 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Handling Concept Drift in Global Time Series Forecasting
Apr 04, 2023
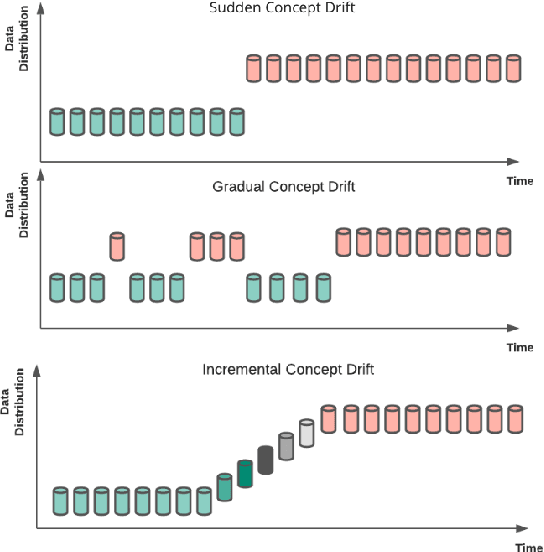
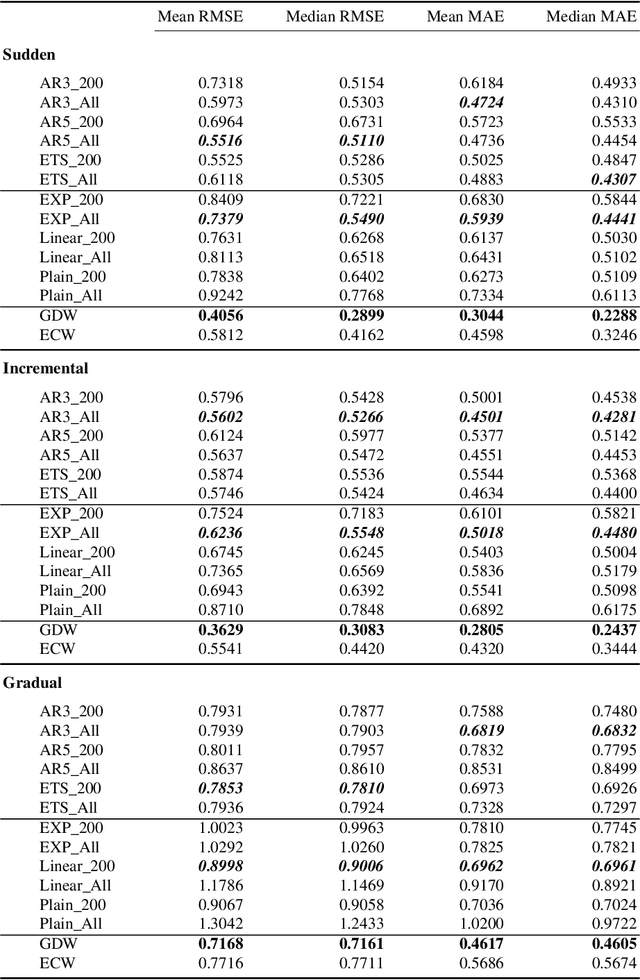
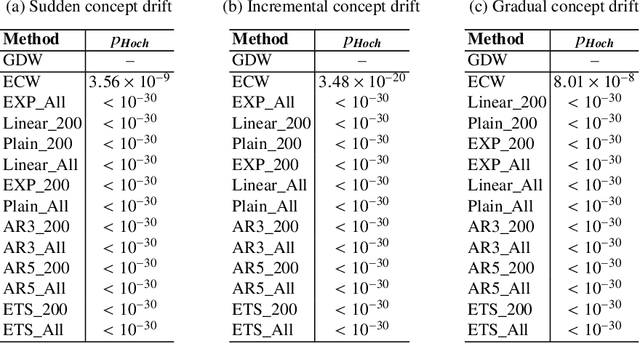
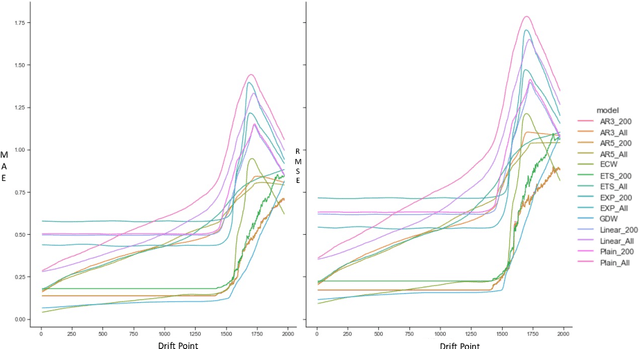
Machine learning (ML) based time series forecasting models often require and assume certain degrees of stationarity in the data when producing forecasts. However, in many real-world situations, the data distributions are not stationary and they can change over time while reducing the accuracy of the forecasting models, which in the ML literature is known as concept drift. Handling concept drift in forecasting is essential for many ML methods in use nowadays, however, the prior work only proposes methods to handle concept drift in the classification domain. To fill this gap, we explore concept drift handling methods in particular for Global Forecasting Models (GFM) which recently have gained popularity in the forecasting domain. We propose two new concept drift handling methods, namely: Error Contribution Weighting (ECW) and Gradient Descent Weighting (GDW), based on a continuous adaptive weighting concept. These methods use two forecasting models which are separately trained with the most recent series and all series, and finally, the weighted average of the forecasts provided by the two models are considered as the final forecasts. Using LightGBM as the underlying base learner, in our evaluation on three simulated datasets, the proposed models achieve significantly higher accuracy than a set of statistical benchmarks and LightGBM baselines across four evaluation metrics.
RaPlace: Place Recognition for Imaging Radar using Radon Transform and Mutable Threshold
Jul 10, 2023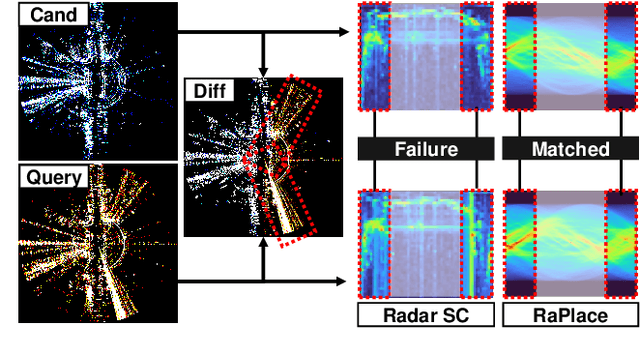
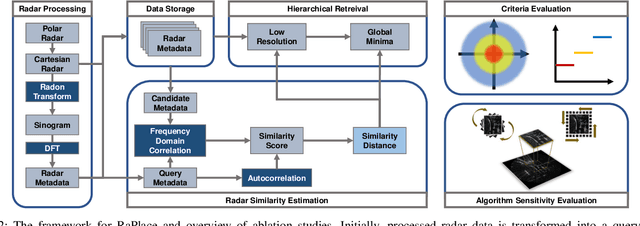
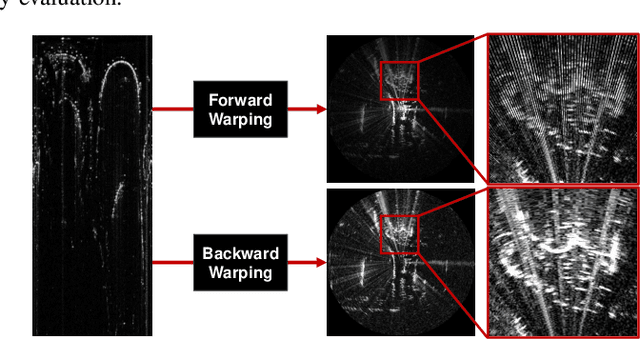
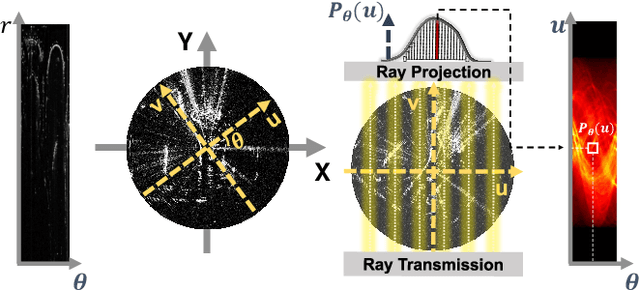
Due to the robustness in sensing, radar has been highlighted, overcoming harsh weather conditions such as fog and heavy snow. In this paper, we present a novel radar-only place recognition that measures the similarity score by utilizing Radon-transformed sinogram images and cross-correlation in frequency domain. Doing so achieves rigid transform invariance during place recognition, while ignoring the effects of radar multipath and ring noises. In addition, we compute the radar similarity distance using mutable threshold to mitigate variability of the similarity score, and reduce the time complexity of processing a copious radar data with hierarchical retrieval. We demonstrate the matching performance for both intra-session loop-closure detection and global place recognition using a publicly available imaging radar datasets. We verify reliable performance compared to existing stable radar place recognition method. Furthermore, codes for the proposed imaging radar place recognition is released for community.
Choosing Well Your Opponents: How to Guide the Synthesis of Programmatic Strategies
Jul 10, 2023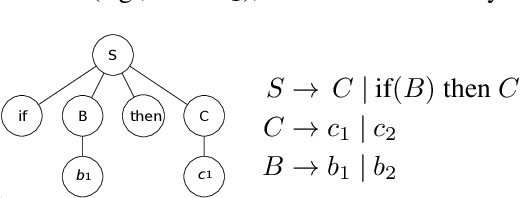

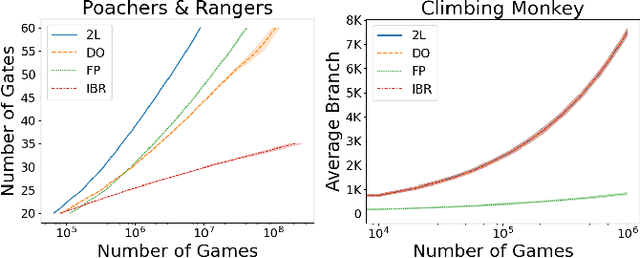
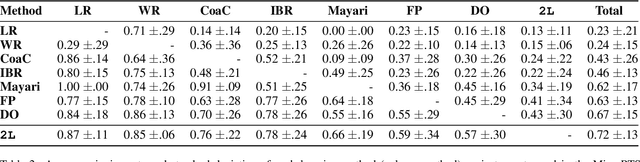
This paper introduces Local Learner (2L), an algorithm for providing a set of reference strategies to guide the search for programmatic strategies in two-player zero-sum games. Previous learning algorithms, such as Iterated Best Response (IBR), Fictitious Play (FP), and Double-Oracle (DO), can be computationally expensive or miss important information for guiding search algorithms. 2L actively selects a set of reference strategies to improve the search signal. We empirically demonstrate the advantages of our approach while guiding a local search algorithm for synthesizing strategies in three games, including MicroRTS, a challenging real-time strategy game. Results show that 2L learns reference strategies that provide a stronger search signal than IBR, FP, and DO. We also simulate a tournament of MicroRTS, where a synthesizer using 2L outperformed the winners of the two latest MicroRTS competitions, which were programmatic strategies written by human programmers.
Deep Learning Method for Cell-Wise Object Tracking, Velocity Estimation and Projection of Sensor Data over Time
Jun 18, 2023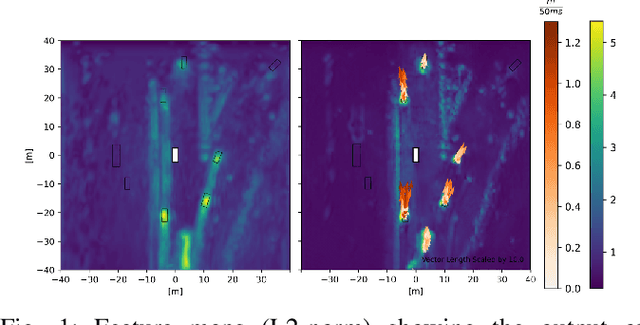
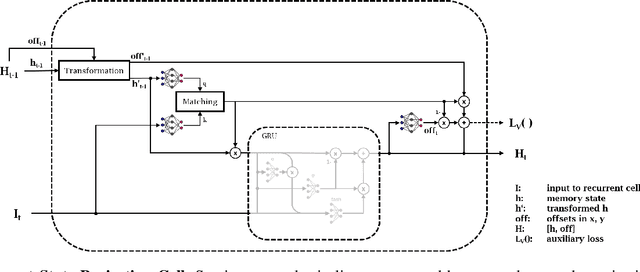
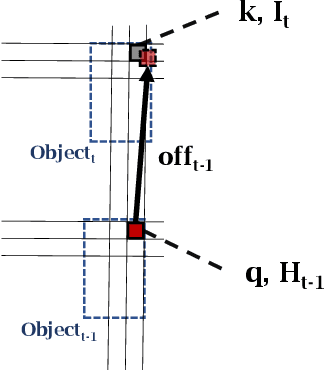
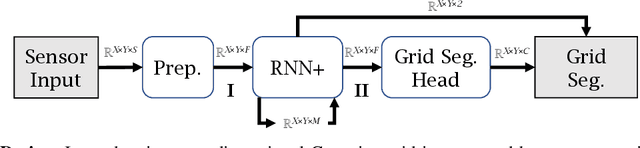
Current Deep Learning methods for environment segmentation and velocity estimation rely on Convolutional Recurrent Neural Networks to exploit spatio-temporal relationships within obtained sensor data. These approaches derive scene dynamics implicitly by correlating novel input and memorized data utilizing ConvNets. We show how ConvNets suffer from architectural restrictions for this task. Based on these findings, we then provide solutions to various issues on exploiting spatio-temporal correlations in a sequence of sensor recordings by presenting a novel Recurrent Neural Network unit utilizing Transformer mechanisms. Within this unit, object encodings are tracked across consecutive frames by correlating key-query pairs derived from sensor inputs and memory states, respectively. We then use resulting tracking patterns to obtain scene dynamics and regress velocities. In a last step, the memory state of the Recurrent Neural Network is projected based on extracted velocity estimates to resolve aforementioned spatio-temporal misalignment.
Never a Dull Moment: Distributional Properties as a Baseline for Time-Series Classification
Mar 31, 2023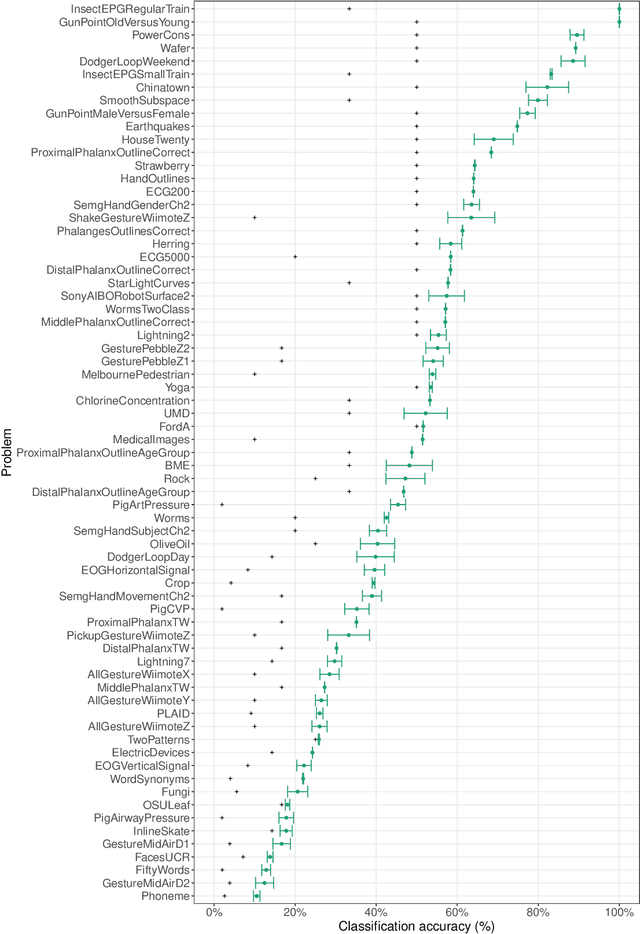
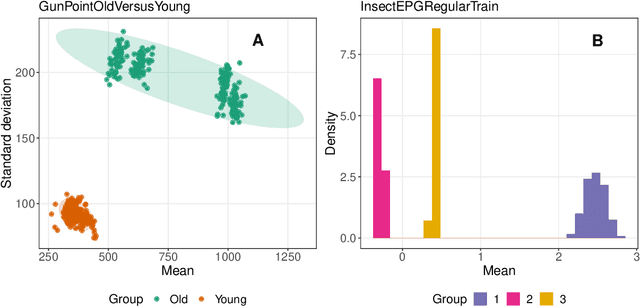

The variety of complex algorithmic approaches for tackling time-series classification problems has grown considerably over the past decades, including the development of sophisticated but challenging-to-interpret deep-learning-based methods. But without comparison to simpler methods it can be difficult to determine when such complexity is required to obtain strong performance on a given problem. Here we evaluate the performance of an extremely simple classification approach -- a linear classifier in the space of two simple features that ignore the sequential ordering of the data: the mean and standard deviation of time-series values. Across a large repository of 128 univariate time-series classification problems, this simple distributional moment-based approach outperformed chance on 69 problems, and reached 100% accuracy on two problems. With a neuroimaging time-series case study, we find that a simple linear model based on the mean and standard deviation performs better at classifying individuals with schizophrenia than a model that additionally includes features of the time-series dynamics. Comparing the performance of simple distributional features of a time series provides important context for interpreting the performance of complex time-series classification models, which may not always be required to obtain high accuracy.
Length of Stay prediction for Hospital Management using Domain Adaptation
Jun 29, 2023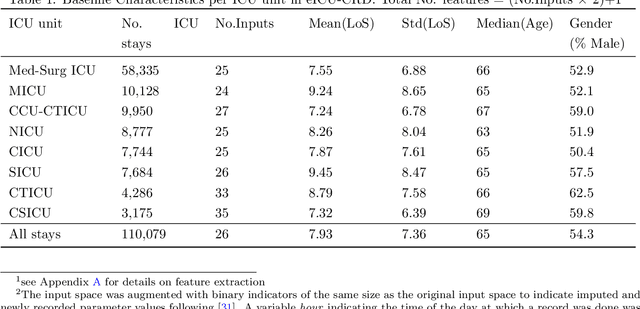
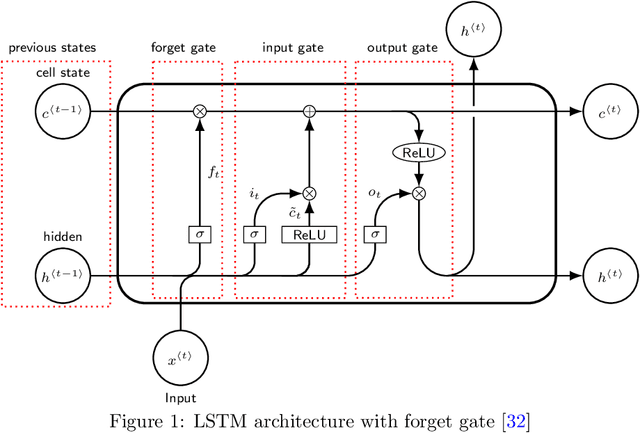
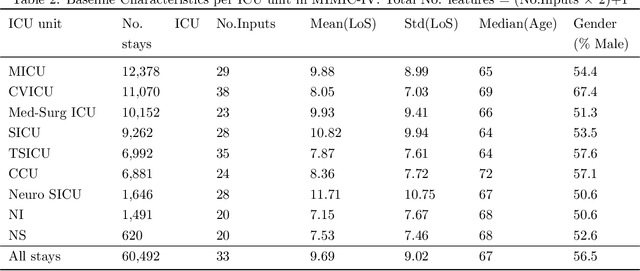
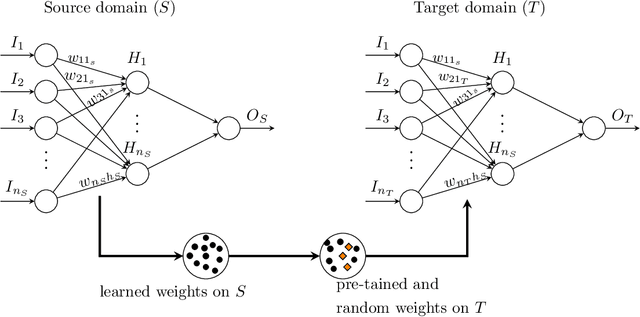
Inpatient length of stay (LoS) is an important managerial metric which if known in advance can be used to efficiently plan admissions, allocate resources and improve care. Using historical patient data and machine learning techniques, LoS prediction models can be developed. Ethically, these models can not be used for patient discharge in lieu of unit heads but are of utmost necessity for hospital management systems in charge of effective hospital planning. Therefore, the design of the prediction system should be adapted to work in a true hospital setting. In this study, we predict early hospital LoS at the granular level of admission units by applying domain adaptation to leverage information learned from a potential source domain. Time-varying data from 110,079 and 60,492 patient stays to 8 and 9 intensive care units were respectively extracted from eICU-CRD and MIMIC-IV. These were fed into a Long-Short Term Memory and a Fully connected network to train a source domain model, the weights of which were transferred either partially or fully to initiate training in target domains. Shapley Additive exPlanations (SHAP) algorithms were used to study the effect of weight transfer on model explanability. Compared to the benchmark, the proposed weight transfer model showed statistically significant gains in prediction accuracy (between 1% and 5%) as well as computation time (up to 2hrs) for some target domains. The proposed method thus provides an adapted clinical decision support system for hospital management that can ease processes of data access via ethical committee, computation infrastructures and time.
The distribution of discourse relations within and across turns in spontaneous conversation
Jul 07, 2023
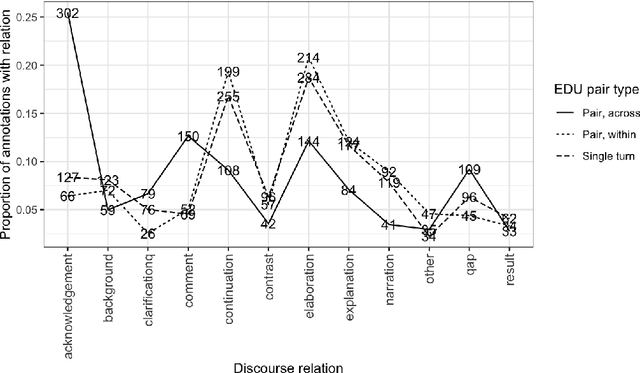
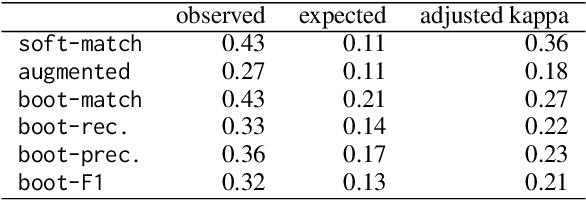
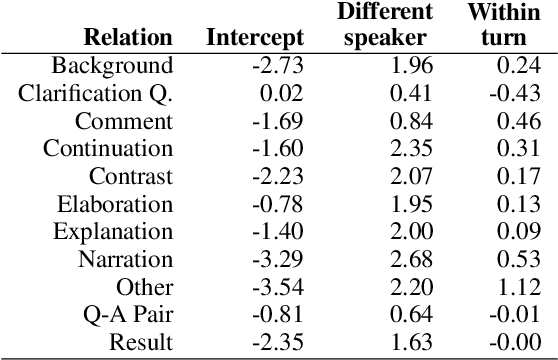
Time pressure and topic negotiation may impose constraints on how people leverage discourse relations (DRs) in spontaneous conversational contexts. In this work, we adapt a system of DRs for written language to spontaneous dialogue using crowdsourced annotations from novice annotators. We then test whether discourse relations are used differently across several types of multi-utterance contexts. We compare the patterns of DR annotation within and across speakers and within and across turns. Ultimately, we find that different discourse contexts produce distinct distributions of discourse relations, with single-turn annotations creating the most uncertainty for annotators. Additionally, we find that the discourse relation annotations are of sufficient quality to predict from embeddings of discourse units.
GRNN-based Real-time Fault Chain Prediction
Mar 15, 2023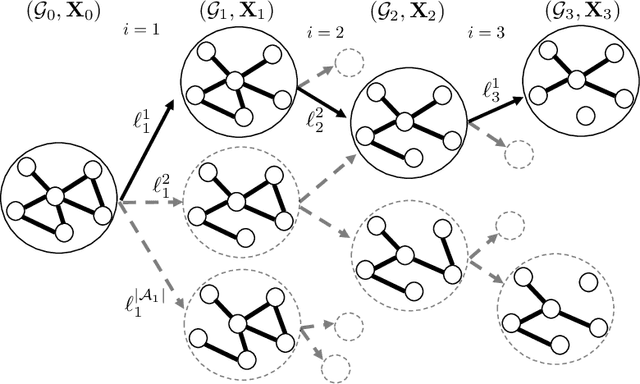
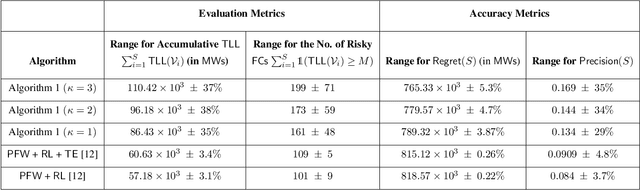
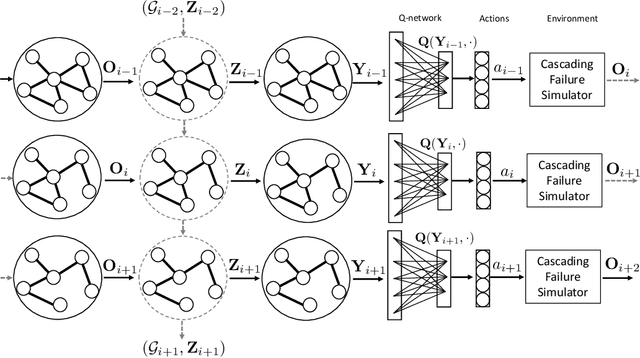
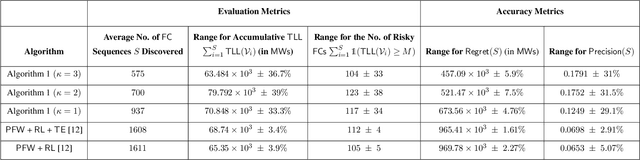
This paper proposes a data-driven graphical framework for the real-time search of risky cascading fault chains (FCs). While identifying risky FCs is pivotal to alleviating cascading failures, the complex spatio-temporal dependencies among the components of the power system render challenges to modeling and analyzing FCs. Furthermore, the real-time search of risky FCs faces an inherent combinatorial complexity that grows exponentially with the size of the system. The proposed framework leverages the recent advances in graph recurrent neural networks to circumvent the computational complexities of the real-time search of FCs. The search process is formalized as a partially observable Markov decision process (POMDP), which is subsequently solved via a time-varying graph recurrent neural network (GRNN) that judiciously accounts for the inherent temporal and spatial structures of the data generated by the system. The key features of this structure include (i) leveraging the spatial structure of the data induced by the system topology, (ii) leveraging the temporal structure of data induced by system dynamics, and (iii) efficiently summarizing the system's history in the latent space of the GRNN. The proposed framework's efficiency is compared to the relevant literature on the IEEE 39-bus New England system and the IEEE 118-bus system.
Where Did the President Visit Last Week? Detecting Celebrity Trips from News Articles
Jul 17, 2023

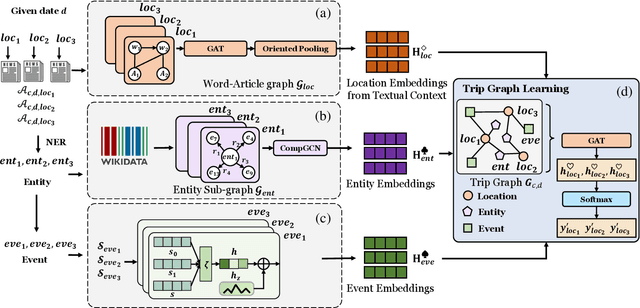

Celebrities' whereabouts are of pervasive importance. For instance, where politicians go, how often they visit, and who they meet, come with profound geopolitical and economic implications. Although news articles contain travel information of celebrities, it is not possible to perform large-scale and network-wise analysis due to the lack of automatic itinerary detection tools. To design such tools, we have to overcome difficulties from the heterogeneity among news articles: 1)One single article can be noisy, with irrelevant people and locations, especially when the articles are long. 2)Though it may be helpful if we consider multiple articles together to determine a particular trip, the key semantics are still scattered across different articles intertwined with various noises, making it hard to aggregate them effectively. 3)Over 20% of the articles refer to the celebrities' trips indirectly, instead of using the exact celebrity names or location names, leading to large portions of trips escaping regular detecting algorithms. We model text content across articles related to each candidate location as a graph to better associate essential information and cancel out the noises. Besides, we design a special pooling layer based on attention mechanism and node similarity, reducing irrelevant information from longer articles. To make up the missing information resulted from indirect mentions, we construct knowledge sub-graphs for named entities (person, organization, facility, etc.). Specifically, we dynamically update embeddings of event entities like the G7 summit from news descriptions since the properties (date and location) of the event change each time, which is not captured by the pre-trained event representations. The proposed CeleTrip jointly trains these modules, which outperforms all baseline models and achieves 82.53% in the F1 metric.
Spatiotemporal Besov Priors for Bayesian Inverse Problems
Jun 28, 2023
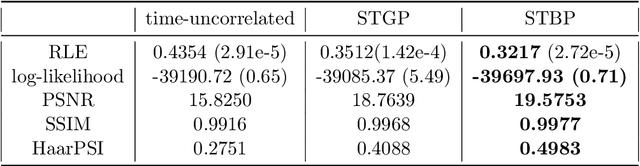
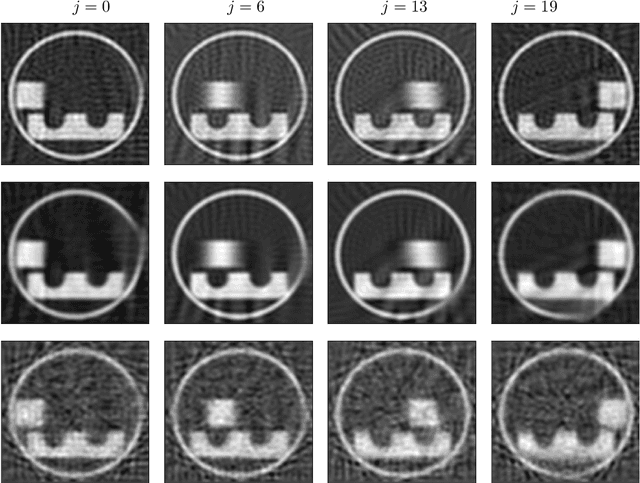
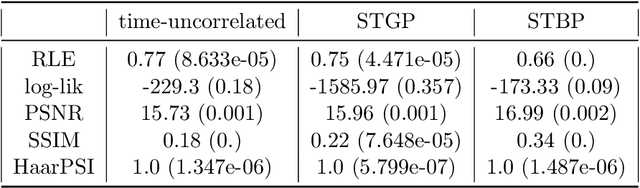
Fast development in science and technology has driven the need for proper statistical tools to capture special data features such as abrupt changes or sharp contrast. Many applications in the data science seek spatiotemporal reconstruction from a sequence of time-dependent objects with discontinuity or singularity, e.g. dynamic computerized tomography (CT) images with edges. Traditional methods based on Gaussian processes (GP) may not provide satisfactory solutions since they tend to offer over-smooth prior candidates. Recently, Besov process (BP) defined by wavelet expansions with random coefficients has been proposed as a more appropriate prior for this type of Bayesian inverse problems. While BP outperforms GP in imaging analysis to produce edge-preserving reconstructions, it does not automatically incorporate temporal correlation inherited in the dynamically changing images. In this paper, we generalize BP to the spatiotemporal domain (STBP) by replacing the random coefficients in the series expansion with stochastic time functions following Q-exponential process which governs the temporal correlation strength. Mathematical and statistical properties about STBP are carefully studied. A white-noise representation of STBP is also proposed to facilitate the point estimation through maximum a posterior (MAP) and the uncertainty quantification (UQ) by posterior sampling. Two limited-angle CT reconstruction examples and a highly non-linear inverse problem involving Navier-Stokes equation are used to demonstrate the advantage of the proposed STBP in preserving spatial features while accounting for temporal changes compared with the classic STGP and a time-uncorrelated approach.