 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
RBF Weighted Hyper-Involution for RGB-D Object Detection
Sep 30, 2023
A vast majority of conventional augmented reality devices are equipped with depth sensors. Depth images produced by such sensors contain complementary information for object detection when used with color images. Despite the benefits, it remains a complex task to simultaneously extract photometric and depth features in real time due to the immanent difference between depth and color images. Moreover, standard convolution operations are not sufficient to properly extract information directly from raw depth images leading to intermediate representations of depth which is inefficient. To address these issues, we propose a real-time and two stream RGBD object detection model. The proposed model consists of two new components: a depth guided hyper-involution that adapts dynamically based on the spatial interaction pattern in the raw depth map and an up-sampling based trainable fusion layer that combines the extracted depth and color image features without blocking the information transfer between them. We show that the proposed model outperforms other RGB-D based object detection models on NYU Depth v2 dataset and achieves comparable (second best) results on SUN RGB-D. Additionally, we introduce a new outdoor RGB-D object detection dataset where our proposed model outperforms other models. The performance evaluation on diverse synthetic data generated from CAD models and images shows the potential of the proposed model to be adapted to augmented reality based applications.
Multiple Physics-Informed Neural Network for Biomedical Tube Flows
Sep 26, 2023Fluid dynamics computations for tube-like geometries are important for biomedical evaluation of vascular and airway fluid dynamics. Physics-Informed Neural Networks (PINNs) have recently emerged as a good alternative to traditional computational fluid dynamics (CFD) methods. The vanilla PINN, however, requires much longer training time than the traditional CFD methods for each specific flow scenario and thus does not justify its mainstream use. Here, we explore the use of the multi-case PINN approach for calculating biomedical tube flows, where varied geometry cases are parameterized and pre-trained on the PINN, such that results for unseen geometries can be obtained in real time. Our objective is to identify network architecture, tube-specific, and regularization strategies that can optimize this, via experiments on a series of idealized 2D stenotic tube flows.
AUTOPARLLM: GNN-Guided Automatic Code Parallelization using Large Language Models
Oct 09, 2023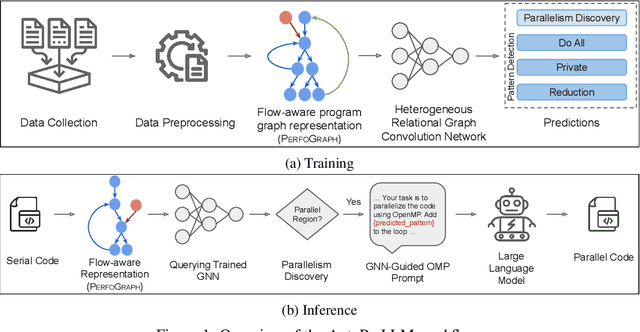
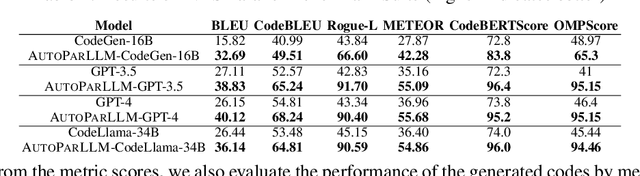


Parallelizing sequentially written programs is a challenging task. Even experienced developers need to spend considerable time finding parallelism opportunities and then actually writing parallel versions of sequentially written programs. To address this issue, we present AUTOPARLLM, a framework for automatically discovering parallelism and generating the parallel version of the sequentially written program. Our framework consists of two major components: i) a heterogeneous Graph Neural Network (GNN) based parallelism discovery and parallel pattern detection module, and ii) an LLM-based code generator to generate the parallel counterpart of the sequential programs. We use the GNN to learn the flow-aware characteristics of the programs to identify parallel regions in sequential programs and then construct an enhanced prompt using the GNN's results for the LLM-based generator to finally produce the parallel counterparts of the sequential programs. We evaluate AUTOPARLLM on 11 applications of 2 well-known benchmark suites: NAS Parallel Benchmark and Rodinia Benchmark. Our results show that AUTOPARLLM is indeed effective in improving the state-of-the-art LLM-based models for the task of parallel code generation in terms of multiple code generation metrics. AUTOPARLLM also improves the average runtime of the parallel code generated by the state-of-the-art LLMs by as high as 3.4% and 2.9% for the NAS Parallel Benchmark and Rodinia Benchmark respectively. Additionally, to overcome the issue that well-known metrics for translation evaluation have not been optimized to evaluate the quality of the generated parallel code, we propose OMPScore for evaluating the quality of the generated code. We show that OMPScore exhibits a better correlation with human judgment than existing metrics, measured by up to 75% improvement of Spearman correlation.
Robust Losses for Decision-Focused Learning
Oct 06, 2023Optimization models used to make discrete decisions often contain uncertain parameters that are context-dependent and are estimated through prediction. To account for the quality of the decision made based on the prediction, decision-focused learning (end-to-end predict-then-optimize) aims at training the predictive model to minimize regret, i.e., the loss incurred by making a suboptimal decision. Despite the challenge of this loss function being possibly non-convex and in general non-differentiable, effective gradient-based learning approaches have been proposed to minimize the expected loss, using the empirical loss as a surrogate. However, empirical regret can be an ineffective surrogate because the uncertainty in the optimization model makes the empirical regret unequal to the expected regret in expectation. To illustrate the impact of this inequality, we evaluate the effect of aleatoric and epistemic uncertainty on the accuracy of empirical regret as a surrogate. Next, we propose three robust loss functions that more closely approximate expected regret. Experimental results show that training two state-of-the-art decision-focused learning approaches using robust regret losses improves test-sample empirical regret in general while keeping computational time equivalent relative to the number of training epochs.
PGraphDTA: Improving Drug Target Interaction Prediction using Protein Language Models and Contact Maps
Oct 06, 2023

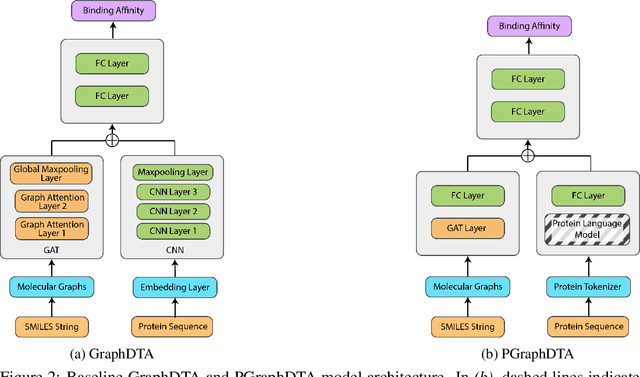
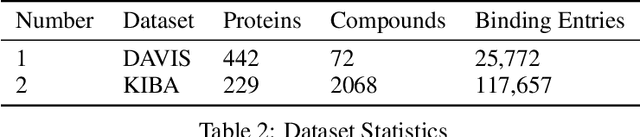
Developing and discovering new drugs is a complex and resource-intensive endeavor that often involves substantial costs, time investment, and safety concerns. A key aspect of drug discovery involves identifying novel drug-target (DT) interactions. Existing computational methods for predicting DT interactions have primarily focused on binary classification tasks, aiming to determine whether a DT pair interacts or not. However, protein-ligand interactions exhibit a continuum of binding strengths, known as binding affinity, presenting a persistent challenge for accurate prediction. In this study, we investigate various techniques employed in Drug Target Interaction (DTI) prediction and propose novel enhancements to enhance their performance. Our approaches include the integration of Protein Language Models (PLMs) and the incorporation of Contact Map information as an inductive bias within current models. Through extensive experimentation, we demonstrate that our proposed approaches outperform the baseline models considered in this study, presenting a compelling case for further development in this direction. We anticipate that the insights gained from this work will significantly narrow the search space for potential drugs targeting specific proteins, thereby accelerating drug discovery. Code and data for PGraphDTA are available at https://anonymous.4open.science/r/PGraphDTA.
Ultimate limit on learning non-Markovian behavior: Fisher information rate and excess information
Oct 06, 2023We address the fundamental limits of learning unknown parameters of any stochastic process from time-series data, and discover exact closed-form expressions for how optimal inference scales with observation length. Given a parametrized class of candidate models, the Fisher information of observed sequence probabilities lower-bounds the variance in model estimation from finite data. As sequence-length increases, the minimal variance scales as the square inverse of the length -- with constant coefficient given by the information rate. We discover a simple closed-form expression for this information rate, even in the case of infinite Markov order. We furthermore obtain the exact analytic lower bound on model variance from the observation-induced metadynamic among belief states. We discover ephemeral, exponential, and more general modes of convergence to the asymptotic information rate. Surprisingly, this myopic information rate converges to the asymptotic Fisher information rate with exactly the same relaxation timescales that appear in the myopic entropy rate as it converges to the Shannon entropy rate for the process. We illustrate these results with a sequence of examples that highlight qualitatively distinct features of stochastic processes that shape optimal learning.
Multilingual Natural Language Processing Model for Radiology Reports -- The Summary is all you need!
Oct 06, 2023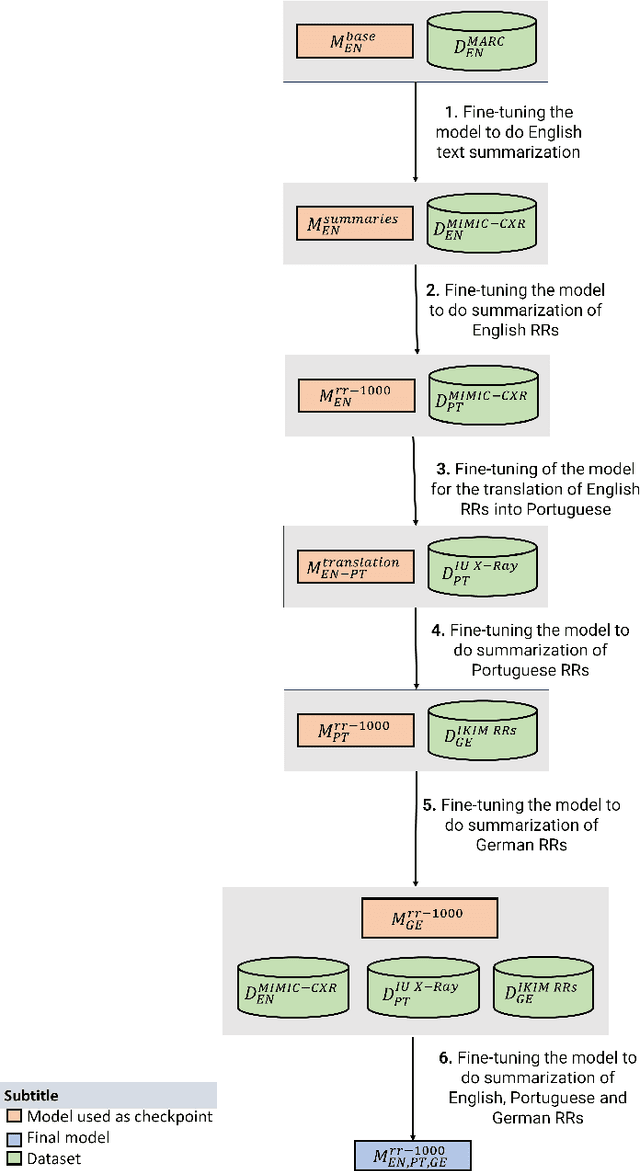

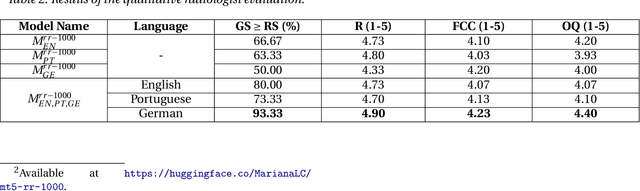
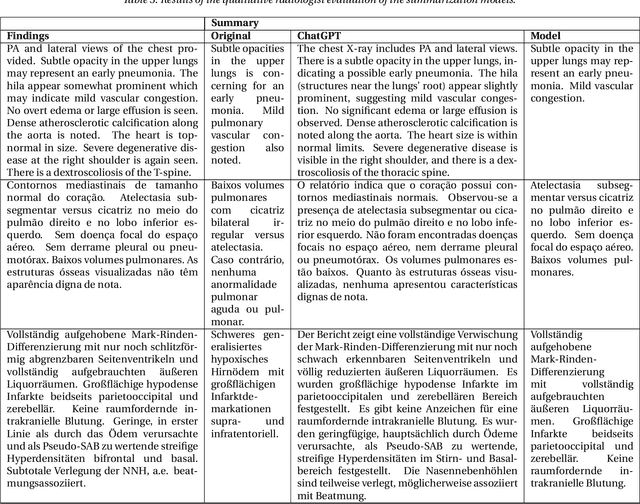
The impression section of a radiology report summarizes important radiology findings and plays a critical role in communicating these findings to physicians. However, the preparation of these summaries is time-consuming and error-prone for radiologists. Recently, numerous models for radiology report summarization have been developed. Nevertheless, there is currently no model that can summarize these reports in multiple languages. Such a model could greatly improve future research and the development of Deep Learning models that incorporate data from patients with different ethnic backgrounds. In this study, the generation of radiology impressions in different languages was automated by fine-tuning a model, publicly available, based on a multilingual text-to-text Transformer to summarize findings available in English, Portuguese, and German radiology reports. In a blind test, two board-certified radiologists indicated that for at least 70% of the system-generated summaries, the quality matched or exceeded the corresponding human-written summaries, suggesting substantial clinical reliability. Furthermore, this study showed that the multilingual model outperformed other models that specialized in summarizing radiology reports in only one language, as well as models that were not specifically designed for summarizing radiology reports, such as ChatGPT.
Statistical physics, Bayesian inference and neural information processing
Sep 29, 2023

Lecture notes from the course given by Professor Sara A. Solla at the Les Houches summer school on "Statistical physics of Machine Learning". The notes discuss neural information processing through the lens of Statistical Physics. Contents include Bayesian inference and its connection to a Gibbs description of learning and generalization, Generalized Linear Models as a controlled alternative to backpropagation through time, and linear and non-linear techniques for dimensionality reduction.
YOLORe-IDNet: An Efficient Multi-Camera System for Person-Tracking
Sep 23, 2023The growing need for video surveillance in public spaces has created a demand for systems that can track individuals across multiple cameras feeds in real-time. While existing tracking systems have achieved impressive performance using deep learning models, they often rely on pre-existing images of suspects or historical data. However, this is not always feasible in cases where suspicious individuals are identified in real-time and without prior knowledge. We propose a person-tracking system that combines correlation filters and Intersection Over Union (IOU) constraints for robust tracking, along with a deep learning model for cross-camera person re-identification (Re-ID) on top of YOLOv5. The proposed system quickly identifies and tracks suspect in real-time across multiple cameras and recovers well after full or partial occlusion, making it suitable for security and surveillance applications. It is computationally efficient and achieves a high F1-Score of 79% and an IOU of 59% comparable to existing state-of-the-art algorithms, as demonstrated in our evaluation on a publicly available OTB-100 dataset. The proposed system offers a robust and efficient solution for the real-time tracking of individuals across multiple camera feeds. Its ability to track targets without prior knowledge or historical data is a significant improvement over existing systems, making it well-suited for public safety and surveillance applications.
Physics-Informed Neural Networks for Accelerating Power System State Estimation
Oct 04, 2023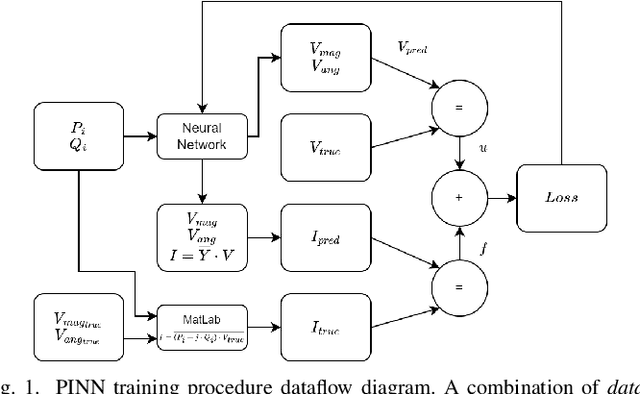
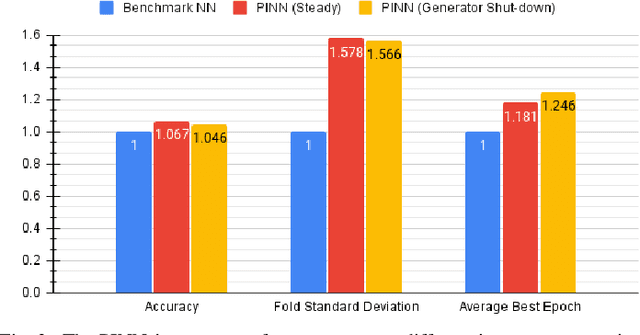
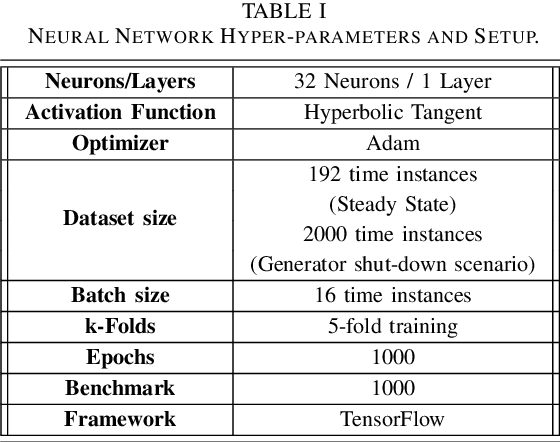
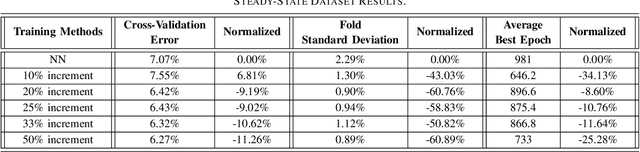
State estimation is the cornerstone of the power system control center since it provides the operating condition of the system in consecutive time intervals. This work investigates the application of physics-informed neural networks (PINNs) for accelerating power systems state estimation in monitoring the operation of power systems. Traditional state estimation techniques often rely on iterative algorithms that can be computationally intensive, particularly for large-scale power systems. In this paper, a novel approach that leverages the inherent physical knowledge of power systems through the integration of PINNs is proposed. By incorporating physical laws as prior knowledge, the proposed method significantly reduces the computational complexity associated with state estimation while maintaining high accuracy. The proposed method achieves up to 11% increase in accuracy, 75% reduction in standard deviation of results, and 30% faster convergence, as demonstrated by comprehensive experiments on the IEEE 14-bus system.