 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
X-ray dark-field via spectral propagation-based imaging
Sep 27, 2023
Dark-field X-ray imaging is a novel modality which visualises scattering from unresolved microstructure. Current dark-field imaging techniques typically require precision optics in a stable environment. Propagation-based imaging (PBI) is an optics-free phase-contrast imaging technique that can be used to recover phase information by modelling the propagation of a diffracted wavefield. Based on the Fokker--Planck equation of X-ray imaging, we propose a dual-energy PBI approach to capture phase and dark-field effects. The equation is solved under conditions of a single-material sample with spatially slowly-varying dark-field signal, together with an a priori dark-field spectral dependence. We use single-grid dark-field imaging to fit a power law to the dark-field spectral dependence, and successfully apply the PBI dark-field retrieval algorithm to simulated and experimental dual-energy data.
Neural Acoustic Context Field: Rendering Realistic Room Impulse Response With Neural Fields
Sep 27, 2023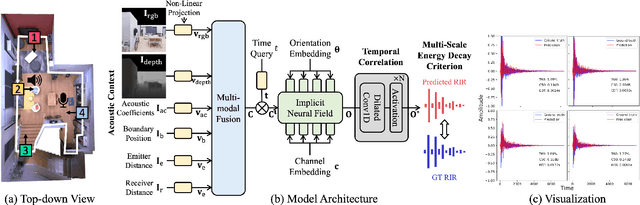

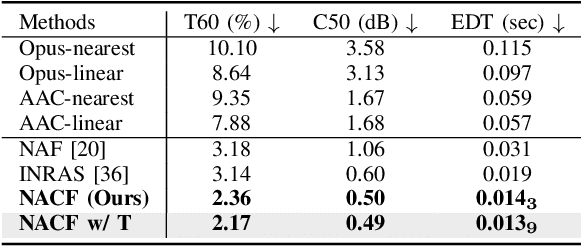
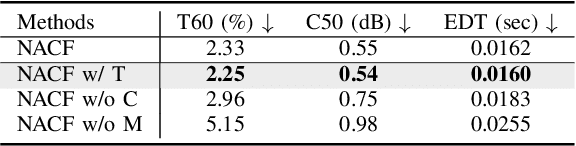
Room impulse response (RIR), which measures the sound propagation within an environment, is critical for synthesizing high-fidelity audio for a given environment. Some prior work has proposed representing RIR as a neural field function of the sound emitter and receiver positions. However, these methods do not sufficiently consider the acoustic properties of an audio scene, leading to unsatisfactory performance. This letter proposes a novel Neural Acoustic Context Field approach, called NACF, to parameterize an audio scene by leveraging multiple acoustic contexts, such as geometry, material property, and spatial information. Driven by the unique properties of RIR, i.e., temporal un-smoothness and monotonic energy attenuation, we design a temporal correlation module and multi-scale energy decay criterion. Experimental results show that NACF outperforms existing field-based methods by a notable margin. Please visit our project page for more qualitative results.
Unleashing the Power of Depth and Pose Estimation Neural Networks by Designing Compatible Endoscopic Images
Sep 14, 2023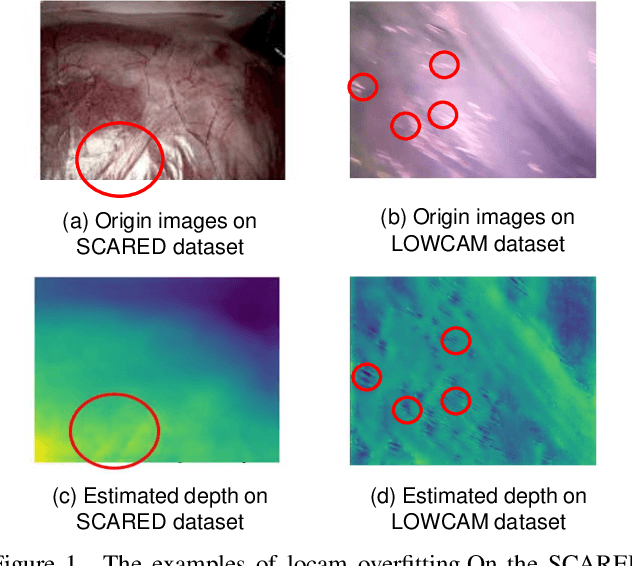
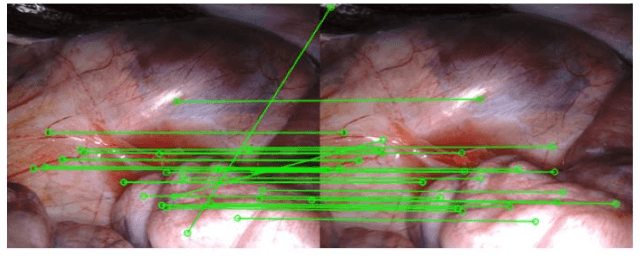
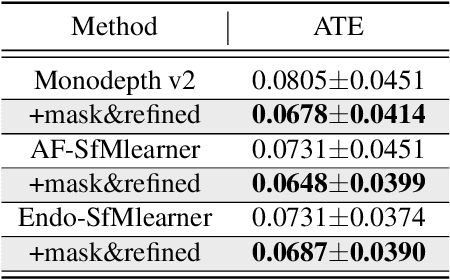
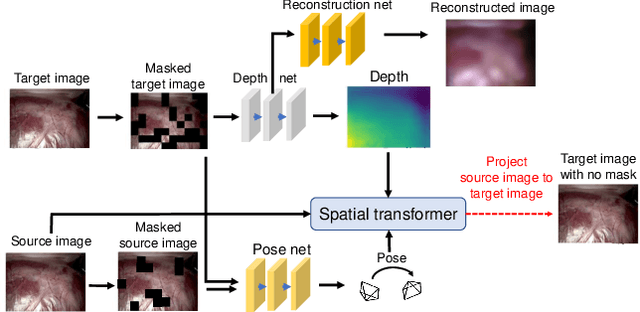
Deep learning models have witnessed depth and pose estimation framework on unannotated datasets as a effective pathway to succeed in endoscopic navigation. Most current techniques are dedicated to developing more advanced neural networks to improve the accuracy. However, existing methods ignore the special properties of endoscopic images, resulting in an inability to fully unleash the power of neural networks. In this study, we conduct a detail analysis of the properties of endoscopic images and improve the compatibility of images and neural networks, to unleash the power of current neural networks. First, we introcude the Mask Image Modelling (MIM) module, which inputs partial image information instead of complete image information, allowing the network to recover global information from partial pixel information. This enhances the network' s ability to perceive global information and alleviates the phenomenon of local overfitting in convolutional neural networks due to local artifacts. Second, we propose a lightweight neural network to enhance the endoscopic images, to explicitly improve the compatibility between images and neural networks. Extensive experiments are conducted on the three public datasets and one inhouse dataset, and the proposed modules improve baselines by a large margin. Furthermore, the enhanced images we proposed, which have higher network compatibility, can serve as an effective data augmentation method and they are able to extract more stable feature points in traditional feature point matching tasks and achieve outstanding performance.
Information-Theoretically Private Federated Submodel Learning with Storage Constrained Databases
Jul 12, 2023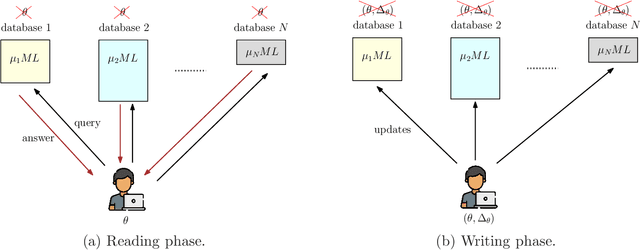

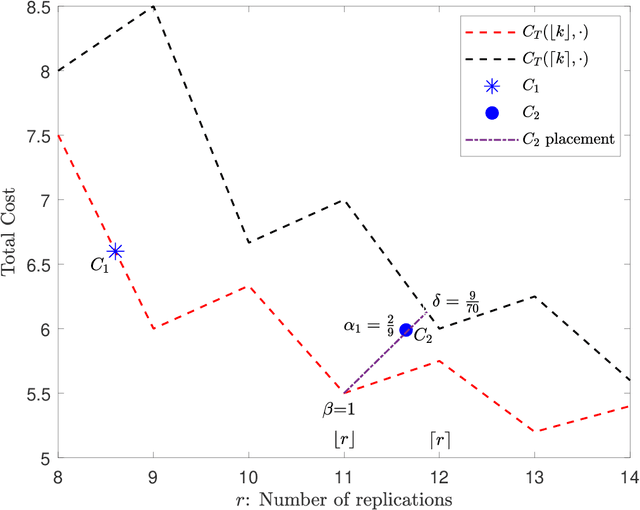
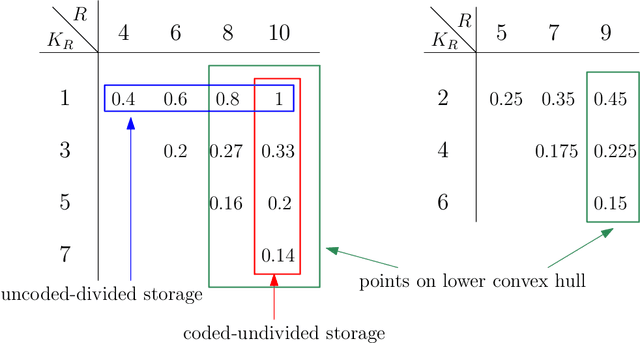
In federated submodel learning (FSL), a machine learning model is divided into multiple submodels based on different types of data used for training. Each user involved in the training process only downloads and updates the submodel relevant to the user's local data, which significantly reduces the communication cost compared to classical federated learning (FL). However, the index of the submodel updated by the user and the values of the updates reveal information about the user's private data. In order to guarantee information-theoretic privacy in FSL, the model is stored at multiple non-colluding databases, and the user sends queries and updates to each database in such a way that no information is revealed on the updating submodel index or the values of the updates. In this work, we consider the practical scenario where the multiple non-colluding databases are allowed to have arbitrary storage constraints. The goal of this work is to develop read-write schemes and storage mechanisms for FSL that efficiently utilize the available storage in each database to store the submodel parameters in such a way that the total communication cost is minimized while guaranteeing information-theoretic privacy of the updating submodel index and the values of the updates. As the main result, we consider both heterogeneous and homogeneous storage constrained databases, and propose private read-write and storage schemes for the two cases.
Question-Answering Approach to Evaluate Legal Summaries
Sep 26, 2023


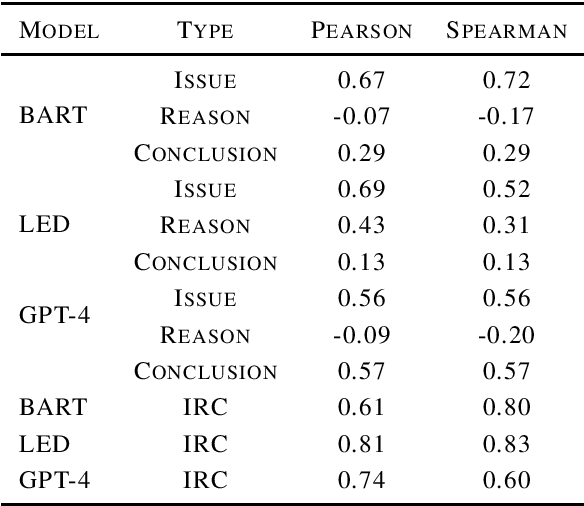
Traditional evaluation metrics like ROUGE compare lexical overlap between the reference and generated summaries without taking argumentative structure into account, which is important for legal summaries. In this paper, we propose a novel legal summarization evaluation framework that utilizes GPT-4 to generate a set of question-answer pairs that cover main points and information in the reference summary. GPT-4 is then used to generate answers based on the generated summary for the questions from the reference summary. Finally, GPT-4 grades the answers from the reference summary and the generated summary. We examined the correlation between GPT-4 grading with human grading. The results suggest that this question-answering approach with GPT-4 can be a useful tool for gauging the quality of the summary.
Reinforcement learning adaptive fuzzy controller for lighting systems: application to aircraft cabin
Sep 30, 2023The lighting requirements are subjective and one light setting cannot work for all. However, there is little work on developing smart lighting algorithms that can adapt to user preferences. To address this gap, this paper uses fuzzy logic and reinforcement learning to develop an adaptive lighting algorithm. In particular, we develop a baseline fuzzy inference system (FIS) using the domain knowledge. We use the existing literature to create a FIS that generates lighting setting recommendations based on environmental conditions i.e. daily glare index, and user information including age, activity, and chronotype. Through a feedback mechanism, the user interacts with the algorithm, correcting the algorithm output to their preferences. We interpret these corrections as rewards to a Q-learning agent, which tunes the FIS parameters online to match the user preferences. We implement the algorithm in an aircraft cabin mockup and conduct an extensive user study to evaluate the effectiveness of the algorithm and understand its learning behavior. Our implementation results demonstrate that the developed algorithm possesses the capability to learn user preferences while successfully adapting to a wide range of environmental conditions and user characteristics. and can deal with a diverse spectrum of environmental conditions and user characteristics. This underscores its viability as a potent solution for intelligent light management, featuring advanced learning capabilities.
Examining the Limitations of Computational Rumor Detection Models Trained on Static Datasets
Sep 20, 2023A crucial aspect of a rumor detection model is its ability to generalize, particularly its ability to detect emerging, previously unknown rumors. Past research has indicated that content-based (i.e., using solely source posts as input) rumor detection models tend to perform less effectively on unseen rumors. At the same time, the potential of context-based models remains largely untapped. The main contribution of this paper is in the in-depth evaluation of the performance gap between content and context-based models specifically on detecting new, unseen rumors. Our empirical findings demonstrate that context-based models are still overly dependent on the information derived from the rumors' source post and tend to overlook the significant role that contextual information can play. We also study the effect of data split strategies on classifier performance. Based on our experimental results, the paper also offers practical suggestions on how to minimize the effects of temporal concept drift in static datasets during the training of rumor detection methods.
Attentive VQ-VAE
Sep 20, 2023
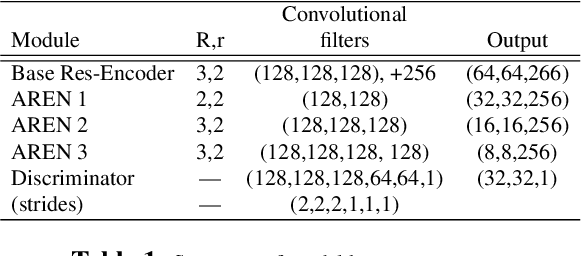
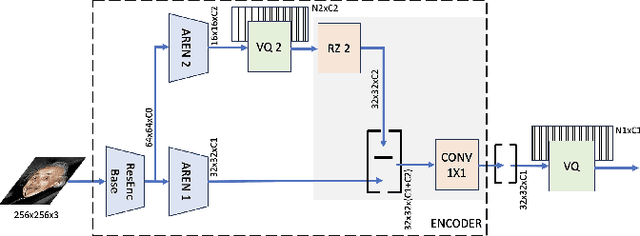
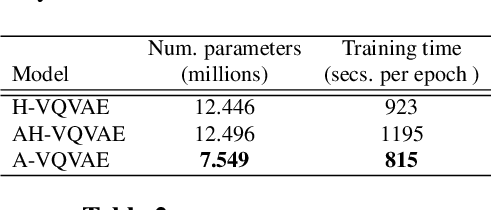
We present a novel approach to enhance the capabilities of VQVAE models through the integration of an Attentive Residual Encoder (AREN) and a Residual Pixel Attention layer. The objective of our research is to improve the performance of VQVAE while maintaining practical parameter levels. The AREN encoder is designed to operate effectively at multiple levels, accommodating diverse architectural complexities. The key innovation is the integration of an inter-pixel auto-attention mechanism into the AREN encoder. This approach allows us to efficiently capture and utilize contextual information across latent vectors. Additionally, our models uses additional encoding levels to further enhance the model's representational power. Our attention layer employs a minimal parameter approach, ensuring that latent vectors are modified only when pertinent information from other pixels is available. Experimental results demonstrate that our proposed modifications lead to significant improvements in data representation and generation, making VQVAEs even more suitable for a wide range of applications.
AttentionMix: Data augmentation method that relies on BERT attention mechanism
Sep 20, 2023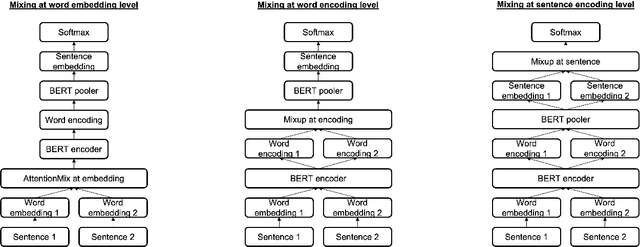
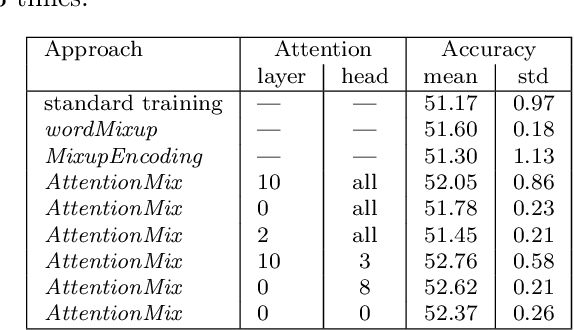
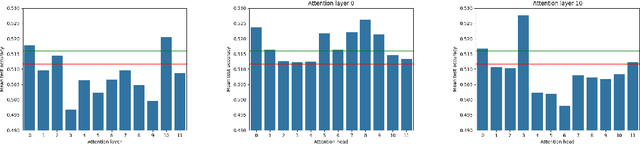
The Mixup method has proven to be a powerful data augmentation technique in Computer Vision, with many successors that perform image mixing in a guided manner. One of the interesting research directions is transferring the underlying Mixup idea to other domains, e.g. Natural Language Processing (NLP). Even though there already exist several methods that apply Mixup to textual data, there is still room for new, improved approaches. In this work, we introduce AttentionMix, a novel mixing method that relies on attention-based information. While the paper focuses on the BERT attention mechanism, the proposed approach can be applied to generally any attention-based model. AttentionMix is evaluated on 3 standard sentiment classification datasets and in all three cases outperforms two benchmark approaches that utilize Mixup mechanism, as well as the vanilla BERT method. The results confirm that the attention-based information can be effectively used for data augmentation in the NLP domain.
Agree To Disagree
Sep 24, 2023How frequently do individuals thoroughly review terms and conditions before proceeding to register for a service, install software, or access a website? The majority of internet users do not engage in this practice. This trend is not surprising, given that terms and conditions typically consist of lengthy documents replete with intricate legal terminology and convoluted sentences. In this paper, we introduce a Machine Learning-powered approach designed to automatically parse and summarize critical information in a user-friendly manner. This technology focuses on distilling the pertinent details that users should contemplate before committing to an agreement.