 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
DuETT: Dual Event Time Transformer for Electronic Health Records
Apr 25, 2023
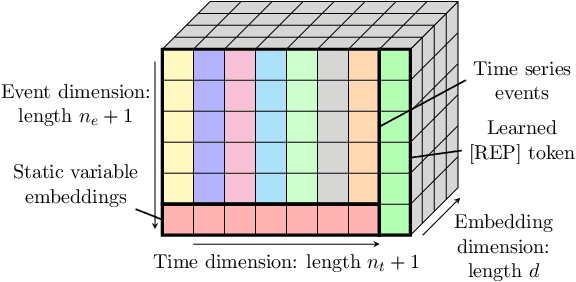
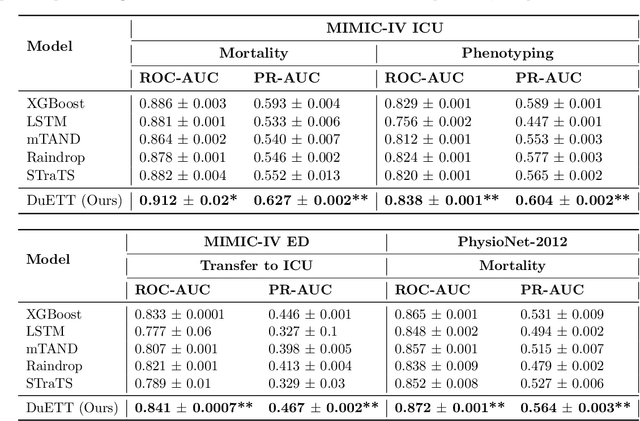
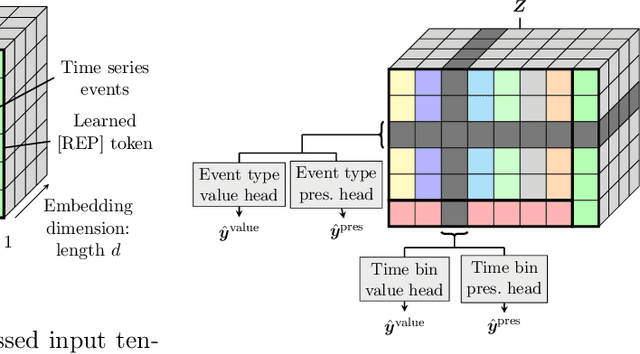
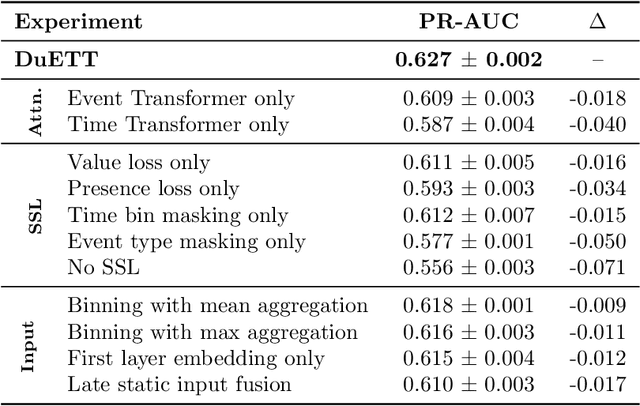
Electronic health records (EHRs) recorded in hospital settings typically contain a wide range of numeric time series data that is characterized by high sparsity and irregular observations. Effective modelling for such data must exploit its time series nature, the semantic relationship between different types of observations, and information in the sparsity structure of the data. Self-supervised Transformers have shown outstanding performance in a variety of structured tasks in NLP and computer vision. But multivariate time series data contains structured relationships over two dimensions: time and recorded event type, and straightforward applications of Transformers to time series data do not leverage this distinct structure. The quadratic scaling of self-attention layers can also significantly limit the input sequence length without appropriate input engineering. We introduce the DuETT architecture, an extension of Transformers designed to attend over both time and event type dimensions, yielding robust representations from EHR data. DuETT uses an aggregated input where sparse time series are transformed into a regular sequence with fixed length; this lowers the computational complexity relative to previous EHR Transformer models and, more importantly, enables the use of larger and deeper neural networks. When trained with self-supervised prediction tasks, that provide rich and informative signals for model pre-training, our model outperforms state-of-the-art deep learning models on multiple downstream tasks from the MIMIC-IV and PhysioNet-2012 EHR datasets.
Machine Learning, Deep Learning and Data Preprocessing Techniques for Detection, Prediction, and Monitoring of Stress and Stress-related Mental Disorders: A Scoping Review
Aug 08, 2023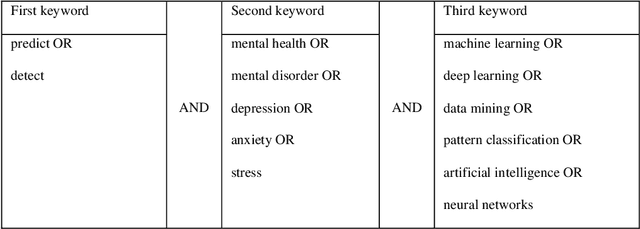
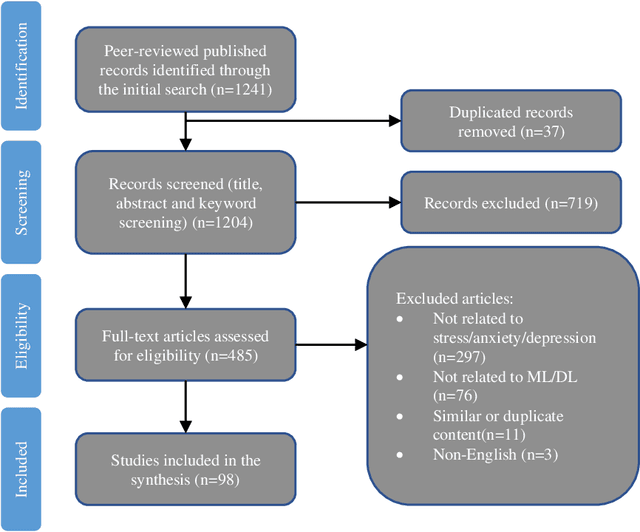
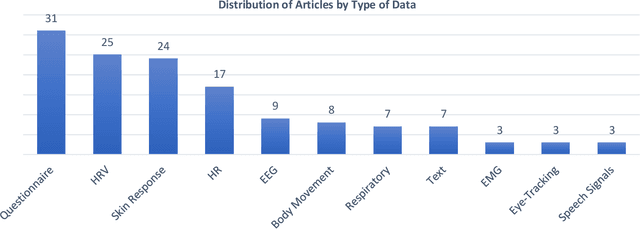
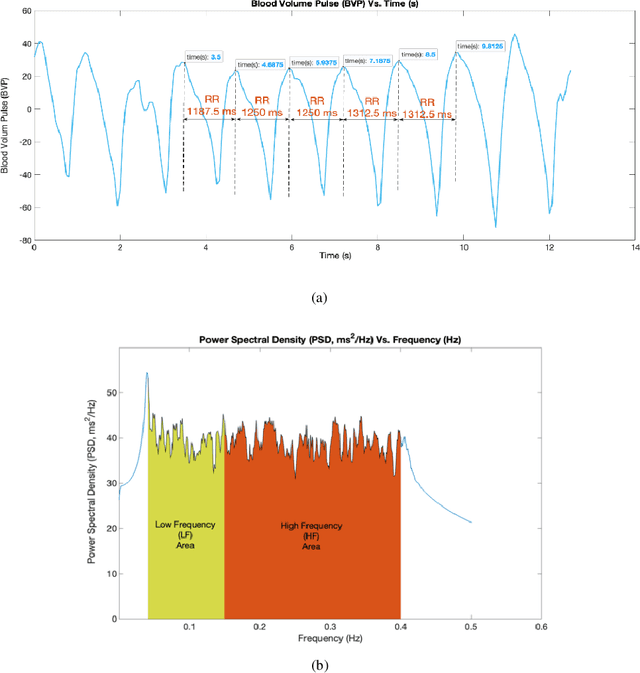
This comprehensive review systematically evaluates Machine Learning (ML) methodologies employed in the detection, prediction, and analysis of mental stress and its consequent mental disorders (MDs). Utilizing a rigorous scoping review process, the investigation delves into the latest ML algorithms, preprocessing techniques, and data types employed in the context of stress and stress-related MDs. The findings highlight that Support Vector Machine (SVM), Neural Network (NN), and Random Forest (RF) models consistently exhibit superior accuracy and robustness among all machine learning algorithms examined. Furthermore, the review underscores that physiological parameters, such as heart rate measurements and skin response, are prevalently used as stress predictors in ML algorithms. This is attributed to their rich explanatory information concerning stress and stress-related MDs, as well as the relative ease of data acquisition. Additionally, the application of dimensionality reduction techniques, including mappings, feature selection, filtering, and noise reduction, is frequently observed as a crucial step preceding the training of ML algorithms. The synthesis of this review identifies significant research gaps and outlines future directions for the field. These encompass areas such as model interpretability, model personalization, the incorporation of naturalistic settings, and real-time processing capabilities for detection and prediction of stress and stress-related MDs.
MT-IceNet -- A Spatial and Multi-Temporal Deep Learning Model for Arctic Sea Ice Forecasting
Aug 08, 2023Arctic amplification has altered the climate patterns both regionally and globally, resulting in more frequent and more intense extreme weather events in the past few decades. The essential part of Arctic amplification is the unprecedented sea ice loss as demonstrated by satellite observations. Accurately forecasting Arctic sea ice from sub-seasonal to seasonal scales has been a major research question with fundamental challenges at play. In addition to physics-based Earth system models, researchers have been applying multiple statistical and machine learning models for sea ice forecasting. Looking at the potential of data-driven approaches to study sea ice variations, we propose MT-IceNet - a UNet based spatial and multi-temporal (MT) deep learning model for forecasting Arctic sea ice concentration (SIC). The model uses an encoder-decoder architecture with skip connections and processes multi-temporal input streams to regenerate spatial maps at future timesteps. Using bi-monthly and monthly satellite retrieved sea ice data from NSIDC as well as atmospheric and oceanic variables from ERA5 reanalysis product during 1979-2021, we show that our proposed model provides promising predictive performance for per-pixel SIC forecasting with up to 60% decrease in prediction error for a lead time of 6 months as compared to its state-of-the-art counterparts.
* Published at IEEE BDCAT 2022. This version includes minor updates made in the text after original publication
Application for White Spot Syndrome Virus (WSSV) Monitoring using Edge Machine Learning
Aug 08, 2023The aquaculture industry, strongly reliant on shrimp exports, faces challenges due to viral infections like the White Spot Syndrome Virus (WSSV) that severely impact output yields. In this context, computer vision can play a significant role in identifying features not immediately evident to skilled or untrained eyes, potentially reducing the time required to report WSSV infections. In this study, the challenge of limited data for WSSV recognition was addressed. A mobile application dedicated to data collection and monitoring was developed to facilitate the creation of an image dataset to train a WSSV recognition model and improve country-wide disease surveillance. The study also includes a thorough analysis of WSSV recognition to address the challenge of imbalanced learning and on-device inference. The models explored, MobileNetV3-Small and EfficientNetV2-B0, gained an F1-Score of 0.72 and 0.99 respectively. The saliency heatmaps of both models were also observed to uncover the "black-box" nature of these models and to gain insight as to what features in the images are most important in making a prediction. These results highlight the effectiveness and limitations of using models designed for resource-constrained devices and balancing their performance in accurately recognizing WSSV, providing valuable information and direction in the use of computer vision in this domain.
Optimal partitioning of directed acyclic graphs with dependent costs between clusters
Aug 08, 2023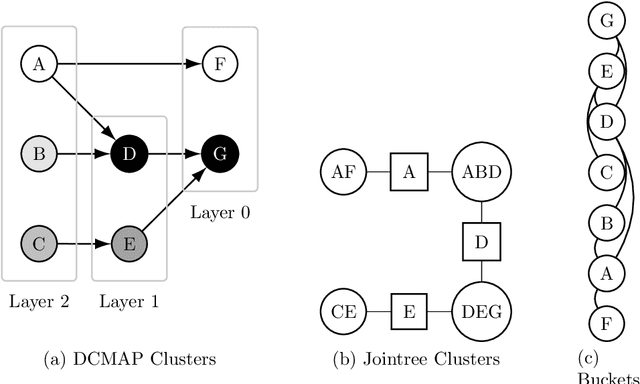

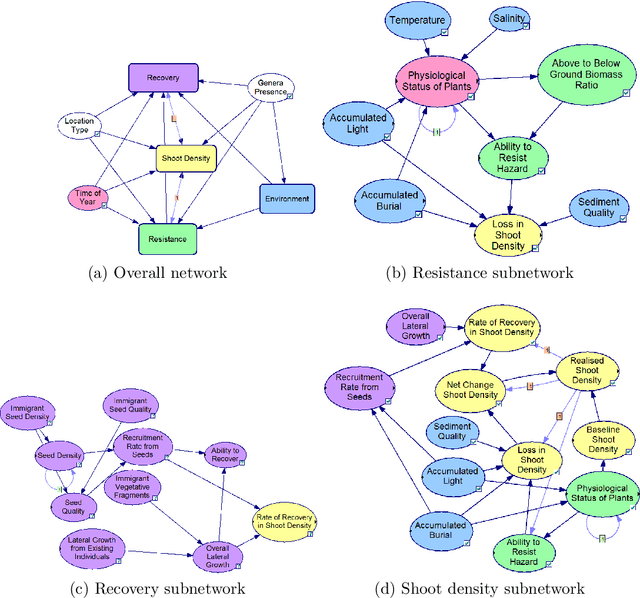
Many statistical inference contexts, including Bayesian Networks (BNs), Markov processes and Hidden Markov Models (HMMS) could be supported by partitioning (i.e.~mapping) the underlying Directed Acyclic Graph (DAG) into clusters. However, optimal partitioning is challenging, especially in statistical inference as the cost to be optimised is dependent on both nodes within a cluster, and the mapping of clusters connected via parent and/or child nodes, which we call dependent clusters. We propose a novel algorithm called DCMAP for optimal cluster mapping with dependent clusters. Given an arbitrarily defined, positive cost function based on the DAG and cluster mappings, we show that DCMAP converges to find all optimal clusters, and returns near-optimal solutions along the way. Empirically, we find that the algorithm is time-efficient for a DBN model of a seagrass complex system using a computation cost function. For a 25 and 50-node DBN, the search space size was $9.91\times 10^9$ and $1.51\times10^{21}$ possible cluster mappings, respectively, but near-optimal solutions with 88\% and 72\% similarity to the optimal solution were found at iterations 170 and 865, respectively. The first optimal solution was found at iteration 934 $(\text{95\% CI } 926,971)$, and 2256 $(2150,2271)$ with a cost that was 4\% and 0.2\% of the naive heuristic cost, respectively.
Asynchronous Evolution of Deep Neural Network Architectures
Aug 08, 2023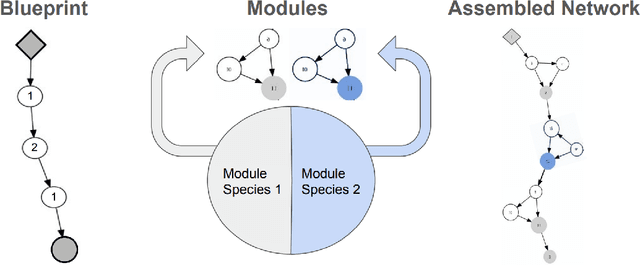
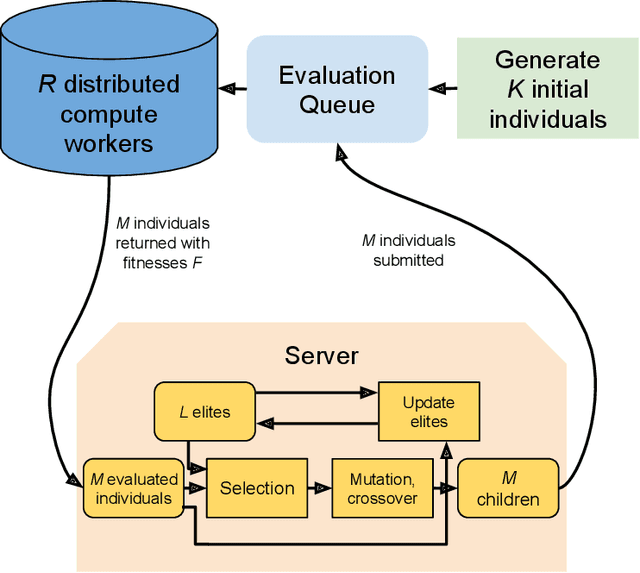
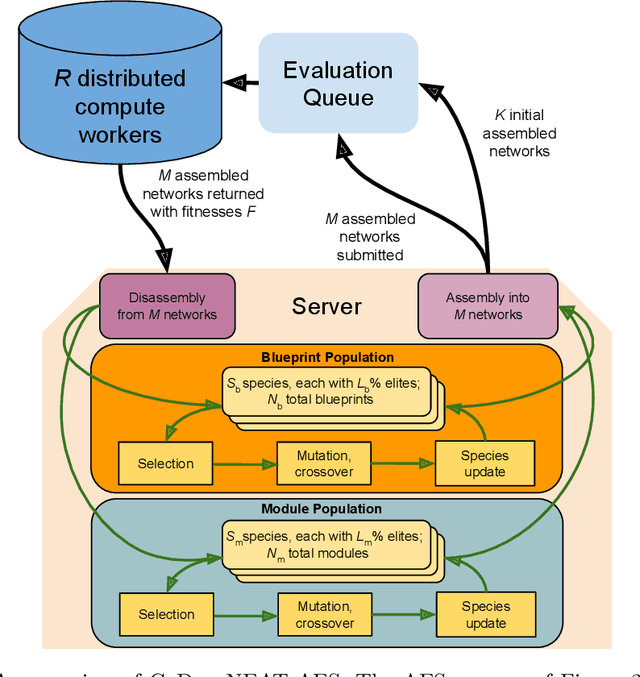
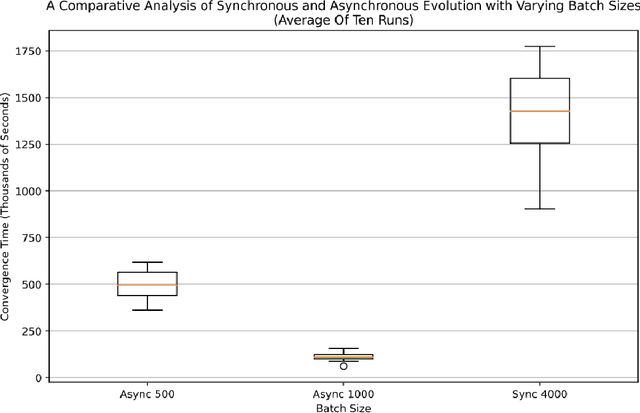
Many evolutionary algorithms (EAs) take advantage of parallel evaluation of candidates. However, if evaluation times vary significantly, many worker nodes (i.e.,\ compute clients) are idle much of the time, waiting for the next generation to be created. Evolutionary neural architecture search (ENAS), a class of EAs that optimizes the architecture and hyperparameters of deep neural networks, is particularly vulnerable to this issue. This paper proposes a generic asynchronous evaluation strategy (AES) that is then adapted to work with ENAS. AES increases throughput by maintaining a queue of upto $K$ individuals ready to be sent to the workers for evaluation and proceeding to the next generation as soon as $M<<K$ individuals have been evaluated by the workers. A suitable value for $M$ is determined experimentally, balancing diversity and efficiency. To showcase the generality and power of AES, it was first evaluated in 11-bit multiplexer design (a single-population verifiable discovery task) and then scaled up to ENAS for image captioning (a multi-population open-ended-optimization task). In both problems, a multifold performance improvement was observed, suggesting that AES is a promising method for parallelizing the evolution of complex systems with long and variable evaluation times, such as those in ENAS.
Target Detection on Hyperspectral Images Using MCMC and VI Trained Bayesian Neural Networks
Aug 11, 2023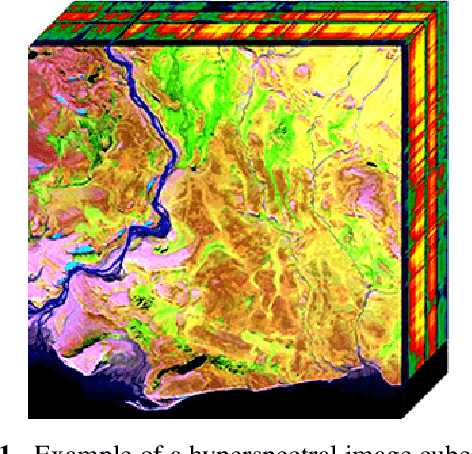
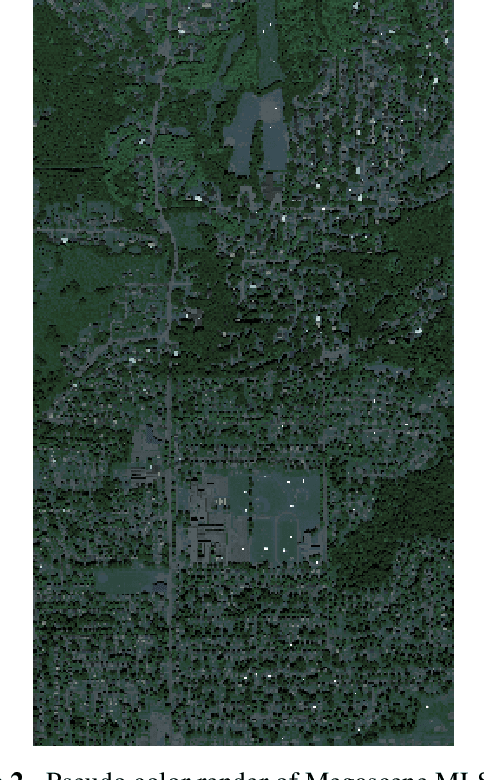

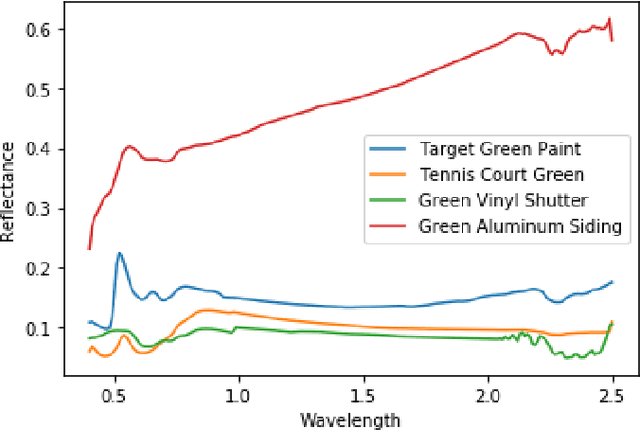
Neural networks (NN) have become almost ubiquitous with image classification, but in their standard form produce point estimates, with no measure of confidence. Bayesian neural networks (BNN) provide uncertainty quantification (UQ) for NN predictions and estimates through the posterior distribution. As NN are applied in more high-consequence applications, UQ is becoming a requirement. BNN provide a solution to this problem by not only giving accurate predictions and estimates, but also an interval that includes reasonable values within a desired probability. Despite their positive attributes, BNN are notoriously difficult and time consuming to train. Traditional Bayesian methods use Markov Chain Monte Carlo (MCMC), but this is often brushed aside as being too slow. The most common method is variational inference (VI) due to its fast computation, but there are multiple concerns with its efficacy. We apply and compare MCMC- and VI-trained BNN in the context of target detection in hyperspectral imagery (HSI), where materials of interest can be identified by their unique spectral signature. This is a challenging field, due to the numerous permuting effects practical collection of HSI has on measured spectra. Both models are trained using out-of-the-box tools on a high fidelity HSI target detection scene. Both MCMC- and VI-trained BNN perform well overall at target detection on a simulated HSI scene. This paper provides an example of how to utilize the benefits of UQ, but also to increase awareness that different training methods can give different results for the same model. If sufficient computational resources are available, the best approach rather than the fastest or most efficient should be used, especially for high consequence problems.
Dynamic Privacy Allocation for Locally Differentially Private Federated Learning with Composite Objectives
Aug 02, 2023
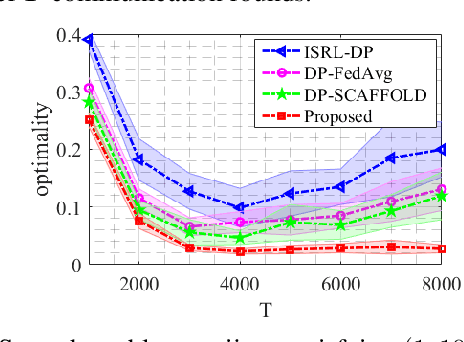
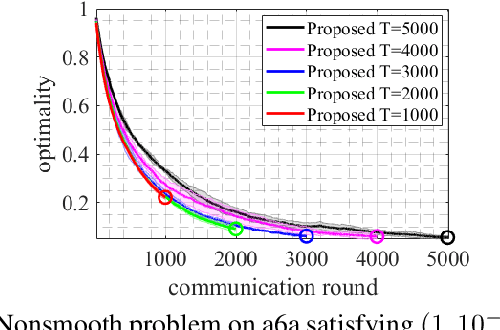
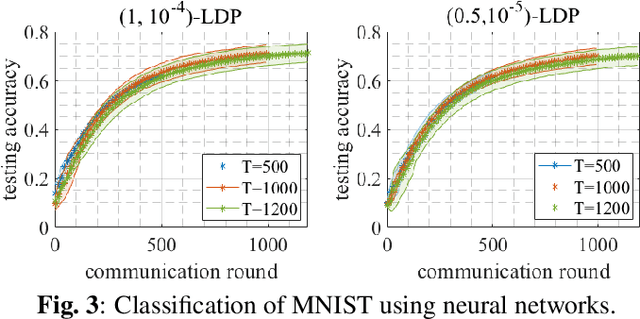
This paper proposes a locally differentially private federated learning algorithm for strongly convex but possibly nonsmooth problems that protects the gradients of each worker against an honest but curious server. The proposed algorithm adds artificial noise to the shared information to ensure privacy and dynamically allocates the time-varying noise variance to minimize an upper bound of the optimization error subject to a predefined privacy budget constraint. This allows for an arbitrarily large but finite number of iterations to achieve both privacy protection and utility up to a neighborhood of the optimal solution, removing the need for tuning the number of iterations. Numerical results show the superiority of the proposed algorithm over state-of-the-art methods.
Semi-supervised Contrastive Regression for Estimation of Eye Gaze
Aug 05, 2023With the escalated demand of human-machine interfaces for intelligent systems, development of gaze controlled system have become a necessity. Gaze, being the non-intrusive form of human interaction, is one of the best suited approach. Appearance based deep learning models are the most widely used for gaze estimation. But the performance of these models is entirely influenced by the size of labeled gaze dataset and in effect affects generalization in performance. This paper aims to develop a semi-supervised contrastive learning framework for estimation of gaze direction. With a small labeled gaze dataset, the framework is able to find a generalized solution even for unseen face images. In this paper, we have proposed a new contrastive loss paradigm that maximizes the similarity agreement between similar images and at the same time reduces the redundancy in embedding representations. Our contrastive regression framework shows good performance in comparison to several state of the art contrastive learning techniques used for gaze estimation.
Textual Data Mining for Financial Fraud Detection: A Deep Learning Approach
Aug 05, 2023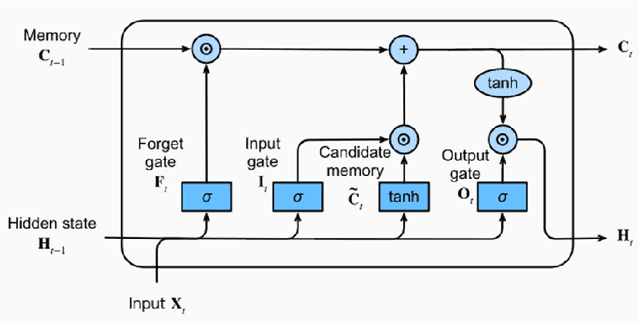
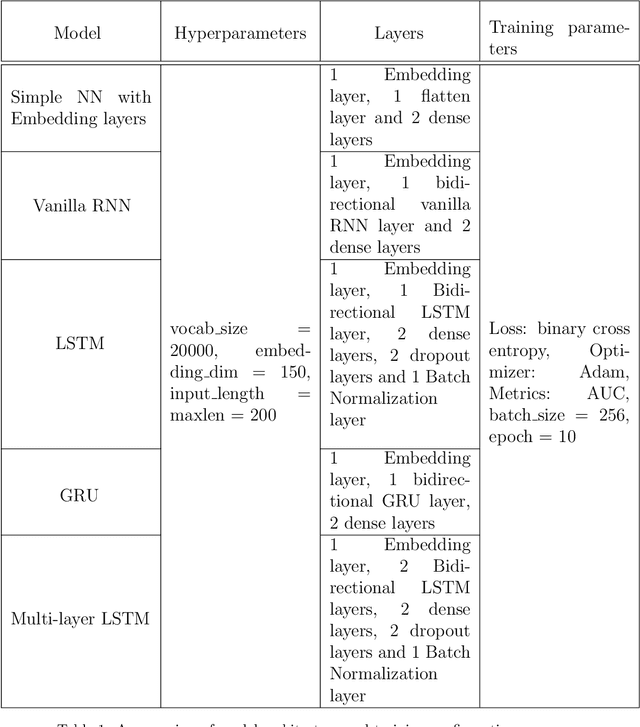
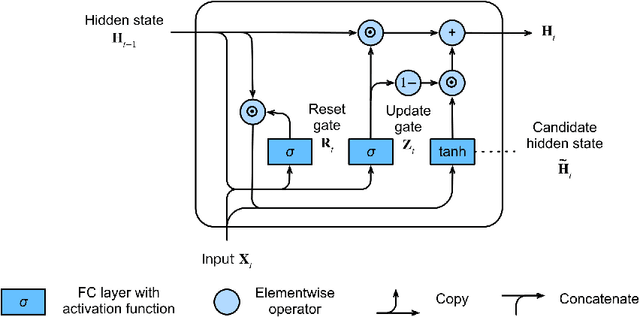
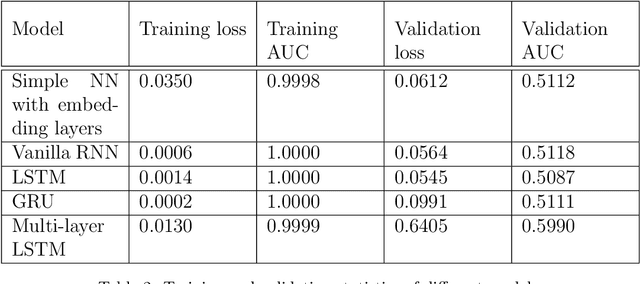
In this report, I present a deep learning approach to conduct a natural language processing (hereafter NLP) binary classification task for analyzing financial-fraud texts. First, I searched for regulatory announcements and enforcement bulletins from HKEX news to define fraudulent companies and to extract their MD&A reports before I organized the sentences from the reports with labels and reporting time. My methodology involved different kinds of neural network models, including Multilayer Perceptrons with Embedding layers, vanilla Recurrent Neural Network (RNN), Long-Short Term Memory (LSTM), and Gated Recurrent Unit (GRU) for the text classification task. By utilizing this diverse set of models, I aim to perform a comprehensive comparison of their accuracy in detecting financial fraud. My results bring significant implications for financial fraud detection as this work contributes to the growing body of research at the intersection of deep learning, NLP, and finance, providing valuable insights for industry practitioners, regulators, and researchers in the pursuit of more robust and effective fraud detection methodologies.