 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Learning Personalized User Preference from Cold Start in Multi-turn Conversations
Sep 10, 2023
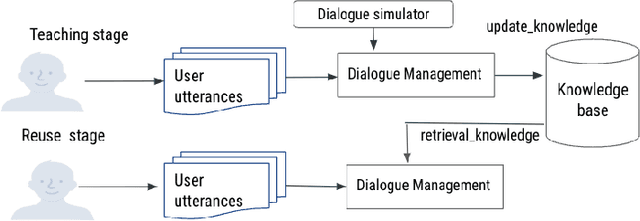
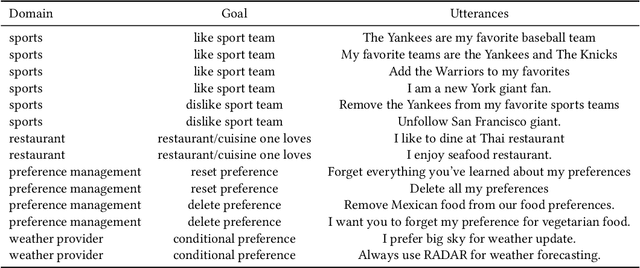
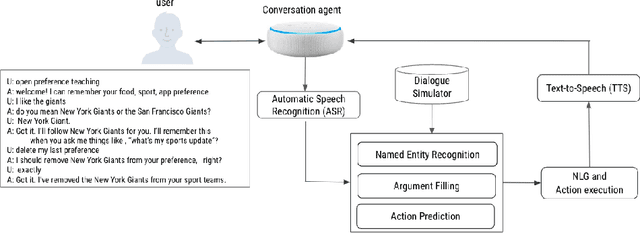
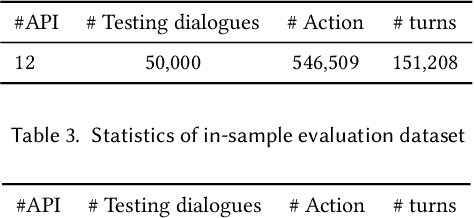
This paper presents a novel teachable conversation interaction system that is capable of learning users preferences from cold start by gradually adapting to personal preferences. In particular, the TAI system is able to automatically identify and label user preference in live interactions, manage dialogue flows for interactive teaching sessions, and reuse learned preference for preference elicitation. We develop the TAI system by leveraging BERT encoder models to encode both dialogue and relevant context information, and build action prediction (AP), argument filling (AF) and named entity recognition (NER) models to understand the teaching session. We adopt a seeker-provider interaction loop mechanism to generate diverse dialogues from cold-start. TAI is capable of learning user preference, which achieves 0.9122 turn level accuracy on out-of-sample dataset, and has been successfully adopted in production.
Lung Diseases Image Segmentation using Faster R-CNNs
Sep 10, 2023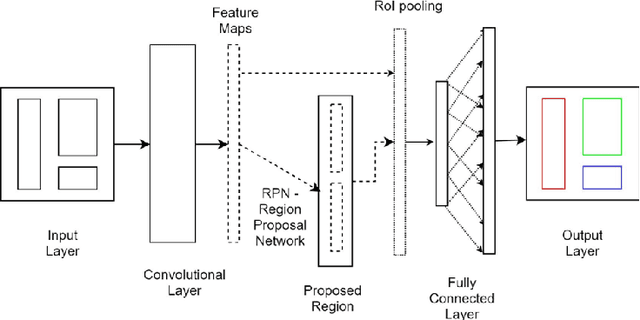
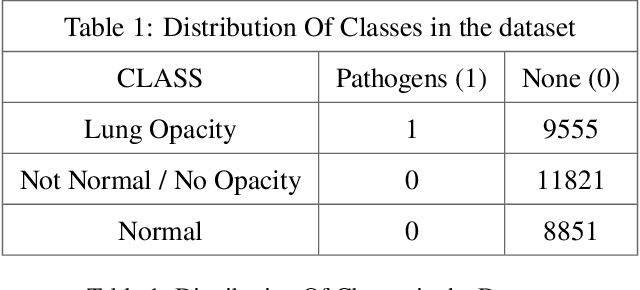
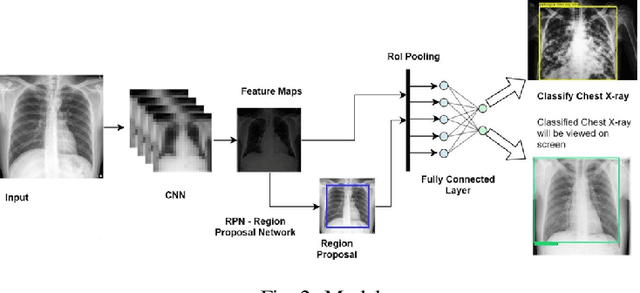
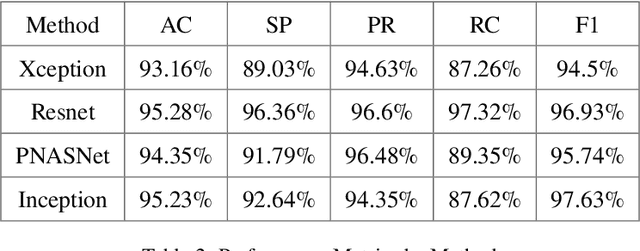
Lung diseases are a leading cause of child mortality in the developing world, with India accounting for approximately half of global pneumonia deaths (370,000) in 2016. Timely diagnosis is crucial for reducing mortality rates. This paper introduces a low-density neural network structure to mitigate topological challenges in deep networks. The network incorporates parameters into a feature pyramid, enhancing data extraction and minimizing information loss. Soft Non-Maximal Suppression optimizes regional proposals generated by the Region Proposal Network. The study evaluates the model on chest X-ray images, computing a confusion matrix to determine accuracy, precision, sensitivity, and specificity. We analyze loss functions, highlighting their trends during training. The regional proposal loss and classification loss assess model performance during training and classification phases. This paper analysis lung disease detection and neural network structures.
DeCUR: decoupling common & unique representations for multimodal self-supervision
Sep 11, 2023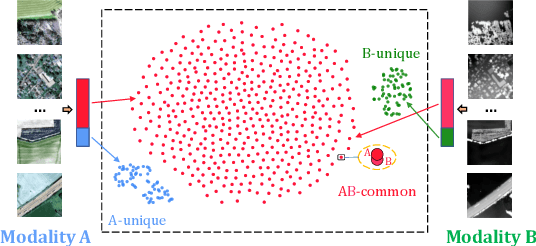
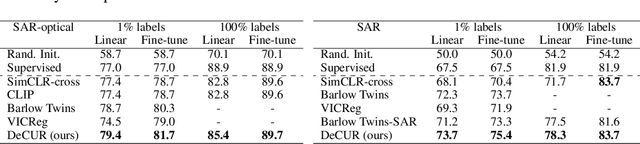
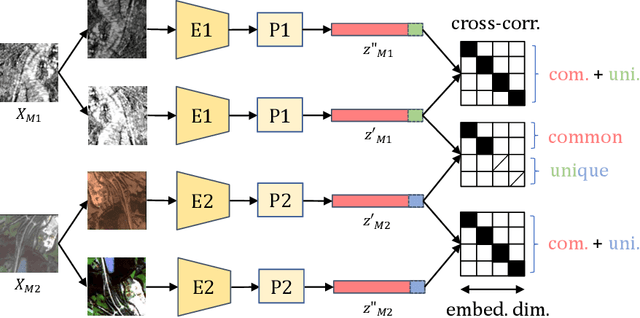

The increasing availability of multi-sensor data sparks interest in multimodal self-supervised learning. However, most existing approaches learn only common representations across modalities while ignoring intra-modal training and modality-unique representations. We propose Decoupling Common and Unique Representations (DeCUR), a simple yet effective method for multimodal self-supervised learning. By distinguishing inter- and intra-modal embeddings, DeCUR is trained to integrate complementary information across different modalities. We evaluate DeCUR in three common multimodal scenarios (radar-optical, RGB-elevation, and RGB-depth), and demonstrate its consistent benefits on scene classification and semantic segmentation downstream tasks. Notably, we get straightforward improvements by transferring our pretrained backbones to state-of-the-art supervised multimodal methods without any hyperparameter tuning. Furthermore, we conduct a comprehensive explainability analysis to shed light on the interpretation of common and unique features in our multimodal approach. Codes are available at \url{https://github.com/zhu-xlab/DeCUR}.
IDVT: Interest-aware Denoising and View-guided Tuning for Social Recommendation
Aug 30, 2023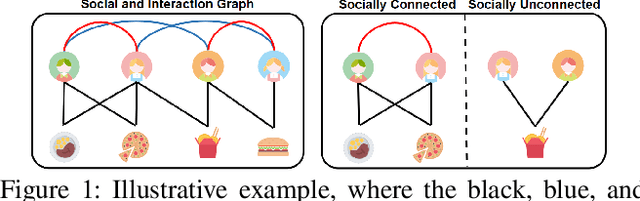
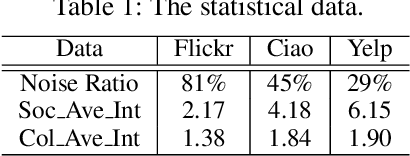
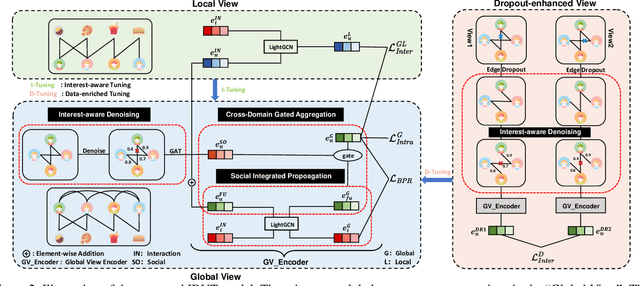
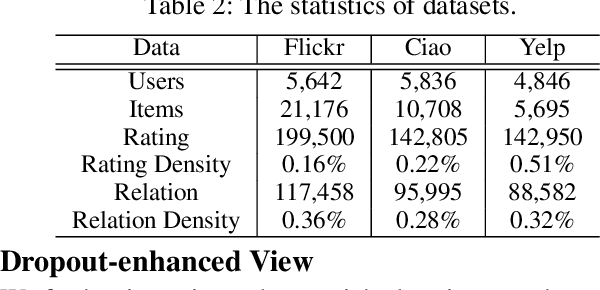
In the information age, recommendation systems are vital for efficiently filtering information and identifying user preferences. Online social platforms have enriched these systems by providing valuable auxiliary information. Socially connected users are assumed to share similar preferences, enhancing recommendation accuracy and addressing cold start issues. However, empirical findings challenge the assumption, revealing that certain social connections can actually harm system performance. Our statistical analysis indicates a significant amount of noise in the social network, where many socially connected users do not share common interests. To address this issue, we propose an innovative \underline{I}nterest-aware \underline{D}enoising and \underline{V}iew-guided \underline{T}uning (IDVT) method for the social recommendation. The first ID part effectively denoises social connections. Specifically, the denoising process considers both social network structure and user interaction interests in a global view. Moreover, in this global view, we also integrate denoised social information (social domain) into the propagation of the user-item interactions (collaborative domain) and aggregate user representations from two domains using a gating mechanism. To tackle potential user interest loss and enhance model robustness within the global view, our second VT part introduces two additional views (local view and dropout-enhanced view) for fine-tuning user representations in the global view through contrastive learning. Extensive evaluations on real-world datasets with varying noise ratios demonstrate the superiority of IDVT over state-of-the-art social recommendation methods.
BoardgameQA: A Dataset for Natural Language Reasoning with Contradictory Information
Jun 13, 2023
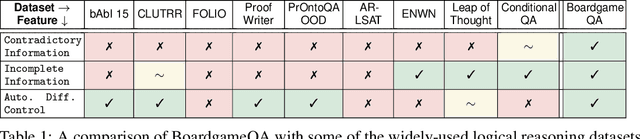

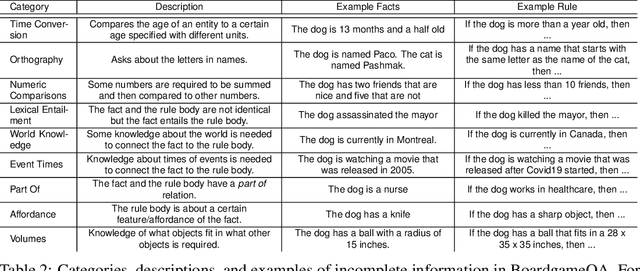
Automated reasoning with unstructured natural text is a key requirement for many potential applications of NLP and for developing robust AI systems. Recently, Language Models (LMs) have demonstrated complex reasoning capacities even without any finetuning. However, existing evaluation for automated reasoning assumes access to a consistent and coherent set of information over which models reason. When reasoning in the real-world, the available information is frequently inconsistent or contradictory, and therefore models need to be equipped with a strategy to resolve such conflicts when they arise. One widely-applicable way of resolving conflicts is to impose preferences over information sources (e.g., based on source credibility or information recency) and adopt the source with higher preference. In this paper, we formulate the problem of reasoning with contradictory information guided by preferences over sources as the classical problem of defeasible reasoning, and develop a dataset called BoardgameQA for measuring the reasoning capacity of LMs in this setting. BoardgameQA also incorporates reasoning with implicit background knowledge, to better reflect reasoning problems in downstream applications. We benchmark various LMs on BoardgameQA and the results reveal a significant gap in the reasoning capacity of state-of-the-art LMs on this problem, showing that reasoning with conflicting information does not surface out-of-the-box in LMs. While performance can be improved with finetuning, it nevertheless remains poor.
Learn to Enhance the Negative Information in Convolutional Neural Network
Jun 18, 2023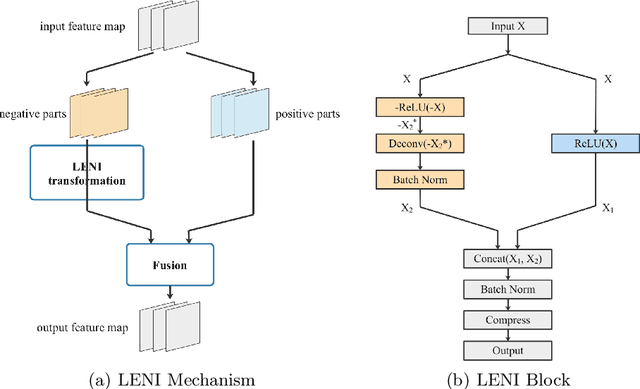
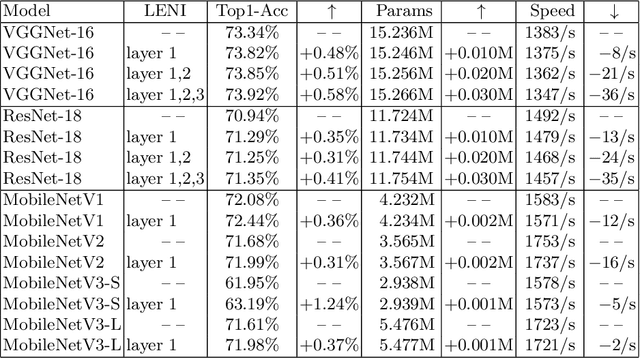
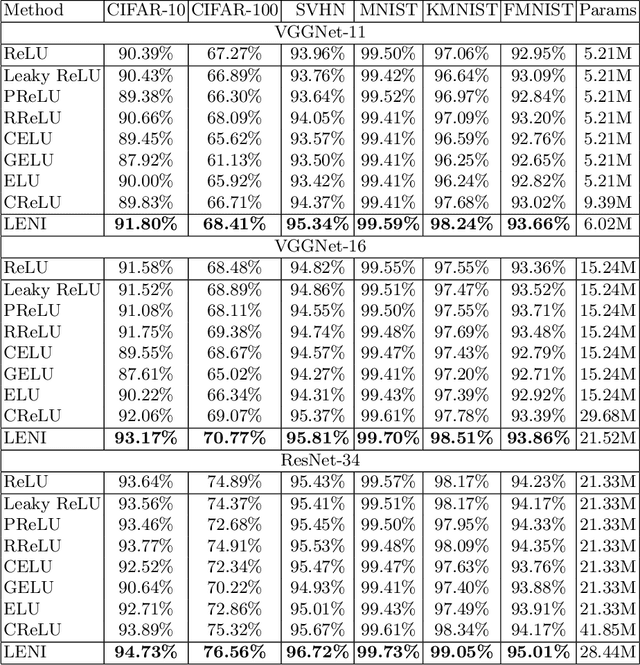
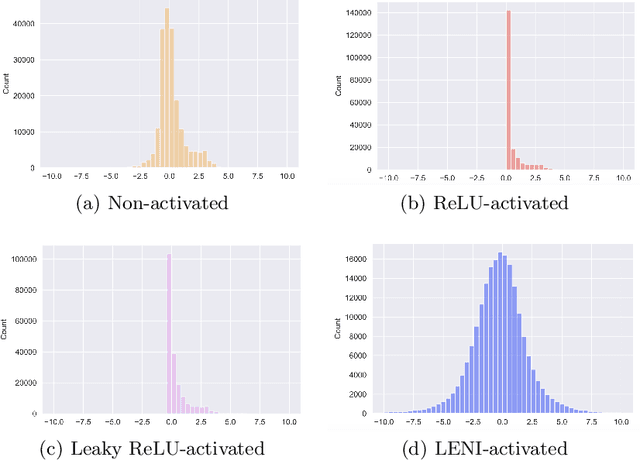
This paper proposes a learnable nonlinear activation mechanism specifically for convolutional neural network (CNN) termed as LENI, which learns to enhance the negative information in CNNs. In sharp contrast to ReLU which cuts off the negative neurons and suffers from the issue of ''dying ReLU'', LENI enjoys the capacity to reconstruct the dead neurons and reduce the information loss. Compared to improved ReLUs, LENI introduces a learnable approach to process the negative phase information more properly. In this way, LENI can enhance the model representational capacity significantly while maintaining the original advantages of ReLU. As a generic activation mechanism, LENI possesses the property of portability and can be easily utilized in any CNN models through simply replacing the activation layers with LENI block. Extensive experiments validate that LENI can improve the performance of various baseline models on various benchmark datasets by a clear margin (up to 1.24% higher top-1 accuracy on ImageNet-1k) with negligible extra parameters. Further experiments show that LENI can act as a channel compensation mechanism, offering competitive or even better performance but with fewer learned parameters than baseline models. In addition, LENI introduces the asymmetry to the model structure which contributes to the enhancement of representational capacity. Through visualization experiments, we validate that LENI can retain more information and learn more representations.
Curvature-based Pooling within Graph Neural Networks
Aug 31, 2023Over-squashing and over-smoothing are two critical issues, that limit the capabilities of graph neural networks (GNNs). While over-smoothing eliminates the differences between nodes making them indistinguishable, over-squashing refers to the inability of GNNs to propagate information over long distances, as exponentially many node states are squashed into fixed-size representations. Both phenomena share similar causes, as both are largely induced by the graph topology. To mitigate these problems in graph classification tasks, we propose CurvPool, a novel pooling method. CurvPool exploits the notion of curvature of a graph to adaptively identify structures responsible for both over-smoothing and over-squashing. By clustering nodes based on the Balanced Forman curvature, CurvPool constructs a graph with a more suitable structure, allowing deeper models and the combination of distant information. We compare it to other state-of-the-art pooling approaches and establish its competitiveness in terms of classification accuracy, computational complexity, and flexibility. CurvPool outperforms several comparable methods across all considered tasks. The most consistent results are achieved by pooling densely connected clusters using the sum aggregation, as this allows additional information about the size of each pool.
Multi-Modal Hybrid Learning and Sequential Training for RGB-T Saliency Detection
Sep 13, 2023RGB-T saliency detection has emerged as an important computer vision task, identifying conspicuous objects in challenging scenes such as dark environments. However, existing methods neglect the characteristics of cross-modal features and rely solely on network structures to fuse RGB and thermal features. To address this, we first propose a Multi-Modal Hybrid loss (MMHL) that comprises supervised and self-supervised loss functions. The supervised loss component of MMHL distinctly utilizes semantic features from different modalities, while the self-supervised loss component reduces the distance between RGB and thermal features. We further consider both spatial and channel information during feature fusion and propose the Hybrid Fusion Module to effectively fuse RGB and thermal features. Lastly, instead of jointly training the network with cross-modal features, we implement a sequential training strategy which performs training only on RGB images in the first stage and then learns cross-modal features in the second stage. This training strategy improves saliency detection performance without computational overhead. Results from performance evaluation and ablation studies demonstrate the superior performance achieved by the proposed method compared with the existing state-of-the-art methods.
Diffusion models for audio semantic communication
Sep 13, 2023Directly sending audio signals from a transmitter to a receiver across a noisy channel may absorb consistent bandwidth and be prone to errors when trying to recover the transmitted bits. On the contrary, the recent semantic communication approach proposes to send the semantics and then regenerate semantically consistent content at the receiver without exactly recovering the bitstream. In this paper, we propose a generative audio semantic communication framework that faces the communication problem as an inverse problem, therefore being robust to different corruptions. Our method transmits lower-dimensional representations of the audio signal and of the associated semantics to the receiver, which generates the corresponding signal with a particular focus on its meaning (i.e., the semantics) thanks to the conditional diffusion model at its core. During the generation process, the diffusion model restores the received information from multiple degradations at the same time including corruption noise and missing parts caused by the transmission over the noisy channel. We show that our framework outperforms competitors in a real-world scenario and with different channel conditions. Visit the project page to listen to samples and access the code: https://ispamm.github.io/diffusion-audio-semantic-communication/.
EarthPT: a foundation model for Earth Observation
Sep 13, 2023We introduce EarthPT -- an Earth Observation (EO) pretrained transformer. EarthPT is a 700 million parameter decoding transformer foundation model trained in an autoregressive self-supervised manner and developed specifically with EO use-cases in mind. We demonstrate that EarthPT is an effective forecaster that can accurately predict future pixel-level surface reflectances across the 400-2300 nm range well into the future. For example, forecasts of the evolution of the Normalised Difference Vegetation Index (NDVI) have a typical error of approximately 0.05 (over a natural range of -1 -> 1) at the pixel level over a five month test set horizon, out-performing simple phase-folded models based on historical averaging. We also demonstrate that embeddings learnt by EarthPT hold semantically meaningful information and could be exploited for downstream tasks such as highly granular, dynamic land use classification. Excitingly, we note that the abundance of EO data provides us with -- in theory -- quadrillions of training tokens. Therefore, if we assume that EarthPT follows neural scaling laws akin to those derived for Large Language Models (LLMs), there is currently no data-imposed limit to scaling EarthPT and other similar `Large Observation Models.'