 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
DFR: Deep Feature Reconstruction for Unsupervised Anomaly Segmentation
Dec 13, 2020
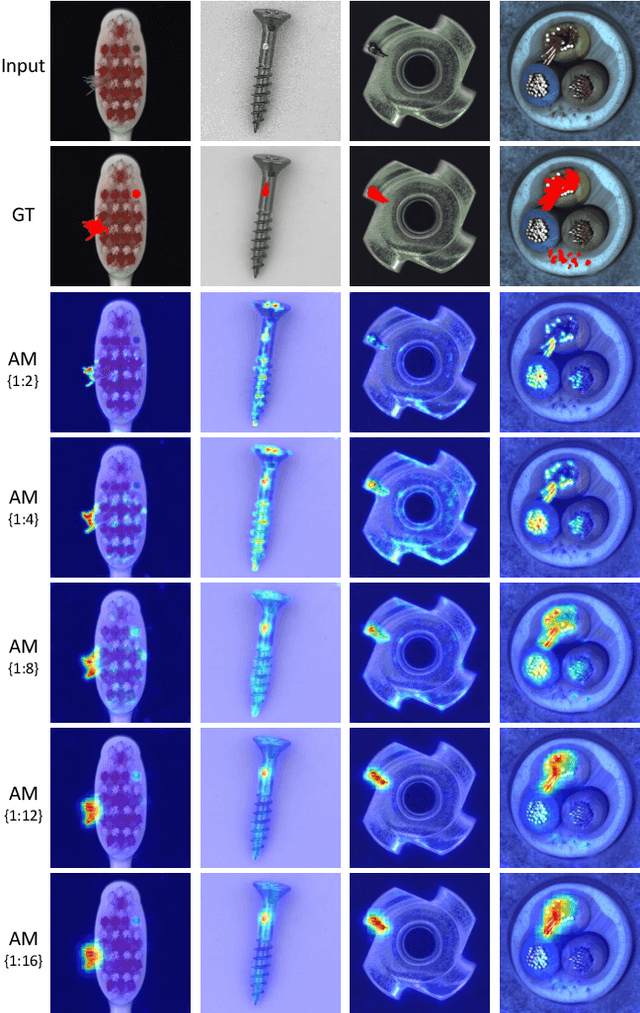
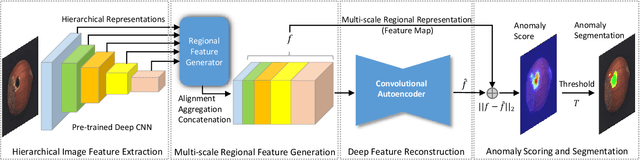
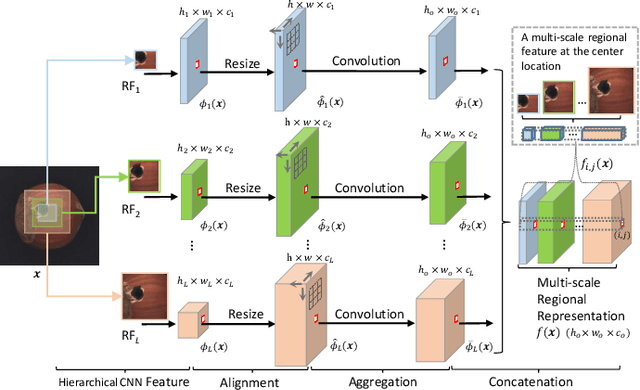
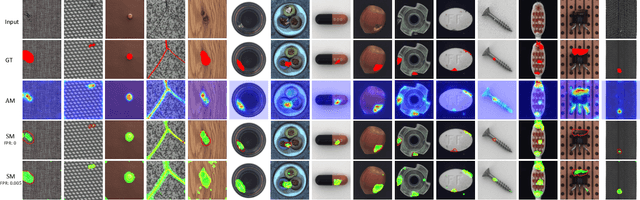
Automatic detecting anomalous regions in images of objects or textures without priors of the anomalies is challenging, especially when the anomalies appear in very small areas of the images, making difficult-to-detect visual variations, such as defects on manufacturing products. This paper proposes an effective unsupervised anomaly segmentation approach that can detect and segment out the anomalies in small and confined regions of images. Concretely, we develop a multi-scale regional feature generator that can generate multiple spatial context-aware representations from pre-trained deep convolutional networks for every subregion of an image. The regional representations not only describe the local characteristics of corresponding regions but also encode their multiple spatial context information, making them discriminative and very beneficial for anomaly detection. Leveraging these descriptive regional features, we then design a deep yet efficient convolutional autoencoder and detect anomalous regions within images via fast feature reconstruction. Our method is simple yet effective and efficient. It advances the state-of-the-art performances on several benchmark datasets and shows great potential for real applications.
Improving the Transferability of Adversarial Examples with the Adam Optimizer
Dec 01, 2020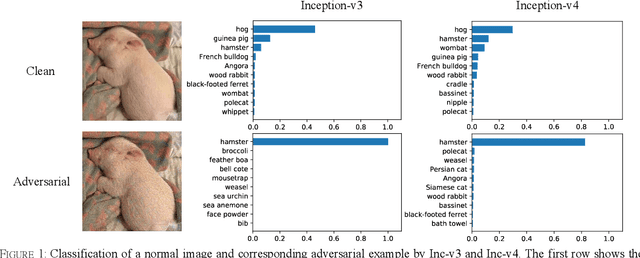
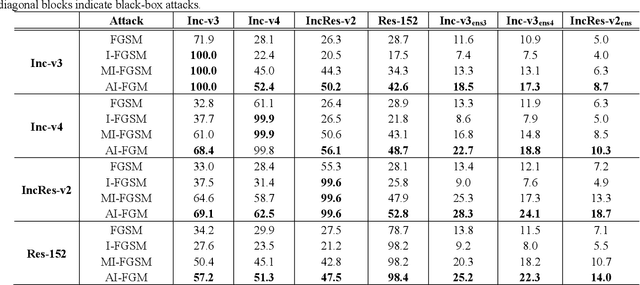
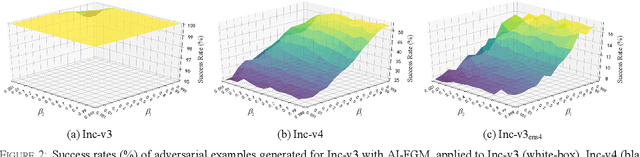
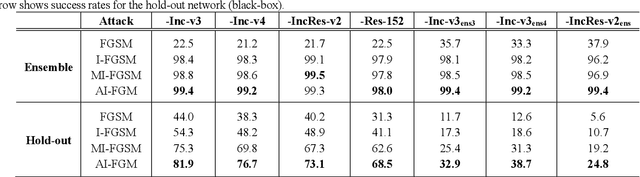
Convolutional neural networks have outperformed humans in image recognition tasks, but they remain vulnerable to attacks from adversarial examples. Since these data are produced by adding imperceptible noise to normal images, their existence poses potential security threats to deep learning systems. Sophisticated adversarial examples with strong attack performance can also be used as a tool to evaluate the robustness of a model. However, the success rate of adversarial attacks remains to be further improved in black-box environments. Therefore, this study combines an improved Adam gradient descent algorithm with the iterative gradient-based attack method. The resulting Adam Iterative Fast Gradient Method is then used to improve the transferability of adversarial examples. Extensive experiments on ImageNet showed that the proposed method offers a higher attack success rate than existing iterative methods. Our best black-box attack achieved a success rate of 81.9% on a normally trained network and 38.7% on an adversarially trained network.
More Informed Random Sample Consensus
Nov 18, 2020
Random sample consensus (RANSAC) is a robust model-fitting algorithm. It is widely used in many fields including image-stitching and point cloud registration. In RANSAC, data is uniformly sampled for hypothesis generation. However, this uniform sampling strategy does not fully utilize all the information on many problems. In this paper, we propose a method that samples data with a L\'{e}vy distribution together with a data sorting algorithm. In the hypothesis sampling step of the proposed method, data is sorted with a sorting algorithm we proposed, which sorts data based on the likelihood of a data point being in the inlier set. Then, hypotheses are sampled from the sorted data with L\'{e}vy distribution. The proposed method is evaluated on both simulation and real-world public datasets. Our method shows better results compared with the uniform baseline method.
SAR Image Despeckling Using Quadratic-Linear Approximated L1-Norm
Jan 15, 2018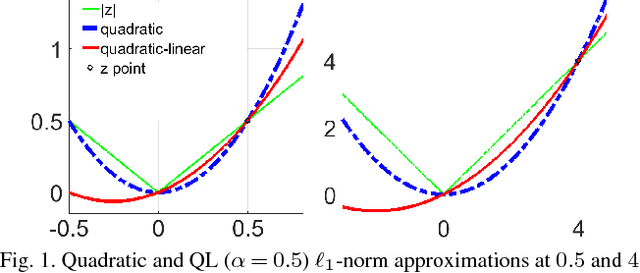

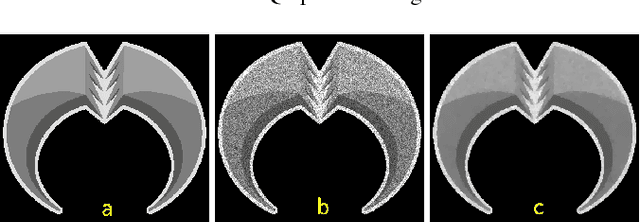
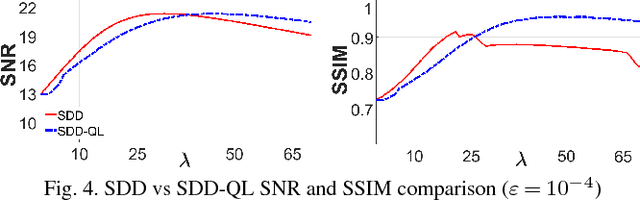
Speckle noise, inherent in synthetic aperture radar (SAR) images, degrades the performance of the various SAR image analysis tasks. Thus, speckle noise reduction is a critical preprocessing step for smoothing homogeneous regions while preserving details. This letter proposes a variational despeckling approach where L1-norm total variation regularization term is approximated in a quadratic and linear manner to increase accuracy while decreasing the computation time. Despeckling performance and computational efficiency of the proposed method are shown using synthetic and real-world SAR images.
Overfitting for Fun and Profit: Instance-Adaptive Data Compression
Jan 21, 2021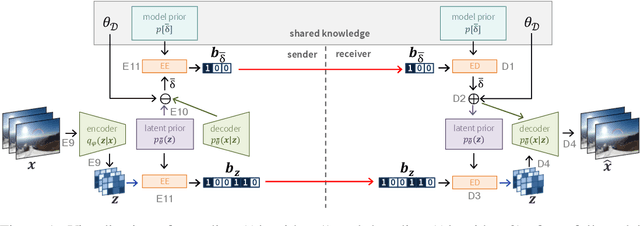

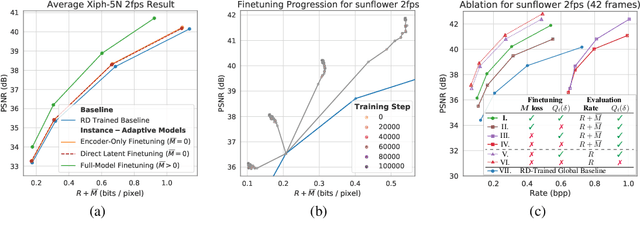
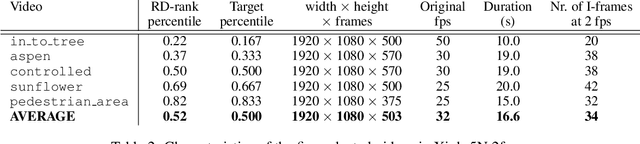
Neural data compression has been shown to outperform classical methods in terms of $RD$ performance, with results still improving rapidly. At a high level, neural compression is based on an autoencoder that tries to reconstruct the input instance from a (quantized) latent representation, coupled with a prior that is used to losslessly compress these latents. Due to limitations on model capacity and imperfect optimization and generalization, such models will suboptimally compress test data in general. However, one of the great strengths of learned compression is that if the test-time data distribution is known and relatively low-entropy (e.g. a camera watching a static scene, a dash cam in an autonomous car, etc.), the model can easily be finetuned or adapted to this distribution, leading to improved $RD$ performance. In this paper we take this concept to the extreme, adapting the full model to a single video, and sending model updates (quantized and compressed using a parameter-space prior) along with the latent representation. Unlike previous work, we finetune not only the encoder/latents but the entire model, and - during finetuning - take into account both the effect of model quantization and the additional costs incurred by sending the model updates. We evaluate an image compression model on I-frames (sampled at 2 fps) from videos of the Xiph dataset, and demonstrate that full-model adaptation improves $RD$ performance by ~1 dB, with respect to encoder-only finetuning.
Truly shift-invariant convolutional neural networks
Dec 01, 2020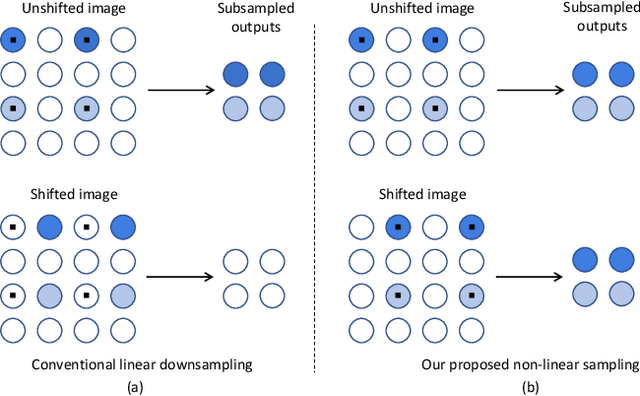
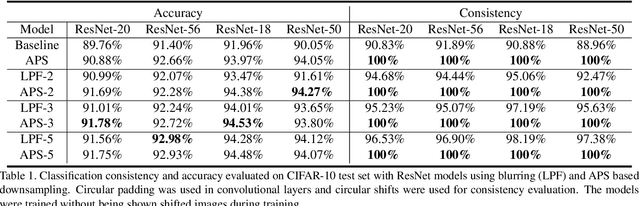
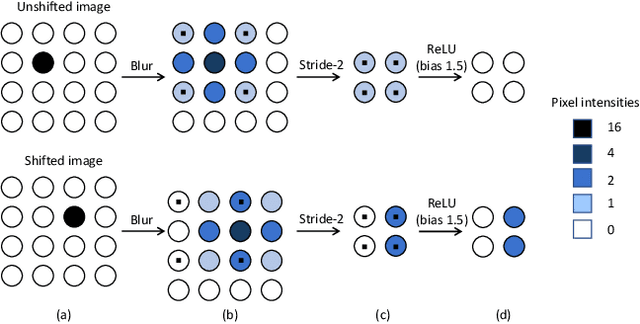
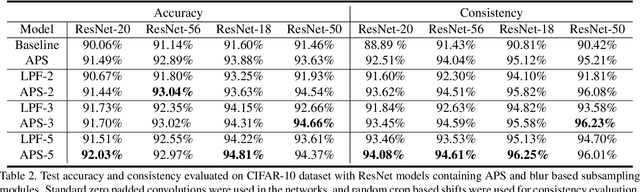
Thanks to the use of convolution and pooling layers, convolutional neural networks were for a long time thought to be shift-invariant. However, recent works have shown that the output of a CNN can change significantly with small shifts in input: a problem caused by the presence of downsampling (stride) layers. The existing solutions rely either on data augmentation or on anti-aliasing, both of which have limitations and neither of which enables perfect shift invariance. Additionally, the gains obtained from these methods do not extend to image patterns not seen during training. To address these challenges, we propose adaptive polyphase sampling (APS), a simple sub-sampling scheme that allows convolutional neural networks to achieve 100% consistency in classification performance under shifts, without any loss in accuracy. With APS the networks exhibit perfect consistency to shifts even before training, making it the first approach that makes convolutional neural networks truly shift invariant.
Meta-Transfer Learning for Zero-Shot Super-Resolution
Feb 27, 2020

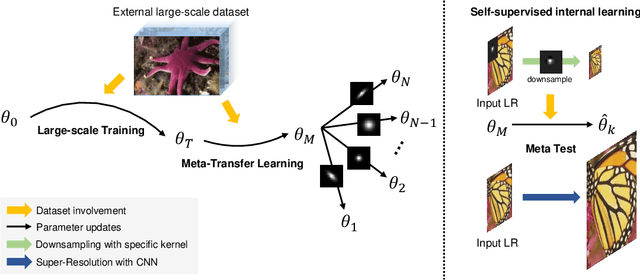
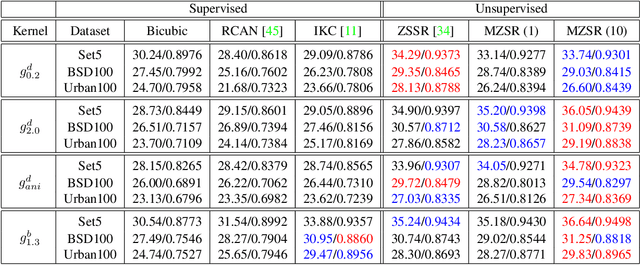
Convolutional neural networks (CNNs) have shown dramatic improvements in single image super-resolution (SISR) by using large-scale external samples. Despite their remarkable performance based on the external dataset, they cannot exploit internal information within a specific image. Another problem is that they are applicable only to the specific condition of data that they are supervised. For instance, the low-resolution (LR) image should be a "bicubic" downsampled noise-free image from a high-resolution (HR) one. To address both issues, zero-shot super-resolution (ZSSR) has been proposed for flexible internal learning. However, they require thousands of gradient updates, i.e., long inference time. In this paper, we present Meta-Transfer Learning for Zero-Shot Super-Resolution (MZSR), which leverages ZSSR. Precisely, it is based on finding a generic initial parameter that is suitable for internal learning. Thus, we can exploit both external and internal information, where one single gradient update can yield quite considerable results. (See Figure 1). With our method, the network can quickly adapt to a given image condition. In this respect, our method can be applied to a large spectrum of image conditions within a fast adaptation process.
Multi-modal Image Registration for Correlative Microscopy
Jan 13, 2015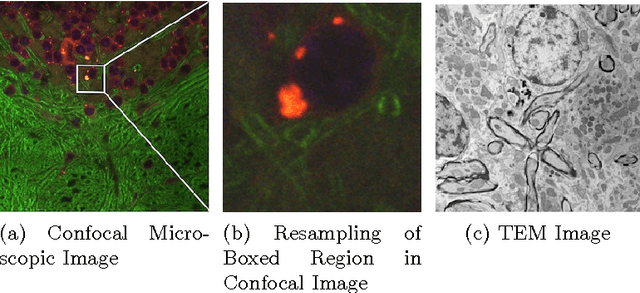
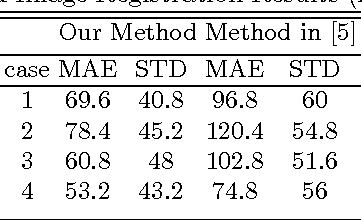

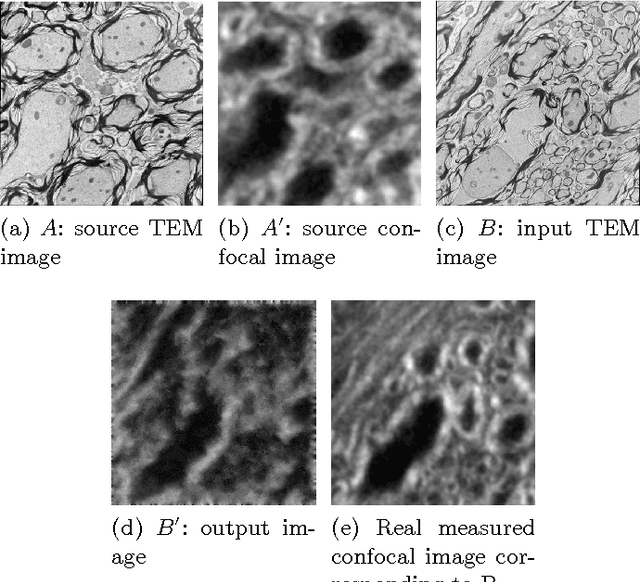
Correlative microscopy is a methodology combining the functionality of light microscopy with the high resolution of electron microscopy and other microscopy technologies. Image registration for correlative microscopy is quite challenging because it is a multi-modal, multi-scale and multi-dimensional registration problem. In this report, I introduce two methods of image registration for correlative microscopy. The first method is based on fiducials (beads). I generate landmarks from the fiducials and compute the similarity transformation matrix based on three pairs of nearest corresponding landmarks. A least-squares matching process is applied afterwards to further refine the registration. The second method is inspired by the image analogies approach. I introduce the sparse representation model into image analogies. I first train representative image patches (dictionaries) for pre-registered datasets from two different modalities, and then I use the sparse coding technique to transfer a given image to a predicted image from one modality to another based on the learned dictionaries. The final image registration is between the predicted image and the original image corresponding to the given image in the different modality. The method transforms a multi-modal registration problem to a mono-modal one. I test my approaches on Transmission Electron Microscopy (TEM) and confocal microscopy images. Experimental results of the methods are also shown in this report.
Progressive Adversarial Semantic Segmentation
May 08, 2020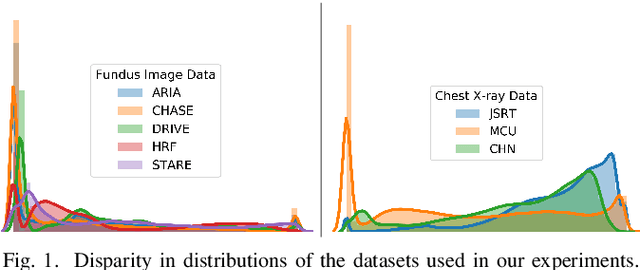
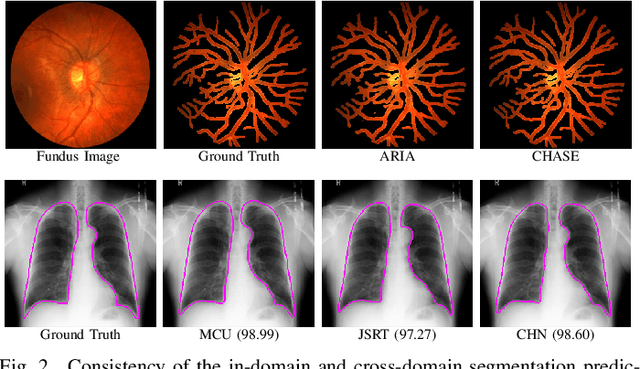
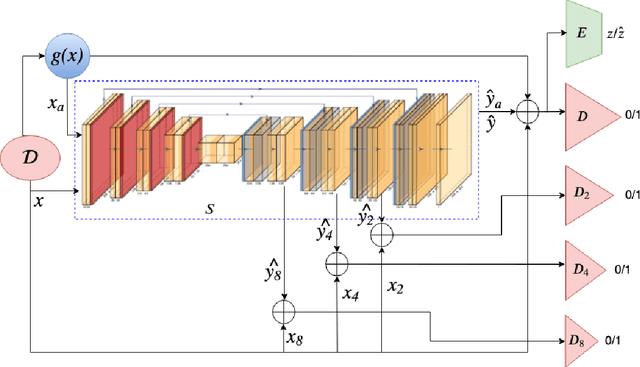
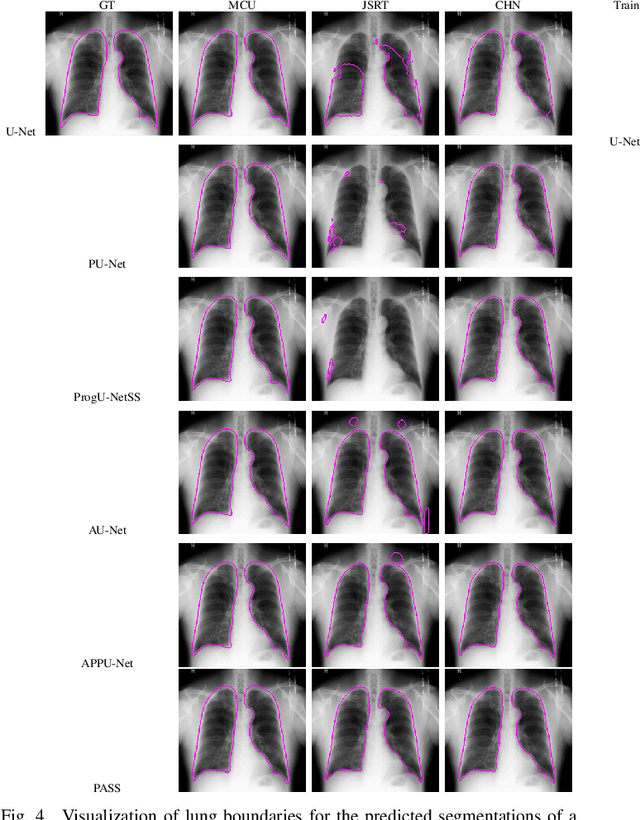
Medical image computing has advanced rapidly with the advent of deep learning techniques such as convolutional neural networks. Deep convolutional neural networks can perform exceedingly well given full supervision. However, the success of such fully-supervised models for various image analysis tasks (e.g., anatomy or lesion segmentation from medical images) is limited to the availability of massive amounts of labeled data. Given small sample sizes, such models are prohibitively data biased with large domain shift. To tackle this problem, we propose a novel end-to-end medical image segmentation model, namely Progressive Adversarial Semantic Segmentation (PASS), which can make improved segmentation predictions without requiring any domain-specific data during training time. Our extensive experimentation with 8 public diabetic retinopathy and chest X-ray datasets, confirms the effectiveness of PASS for accurate vascular and pulmonary segmentation, both for in-domain and cross-domain evaluations.
Each Part Matters: Local Patterns Facilitate Cross-view Geo-localization
Aug 26, 2020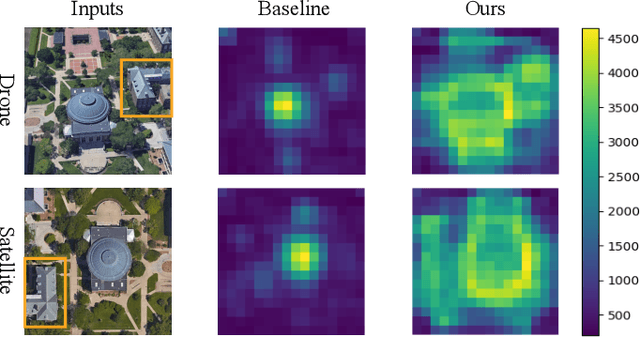

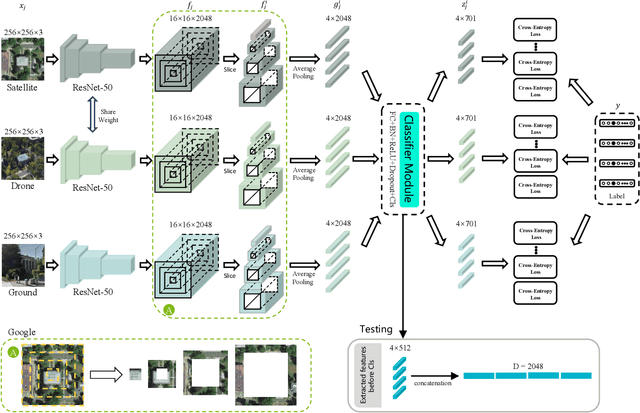
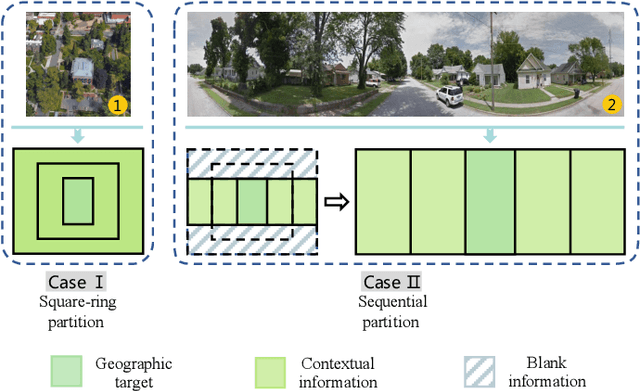
Cross-view geo-localization is to spot images of the same geographic target from different platforms, e.g., drone-view cameras and satellites. It is challenging in the large visual appearance changes caused by extreme viewpoint variations. Existing methods usually concentrate on mining the fine-grained feature of the geographic target in the image center, but underestimate the contextual information in neighbor areas. In this work, we argue that neighbor areas can be leveraged as auxiliary information, enriching discriminative clues for geo-localization. Specifically, we introduce a simple and effective deep neural network, called Local Pattern Network (LPN), to take advantage of contextual information in an end-to-end manner. Without using extra part estimators, LPN adopts a square-ring feature partition strategy, which provides the attention according to the distance to the image center. It eases the part matching and enables the part-wise representation learning. Owing to the square-ring partition design, the proposed LPN has good scalability to rotation variations and achieves competitive results on two prevailing benchmarks, i.e., University-1652 and CVUSA. Besides, we also show the proposed LPN can be easily embedded into other frameworks to further boost performance.