 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
GazeGAN - Unpaired Adversarial Image Generation for Gaze Estimation
Nov 27, 2017

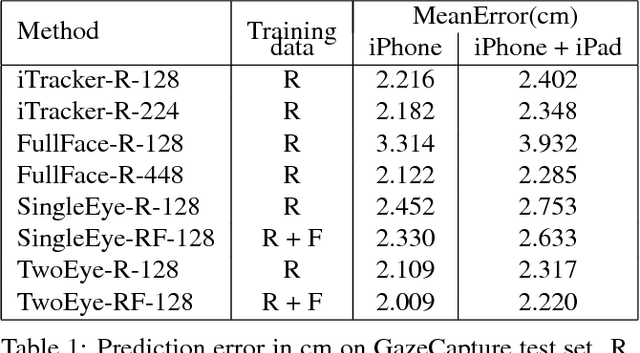
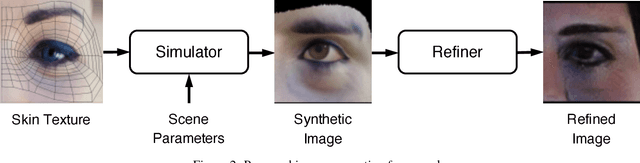
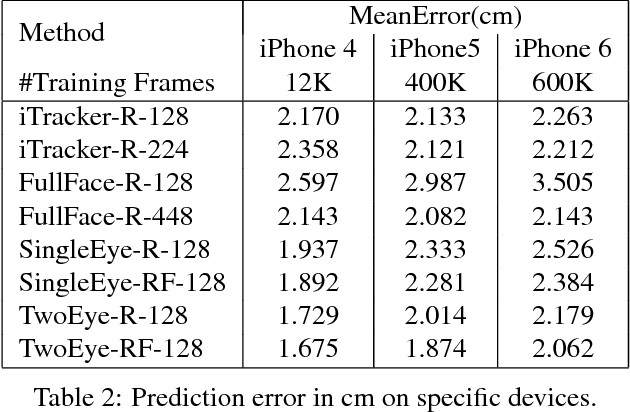
Recent research has demonstrated the ability to estimate gaze on mobile devices by performing inference on the image from the phone's front-facing camera, and without requiring specialized hardware. While this offers wide potential applications such as in human-computer interaction, medical diagnosis and accessibility (e.g., hands free gaze as input for patients with motor disorders), current methods are limited as they rely on collecting data from real users, which is a tedious and expensive process that is hard to scale across devices. There have been some attempts to synthesize eye region data using 3D models that can simulate various head poses and camera settings, however these lack in realism. In this paper, we improve upon a recently suggested method, and propose a generative adversarial framework to generate a large dataset of high resolution colorful images with high diversity (e.g., in subjects, head pose, camera settings) and realism, while simultaneously preserving the accuracy of gaze labels. The proposed approach operates on extended regions of the eye, and even completes missing parts of the image. Using this rich synthesized dataset, and without using any additional training data from real users, we demonstrate improvements over state-of-the-art for estimating 2D gaze position on mobile devices. We further demonstrate cross-device generalization of model performance, as well as improved robustness to diverse head pose, blur and distance.
Clearing the Skies: A deep network architecture for single-image rain removal
Feb 06, 2017



We introduce a deep network architecture called DerainNet for removing rain streaks from an image. Based on the deep convolutional neural network (CNN), we directly learn the mapping relationship between rainy and clean image detail layers from data. Because we do not possess the ground truth corresponding to real-world rainy images, we synthesize images with rain for training. In contrast to other common strategies that increase depth or breadth of the network, we use image processing domain knowledge to modify the objective function and improve deraining with a modestly-sized CNN. Specifically, we train our DerainNet on the detail (high-pass) layer rather than in the image domain. Though DerainNet is trained on synthetic data, we find that the learned network translates very effectively to real-world images for testing. Moreover, we augment the CNN framework with image enhancement to improve the visual results. Compared with state-of-the-art single image de-raining methods, our method has improved rain removal and much faster computation time after network training.
Efficiently Computing Piecewise Flat Embeddings for Data Clustering and Image Segmentation
Dec 20, 2016
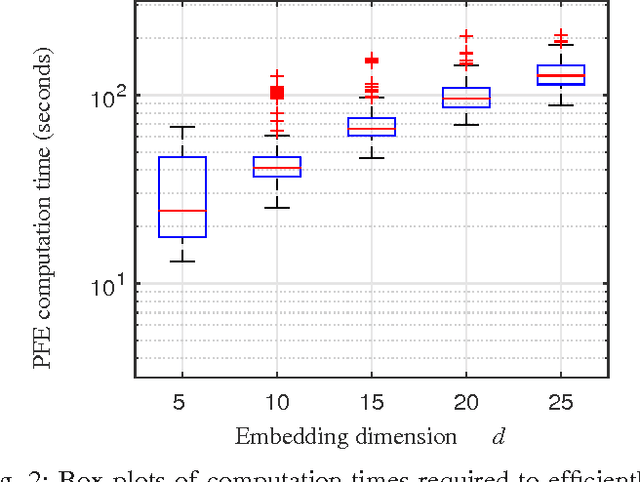
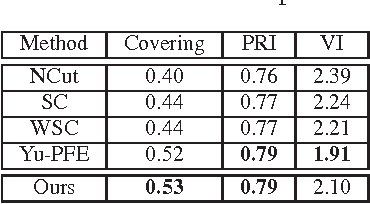
Image segmentation is a popular area of research in computer vision that has many applications in automated image processing. A recent technique called piecewise flat embeddings (PFE) has been proposed for use in image segmentation; PFE transforms image pixel data into a lower dimensional representation where similar pixels are pulled close together and dissimilar pixels are pushed apart. This technique has shown promising results, but its original formulation is not computationally feasible for large images. We propose two improvements to the algorithm for computing PFE: first, we reformulate portions of the algorithm to enable various linear algebra operations to be performed in parallel; second, we propose utilizing an iterative linear solver (preconditioned conjugate gradient) to quickly solve a linear least-squares problem that occurs in the inner loop of a nested iteration. With these two computational improvements, we show on a publicly available image database that PFE can be sped up by an order of magnitude without sacrificing segmentation performance. Our results make this technique more practical for use on large data sets, not only for image segmentation, but for general data clustering problems.
Stereo Vision Based Single-Shot 6D Object Pose Estimation for Bin-Picking by a Robot Manipulator
May 28, 2020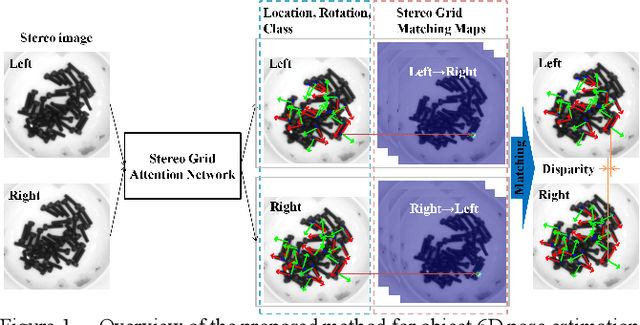
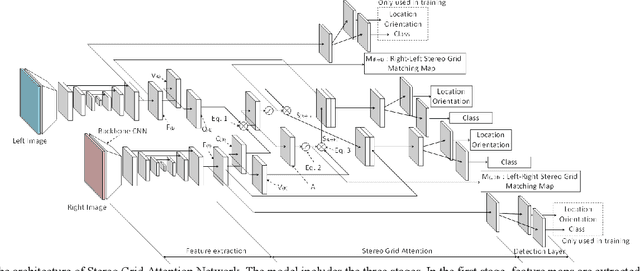

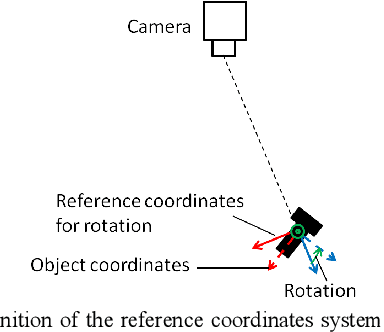
We propose a fast and accurate method of 6D object pose estimation for bin-picking of mechanical parts by a robot manipulator. We extend the single-shot approach to stereo vision by application of attention architecture. Our convolutional neural network model regresses to object locations and rotations from either a left image or a right image without depth information. Then, a stereo feature matching module, designated as Stereo Grid Attention, generates stereo grid matching maps. The important point of our method is only to calculate disparity of the objects found by the attention from stereo images, instead of calculating a point cloud over the entire image. The disparity value is then used to calculate the depth to the objects by the principle of triangulation. Our method also achieves a rapid processing speed of pose estimation by the single-shot architecture and it is possible to process a 1024 x 1024 pixels image in 75 milliseconds on the Jetson AGX Xavier implemented with half-float model. Weakly textured mechanical parts are used to exemplify the method. First, we create original synthetic datasets for training and evaluating of the proposed model. This dataset is created by capturing and rendering numerous 3D models of several types of mechanical parts in virtual space. Finally, we use a robotic manipulator with an electromagnetic gripper to pick up the mechanical parts in a cluttered state to verify the validity of our method in an actual scene. When a raw stereo image is used by the proposed method from our stereo camera to detect black steel screws, stainless screws, and DC motor parts, i.e., cases, rotor cores and commutator caps, the bin-picking tasks are successful with 76.3%, 64.0%, 50.5%, 89.1% and 64.2% probability, respectively.
A Feature Analysis for Multimodal News Retrieval
Jul 13, 2020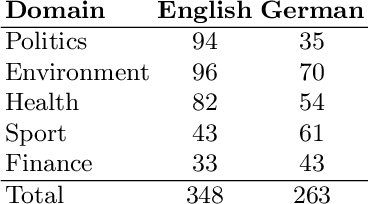

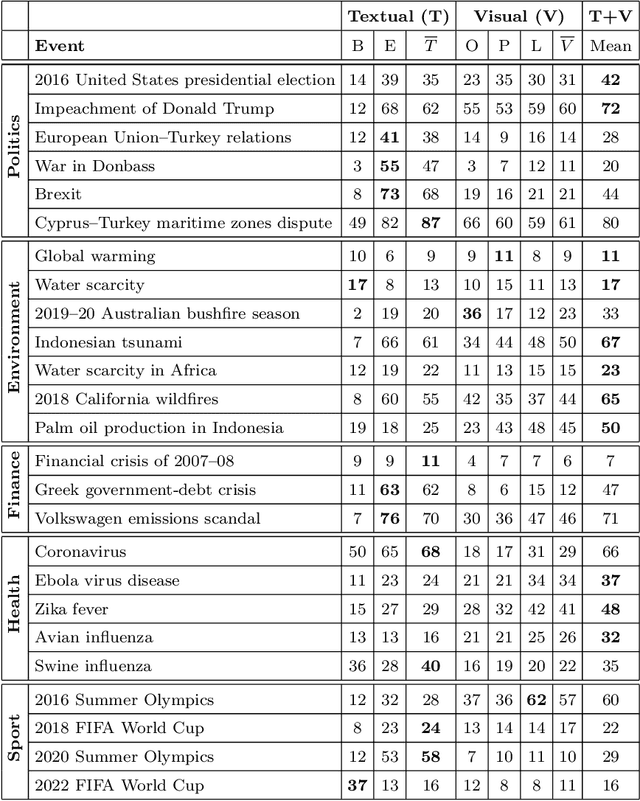
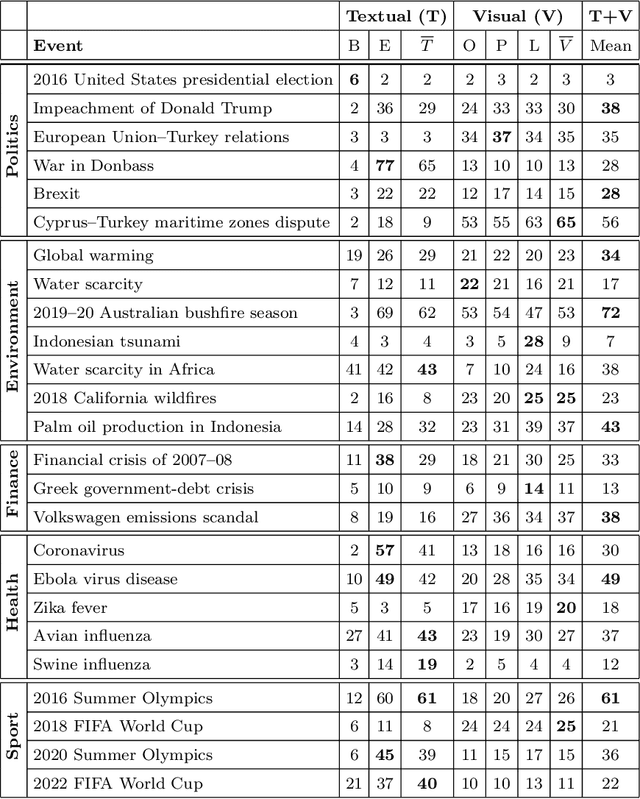
Content-based information retrieval is based on the information contained in documents rather than using metadata such as keywords. Most information retrieval methods are either based on text or image. In this paper, we investigate the usefulness of multimodal features for cross-lingual news search in various domains: politics, health, environment, sport, and finance. To this end, we consider five feature types for image and text and compare the performance of the retrieval system using different combinations. Experimental results show that retrieval results can be improved when considering both visual and textual information. In addition, it is observed that among textual features entity overlap outperforms word embeddings, while geolocation embeddings achieve better performance among visual features in the retrieval task.
Association: Remind Your GAN not to Forget
Nov 27, 2020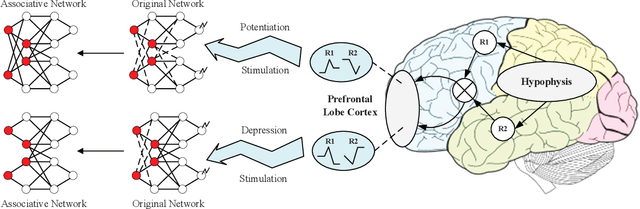
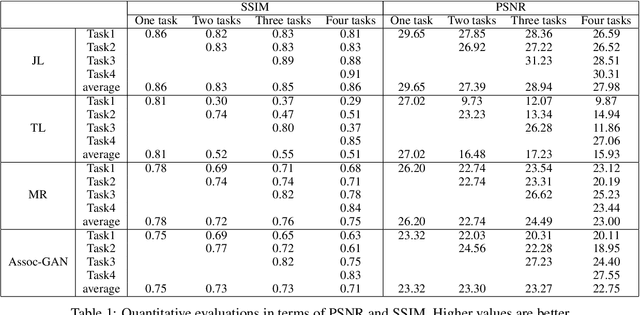
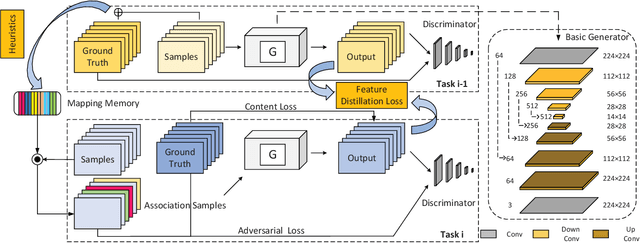

Neural networks are susceptible to catastrophic forgetting. They fail to preserve previously acquired knowledge when adapting to new tasks. Inspired by human associative memory system, we propose a brain-like approach that imitates the associative learning process to achieve continual learning. We design a heuristics mechanism to potentiatively stimulates the model, which guides the model to recall the historical episodes based on the current circumstance and obtained association experience. Besides, a distillation measure is added to depressively alter the efficacy of synaptic transmission, which dampens the feature reconstruction learning for new task. The framework is mediated by potentiation and depression stimulation that play opposing roles in directing synaptic and behavioral plasticity. It requires no access to the original data and is more similar to human cognitive process. Experiments demonstrate the effectiveness of our method in alleviating catastrophic forgetting on continual image reconstruction problems.
Efficient Conditional Pre-training for Transfer Learning
Dec 10, 2020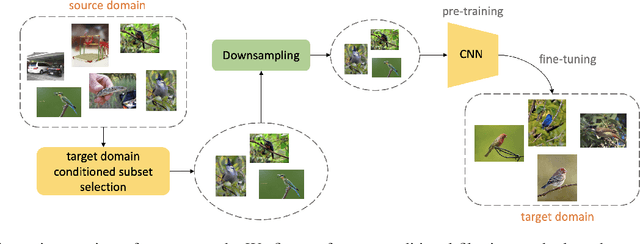
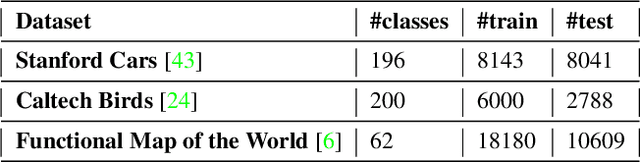
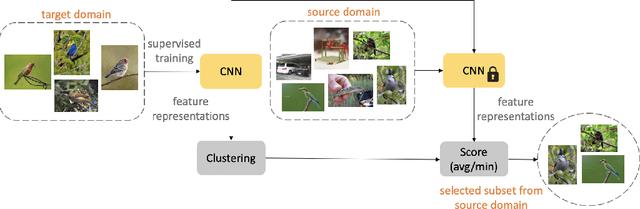
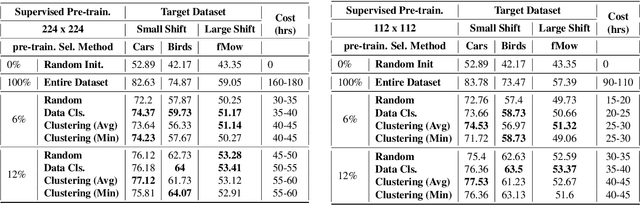
Almost all the state-of-the-art neural networks for computer vision tasks are trained by (1) Pre-training on a large scale dataset and (2) finetuning on the target dataset. This strategy helps reduce the dependency on the target dataset and improves convergence rate and generalization on the target task. Although pre-training on large scale datasets is very useful, its foremost disadvantage is high training cost. To address this, we propose efficient target dataset conditioned filtering methods to remove less relevant samples from the pre-training dataset. Unlike prior work, we focus on efficiency, adaptability, and flexibility in addition to performance. Additionally, we discover that lowering image resolutions in the pre-training step offers a great trade-off between cost and performance. We validate our techniques by pre-training on ImageNet in both the unsupervised and supervised settings and finetuning on a diverse collection of target datasets and tasks. Our proposed methods drastically reduce pre-training cost and provide strong performance boosts.
Adversarial Attack on Deep Learning-Based Splice Localization
Apr 17, 2020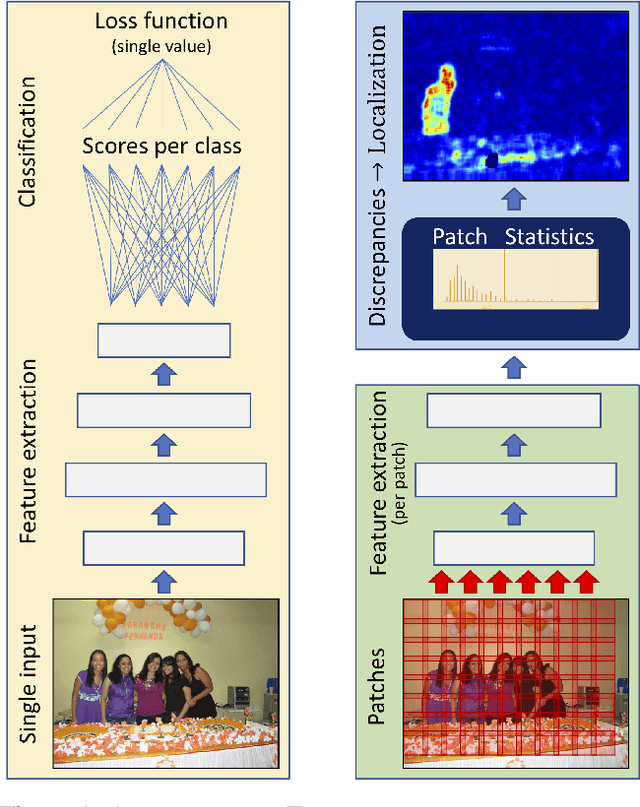
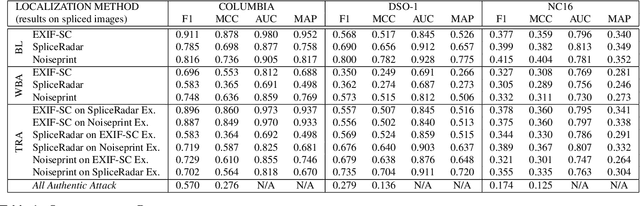
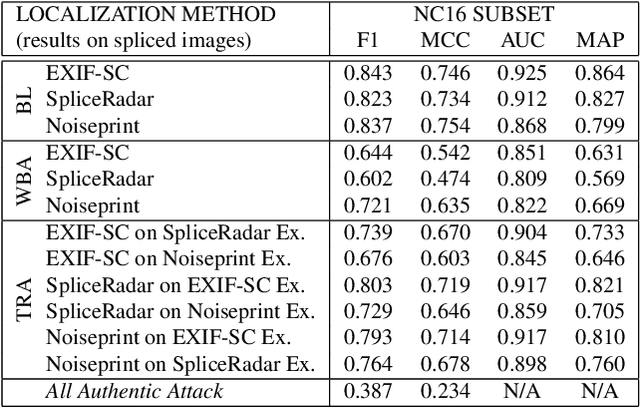
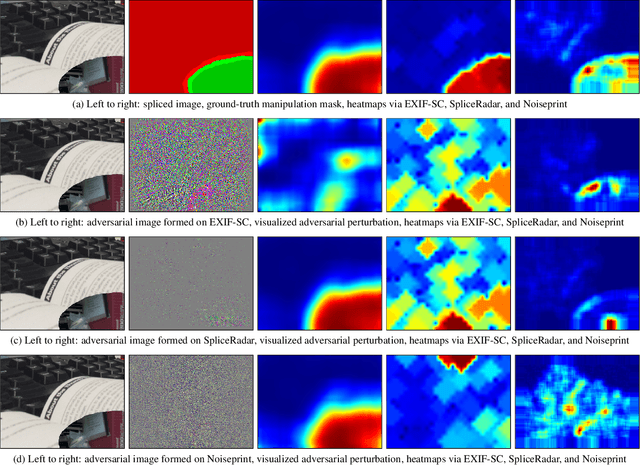
Regarding image forensics, researchers have proposed various approaches to detect and/or localize manipulations, such as splices. Recent best performing image-forensics algorithms greatly benefit from the application of deep learning, but such tools can be vulnerable to adversarial attacks. Due to the fact that most of the proposed adversarial example generation techniques can be used only on end-to-end classifiers, the adversarial robustness of image-forensics methods that utilize deep learning only for feature extraction has not been studied yet. Using a novel algorithm capable of directly adjusting the underlying representations of patches we demonstrate on three non end-to-end deep learning-based splice localization tools that hiding manipulations of images is feasible via adversarial attacks. While the tested image-forensics methods, EXIF-SC, SpliceRadar, and Noiseprint, rely on feature extractors that were trained on different surrogate tasks, we find that the formed adversarial perturbations can be transferable among them regarding the deterioration of their localization performance.
Objective Evaluation of Deep Uncertainty Predictions for COVID-19 Detection
Dec 22, 2020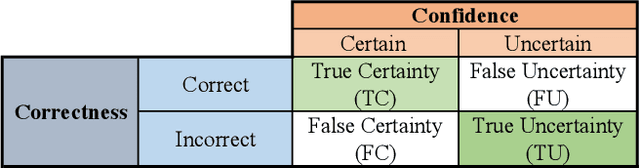

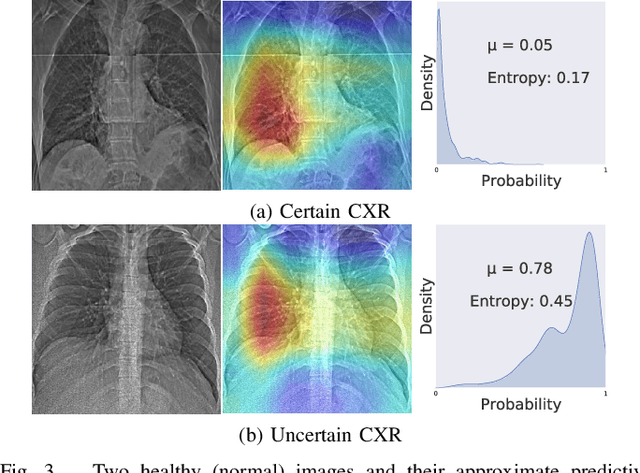
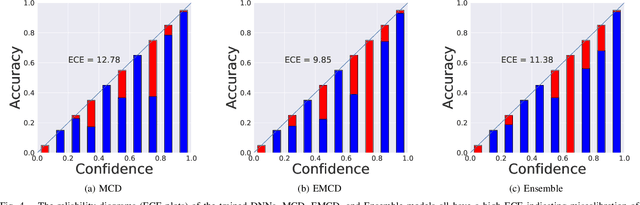
Deep neural networks (DNNs) have been widely applied for detecting COVID-19 in medical images. Existing studies mainly apply transfer learning and other data representation strategies to generate accurate point estimates. The generalization power of these networks is always questionable due to being developed using small datasets and failing to report their predictive confidence. Quantifying uncertainties associated with DNN predictions is a prerequisite for their trusted deployment in medical settings. Here we apply and evaluate three uncertainty quantification techniques for COVID-19 detection using chest X-Ray (CXR) images. The novel concept of uncertainty confusion matrix is proposed and new performance metrics for the objective evaluation of uncertainty estimates are introduced. Through comprehensive experiments, it is shown that networks pertained on CXR images outperform networks pretrained on natural image datasets such as ImageNet. Qualitatively and quantitatively evaluations also reveal that the predictive uncertainty estimates are statistically higher for erroneous predictions than correct predictions. Accordingly, uncertainty quantification methods are capable of flagging risky predictions with high uncertainty estimates. We also observe that ensemble methods more reliably capture uncertainties during the inference.
Cooperating RPN's Improve Few-Shot Object Detection
Nov 19, 2020
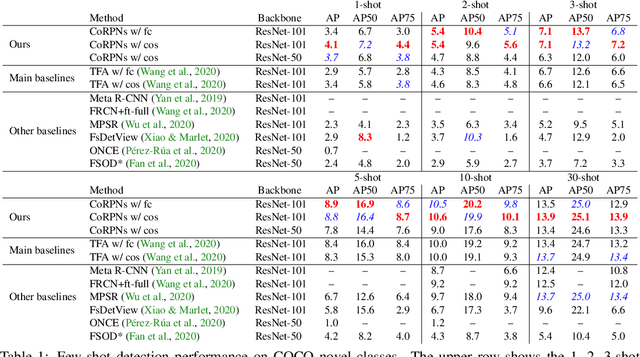
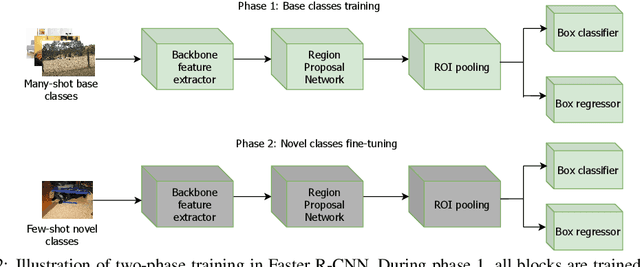
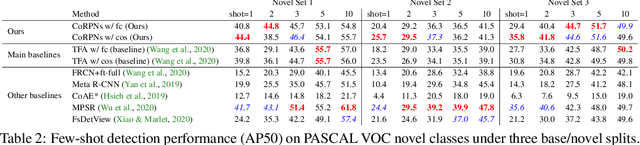
Learning to detect an object in an image from very few training examples - few-shot object detection - is challenging, because the classifier that sees proposal boxes has very little training data. A particularly challenging training regime occurs when there are one or two training examples. In this case, if the region proposal network (RPN) misses even one high intersection-over-union (IOU) training box, the classifier's model of how object appearance varies can be severely impacted. We use multiple distinct yet cooperating RPN's. Our RPN's are trained to be different, but not too different; doing so yields significant performance improvements over state of the art for COCO and PASCAL VOC in the very few-shot setting. This effect appears to be independent of the choice of classifier or dataset.