 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
QS-ADN: Quasi-Supervised Artifact Disentanglement Network for Low-Dose CT Image Denoising by Local Similarity Among Unpaired Data
Feb 08, 2023
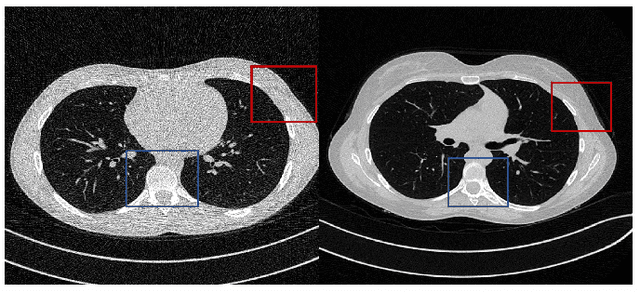
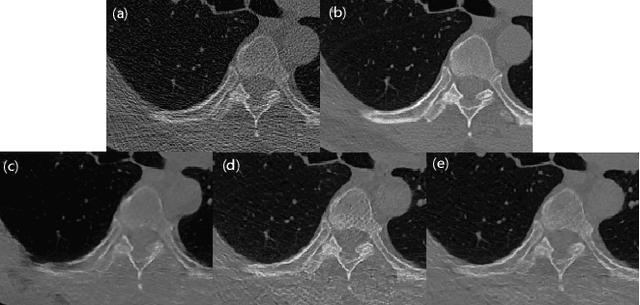
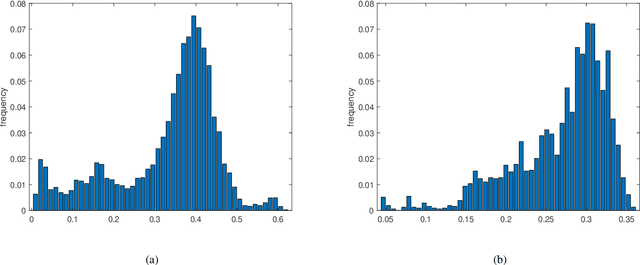
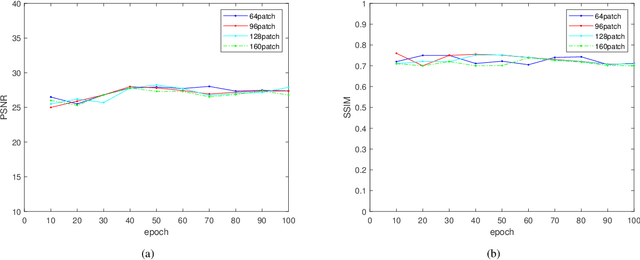
Deep learning has been successfully applied to low-dose CT (LDCT) image denoising for reducing potential radiation risk. However, the widely reported supervised LDCT denoising networks require a training set of paired images, which is expensive to obtain and cannot be perfectly simulated. Unsupervised learning utilizes unpaired data and is highly desirable for LDCT denoising. As an example, an artifact disentanglement network (ADN) relies on unparied images and obviates the need for supervision but the results of artifact reduction are not as good as those through supervised learning.An important observation is that there is often hidden similarity among unpaired data that can be utilized. This paper introduces a new learning mode, called quasi-supervised learning, to empower the ADN for LDCT image denoising.For every LDCT image, the best matched image is first found from an unpaired normal-dose CT (NDCT) dataset. Then, the matched pairs and the corresponding matching degree as prior information are used to construct and train our ADN-type network for LDCT denoising.The proposed method is different from (but compatible with) supervised and semi-supervised learning modes and can be easily implemented by modifying existing networks. The experimental results show that the method is competitive with state-of-the-art methods in terms of noise suppression and contextual fidelity. The code and working dataset are publicly available at https://github.com/ruanyuhui/ADN-QSDL.git.
Health Information Retrieval -- State of the art report
May 18, 2022This report provides an overview of the field of Information Retrieval (IR) in healthcare. It does not aim to introduce general concepts and theories of IR but to present and describe specific aspects of Health Information Retrieval (HIR). After a brief introduction to the more broader field of IR, the significance of HIR at current times is discussed. Specific characteristics of Health Information, its classification and the main existing representations for health concepts are described together with the main products and services in the area (e.g.: databases of health bibliographic content, health specific search engines and others). Recent research work is discussed and the most active researchers, projects and research groups are also presented. Main organizations and journals are also identified.
Pixel Relationships-based Regularizer for Retinal Vessel Image Segmentation
Dec 28, 2022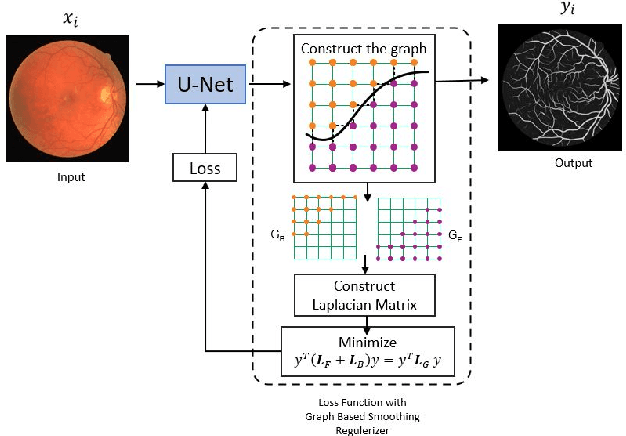
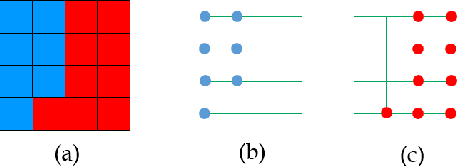
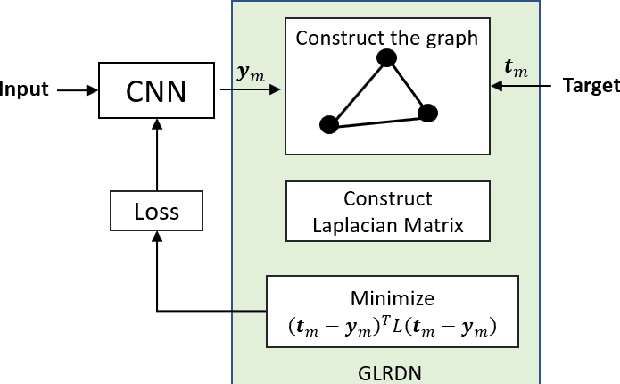
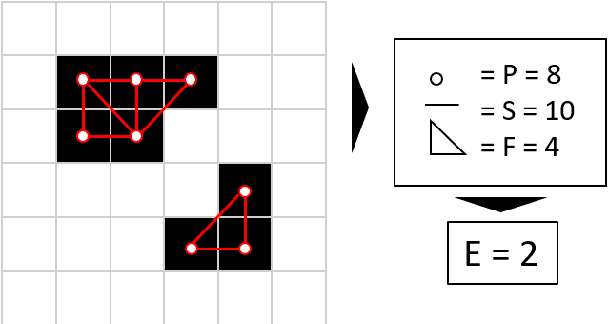
The task of image segmentation is to classify each pixel in the image based on the appropriate label. Various deep learning approaches have been proposed for image segmentation that offers high accuracy and deep architecture. However, the deep learning technique uses a pixel-wise loss function for the training process. Using pixel-wise loss neglected the pixel neighbor relationships in the network learning process. The neighboring relationship of the pixels is essential information in the image. Utilizing neighboring pixel information provides an advantage over using only pixel-to-pixel information. This study presents regularizers to give the pixel neighbor relationship information to the learning process. The regularizers are constructed by the graph theory approach and topology approach: By graph theory approach, graph Laplacian is used to utilize the smoothness of segmented images based on output images and ground-truth images. By topology approach, Euler characteristic is used to identify and minimize the number of isolated objects on segmented images. Experiments show that our scheme successfully captures pixel neighbor relations and improves the performance of the convolutional neural network better than the baseline without a regularization term.
Global Flood Prediction: a Multimodal Machine Learning Approach
Jan 29, 2023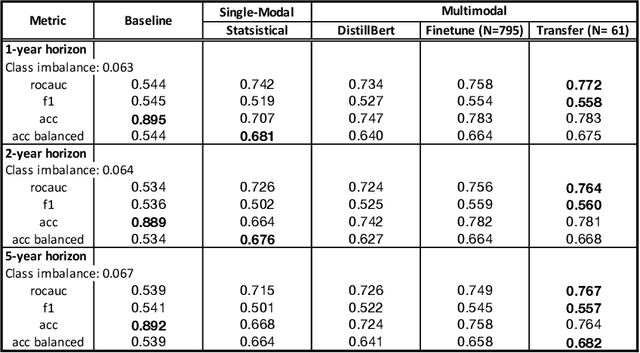
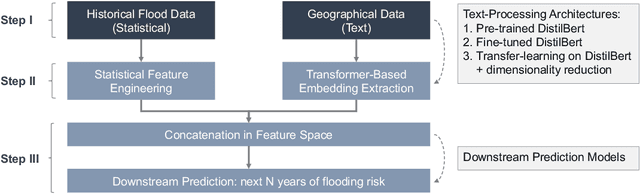
Flooding is one of the most destructive and costly natural disasters, and climate changes would further increase risks globally. This work presents a novel multimodal machine learning approach for multi-year global flood risk prediction, combining geographical information and historical natural disaster dataset. Our multimodal framework employs state-of-the-art processing techniques to extract embeddings from each data modality, including text-based geographical data and tabular-based time-series data. Experiments demonstrate that a multimodal approach, that is combining text and statistical data, outperforms a single-modality approach. Our most advanced architecture, employing embeddings extracted using transfer learning upon DistilBert model, achieves 75\%-77\% ROCAUC score in predicting the next 1-5 year flooding event in historically flooded locations. This work demonstrates the potentials of using machine learning for long-term planning in natural disaster management.
MessageNet: Message Classification using Natural Language Processing and Meta-data
Jan 04, 2023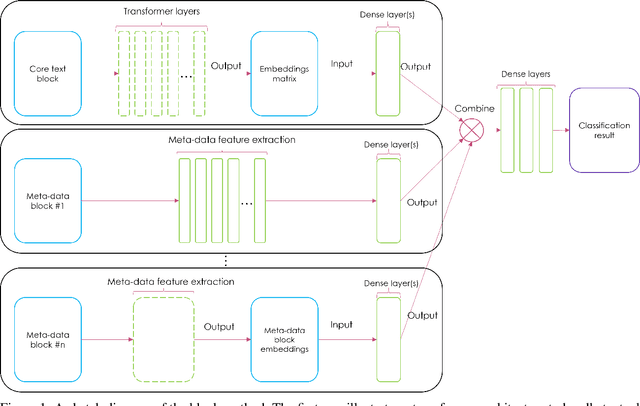
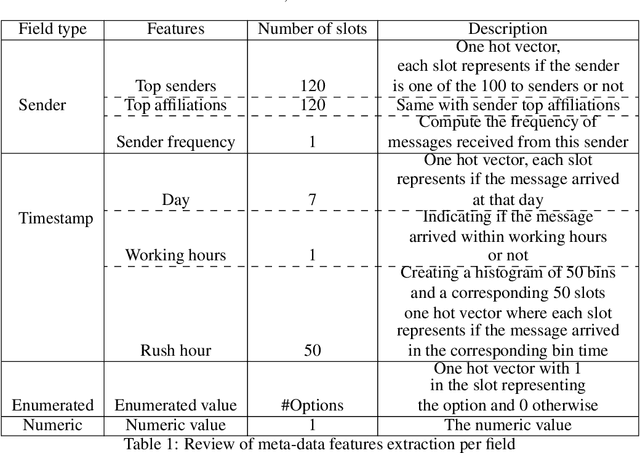
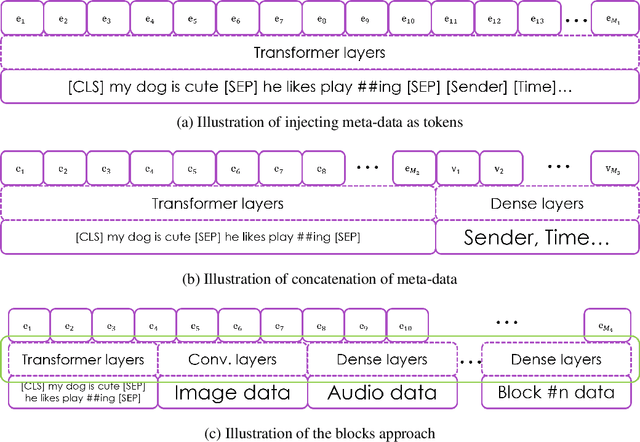
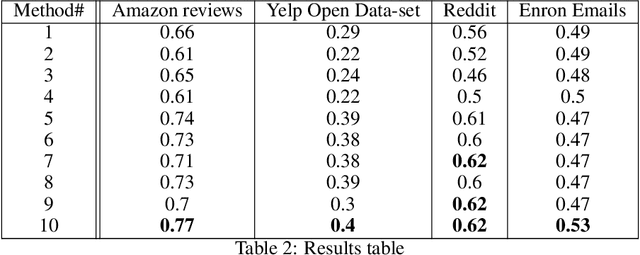
In this paper we propose a new Deep Learning (DL) approach for message classification. Our method is based on the state-of-the-art Natural Language Processing (NLP) building blocks, combined with a novel technique for infusing the meta-data input that is typically available in messages such as the sender information, timestamps, attached image, audio, affiliations, and more. As we demonstrate throughout the paper, going beyond the mere text by leveraging all available channels in the message, could yield an improved representation and higher classification accuracy. To achieve message representation, each type of input is processed in a dedicated block in the neural network architecture that is suitable for the data type. Such an implementation enables training all blocks together simultaneously, and forming cross channels features in the network. We show in the Experiments Section that in some cases, message's meta-data holds an additional information that cannot be extracted just from the text, and when using this information we achieve better performance. Furthermore, we demonstrate that our multi-modality block approach outperforms other approaches for injecting the meta data to the the text classifier.
Learning Mean-Field Control for Delayed Information Load Balancing in Large Queuing Systems
Aug 09, 2022
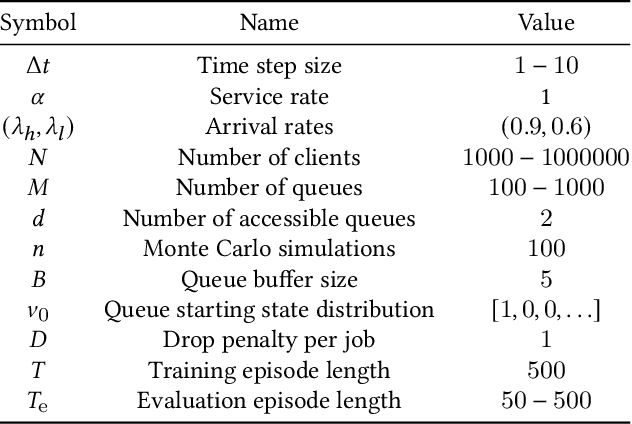
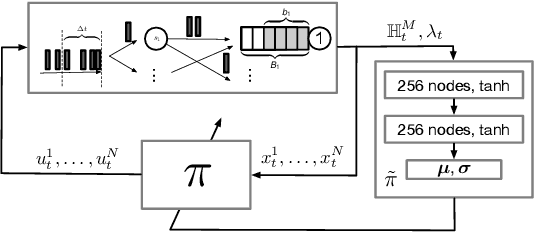
Recent years have seen a great increase in the capacity and parallel processing power of data centers and cloud services. To fully utilize the said distributed systems, optimal load balancing for parallel queuing architectures must be realized. Existing state-of-the-art solutions fail to consider the effect of communication delays on the behaviour of very large systems with many clients. In this work, we consider a multi-agent load balancing system, with delayed information, consisting of many clients (load balancers) and many parallel queues. In order to obtain a tractable solution, we model this system as a mean-field control problem with enlarged state-action space in discrete time through exact discretization. Subsequently, we apply policy gradient reinforcement learning algorithms to find an optimal load balancing solution. Here, the discrete-time system model incorporates a synchronization delay under which the queue state information is synchronously broadcasted and updated at all clients. We then provide theoretical performance guarantees for our methodology in large systems. Finally, using experiments, we prove that our approach is not only scalable but also shows good performance when compared to the state-of-the-art power-of-d variant of the Join-the-Shortest-Queue (JSQ) and other policies in the presence of synchronization delays.
Data efficiency and extrapolation trends in neural network interatomic potentials
Feb 12, 2023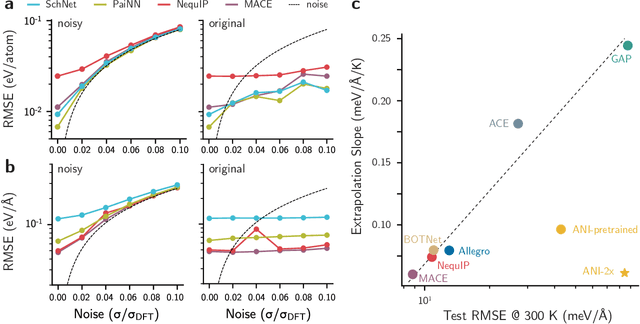
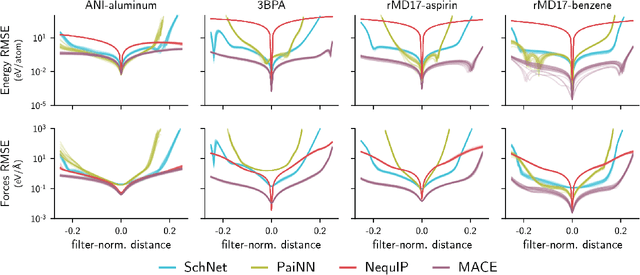

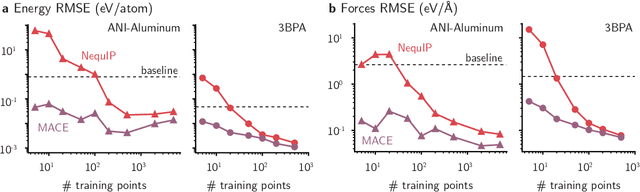
Over the last few years, key architectural advances have been proposed for neural network interatomic potentials (NNIPs), such as incorporating message-passing networks, equivariance, or many-body expansion terms. Although modern NNIP models exhibit nearly negligible differences in energy/forces errors, improvements in accuracy are still considered the main target when developing new NNIP architectures. In this work, we investigate how architectural choices influence the trainability and generalization error in NNIPs, revealing trends in extrapolation, data efficiency, and loss landscapes. First, we show that modern NNIP architectures recover the underlying potential energy surface (PES) of the training data even when trained to corrupted labels. Second, generalization metrics such as errors on high-temperature samples from the 3BPA dataset are demonstrated to follow a scaling relation for a variety of models. Thus, improvements in accuracy metrics may not bring independent information on the robust generalization of NNIPs. To circumvent this problem, we relate loss landscapes to model generalization across datasets. Using this probe, we explain why NNIPs with similar accuracy metrics exhibit different abilities to extrapolate and how training to forces improves the optimization landscape of a model. As an example, we show that MACE can predict PESes with reasonable error after being trained to as few as five data points, making it an example of a "few-shot" model for learning PESes. On the other hand, models with similar accuracy metrics such as NequIP show smaller ability to extrapolate in this extremely low-data regime. Our work provides a deep learning justification for the performance of many common NNIPs, and introduces tools beyond accuracy metrics that can be used to inform the development of next-generation models.
Kernel Subspace and Feature Extraction
Jan 04, 2023We study kernel methods in machine learning from the perspective of feature subspace. We establish a one-to-one correspondence between feature subspaces and kernels and propose an information-theoretic measure for kernels. In particular, we construct a kernel from Hirschfeld--Gebelein--R\'{e}nyi maximal correlation functions, coined the maximal correlation kernel, and demonstrate its information-theoretic optimality. We use the support vector machine (SVM) as an example to illustrate a connection between kernel methods and feature extraction approaches. We show that the kernel SVM on maximal correlation kernel achieves minimum prediction error. Finally, we interpret the Fisher kernel as a special maximal correlation kernel and establish its optimality.
Generalization Bounds with Data-dependent Fractal Dimensions
Feb 06, 2023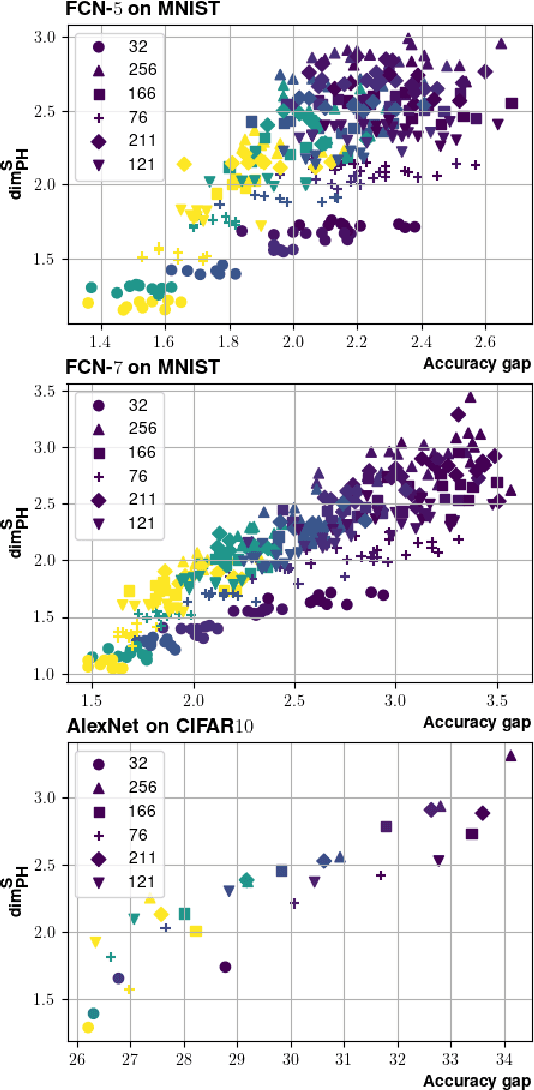
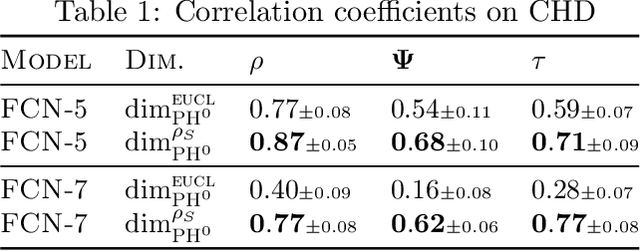
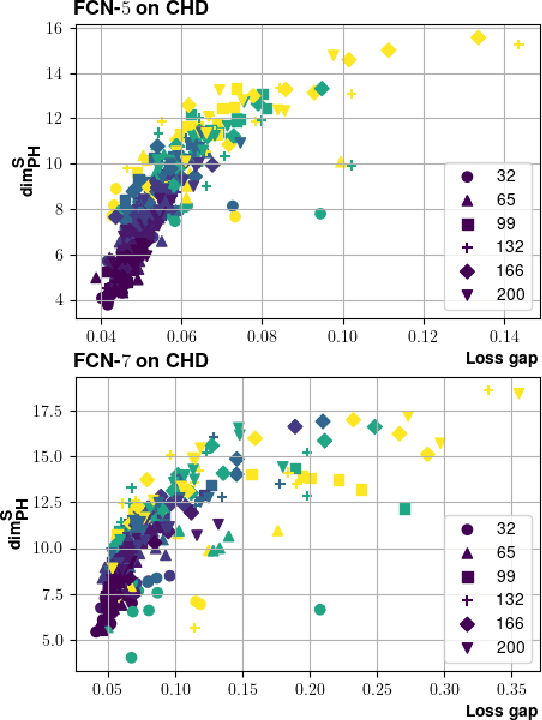
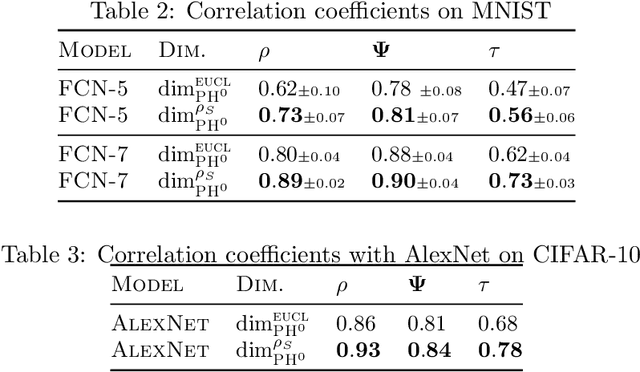
Providing generalization guarantees for modern neural networks has been a crucial task in statistical learning. Recently, several studies have attempted to analyze the generalization error in such settings by using tools from fractal geometry. While these works have successfully introduced new mathematical tools to apprehend generalization, they heavily rely on a Lipschitz continuity assumption, which in general does not hold for neural networks and might make the bounds vacuous. In this work, we address this issue and prove fractal geometry-based generalization bounds without requiring any Lipschitz assumption. To achieve this goal, we build up on a classical covering argument in learning theory and introduce a data-dependent fractal dimension. Despite introducing a significant amount of technical complications, this new notion lets us control the generalization error (over either fixed or random hypothesis spaces) along with certain mutual information (MI) terms. To provide a clearer interpretation to the newly introduced MI terms, as a next step, we introduce a notion of "geometric stability" and link our bounds to the prior art. Finally, we make a rigorous connection between the proposed data-dependent dimension and topological data analysis tools, which then enables us to compute the dimension in a numerically efficient way. We support our theory with experiments conducted on various settings.
Optimizing Energy-Harvesting Hybrid VLC/RF Networks with Random Receiver Orientation
Feb 06, 2023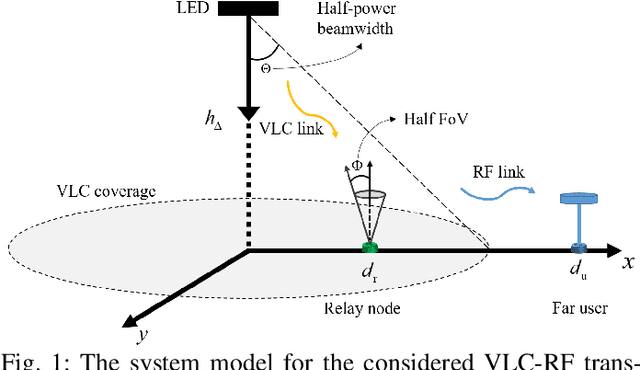
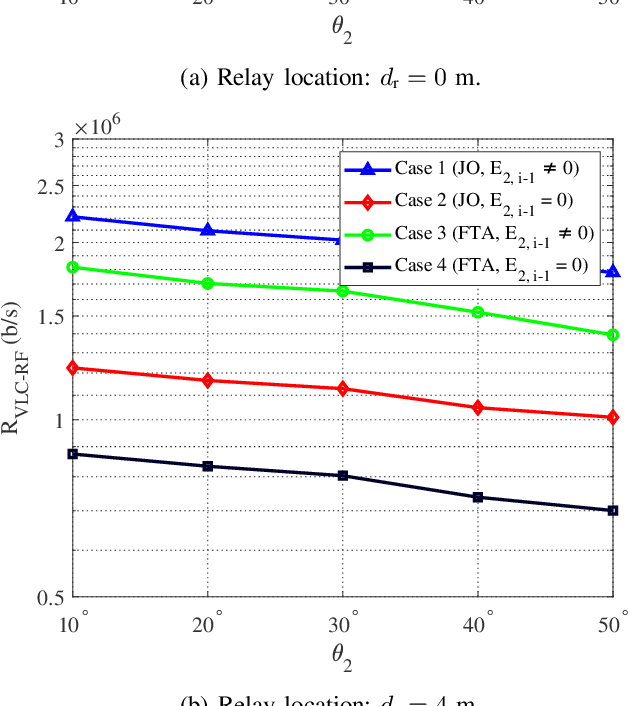
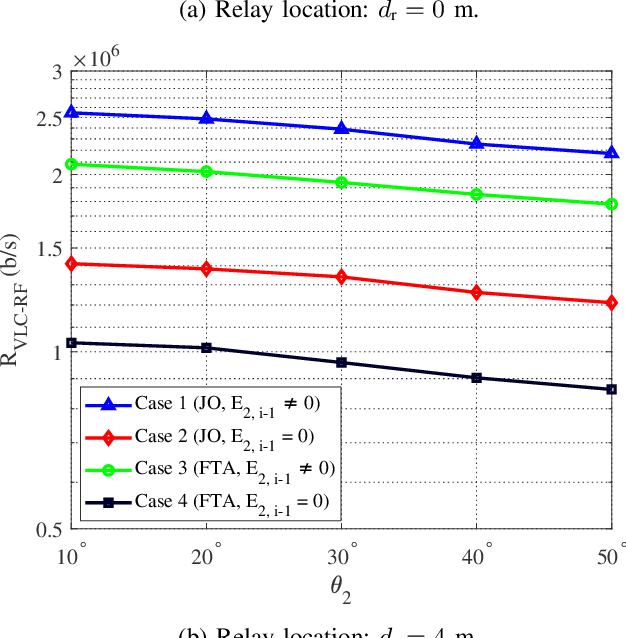
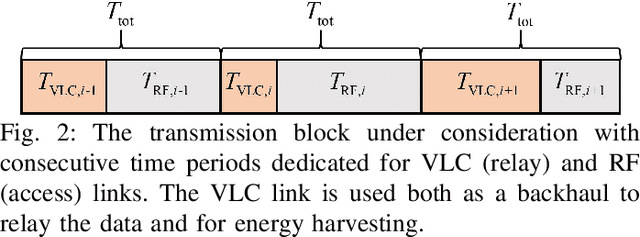
In this paper, we consider an indoor hybrid visible light communication (VLC) and radio frequency (RF) communication scenario with two-hop downlink transmission. The LED carries both data and energy in the first phase, VLC, to an energy harvester relay node, which then uses the harvested energy to re-transmit the decoded information to the RF user in the second phase, RF communication. The direct current (DC) bias and the assigned time duration for VLC transmission are taken into account as design parameters. The optimization problem is formulated to maximize the data rate with the assumption of decode-and-forward relaying for fixed receiver orientation. The non-convex optimization is split into two sub-problems and solved cyclically. It optimizes the data rate by solving two sub-problems: fixing time duration for VLC link to solve DC bias and fixing DC bias to solve time duration. The effect of random receiver orientation on the data rate is also studied, and closed-form expressions for both VLC and RF data rates are derived. The optimization is solved through an exhaustive search, and the results show that a higher data rate can be achieved by solving the joint problem of DC bias and time duration compared to solely optimizing the DC bias.