 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Bitstream-Based JPEG Image Encryption with File-Size Preserving
Aug 17, 2018
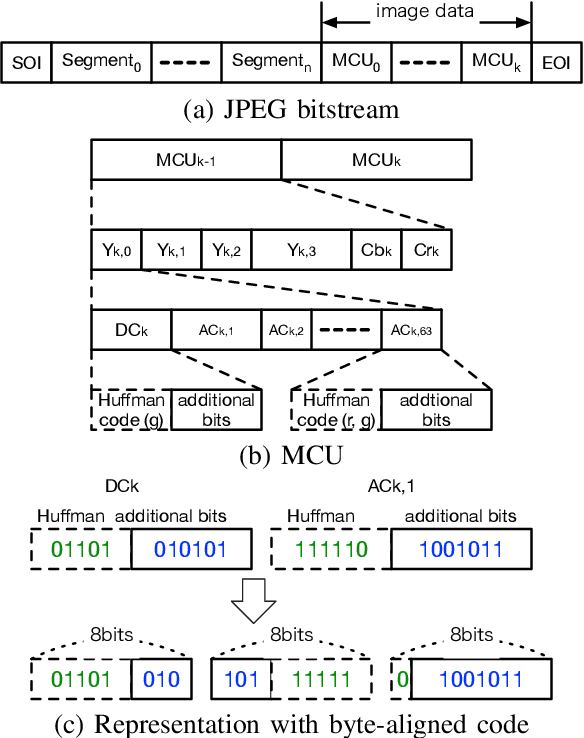
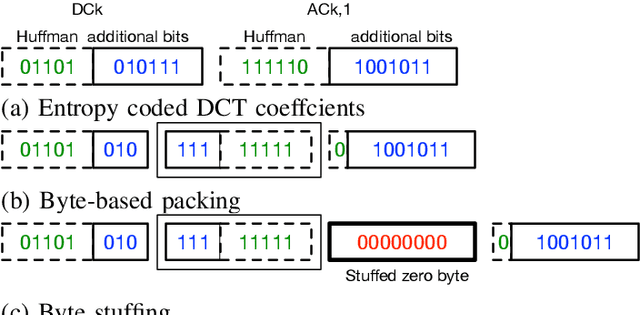
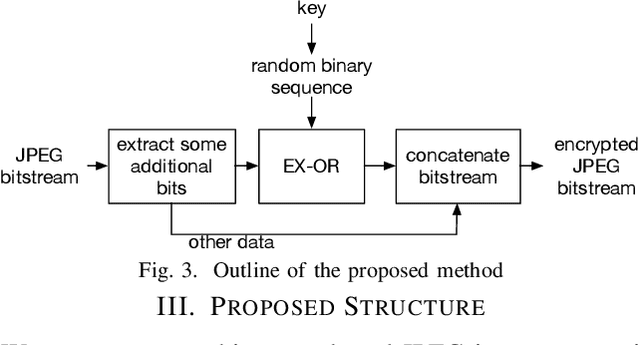

An encryption scheme of JPEG images in the bitstream domain is proposed. The proposed scheme preserves the JPEG format even after encrypting the images, and the file size of encrypted images is the exact same as that of the original JPEG images. Several methods for encrypting JPEG images in the bitstream domain have been proposed. However, since some marker codes are generated or lost in the encryption process, the file size of JPEG bitstreams is generally changed due to the encryption operations. The proposed method inputs JPEG bitstreams and selectively encrypts the additional bit components of the Huffman code in the bitstreams. This feature allows us to have encrypted images with the same data size as that recoded in the image transmission process, when JPEG images are replaced with the encrypted ones by the hooking, so that the image transmission are successfully carried out after the hooking.
A Recipe for Global Convergence Guarantee in Deep Neural Networks
Apr 15, 2021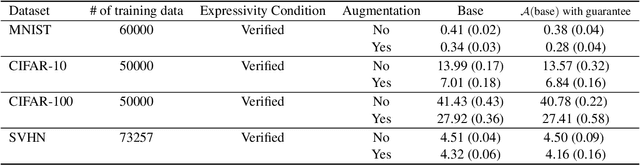
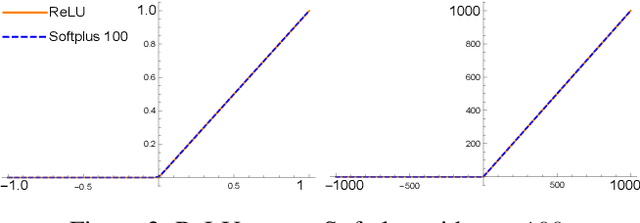

Existing global convergence guarantees of (stochastic) gradient descent do not apply to practical deep networks in the practical regime of deep learning beyond the neural tangent kernel (NTK) regime. This paper proposes an algorithm, which is ensured to have global convergence guarantees in the practical regime beyond the NTK regime, under a verifiable condition called the expressivity condition. The expressivity condition is defined to be both data-dependent and architecture-dependent, which is the key property that makes our results applicable for practical settings beyond the NTK regime. On the one hand, the expressivity condition is theoretically proven to hold data-independently for fully-connected deep neural networks with narrow hidden layers and a single wide layer. On the other hand, the expressivity condition is numerically shown to hold data-dependently for deep (convolutional) ResNet with batch normalization with various standard image datasets. We also show that the proposed algorithm has generalization performances comparable with those of the heuristic algorithm, with the same hyper-parameters and total number of iterations. Therefore, the proposed algorithm can be viewed as a step towards providing theoretical guarantees for deep learning in the practical regime.
Geospatial Transformations for Ground-Based Sky Imaging Systems
Mar 09, 2021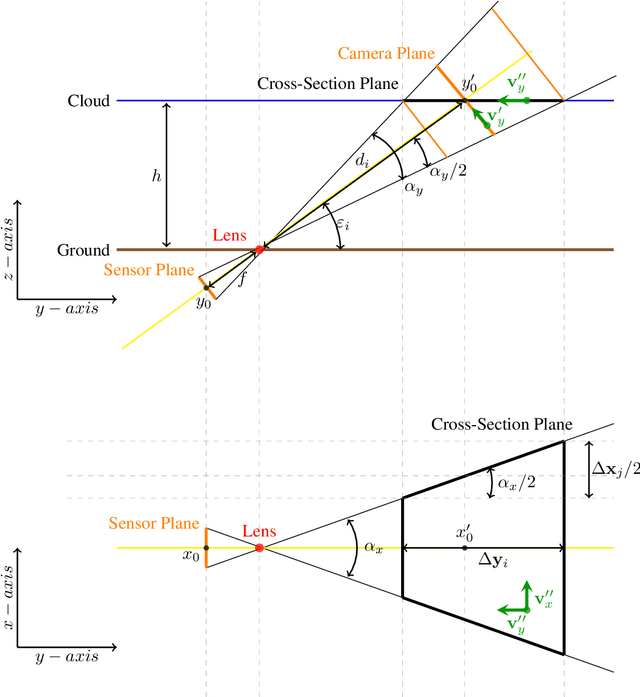
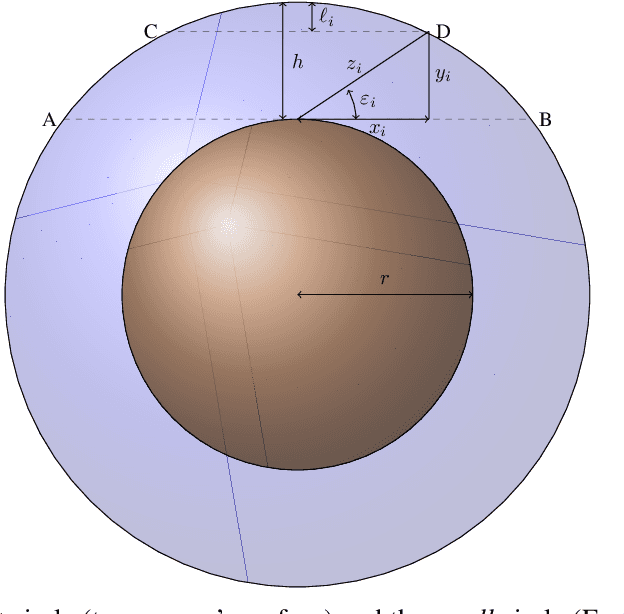
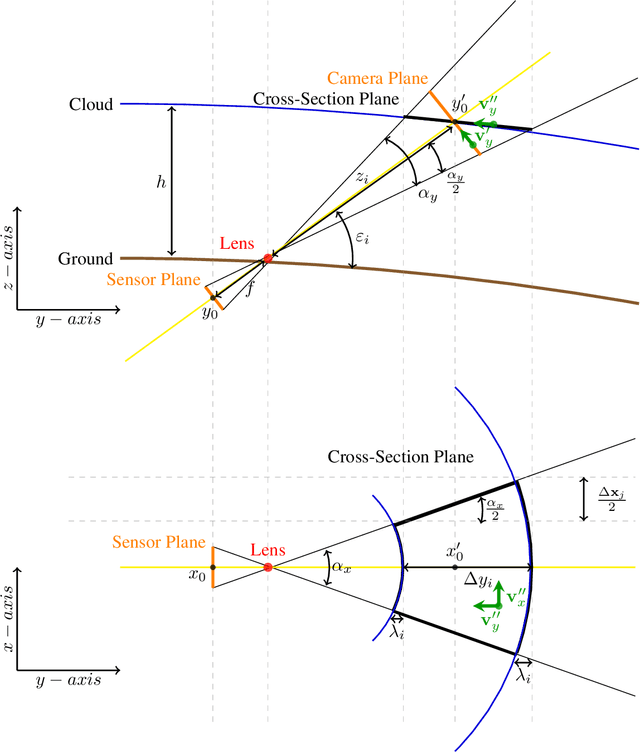

Sky imaging systems use lenses to acquire images concentrating light beams in an imager. The light beams received by the sky imager have an elevation angle with respect to the normal of the device. This produces that the image pixels contain information from different areas of the sky within the imaging system Field Of View (FOV). The area of the field of view contained in the pixels increases as the elevation angle of the incident light beams decreases. When the sky imagers are mounted on a solar tracker incidence angle of the light beam on a pixel varies over time. This investigation introduces a transformation that projects the original euclidean frame of the imager plane to the geospatial frame atmosphere cross-section plane form when the sky imager field of view intersects the tropopause.
Automation of Hemocompatibility Analysis Using Image Segmentation and a Random Forest
Oct 13, 2020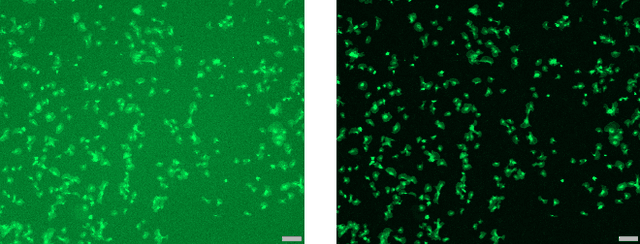

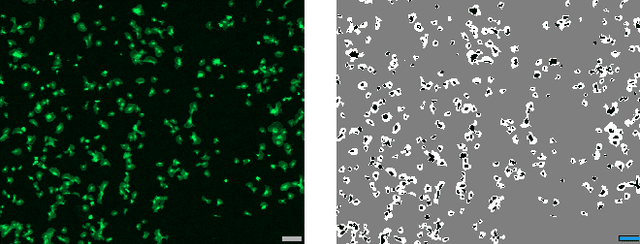
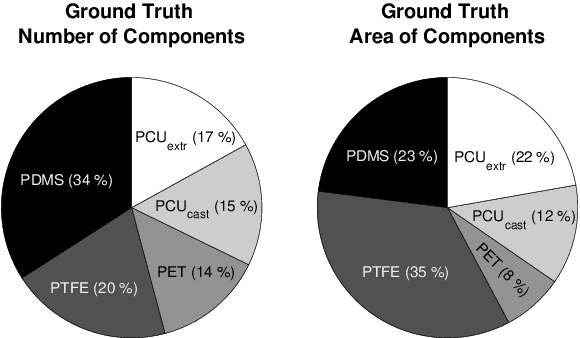
The hemocompatibility of blood-contacting medical devices remains one of the major challenges in biomedical engineering and makes research in the field of new and improved materials inevitable. However, current in-vitro test and analysis methods are still lacking standardization and comparability, which impedes advances in material design. For example, the optical platelet analysis of material in-vitro hemocompatibility tests is carried out manually or semi-manually by each research group individually. As a step towards standardization, this paper proposes an automation approach for the optical platelet count and analysis. To this end, fluorescence images are segmented using Zach's convexification of the multiphase-phase piecewise constant Mumford--Shah model. The resulting connected components of the non-background segments then need to be classified as platelet or no platelet. Therefore, a supervised random forest is applied to feature vectors derived from the components using features like area, perimeter and circularity. With an overall high accuracy and low error rates, the random forest achieves reliable results. This is supported by high areas under the receiver-operator and the prediction-recall curve, respectively. We developed a new method for a fast, user-independent and reproducible analysis of material hemocompatibility tests, which is therefore a unique and powerful tool for advances in biomaterial research.
A New Variational Model for Joint Image Reconstruction and Motion Estimation in Spatiotemporal Imaging
Dec 18, 2018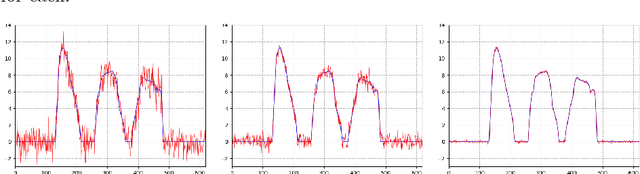



We propose a new variational model for joint image reconstruction and motion estimation in spatiotemporal imaging, which is investigated along a general framework that we present with shape theory. This model consists of two components, one for conducting modified static image reconstruction, and the other performs sequentially indirect image registration. For the latter, we generalize the large deformation diffeomorphic metric mapping framework into the sequentially indirect registration setting. The proposed model is compared theoretically against alternative approaches (optical flow based model and diffeomorphic motion models), and we demonstrate that the proposed model has desirable properties in terms of the optimal solution. The theoretical derivations and efficient algorithms are also presented for a time-discretized scenario of the proposed model, which show that the optimal solution of the time-discretized version is consistent with that of the time-continuous one, and most of the computational components is the easy-implemented linearized deformation. The complexity of the algorithm is analyzed as well. This work is concluded by some numerical examples in 2D space + time tomography with very sparse and/or highly noisy data.
Image reconstruction by domain transform manifold learning
Apr 28, 2017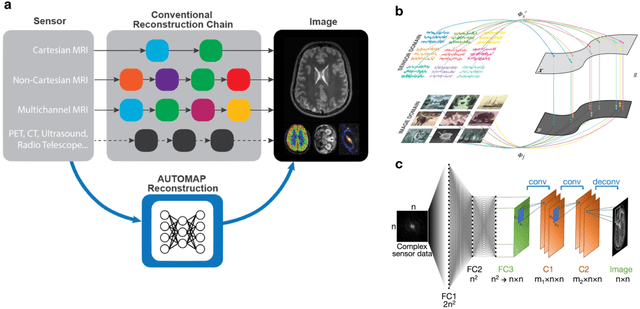
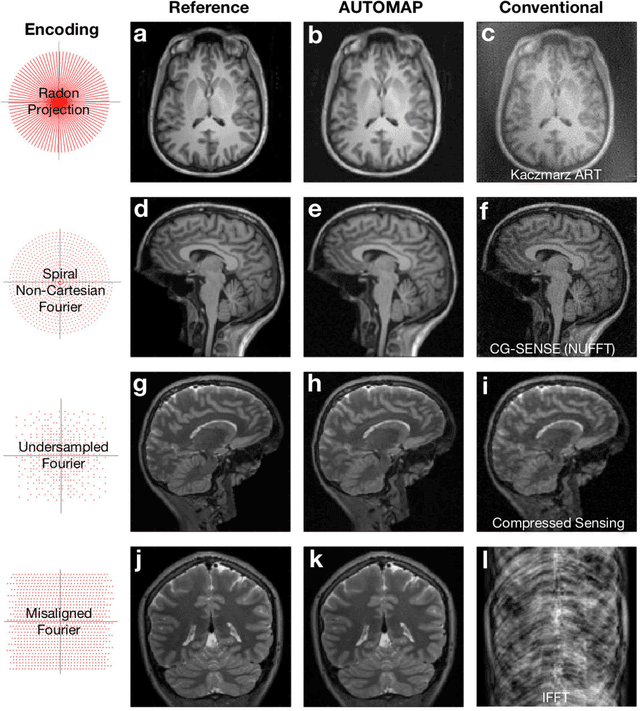
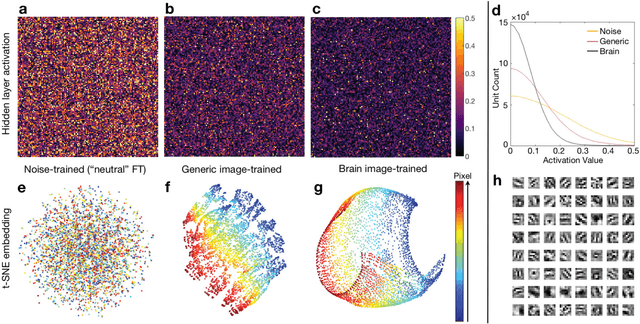
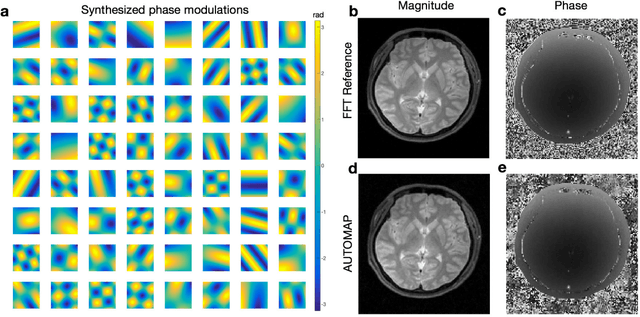
Image reconstruction plays a critical role in the implementation of all contemporary imaging modalities across the physical and life sciences including optical, MRI, CT, PET, and radio astronomy. During an image acquisition, the sensor encodes an intermediate representation of an object in the sensor domain, which is subsequently reconstructed into an image by an inversion of the encoding function. Image reconstruction is challenging because analytic knowledge of the inverse transform may not exist a priori, especially in the presence of sensor non-idealities and noise. Thus, the standard reconstruction approach involves approximating the inverse function with multiple ad hoc stages in a signal processing chain whose composition depends on the details of each acquisition strategy, and often requires expert parameter tuning to optimize reconstruction performance. We present here a unified framework for image reconstruction, AUtomated TransfOrm by Manifold APproximation (AUTOMAP), which recasts image reconstruction as a data-driven, supervised learning task that allows a mapping between sensor and image domain to emerge from an appropriate corpus of training data. We implement AUTOMAP with a deep neural network and exhibit its flexibility in learning reconstruction transforms for a variety of MRI acquisition strategies, using the same network architecture and hyperparameters. We further demonstrate its efficiency in sparsely representing transforms along low-dimensional manifolds, resulting in superior immunity to noise and reconstruction artifacts compared with conventional handcrafted reconstruction methods. In addition to improving the reconstruction performance of existing acquisition methodologies, we anticipate accelerating the discovery of new acquisition strategies across modalities as the burden of reconstruction becomes lifted by AUTOMAP and learned-reconstruction approaches.
CNN+CNN: Convolutional Decoders for Image Captioning
May 23, 2018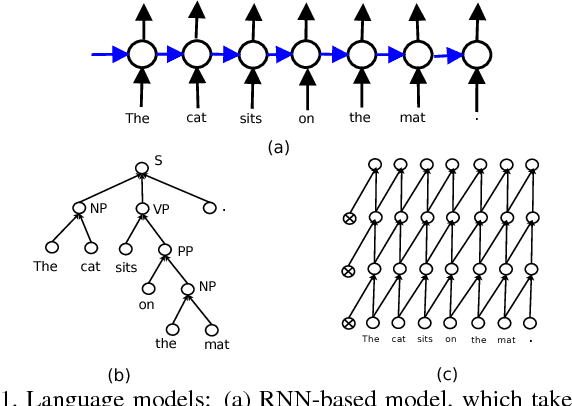
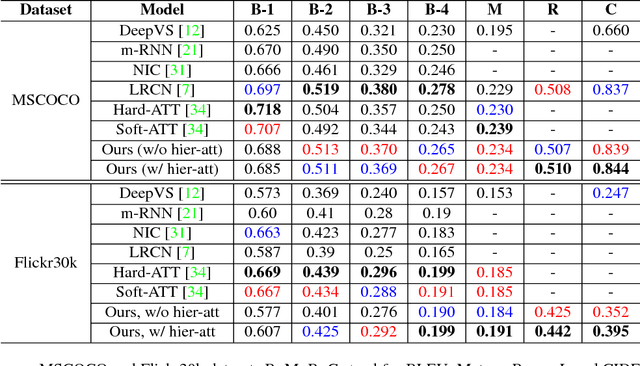
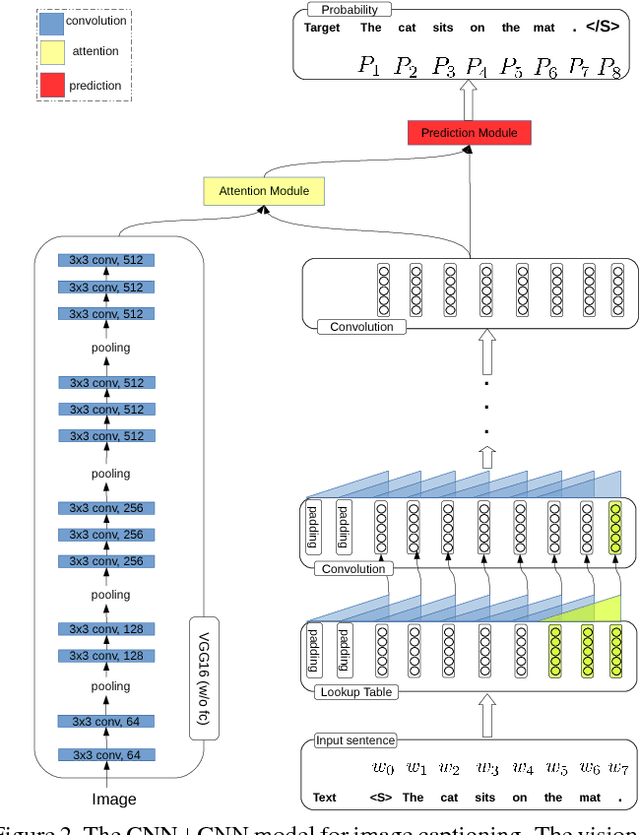
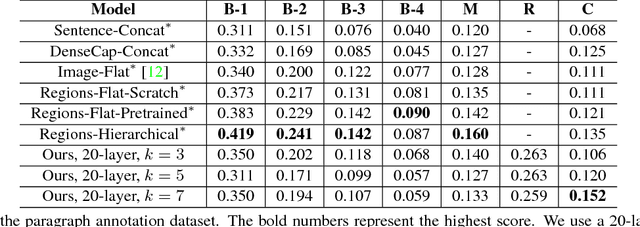
Image captioning is a challenging task that combines the field of computer vision and natural language processing. A variety of approaches have been proposed to achieve the goal of automatically describing an image, and recurrent neural network (RNN) or long-short term memory (LSTM) based models dominate this field. However, RNNs or LSTMs cannot be calculated in parallel and ignore the underlying hierarchical structure of a sentence. In this paper, we propose a framework that only employs convolutional neural networks (CNNs) to generate captions. Owing to parallel computing, our basic model is around 3 times faster than NIC (an LSTM-based model) during training time, while also providing better results. We conduct extensive experiments on MSCOCO and investigate the influence of the model width and depth. Compared with LSTM-based models that apply similar attention mechanisms, our proposed models achieves comparable scores of BLEU-1,2,3,4 and METEOR, and higher scores of CIDEr. We also test our model on the paragraph annotation dataset, and get higher CIDEr score compared with hierarchical LSTMs
An Introduction to Robust Graph Convolutional Networks
Mar 27, 2021

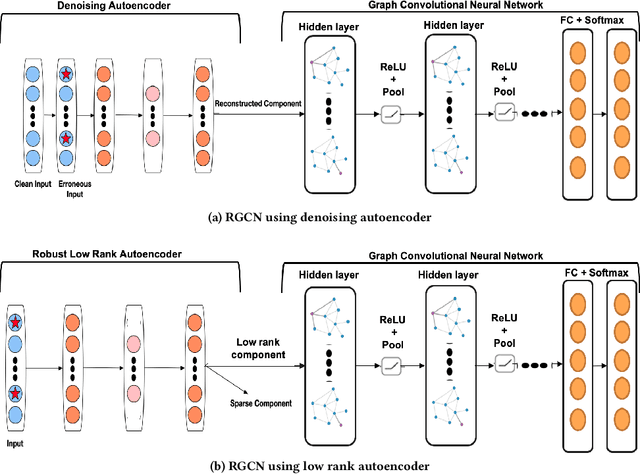

Graph convolutional neural networks (GCNs) generalize tradition convolutional neural networks (CNNs) from low-dimensional regular graphs (e.g., image) to high dimensional irregular graphs (e.g., text documents on word embeddings). Due to inevitable faulty data collection instruments, deceptive data manipulation, or other system errors, the data might be error-contaminated. Even a small amount of error such as noise can compromise the ability of GCNs and render them inadmissible to a large extent. The key challenge is how to effectively and efficiently employ GCNs in the presence of erroneous data. In this paper, we propose a novel Robust Graph Convolutional Neural Networks for possible erroneous single-view or multi-view data where data may come from multiple sources. By incorporating an extra layers via Autoencoders into traditional graph convolutional networks, we characterize and handle typical error models explicitly. Experimental results on various real-world datasets demonstrate the superiority of the proposed model over the baseline methods and its robustness against different types of error.
Sparse Range-constrained Learning and Its Application for Medical Image Grading
Jul 11, 2018
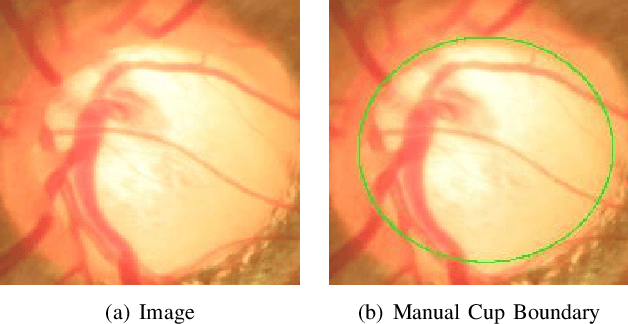
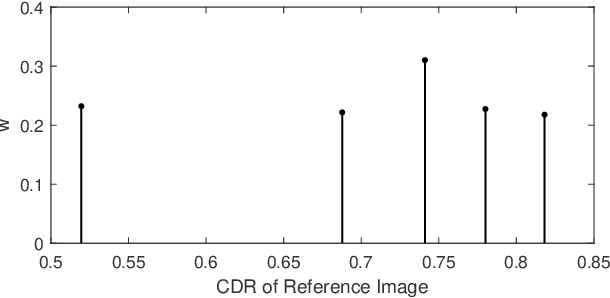
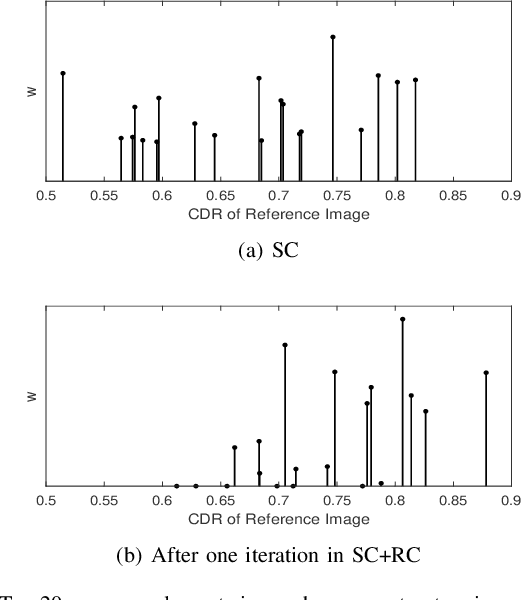
Sparse learning has been shown to be effective in solving many real-world problems. Finding sparse representations is a fundamentally important topic in many fields of science including signal processing, computer vision, genome study and medical imaging. One important issue in applying sparse representation is to find the basis to represent the data,especially in computer vision and medical imaging where the data is not necessary incoherent. In medical imaging, clinicians often grade the severity or measure the risk score of a disease based on images. This process is referred to as medical image grading. Manual grading of the disease severity or risk score is often used. However, it is tedious, subjective and expensive. Sparse learning has been used for automatic grading of medical images for different diseases. In the grading, we usually begin with one step to find a sparse representation of the testing image using a set of reference images or atoms from the dictionary. Then in the second step, the selected atoms are used as references to compute the grades of the testing images. Since the two steps are conducted sequentially, the objective function in the first step is not necessarily optimized for the second step. In this paper, we propose a novel sparse range-constrained learning(SRCL)algorithm for medical image grading.Different from most of existing sparse learning algorithms, SRCL integrates the objective of finding a sparse representation and that of grading the image into one function. It aims to find a sparse representation of the testing image based on atoms that are most similar in both the data or feature representation and the medical grading scores. We apply the new proposed SRCL to CDR computation and cataract grading. Experimental results show that the proposed method is able to improve the accuracy in cup-to-disc ratio computation and cataract grading.
All-You-Can-Fit 8-Bit Flexible Floating-Point Format for Accurate and Memory-Efficient Inference of Deep Neural Networks
Apr 24, 2021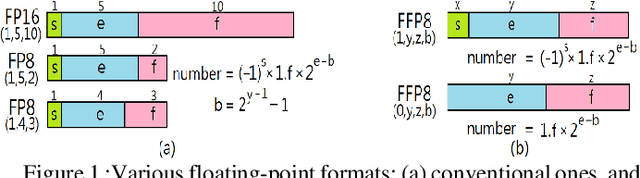


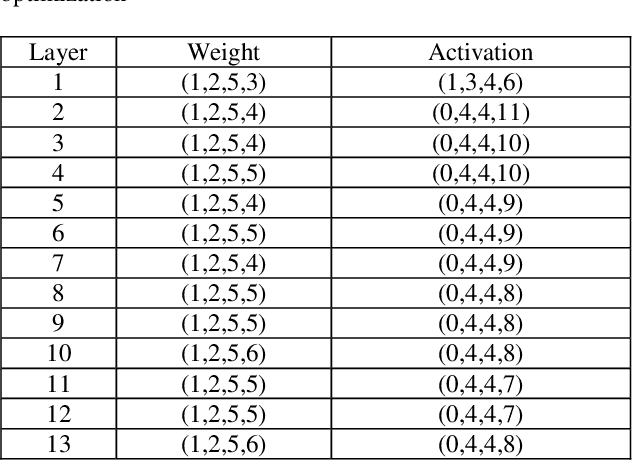
Modern deep neural network (DNN) models generally require a huge amount of weight and activation values to achieve good inference outcomes. Those data inevitably demand a massive off-chip memory capacity/bandwidth, and the situation gets even worse if they are represented in high-precision floating-point formats. Effort has been made for representing those data in different 8-bit floating-point formats, nevertheless, a notable accuracy loss is still unavoidable. In this paper we introduce an extremely flexible 8-bit floating-point (FFP8) format whose defining factors - the bit width of exponent/fraction field, the exponent bias, and even the presence of the sign bit - are all configurable. We also present a methodology to properly determine those factors so that the accuracy of model inference can be maximized. The foundation of this methodology is based on a key observation - both the maximum magnitude and the value distribution are quite dissimilar between weights and activations in most DNN models. Experimental results demonstrate that the proposed FFP8 format achieves an extremely low accuracy loss of $0.1\%\sim 0.3\%$ for several representative image classification models even without the need of model retraining. Besides, it is easy to turn a classical floating-point processing unit into an FFP8-compliant one, and the extra hardware cost is minor.