 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
ToupleGDD: A Fine-Designed Solution of Influence Maximization by Deep Reinforcement Learning
Oct 18, 2022
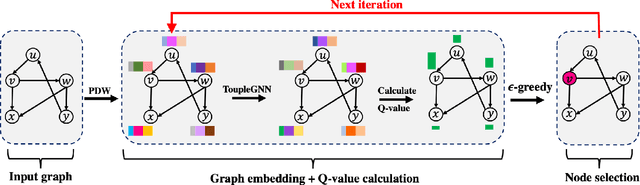
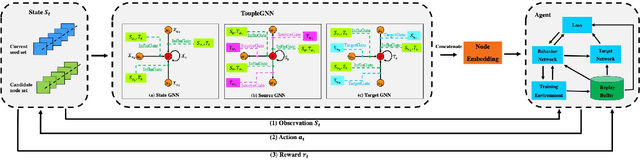
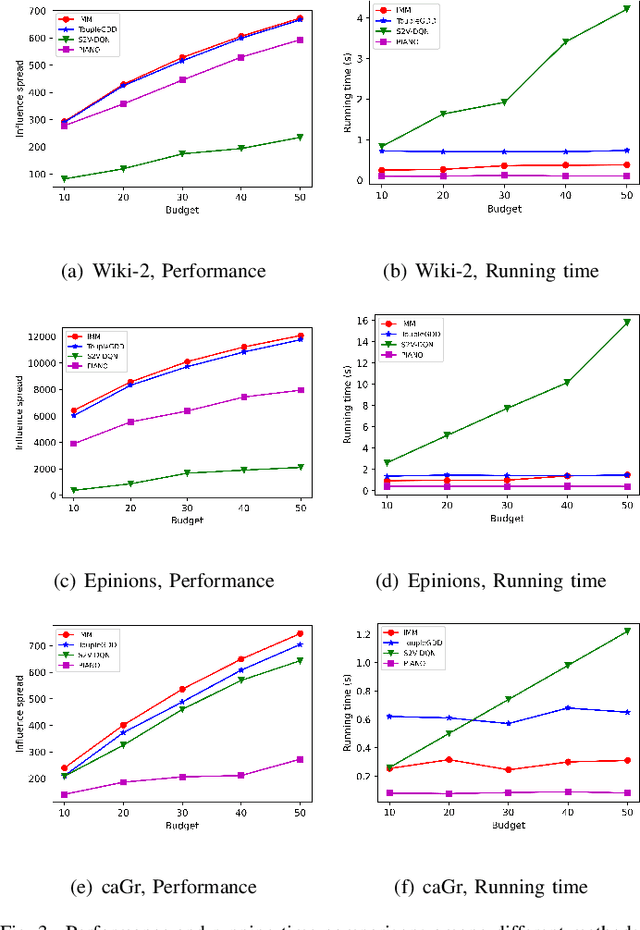
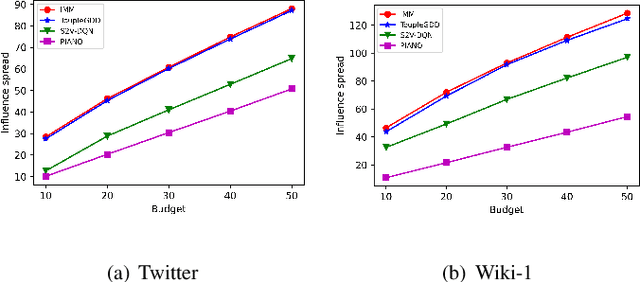
Online social platforms have become more and more popular, and the dissemination of information on social networks has attracted wide attention of the industries and academia. Aiming at selecting a small subset of nodes with maximum influence on networks, the Influence Maximization (IM) problem has been extensively studied. Since it is #P-hard to compute the influence spread given a seed set, the state-of-art methods, including heuristic and approximation algorithms, faced with great difficulties such as theoretical guarantee, time efficiency, generalization, etc. This makes it unable to adapt to large-scale networks and more complex applications. With the latest achievements of Deep Reinforcement Learning (DRL) in artificial intelligence and other fields, a lot of works has focused on exploiting DRL to solve the combinatorial optimization problems. Inspired by this, we propose a novel end-to-end DRL framework, ToupleGDD, to address the IM problem in this paper, which incorporates three coupled graph neural networks for network embedding and double deep Q-networks for parameters learning. Previous efforts to solve the IM problem with DRL trained their models on the subgraph of the whole network, and then tested their performance on the whole graph, which makes the performance of their models unstable among different networks. However, our model is trained on several small randomly generated graphs and tested on completely different networks, and can obtain results that are very close to the state-of-the-art methods. In addition, our model is trained with a small budget, and it can perform well under various large budgets in the test, showing strong generalization ability. Finally, we conduct entensive experiments on synthetic and realistic datasets, and the experimental results prove the effectiveness and superiority of our model.
Fuse: In-Situ Sensemaking Support in the Browser
Aug 31, 2022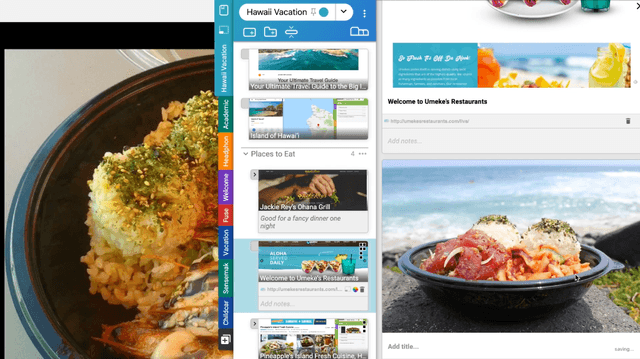

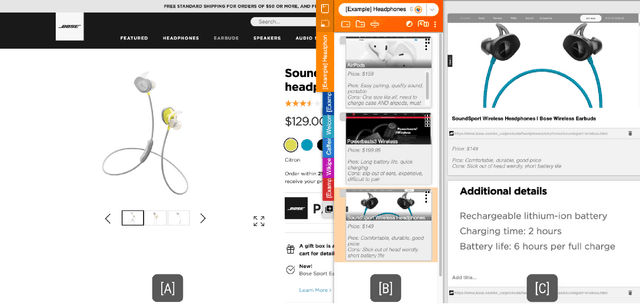
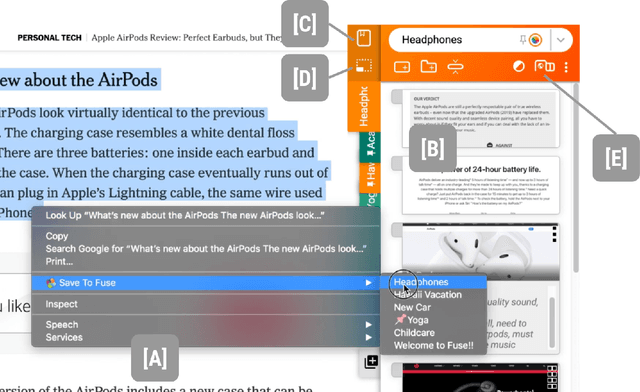
People spend a significant amount of time trying to make sense of the internet, collecting content from a variety of sources and organizing it to make decisions and achieve their goals. While humans are able to fluidly iterate on collecting and organizing information in their minds, existing tools and approaches introduce significant friction into the process. We introduce Fuse, a browser extension that externalizes users' working memory by combining low-cost collection with lightweight organization of content in a compact card-based sidebar that is always available. Fuse helps users simultaneously extract key web content and structure it in a lightweight and visual way. We discuss how these affordances help users externalize more of their mental model into the system (e.g., saving, annotating, and structuring items) and support fast reviewing and resumption of task contexts. Our 22-month public deployment and follow-up interviews provide longitudinal insights into the structuring behaviors of real-world users conducting information foraging tasks.
InfoSeg: Unsupervised Semantic Image Segmentation with Mutual Information Maximization
Oct 07, 2021
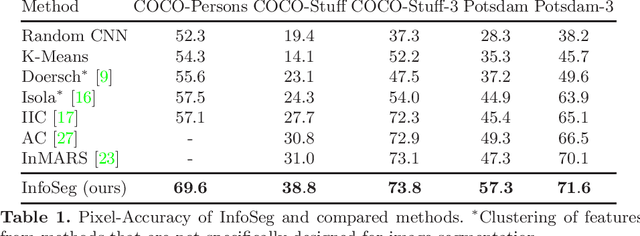
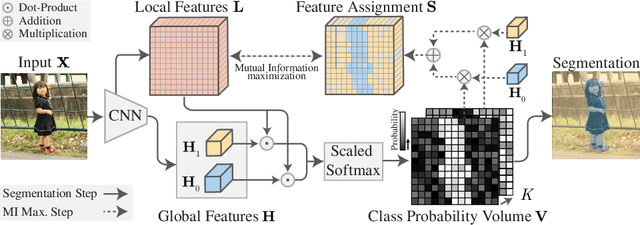
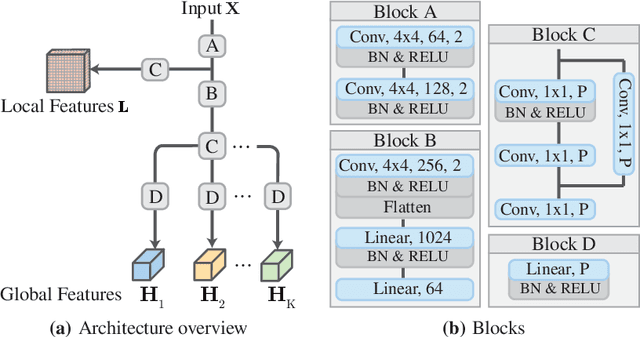
We propose a novel method for unsupervised semantic image segmentation based on mutual information maximization between local and global high-level image features. The core idea of our work is to leverage recent progress in self-supervised image representation learning. Representation learning methods compute a single high-level feature capturing an entire image. In contrast, we compute multiple high-level features, each capturing image segments of one particular semantic class. To this end, we propose a novel two-step learning procedure comprising a segmentation and a mutual information maximization step. In the first step, we segment images based on local and global features. In the second step, we maximize the mutual information between local features and high-level features of their respective class. For training, we provide solely unlabeled images and start from random network initialization. For quantitative and qualitative evaluation, we use established benchmarks, and COCO-Persons, whereby we introduce the latter in this paper as a challenging novel benchmark. InfoSeg significantly outperforms the current state-of-the-art, e.g., we achieve a relative increase of 26% in the Pixel Accuracy metric on the COCO-Stuff dataset.
Research on restaurant recommendation using machine learning
Aug 10, 2022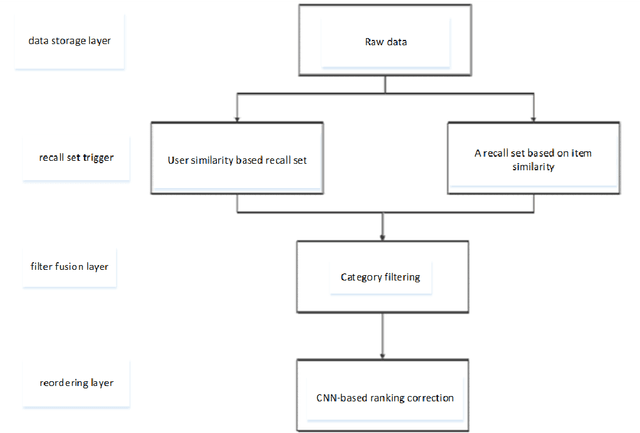



A recommender system is a system that helps users filter irrelevant information and create user interest models based on their historical records. With the continuous development of Internet information, recommendation systems have received widespread attention in the industry. In this era of ubiquitous data and information, how to obtain and analyze these data has become the research topic of many people. In view of this situation, this paper makes some brief overviews of machine learning-related recommendation systems. By analyzing some technologies and ideas used by machine learning in recommender systems, let more people understand what is Big data and what is machine learning. The most important point is to let everyone understand the profound impact of machine learning on our daily life.
Look where you look! Saliency-guided Q-networks for visual RL tasks
Sep 29, 2022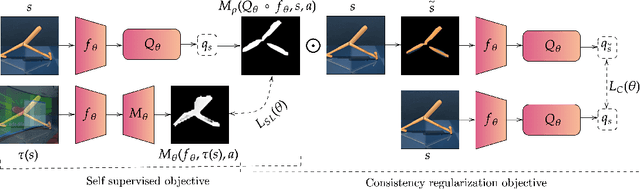
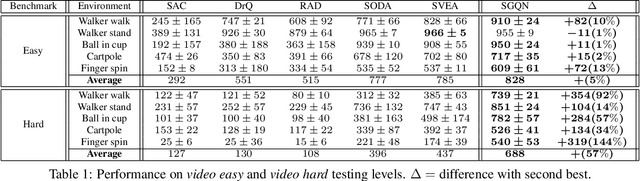

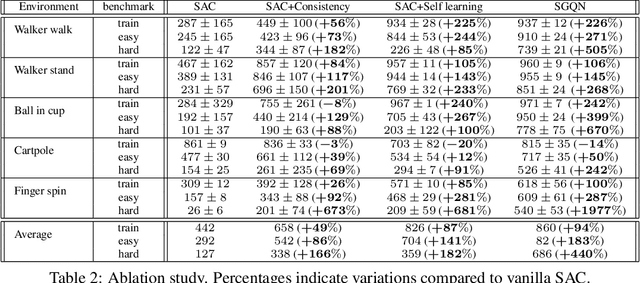
Deep reinforcement learning policies, despite their outstanding efficiency in simulated visual control tasks, have shown disappointing ability to generalize across disturbances in the input training images. Changes in image statistics or distracting background elements are pitfalls that prevent generalization and real-world applicability of such control policies. We elaborate on the intuition that a good visual policy should be able to identify which pixels are important for its decision, and preserve this identification of important sources of information across images. This implies that training of a policy with small generalization gap should focus on such important pixels and ignore the others. This leads to the introduction of saliency-guided Q-networks (SGQN), a generic method for visual reinforcement learning, that is compatible with any value function learning method. SGQN vastly improves the generalization capability of Soft Actor-Critic agents and outperforms existing stateof-the-art methods on the Deepmind Control Generalization benchmark, setting a new reference in terms of training efficiency, generalization gap, and policy interpretability.
COMPS: Conceptual Minimal Pair Sentences for testing Property Knowledge and Inheritance in Pre-trained Language Models
Oct 05, 2022
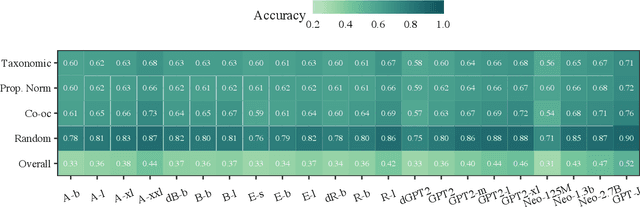
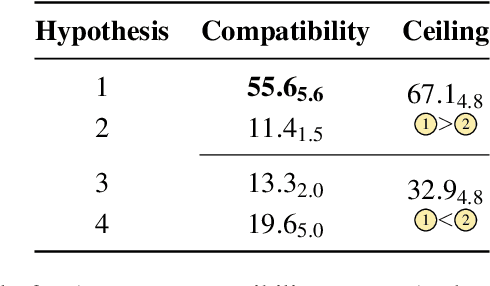

A characteristic feature of human semantic memory is its ability to not only store and retrieve the properties of concepts observed through experience, but to also facilitate the inheritance of properties (can breathe) from superordinate concepts (animal) to their subordinates (dog) -- i.e. demonstrate property inheritance. In this paper, we present COMPS, a collection of minimal pair sentences that jointly tests pre-trained language models (PLMs) on their ability to attribute properties to concepts and their ability to demonstrate property inheritance behavior. Analyses of 22 different PLMs on COMPS reveal that they can easily distinguish between concepts on the basis of a property when they are trivially different, but find it relatively difficult when concepts are related on the basis of nuanced knowledge representations. Furthermore, we find that PLMs can demonstrate behavior consistent with property inheritance to a great extent, but fail in the presence of distracting information, which decreases the performance of many models, sometimes even below chance. This lack of robustness in demonstrating simple reasoning raises important questions about PLMs' capacity to make correct inferences even when they appear to possess the prerequisite knowledge.
Dual-Domain Cross-Iteration Squeeze-Excitation Network for Sparse Reconstruction of Brain MRI
Oct 05, 2022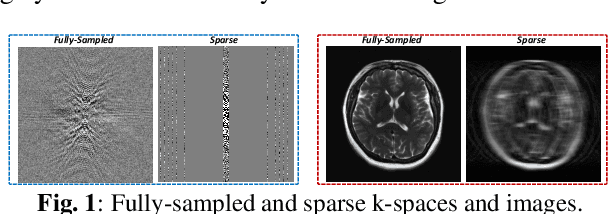
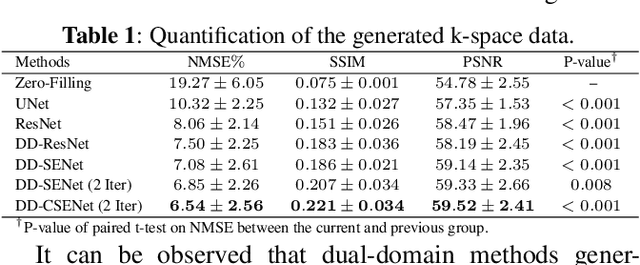
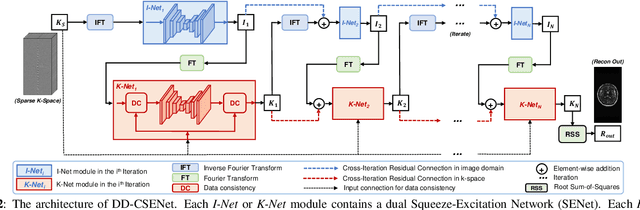
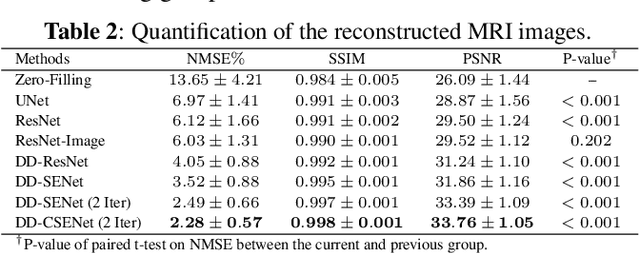
Magnetic resonance imaging (MRI) is one of the most commonly applied tests in neurology and neurosurgery. However, the utility of MRI is largely limited by its long acquisition time, which might induce many problems including patient discomfort and motion artifacts. Acquiring fewer k-space sampling is a potential solution to reducing the total scanning time. However, it can lead to severe aliasing reconstruction artifacts and thus affect the clinical diagnosis. Nowadays, deep learning has provided new insights into the sparse reconstruction of MRI. In this paper, we present a new approach to this problem that iteratively fuses the information of k-space and MRI images using novel dual Squeeze-Excitation Networks and Cross-Iteration Residual Connections. This study included 720 clinical multi-coil brain MRI cases adopted from the open-source deidentified fastMRI Dataset. 8-folder downsampling rate was applied to generate the sparse k-space. Results showed that the average reconstruction error over 120 testing cases by our proposed method was 2.28%, which outperformed the existing image-domain prediction (6.03%, p<0.001), k-space synthesis (6.12%, p<0.001), and dual-domain feature fusion (4.05%, p<0.001).
Token Classification for Disambiguating Medical Abbreviations
Oct 05, 2022
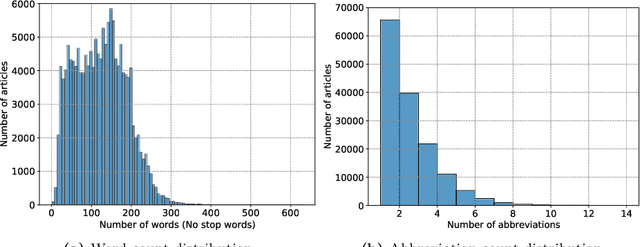
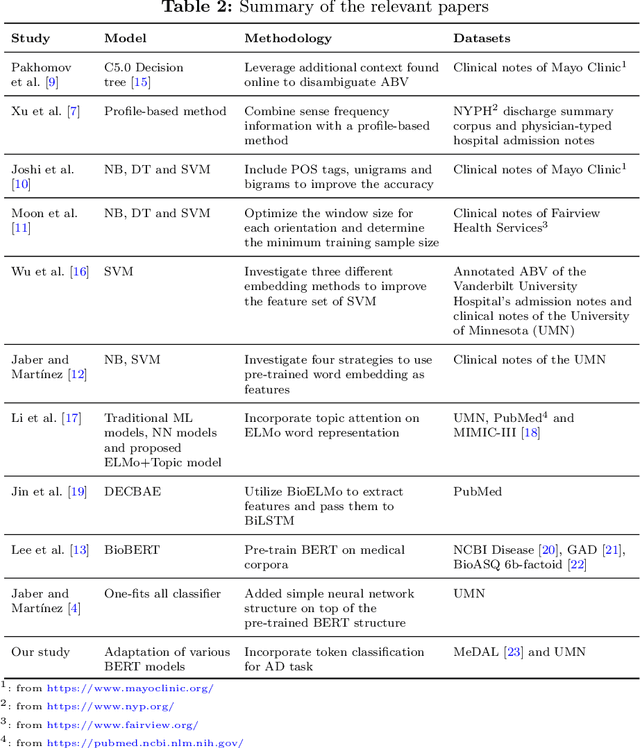
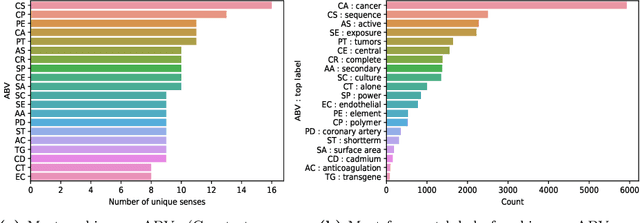
Abbreviations are unavoidable yet critical parts of the medical text. Using abbreviations, especially in clinical patient notes, can save time and space, protect sensitive information, and help avoid repetitions. However, most abbreviations might have multiple senses, and the lack of a standardized mapping system makes disambiguating abbreviations a difficult and time-consuming task. The main objective of this study is to examine the feasibility of token classification methods for medical abbreviation disambiguation. Specifically, we explore the capability of token classification methods to deal with multiple unique abbreviations in a single text. We use two public datasets to compare and contrast the performance of several transformer models pre-trained on different scientific and medical corpora. Our proposed token classification approach outperforms the more commonly used text classification models for the abbreviation disambiguation task. In particular, the SciBERT model shows a strong performance for both token and text classification tasks over the two considered datasets. Furthermore, we find that abbreviation disambiguation performance for the text classification models becomes comparable to that of token classification only when postprocessing is applied to their predictions, which involves filtering possible labels for an abbreviation based on the training data.
Pay Self-Attention to Audio-Visual Navigation
Oct 05, 2022
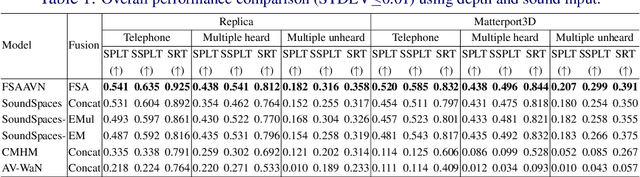
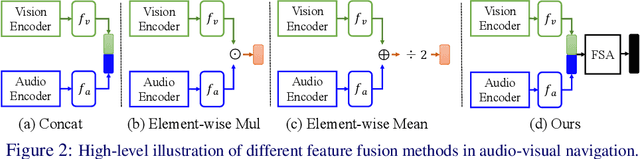
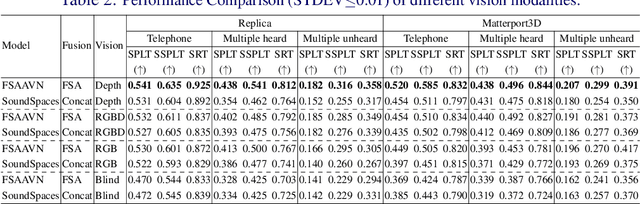
Audio-visual embodied navigation, as a hot research topic, aims training a robot to reach an audio target using egocentric visual (from the sensors mounted on the robot) and audio (emitted from the target) input. The audio-visual information fusion strategy is naturally important to the navigation performance, but the state-of-the-art methods still simply concatenate the visual and audio features, potentially ignoring the direct impact of context. Moreover, the existing approaches requires either phase-wise training or additional aid (e.g. topology graph and sound semantics). Up till this date, the work that deals with the more challenging setup with moving target(s) is still rare. As a result, we propose an end-to-end framework FSAAVN (feature self-attention audio-visual navigation) to learn chasing after a moving audio target using a context-aware audio-visual fusion strategy implemented as a self-attention module. Our thorough experiments validate the superior performance (both quantitatively and qualitatively) of FSAAVN in comparison with the state-of-the-arts, and also provide unique insights about the choice of visual modalities, visual/audio encoder backbones and fusion patterns.
Design Perspectives of Multitask Deep Learning Models and Applications
Sep 27, 2022In recent years, multi-task learning has turned out to be of great success in various applications. Though single model training has promised great results throughout these years, it ignores valuable information that might help us estimate a metric better. Under learning-related tasks, multi-task learning has been able to generalize the models even better. We try to enhance the feature mapping of the multi-tasking models by sharing features among related tasks and inductive transfer learning. Also, our interest is in learning the task relationships among various tasks for acquiring better benefits from multi-task learning. In this chapter, our objective is to visualize the existing multi-tasking models, compare their performances, the methods used to evaluate the performance of the multi-tasking models, discuss the problems faced during the design and implementation of these models in various domains, and the advantages and milestones achieved by them