 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Prediction of financial time series using LSTM and data denoising methods
Mar 05, 2021
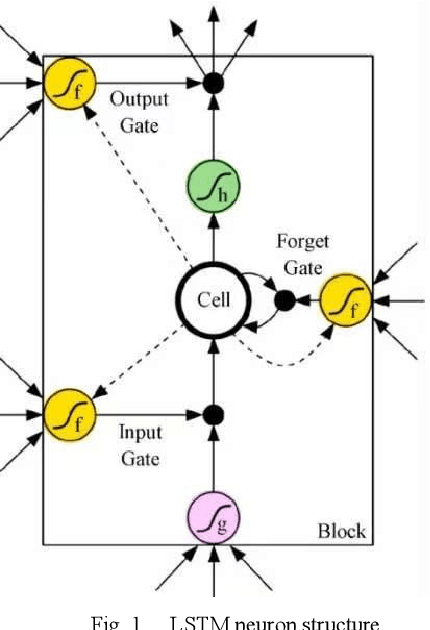

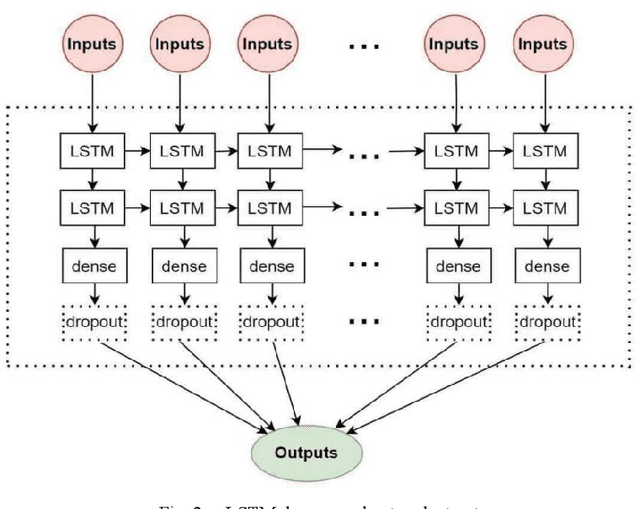

In order to further overcome the difficulties of the existing models in dealing with the non-stationary and nonlinear characteristics of high-frequency financial time series data, especially its weak generalization ability, this paper proposes an ensemble method based on data denoising methods, including the wavelet transform (WT) and singular spectrum analysis (SSA), and long-term short-term memory neural network (LSTM) to build a data prediction model, The financial time series is decomposed and reconstructed by WT and SSA to denoise. Under the condition of denoising, the smooth sequence with effective information is reconstructed. The smoothing sequence is introduced into LSTM and the predicted value is obtained. With the Dow Jones industrial average index (DJIA) as the research object, the closing price of the DJIA every five minutes is divided into short-term (1 hour), medium-term (3 hours) and long-term (6 hours) respectively. . Based on root mean square error (RMSE), mean absolute error (MAE), mean absolute percentage error (MAPE) and absolute percentage error standard deviation (SDAPE), the experimental results show that in the short-term, medium-term and long-term, data denoising can greatly improve the accuracy and stability of the prediction, and can effectively improve the generalization ability of LSTM prediction model. As WT and SSA can extract useful information from the original sequence and avoid overfitting, the hybrid model can better grasp the sequence pattern of the closing price of the DJIA. And the WT-LSTM model is better than the benchmark LSTM model and SSA-LSTM model.
Weakly Supervised Instance Attention for Multisource Fine-Grained Object Recognition with an Application to Tree Species Classification
May 25, 2021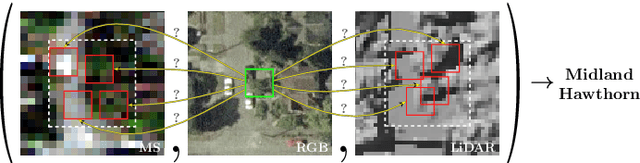
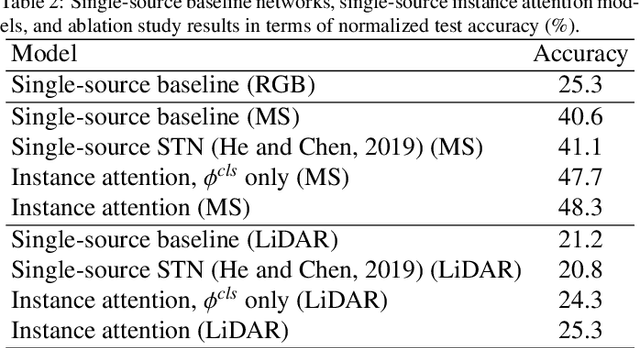
Multisource image analysis that leverages complementary spectral, spatial, and structural information benefits fine-grained object recognition that aims to classify an object into one of many similar subcategories. However, for multisource tasks that involve relatively small objects, even the smallest registration errors can introduce high uncertainty in the classification process. We approach this problem from a weakly supervised learning perspective in which the input images correspond to larger neighborhoods around the expected object locations where an object with a given class label is present in the neighborhood without any knowledge of its exact location. The proposed method uses a single-source deep instance attention model with parallel branches for joint localization and classification of objects, and extends this model into a multisource setting where a reference source that is assumed to have no location uncertainty is used to aid the fusion of multiple sources in four different levels: probability level, logit level, feature level, and pixel level. We show that all levels of fusion provide higher accuracies compared to the state-of-the-art, with the best performing method of feature-level fusion resulting in 53% accuracy for the recognition of 40 different types of trees, corresponding to an improvement of 5.7% over the best performing baseline when RGB, multispectral, and LiDAR data are used. We also provide an in-depth comparison by evaluating each model at various parameter complexity settings, where the increased model capacity results in a further improvement of 6.3% over the default capacity setting.
Surface Disinfection using Ultraviolet Lightwith a Mobile Manipulation Robot
Apr 21, 2021

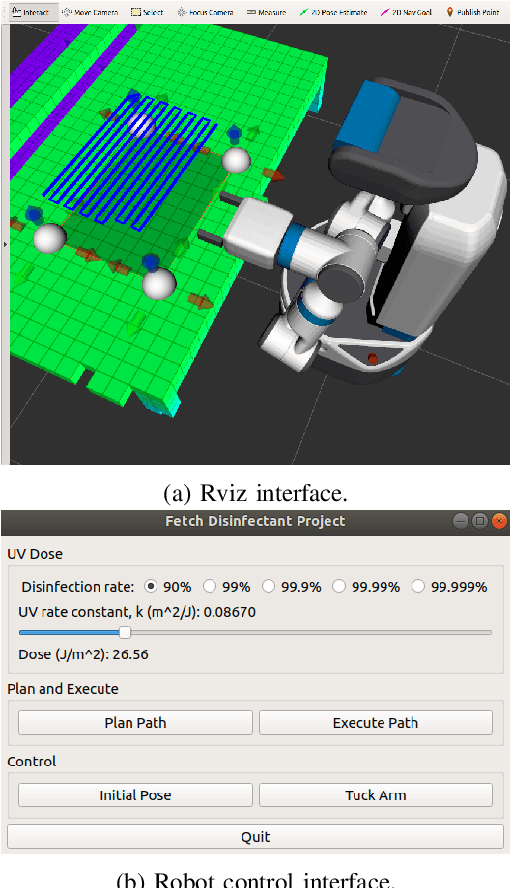

Robots are being increasingly used in the fight against highly-infectious diseases such as Ebola, MERS, and SARS-COV-2. Many of the robots that are being used employ ultraviolet lights mounted on a mobile base to inactivate the pathogens. However, these lights are often mounted in a fixed configuration and do not provide adequate decontamination of horizontal surfaces, which can be a major source of cross-contamination. In the paper, we describe the design, implementation, and testing of an Ultraviolet Germicidal Irradiation (UVGI) system implemented on a mobile manipulation robot. A human supervisor designates a surface for disinfection, the robot autonomously plans and executes an end-effector trajectory to disinfect the surface to the required certainty, and then displays the results for the human supervisor to verify. We also provide some background information on UVGI and describe how we constructed and validated mathematical models of Ultraviolet (UV) radiation propagation and accumulation. Finally, we describe our implementation on a Fetch mobile manipulation platform, and discuss how the practicalities of implementation on a real robot affect our models.
Frame-independent vector-cloud neural network for nonlocal constitutive modelling on arbitrary grids
Mar 11, 2021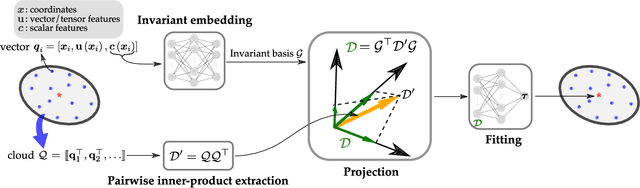
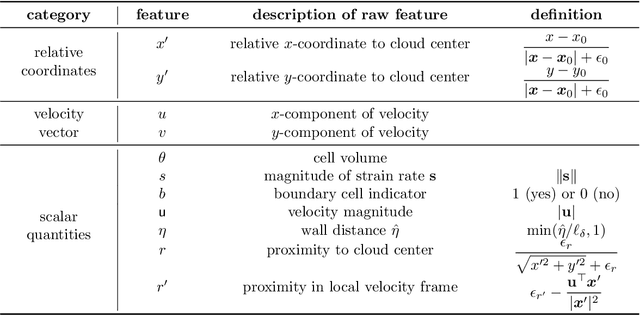

Constitutive models are widely used for modelling complex systems in science and engineering, where first-principle-based, well-resolved simulations are often prohibitively expensive. For example, in fluid dynamics, constitutive models are required to describe nonlocal, unresolved physics such as turbulence and laminar-turbulent transition. In particular, Reynolds stress models for turbulence and intermittency transport equations for laminar-turbulent transition both utilize convection--diffusion partial differential equations (PDEs). However, traditional PDE-based constitutive models can lack robustness and are often too rigid to accommodate diverse calibration data. We propose a frame-independent, nonlocal constitutive model based on a vector-cloud neural network that can be trained with data. The learned constitutive model can predict the closure variable at a point based on the flow information in its neighborhood. Such nonlocal information is represented by a group of points, each having a feature vector attached to it, and thus the input is referred to as vector cloud. The cloud is mapped to the closure variable through a frame-independent neural network, which is invariant both to coordinate translation and rotation and to the ordering of points in the cloud. As such, the network takes any number of arbitrarily arranged grid points as input and thus is suitable for unstructured meshes commonly used in fluid flow simulations. The merits of the proposed network are demonstrated on scalar transport PDEs on a family of parameterized periodic hill geometries. Numerical results show that the vector-cloud neural network is a promising tool not only as nonlocal constitutive models and but also as general surrogate models for PDEs on irregular domains.
L3DAS21 Challenge: Machine Learning for 3D Audio Signal Processing
Apr 29, 2021
The L3DAS21 Challenge is aimed at encouraging and fostering collaborative research on machine learning for 3D audio signal processing, with particular focus on 3D speech enhancement (SE) and 3D sound localization and detection (SELD). Alongside with the challenge, we release the L3DAS21 dataset, a 65 hours 3D audio corpus, accompanied with a Python API that facilitates the data usage and results submission stage. Usually, machine learning approaches to 3D audio tasks are based on single-perspective Ambisonics recordings or on arrays of single-capsule microphones. We propose, instead, a novel multichannel audio configuration based multiple-source and multiple-perspective Ambisonics recordings, performed with an array of two first-order Ambisonics microphones. To the best of our knowledge, it is the first time that a dual-mic Ambisonics configuration is used for these tasks. We provide baseline models and results for both tasks, obtained with state-of-the-art architectures: FaSNet for SE and SELDNet for SELD. This report is aimed at providing all needed information to participate in the L3DAS21 Challenge, illustrating the details of the L3DAS21 dataset, the challenge tasks and the baseline models.
Towards Metric GPR Migration based on DNN Noise Removal and Dielectric Estimation
Apr 21, 2021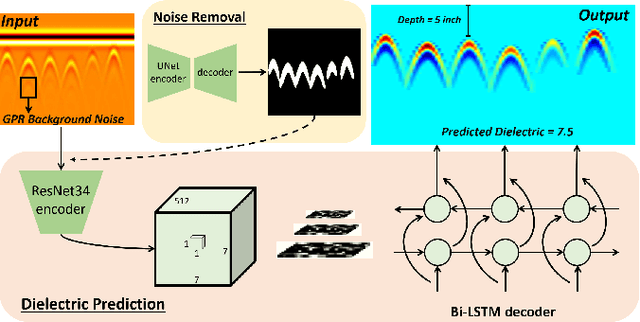

Ground Penetrating Radar (GPR) is one of the most important non-destructive evaluation (NDE) devices to detect the subsurface objects (i.e. rebars, utility pipes) and reveal the underground scene. Due to the background noise and unknown dielectric property of GPR data, the reconstruction of the subsurface objects with metric information remains the main challenge in GPR inspection. In this letter, a novel metric GPR migration method is proposed consisting of three steps to address the above challenge. Firstly, a noise removal segmentation model is introduced to clear the GPR raw data; furthermore, a DielectricNet is proposed to predict the dielectric of each GPR B-scan data and the depth of a target object; at the last step, we optimize the migration algorithm by using random motion pattern, thus to obtain the 3D metric migration result. We use both the field and synthetic data to verify the proposed method, experimental results show that our proposed method is able to achieve at least 10% improvement in reconstruction accuracy compared with the conventional migration methods.
Post-Hoc Domain Adaptation via Guided Data Homogenization
Apr 08, 2021

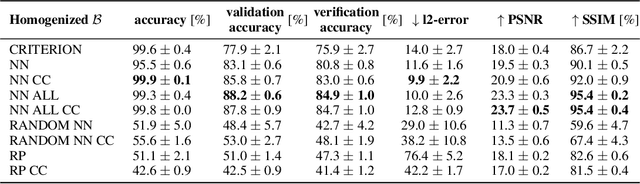
Addressing shifts in data distributions is an important prerequisite for the deployment of deep learning models to real-world settings. A general approach to this problem involves the adjustment of models to a new domain through transfer learning. However, in many cases, this is not applicable in a post-hoc manner to deployed models and further parameter adjustments jeopardize safety certifications that were established beforehand. In such a context, we propose to deal with changes in the data distribution via guided data homogenization which shifts the burden of adaptation from the model to the data. This approach makes use of information about the training data contained implicitly in the deep learning model to learn a domain transfer function. This allows for a targeted deployment of models to unknown scenarios without changing the model itself. We demonstrate the potential of data homogenization through experiments on the CIFAR-10 and MNIST data sets.
FaceLeaks: Inference Attacks against Transfer Learning Models via Black-box Queries
Oct 27, 2020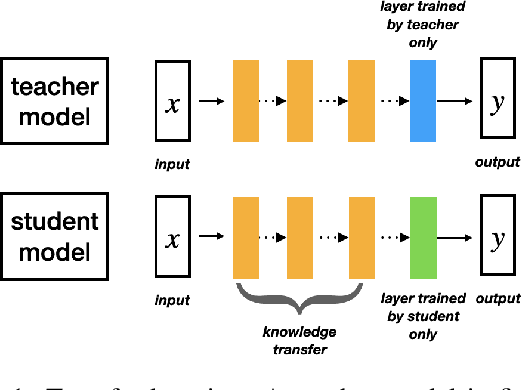
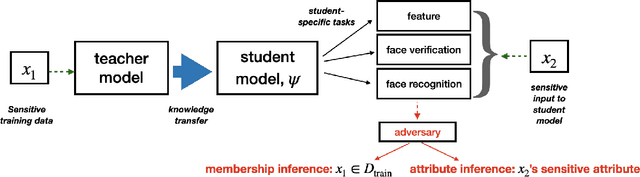
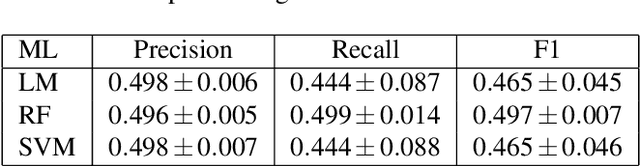
Transfer learning is a useful machine learning framework that allows one to build task-specific models (student models) without significantly incurring training costs using a single powerful model (teacher model) pre-trained with a large amount of data. The teacher model may contain private data, or interact with private inputs. We investigate if one can leak or infer such private information without interacting with the teacher model directly. We describe such inference attacks in the context of face recognition, an application of transfer learning that is highly sensitive to personal privacy. Under black-box and realistic settings, we show that existing inference techniques are ineffective, as interacting with individual training instances through the student models does not reveal information about the teacher. We then propose novel strategies to infer from aggregate-level information. Consequently, membership inference attacks on the teacher model are shown to be possible, even when the adversary has access only to the student models. We further demonstrate that sensitive attributes can be inferred, even in the case where the adversary has limited auxiliary information. Finally, defensive strategies are discussed and evaluated. Our extensive study indicates that information leakage is a real privacy threat to the transfer learning framework widely used in real-life situations.
Convergence analysis of the information matrix in Gaussian belief propagation
Apr 13, 2017Gaussian belief propagation (BP) has been widely used for distributed estimation in large-scale networks such as the smart grid, communication networks, and social networks, where local measurements/observations are scattered over a wide geographical area. However, the convergence of Gaus- sian BP is still an open issue. In this paper, we consider the convergence of Gaussian BP, focusing in particular on the convergence of the information matrix. We show analytically that the exchanged message information matrix converges for arbitrary positive semidefinite initial value, and its dis- tance to the unique positive definite limit matrix decreases exponentially fast.
RIS-Aided Cell-Free Massive MIMO: Performance Analysis and Competitiveness
May 06, 2021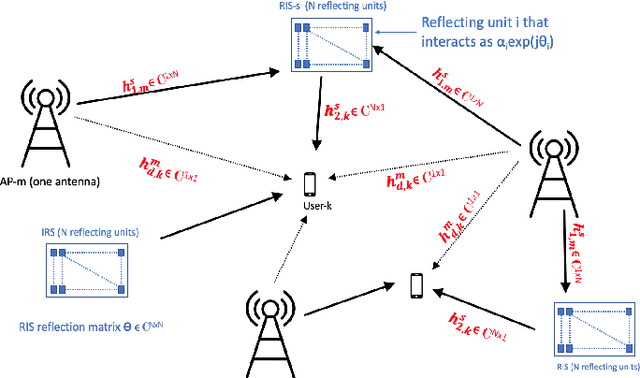
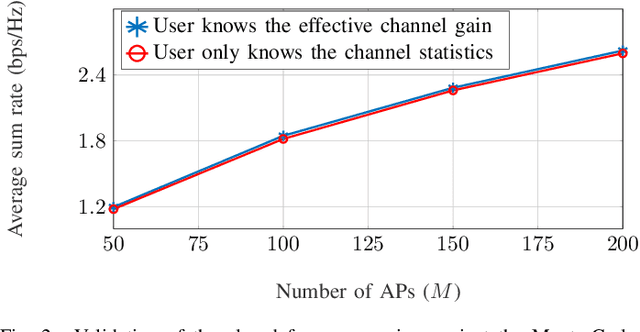
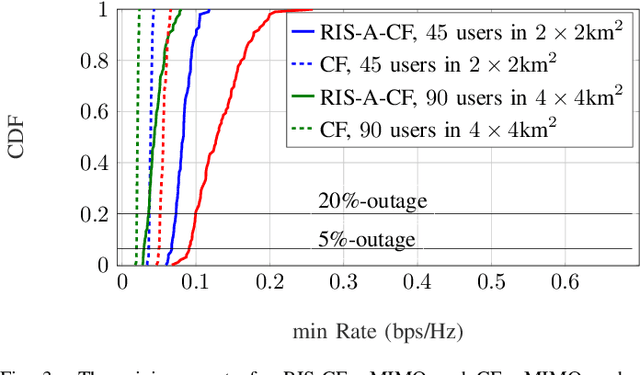
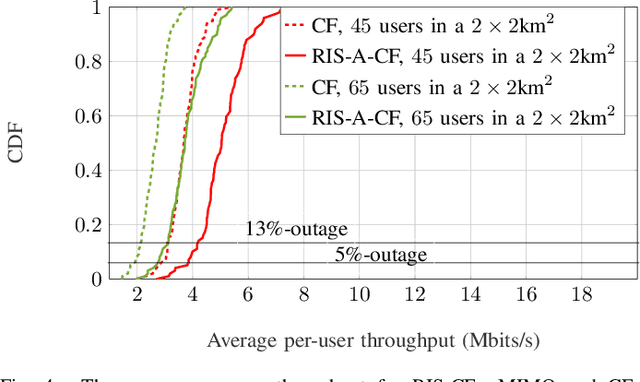
In this paper, we consider and study a cell-free massive MIMO (CF-mMIMO) system aided with reconfigurable intelligent surfaces (RISs), where a large number of access points (APs) cooperate to serve a smaller number of users with the help of RIS technology. We consider imperfect channel state information (CSI), where each AP uses the local channel estimates obtained from the uplink pilots and applies conjugate beamforming for downlink data transmission. Additionally, we consider random beamforming at the RIS during both training and data transmission phases. This allows us to eliminate the need of estimating each RIS assisted link, which has been proven to be a challenging task in literature. We then derive a closed-form expression for the achievable rate and use it to evaluate the system's performance supported with numerical results. We show that the RIS provided array gain improves the system's coverage, and provides nearly a 2-fold increase in the minimum rate and a 1.5-fold increase in the per-user throughput. We also use the results to provide preliminary insights on the number of RISs that need to be used to replace an AP, while achieving similar performance as a typical CF-mMIMO system with dense AP deployment.