 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Open-Vocabulary Object Detection Using Captions
Nov 20, 2020
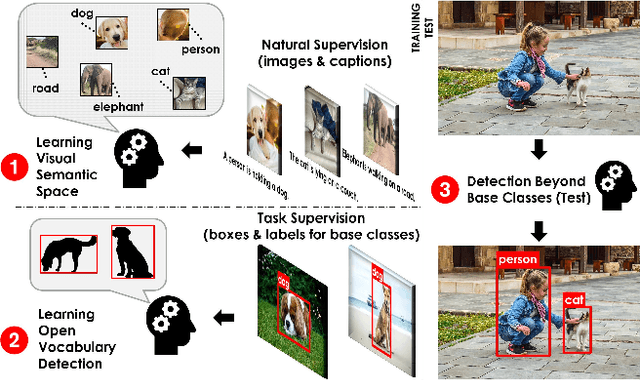
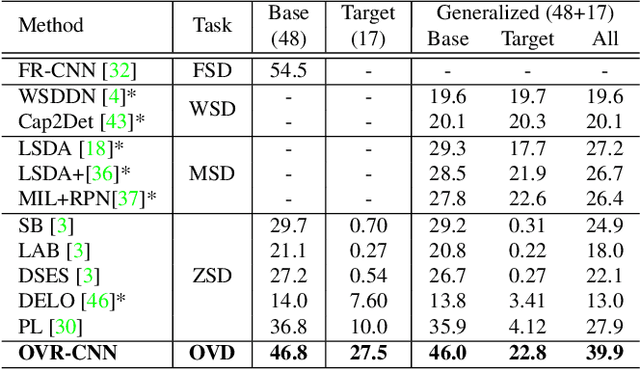
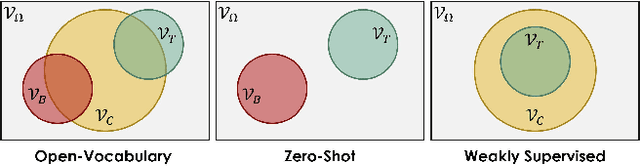
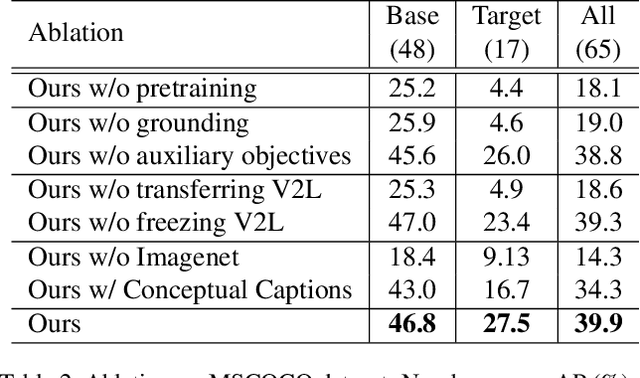
Despite the remarkable accuracy of deep neural networks in object detection, they are costly to train and scale due to supervision requirements. Particularly, learning more object categories typically requires proportionally more bounding box annotations. Weakly supervised and zero-shot learning techniques have been explored to scale object detectors to more categories with less supervision, but they have not been as successful and widely adopted as supervised models. In this paper, we put forth a novel formulation of the object detection problem, namely open-vocabulary object detection, which is more general, more practical, and more effective than weakly supervised and zero-shot approaches. We propose a new method to train object detectors using bounding box annotations for a limited set of object categories, as well as image-caption pairs that cover a larger variety of objects at a significantly lower cost. We show that the proposed method can detect and localize objects for which no bounding box annotation is provided during training, at a significantly higher accuracy than zero-shot approaches. Meanwhile, objects with bounding box annotation can be detected almost as accurately as supervised methods, which is significantly better than weakly supervised baselines. Accordingly, we establish a new state of the art for scalable object detection.
PaXNet: Dental Caries Detection in Panoramic X-ray using Ensemble Transfer Learning and Capsule Classifier
Dec 26, 2020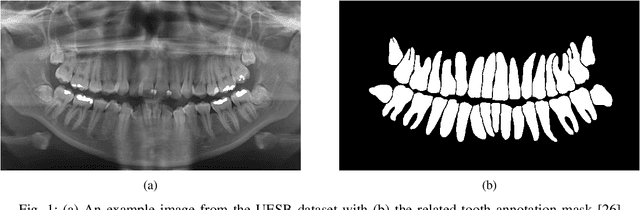

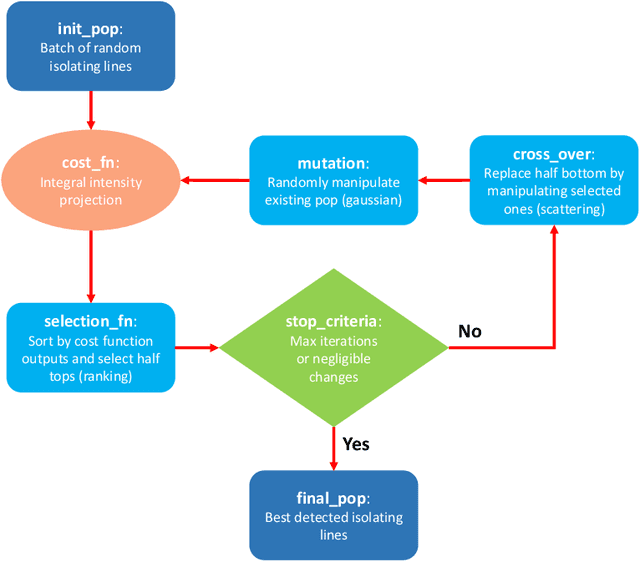
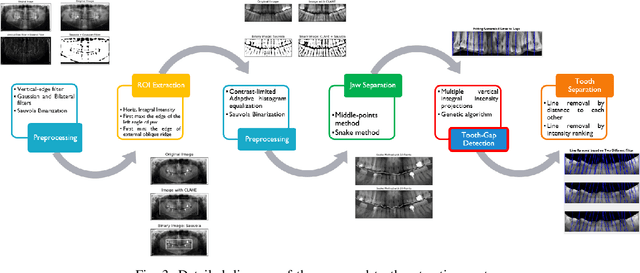
Dental caries is one of the most chronic diseases involving the majority of the population during their lifetime. Caries lesions are typically diagnosed by radiologists relying only on their visual inspection to detect via dental x-rays. In many cases, dental caries is hard to identify using x-rays and can be misinterpreted as shadows due to different reasons such as low image quality. Hence, developing a decision support system for caries detection has been a topic of interest in recent years. Here, we propose an automatic diagnosis system to detect dental caries in Panoramic images for the first time, to the best of authors' knowledge. The proposed model benefits from various pretrained deep learning models through transfer learning to extract relevant features from x-rays and uses a capsule network to draw prediction results. On a dataset of 470 Panoramic images used for features extraction, including 240 labeled images for classification, our model achieved an accuracy score of 86.05\% on the test set. The obtained score demonstrates acceptable detection performance and an increase in caries detection speed, as long as the challenges of using Panoramic x-rays of real patients are taken into account. Among images with caries lesions in the test set, our model acquired recall scores of 69.44\% and 90.52\% for mild and severe ones, confirming the fact that severe caries spots are more straightforward to detect and efficient mild caries detection needs a more robust and larger dataset. Considering the novelty of current research study as using Panoramic images, this work is a step towards developing a fully automated efficient decision support system to assist domain experts.
Large scale evaluation of local image feature detectors on homography datasets
Jul 20, 2018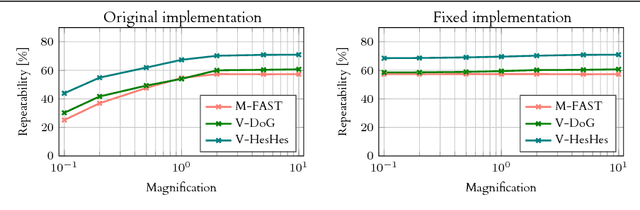
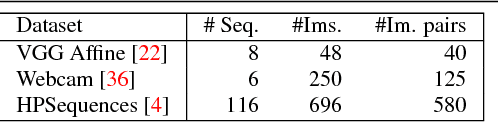
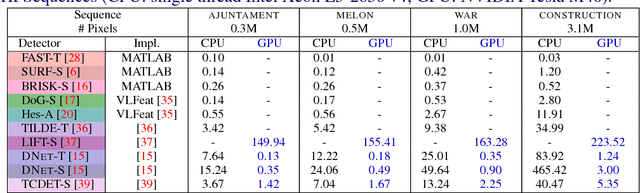
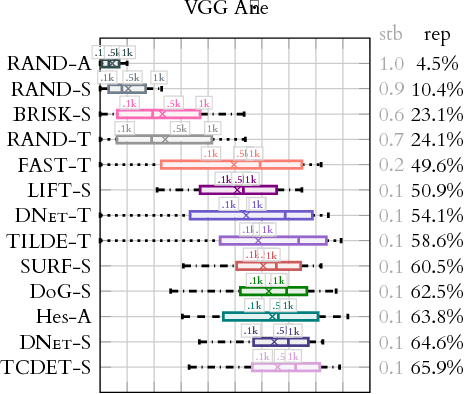
We present a large scale benchmark for the evaluation of local feature detectors. Our key innovation is the introduction of a new evaluation protocol which extends and improves the standard detection repeatability measure. The new protocol is better for assessment on a large number of images and reduces the dependency of the results on unwanted distractors such as the number of detected features and the feature magnification factor. Additionally, our protocol provides a comprehensive assessment of the expected performance of detectors under several practical scenarios. Using images from the recently-introduced HPatches dataset, we evaluate a range of state-of-the-art local feature detectors on two main tasks: viewpoint and illumination invariant detection. Contrary to previous detector evaluations, our study contains an order of magnitude more image sequences, resulting in a quantitative evaluation significantly more robust to over-fitting. We also show that traditional detectors are still very competitive when compared to recent deep-learning alternatives.
Towards Automatic Image Editing: Learning to See another You
Nov 26, 2015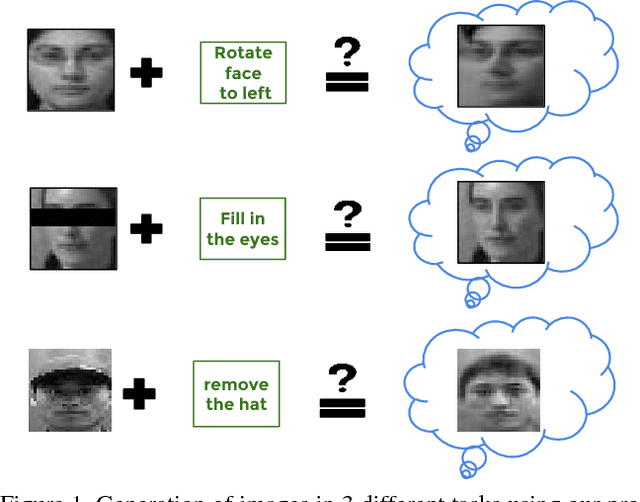
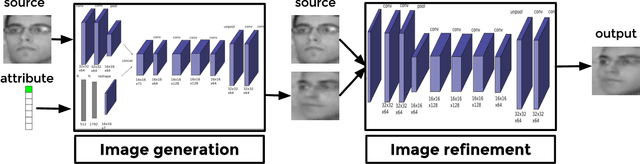
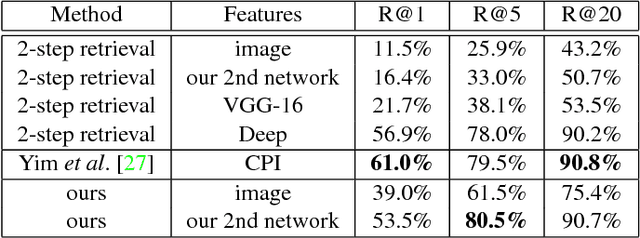
Learning the distribution of images in order to generate new samples is a challenging task due to the high dimensionality of the data and the highly non-linear relations that are involved. Nevertheless, some promising results have been reported in the literature recently,building on deep network architectures. In this work, we zoom in on a specific type of image generation: given an image and knowing the category of objects it belongs to (e.g. faces), our goal is to generate a similar and plausible image, but with some altered attributes. This is particularly challenging, as the model needs to learn to disentangle the effect of each attribute and to apply a desired attribute change to a given input image, while keeping the other attributes and overall object appearance intact. To this end, we learn a convolutional network, where the desired attribute information is encoded then merged with the encoded image at feature map level. We show promising results, both qualitatively as well as quantitatively, in the context of a retrieval experiment, on two face datasets (MultiPie and CAS-PEAL-R1).
ImagePairs: Realistic Super Resolution Dataset via Beam Splitter Camera Rig
Apr 18, 2020
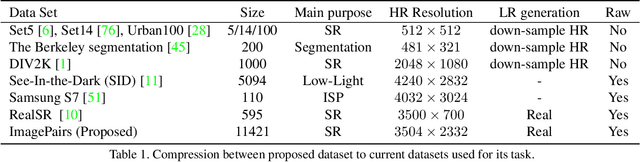
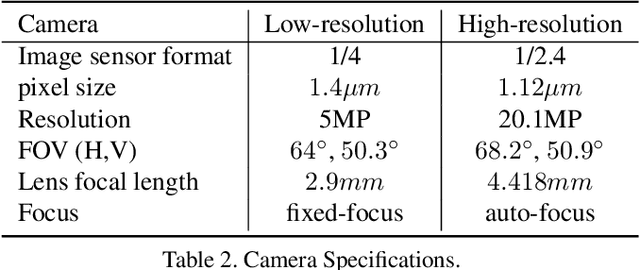
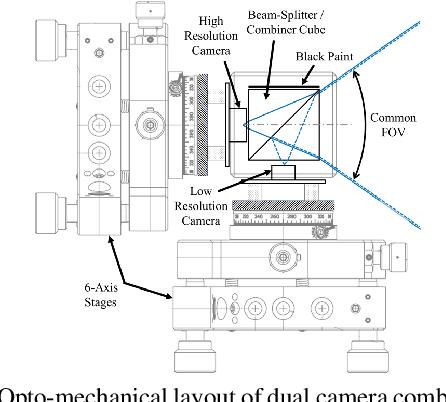
Super Resolution is the problem of recovering a high-resolution image from a single or multiple low-resolution images of the same scene. It is an ill-posed problem since high frequency visual details of the scene are completely lost in low-resolution images. To overcome this, many machine learning approaches have been proposed aiming at training a model to recover the lost details in the new scenes. Such approaches include the recent successful effort in utilizing deep learning techniques to solve super resolution problem. As proven, data itself plays a significant role in the machine learning process especially deep learning approaches which are data hungry. Therefore, to solve the problem, the process of gathering data and its formation could be equally as vital as the machine learning technique used. Herein, we are proposing a new data acquisition technique for gathering real image data set which could be used as an input for super resolution, noise cancellation and quality enhancement techniques. We use a beam-splitter to capture the same scene by a low resolution camera and a high resolution camera. Since we also release the raw images, this large-scale dataset could be used for other tasks such as ISP generation. Unlike current small-scale dataset used for these tasks, our proposed dataset includes 11,421 pairs of low-resolution high-resolution images of diverse scenes. To our knowledge this is the most complete dataset for super resolution, ISP and image quality enhancement. The benchmarking result shows how the new dataset can be successfully used to significantly improve the quality of real-world image super resolution.
Knife and Threat Detectors
Apr 08, 2020



Despite rapid advances in image-based machine learning, the threat identification of a knife wielding attacker has not garnered substantial academic attention. This relative research gap appears less understandable given the high knife assault rate (>100,000 annually) and the increasing availability of public video surveillance to analyze and forensically document. We present three complementary methods for scoring automated threat identification using multiple knife image datasets, each with the goal of narrowing down possible assault intentions while minimizing misidentifying false positives and risky false negatives. To alert an observer to the knife-wielding threat, we test and deploy classification built around MobileNet in a sparse and pruned neural network with a small memory requirement (< 2.2 megabytes) and 95% test accuracy. We secondly train a detection algorithm (MaskRCNN) to segment the hand from the knife in a single image and assign probable certainty to their relative location. This segmentation accomplishes both localization with bounding boxes but also relative positions to infer overhand threats. A final model built on the PoseNet architecture assigns anatomical waypoints or skeletal features to narrow the threat characteristics and reduce misunderstood intentions. We further identify and supplement existing data gaps that might blind a deployed knife threat detector such as collecting innocuous hand and fist images as important negative training sets. When automated on commodity hardware and software solutions one original research contribution is this systematic survey of timely and readily available image-based alerts to task and prioritize crime prevention countermeasures prior to a tragic outcome.
A Method for Arbitrary Instance Style Transfer
Dec 13, 2019
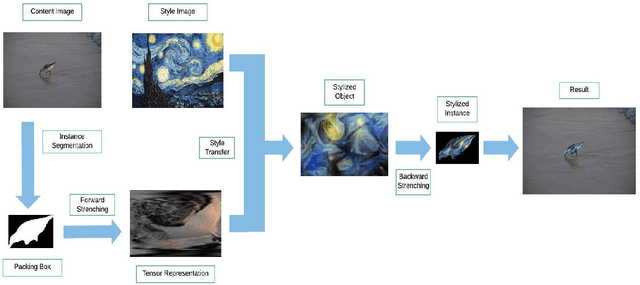

The ability to synthesize style and content of different images to form a visually coherent image holds great promise in various applications such as stylistic painting, design prototyping, image editing, and augmented reality. However, the majority of works in image style transfer have focused on transferring the style of an image to the entirety of another image, and only a very small number of works have experimented on methods to transfer style to an instance of another image. Researchers have proposed methods to circumvent the difficulty of transferring style to an instance in an arbitrary shape. In this paper, we propose a topologically inspired algorithm called Forward Stretching to tackle this problem by transforming an instance into a tensor representation, which allows us to transfer style to this instance itself directly. Forward Stretching maps pixels to specific positions and interpolate values between pixels to transform an instance to a tensor. This algorithm allows us to introduce a method to transfer arbitrary style to an instance in an arbitrary shape. We showcase the results of our method in this paper.
FaceSpoof Buster: a Presentation Attack Detector Based on Intrinsic Image Properties and Deep Learning
Feb 07, 2019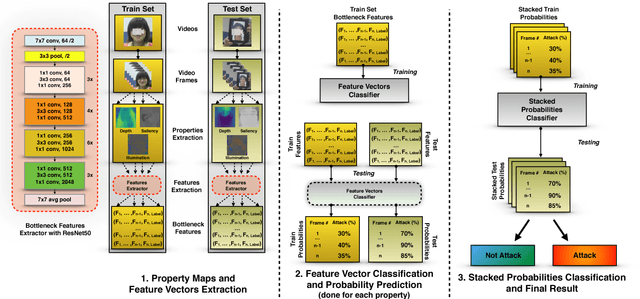
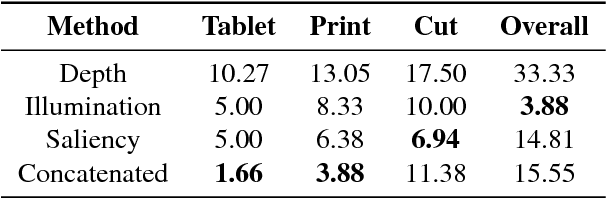
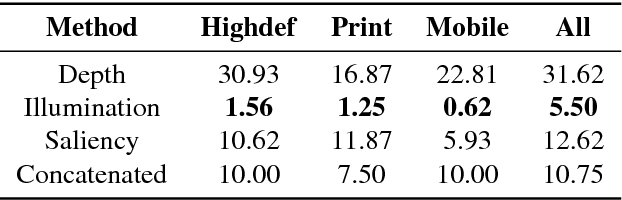
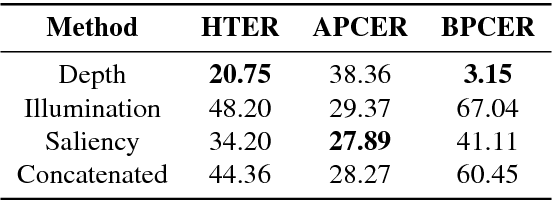
Nowadays, the adoption of face recognition for biometric authentication systems is usual, mainly because this is one of the most accessible biometric modalities. Techniques that rely on trespassing these kind of systems by using a forged biometric sample, such as a printed paper or a recorded video of a genuine access, are known as presentation attacks, but may be also referred in the literature as face spoofing. Presentation attack detection is a crucial step for preventing this kind of unauthorized accesses into restricted areas and/or devices. In this paper, we propose a novel approach which relies in a combination between intrinsic image properties and deep neural networks to detect presentation attack attempts. Our method explores depth, salience and illumination maps, associated with a pre-trained Convolutional Neural Network in order to produce robust and discriminant features. Each one of these properties are individually classified and, in the end of the process, they are combined by a meta learning classifier, which achieves outstanding results on the most popular datasets for PAD. Results show that proposed method is able to overpass state-of-the-art results in an inter-dataset protocol, which is defined as the most challenging in the literature.
Sparse-View Spectral CT Reconstruction Using Deep Learning
Nov 30, 2020
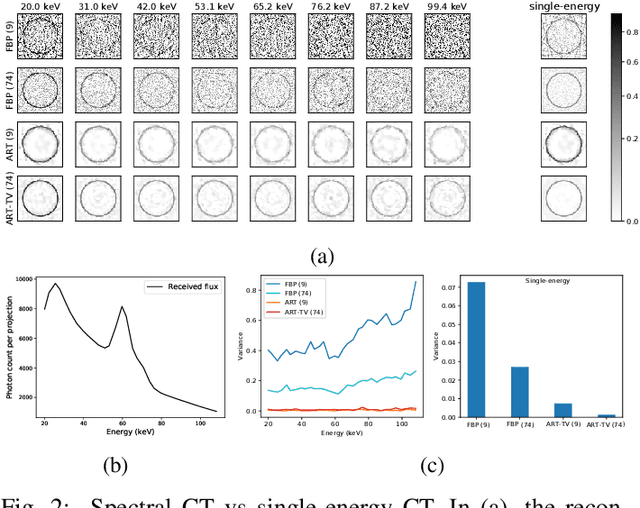
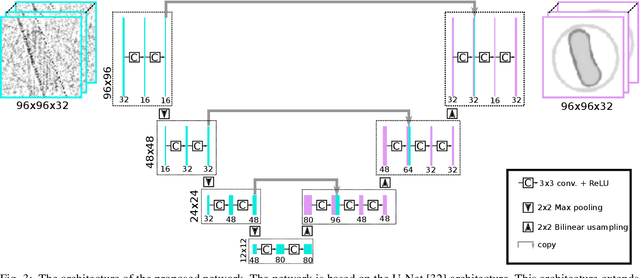

Spectral CT is an emerging technology capable of providing high chemical specificity, which is crucial for many applications such as detecting threats in luggage. Such applications often require both fast and high-quality image reconstruction based on sparse-view (few) projections. The conventional FBP method is fast but it produces low-quality images dominated by noise and artifacts when few projections are available. Iterative methods with, e.g., TV regularizers can circumvent that but they are computationally expensive, with the computational load proportionally increasing with the number of spectral channels. Instead, we propose an approach for fast reconstruction of sparse-view spectral CT data using U-Net with multi-channel input and output. The network is trained to output high-quality images from input images reconstructed by FBP. The network is fast at run-time and because the internal convolutions are shared between the channels, the computation load increases only at the first and last layers, making it an efficient approach to process spectral data with a large number of channels. We validated our approach using real CT scans. The results show qualitatively and quantitatively that our approach is able to outperform the state-of-the-art iterative methods. Furthermore, the results indicate that the network is able to exploit the coupling of the channels to enhance the overall quality and robustness.
DeepPhaseCut: Deep Relaxation in Phase for Unsupervised Fourier Phase Retrieval
Nov 20, 2020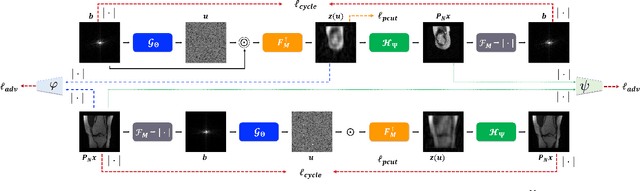
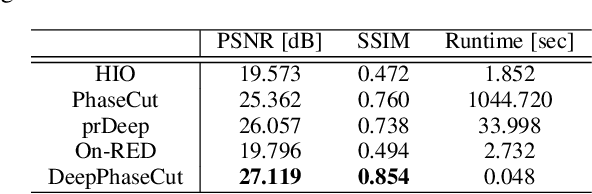
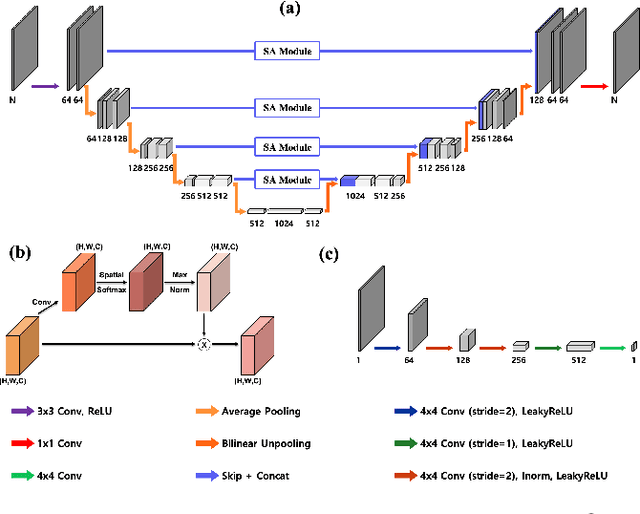
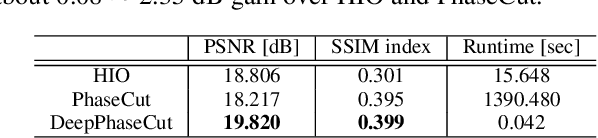
Fourier phase retrieval is a classical problem of restoring a signal only from the measured magnitude of its Fourier transform. Although Fienup-type algorithms, which use prior knowledge in both spatial and Fourier domains, have been widely used in practice, they can often stall in local minima. Modern methods such as PhaseLift and PhaseCut may offer performance guarantees with the help of convex relaxation. However, these algorithms are usually computationally intensive for practical use. To address this problem, we propose a novel, unsupervised, feed-forward neural network for Fourier phase retrieval which enables immediate high quality reconstruction. Unlike the existing deep learning approaches that use a neural network as a regularization term or an end-to-end blackbox model for supervised training, our algorithm is a feed-forward neural network implementation of PhaseCut algorithm in an unsupervised learning framework. Specifically, our network is composed of two generators: one for the phase estimation using PhaseCut loss, followed by another generator for image reconstruction, all of which are trained simultaneously using a cycleGAN framework without matched data. The link to the classical Fienup-type algorithms and the recent symmetry-breaking learning approach is also revealed. Extensive experiments demonstrate that the proposed method outperforms all existing approaches in Fourier phase retrieval problems.