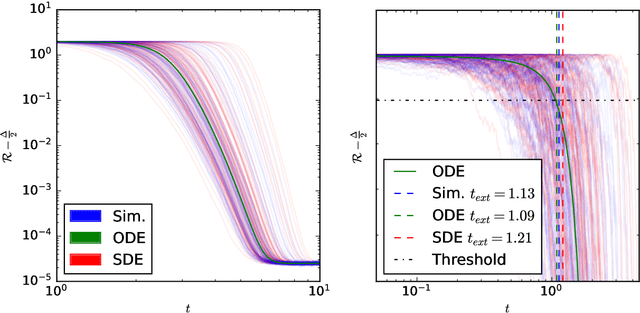
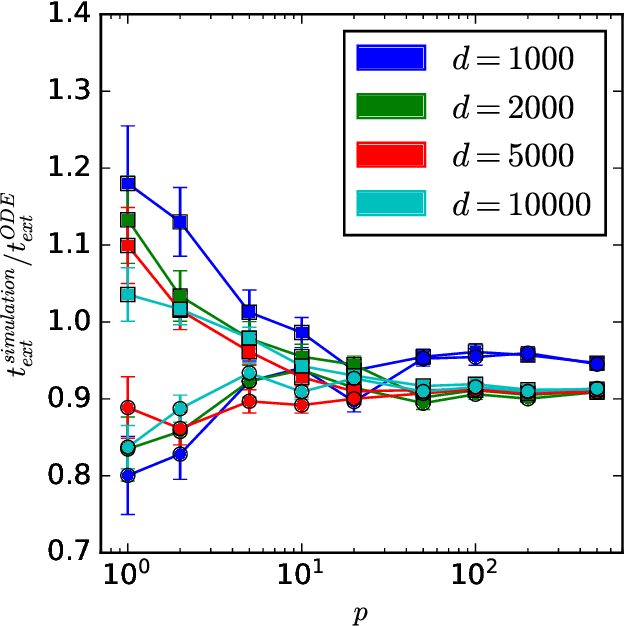
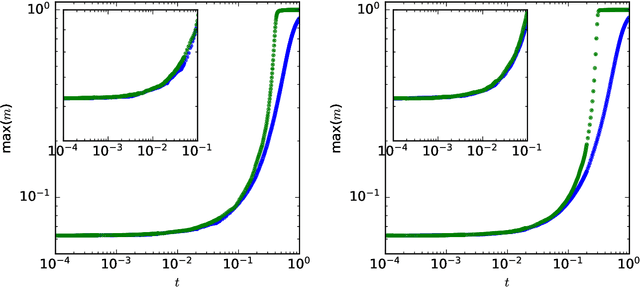
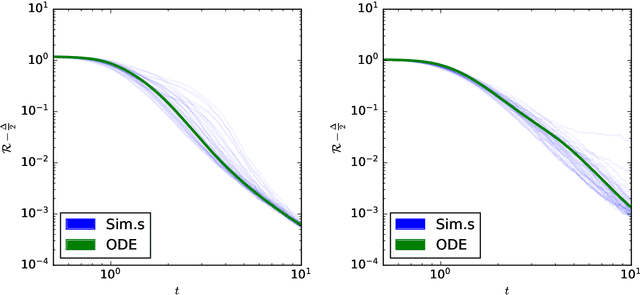
This study explores the sample complexity for two-layer neural networks to learn a single-index target function under Stochastic Gradient Descent (SGD), focusing on the challenging regime where many flat directions are present at initialization. It is well-established that in this scenario $n=O(d\log{d})$ samples are typically needed. However, we provide precise results concerning the pre-factors in high-dimensional contexts and for varying widths. Notably, our findings suggest that overparameterization can only enhance convergence by a constant factor within this problem class. These insights are grounded in the reduction of SGD dynamics to a stochastic process in lower dimensions, where escaping mediocrity equates to calculating an exit time. Yet, we demonstrate that a deterministic approximation of this process adequately represents the escape time, implying that the role of stochasticity may be minimal in this scenario.
Towards a Better Understanding of Representation Dynamics under TD-learning
May 29, 2023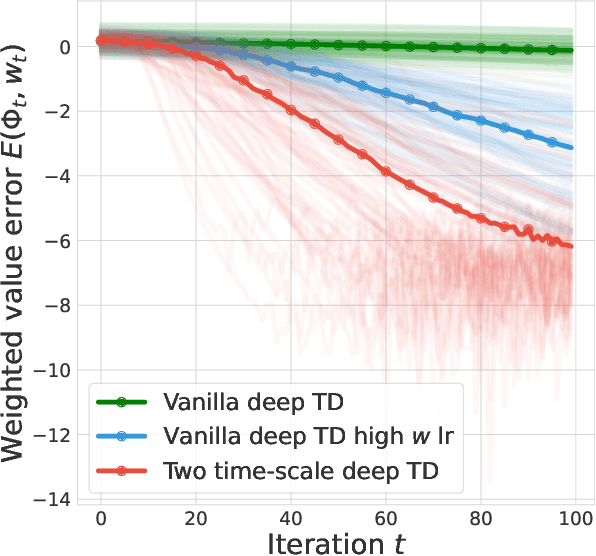
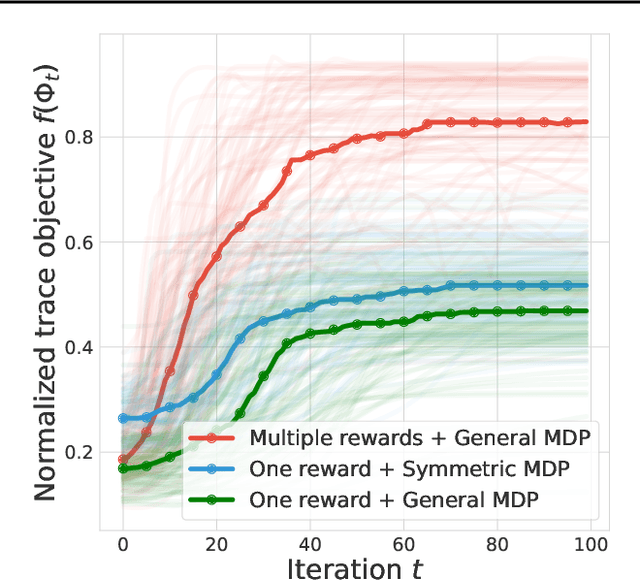
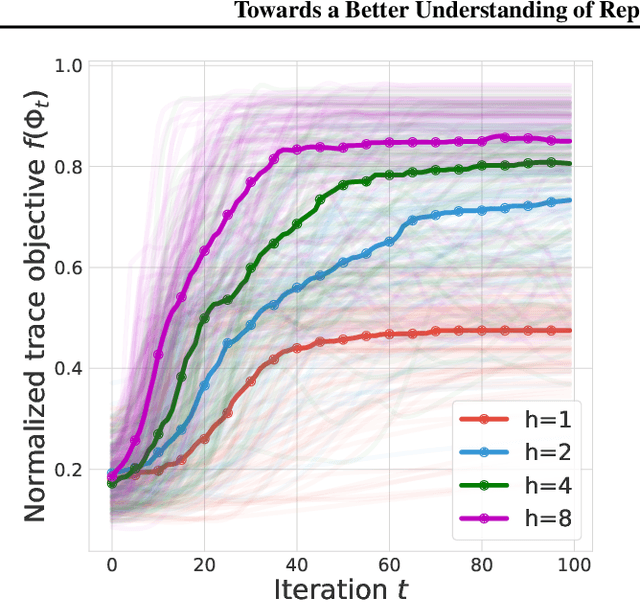
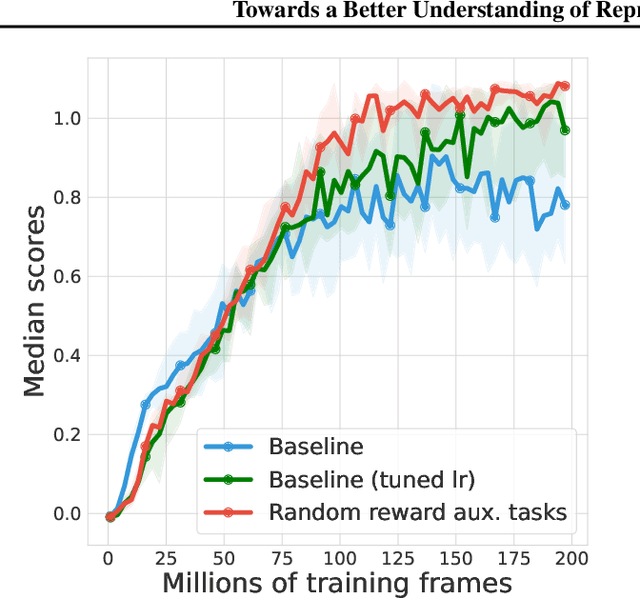
TD-learning is a foundation reinforcement learning (RL) algorithm for value prediction. Critical to the accuracy of value predictions is the quality of state representations. In this work, we consider the question: how does end-to-end TD-learning impact the representation over time? Complementary to prior work, we provide a set of analysis that sheds further light on the representation dynamics under TD-learning. We first show that when the environments are reversible, end-to-end TD-learning strictly decreases the value approximation error over time. Under further assumptions on the environments, we can connect the representation dynamics with spectral decomposition over the transition matrix. This latter finding establishes fitting multiple value functions from randomly generated rewards as a useful auxiliary task for representation learning, as we empirically validate on both tabular and Atari game suites.
The Hybrid Extended Bicycle: A Simple Model for High Dynamic Vehicle Trajectory Planning
Jun 08, 2023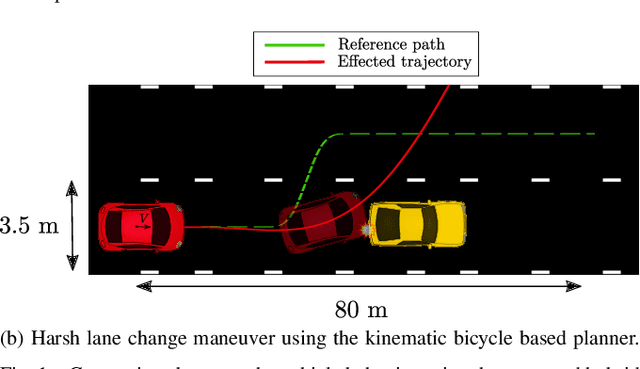
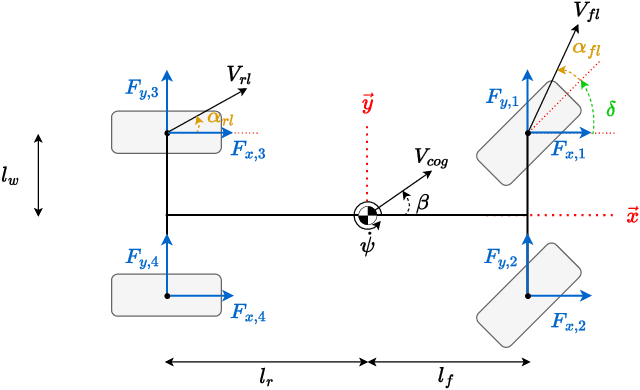
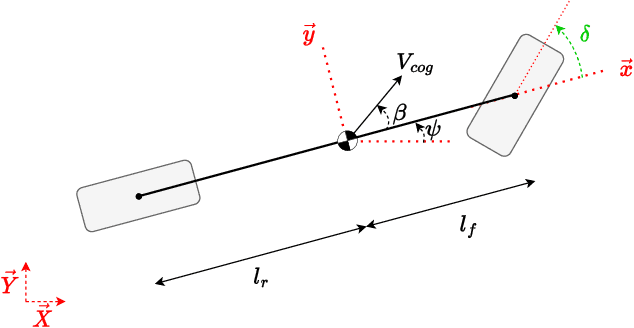
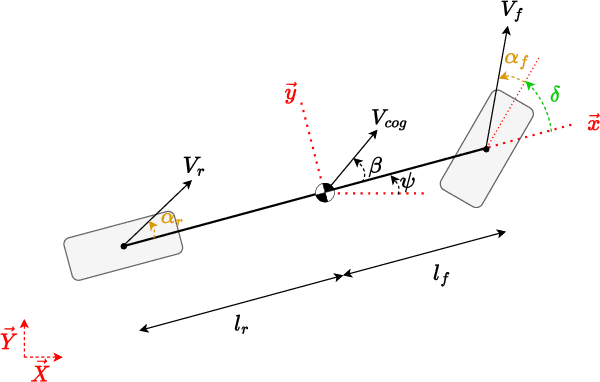
While highly automated driving relies most of the time on a smooth driving assumption, the possibility of a vehicle performing harsh maneuvers with high dynamic driving to face unexpected events is very likely. The modeling of the behavior of the vehicle in these events is crucial to proper planning and controlling; the used model should present accurate and computationally efficient properties. In this article, we propose an LSTM-based hybrid extended bicycle model able to present an accurate description of the state of the vehicle for both normal and aggressive situations. The introduced model is used in an MPPI framework for planning trajectories in high-dynamic scenarios where other simple models fail.
Fit Like You Sample: Sample-Efficient Generalized Score Matching from Fast Mixing Markov Chains
Jun 20, 2023Score matching is an approach to learning probability distributions parametrized up to a constant of proportionality (e.g. Energy-Based Models). The idea is to fit the score of the distribution, rather than the likelihood, thus avoiding the need to evaluate the constant of proportionality. While there's a clear algorithmic benefit, the statistical "cost'' can be steep: recent work by Koehler et al. 2022 showed that for distributions that have poor isoperimetric properties (a large Poincar\'e or log-Sobolev constant), score matching is substantially statistically less efficient than maximum likelihood. However, many natural realistic distributions, e.g. multimodal distributions as simple as a mixture of two Gaussians in one dimension -- have a poor Poincar\'e constant. In this paper, we show a close connection between the mixing time of an arbitrary Markov process with generator $\mathcal{L}$ and an appropriately chosen generalized score matching loss that tries to fit $\frac{\mathcal{O} p}{p}$. If $\mathcal{L}$ corresponds to a Markov process corresponding to a continuous version of simulated tempering, we show the corresponding generalized score matching loss is a Gaussian-convolution annealed score matching loss, akin to the one proposed in Song and Ermon 2019. Moreover, we show that if the distribution being learned is a finite mixture of Gaussians in $d$ dimensions with a shared covariance, the sample complexity of annealed score matching is polynomial in the ambient dimension, the diameter the means, and the smallest and largest eigenvalues of the covariance -- obviating the Poincar\'e constant-based lower bounds of the basic score matching loss shown in Koehler et al. 2022. This is the first result characterizing the benefits of annealing for score matching -- a crucial component in more sophisticated score-based approaches like Song and Ermon 2019.
Candidate Set Re-ranking for Composed Image Retrieval with Dual Multi-modal Encoder
Jun 05, 2023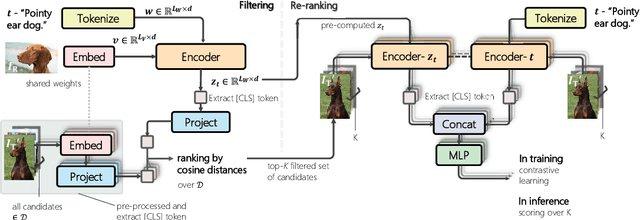
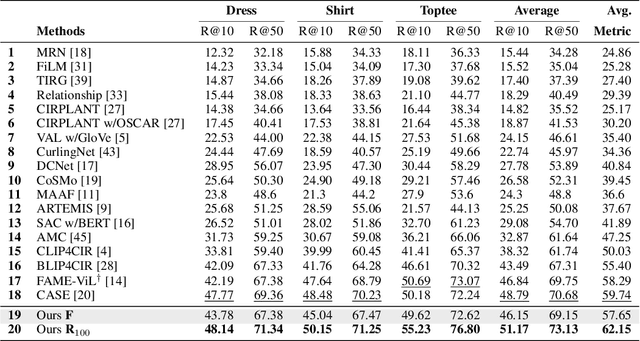
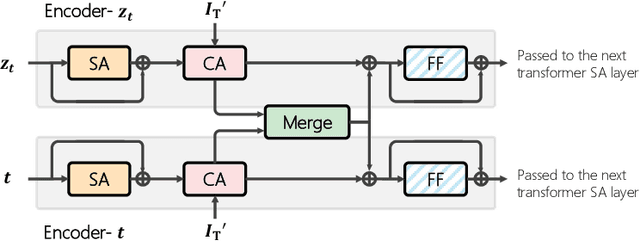
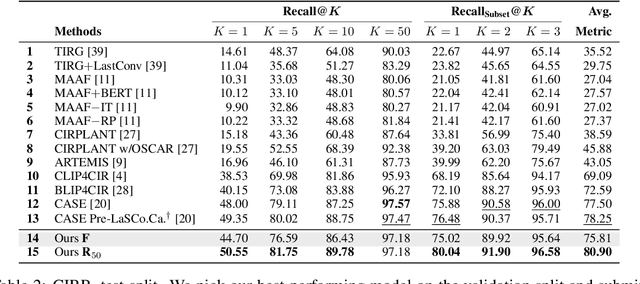
Composed image retrieval aims to find an image that best matches a given multi-modal user query consisting of a reference image and text pair. Existing methods commonly pre-compute image embeddings over the entire corpus and compare these to a reference image embedding modified by the query text at test time. Such a pipeline is very efficient at test time since fast vector distances can be used to evaluate candidates, but modifying the reference image embedding guided only by a short textual description can be difficult, especially independent of potential candidates. An alternative approach is to allow interactions between the query and every possible candidate, i.e., reference-text-candidate triplets, and pick the best from the entire set. Though this approach is more discriminative, for large-scale datasets the computational cost is prohibitive since pre-computation of candidate embeddings is no longer possible. We propose to combine the merits of both schemes using a two-stage model. Our first stage adopts the conventional vector distancing metric and performs a fast pruning among candidates. Meanwhile, our second stage employs a dual-encoder architecture, which effectively attends to the input triplet of reference-text-candidate and re-ranks the candidates. Both stages utilize a vision-and-language pre-trained network, which has proven beneficial for various downstream tasks. Our method consistently outperforms state-of-the-art approaches on standard benchmarks for the task.